Agent 落地之前,先把地基打对

2026 年,企业级 Agent 的落地速度到了一个临界点。
对话即分析、自动归因、一键执行策略——大模型的推理能力在过去一年跃迁了两个量级,"提问→解答→执行"这条链路正在被快速闭合。企业数据团队的需求侧也在同步升温:如果能用自然语言替代 SQL,数据分析的瓶颈将从"能写 SQL 的人"变成"能问对问题的人"。
但与此同时,另一个信号在行业里悄然积聚。
数据团队的社区、从业者群聊里,对 Agent 的吐槽频率在持续走高。"答案很完整,但我不知道该怎么问""它用的口径跟我们实际考核的不是一回事""同一个问题,换个问法答案不一样"。最典型的一句话是:"我不敢把它给的方案直接推全量。"
热度与信任之间,出现了一道正在扩大的裂缝。
这个裂缝不是某一家产品的问题。它指向一个结构性矛盾:Agent 的执行能力在快速逼近天花板,但企业的业务上下文、数据底座、判断链路还在旧水平线上。用旧地基支撑新物种,信任裂缝只会越来越大。
有些问题,发生在提问之前
传统 BI 时代,数据基础设施的设计目标很明确:帮人更高效地看数据。
这个目标决定了一个前提:最后一步是人。指标口径对不上了,拉个会对齐。分析方法论不系统,师傅带徒弟走几遍流程。结论靠不靠谱,人能本能地质疑——"这个口径对不对""有没有排除季节性波动""是不是某个渠道停投了"。
口径可容错,因为人会发现不对。分析方法论可以不系统,因为人在积累。结论可以不验证,因为人在质疑。
Agent 时代,这个前提不成立了。
新版本上线第七天,制作人盯着看板:七日留存从 42% 掉到 39%。不是"调 A 数值还是调 B 数值"这种有选项的问题,是"整个方向是不是该换了"。新手引导改得不对?渠道质量有问题?还是这届用户不带感?没有明确的提问对象,没有可拆解的指标。事情在变,气氛在微妙变化,他隐约觉得不对。
运营负责人在算一笔账:上周活动流水涨了 15%,扣除买量、分成、奖励,ROI 到底正还是负?财务按自然月摊销,运营按活动周期算,数据说 LTV 要拉 90 天看——三个口径,三个答案。
CEO 更直接:一条产品线做了三年,月流水 500 万,增长停了。继续投还是砍?数据告诉不了他"这个方向还有没有意义"。
这些"隐约觉得不对",发生在提问之前。Agent 能解决"被清晰表述的问题",但最有价值的问题,往往是还没被表述出来的。
三件事,没法靠外采解决
当 Agent 从"给人参考"变成"替人执行",企业需要重新算一笔账:什么东西在变便宜,什么不会?
算力、模型能力、推理速度、通用知识检索、标准化分析、流程化执行——这些正在变便宜。一个工作室今年还在堆的"数据分析能力",明年可能就是接口费用。
但有三件事,不会变便宜。
业务上下文的厚度。问"留存为什么下降",十年积累的团队知道:这个口径是含新增还是不含新增、上次类似问题是渠道质量、上上次是新手引导第三步流失、现在业务刚过新手期进入长草期。这些上下文不在公开互联网,是组织里一群人长期积累的私有结构。模型再强,没有这个底座只能给通用答案,而通用答案在企业决策里几乎没有价值。
Agentic Engine:100+行业Skills开箱即用
数据底座的稠密度。大部分企业的现状:投放数据在巨量/腾讯后台、LTV 在自研 BI、舆情在舆情系统、客服工单在 Zendesk、版本数据在 Jira——口径打架、归因断链、人工搬运。喂进去的数据稀薄,吐出来的判断就薄。能力在变便宜,喂养能力的底座反而在变贵——没法靠外采解决。
Agentic Engine:多Agent协作闭环
判断链路的清晰度。从"看到信号"到"做出决定",中间多少环节、谁有权按按钮、谁负责——这条链路的清晰程度,决定了 Agent 能接到哪一层。链路混乱的组织,Agent 接不动("这个决定要过产品委员会→CTO→CEO,你先拉个会");链路清晰的组织,Agent 能从信号扫描接到方案推全。
这是组织能力,不是技术能力。
幻觉的根,不在模型层
当前行业对 Agent 幻觉的主流解法,集中在模型层:更好的 prompt、更好的 RAG、更好的微调。这些努力有价值,但解决的是"模型推理"这个环节。
而前面三个环节——业务上下文注入、数据底座治理、判断链路对齐——在模型开始推理之前就已经跑偏了。
真正的防线在模型下面那一层:
统一语义层,让"DAU""收入""留存"在企业内部有唯一定义。持续记忆系统,让历史结论、异常归因、A/B 胜负沉淀为长期记忆。行业分析框架,让留存怎么拆、付费看什么维度、ROI 怎么归因被编码为结构化路径。全链路验证,新逻辑先在历史数据上验证,再与旧逻辑并行对比。
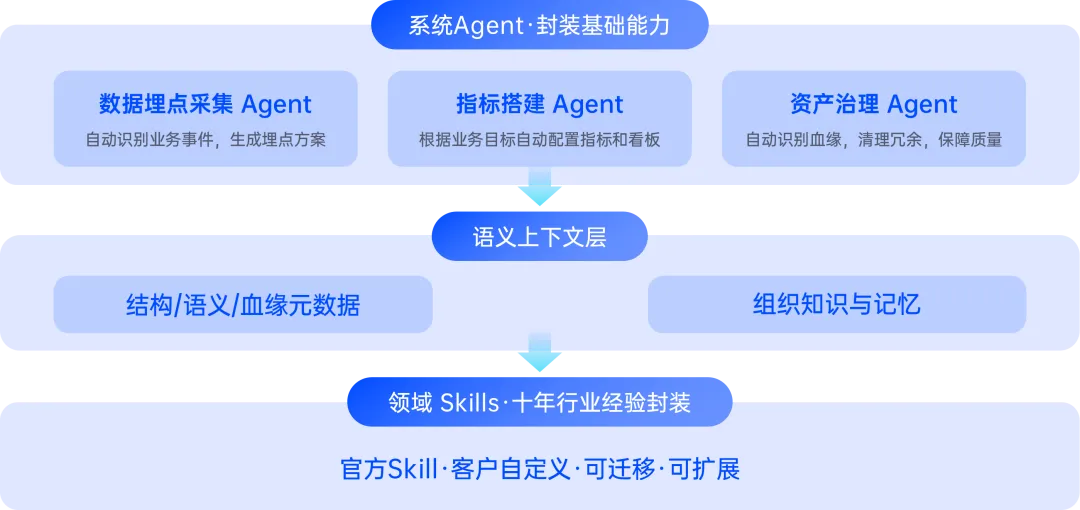
ThinkingAI 的 Agentic Engine 把这几道防线作为数据底座来建——不是功能附加,是基础设施。这个方向值得关注,因为它代表了一种切换:从"让模型更聪明"到"让模型有正确的信息地基"。
从"参考级"到"执行级"
BI 时代,数据基础设施是"参考级"的。人容忍 90% 准确率——口径不对人能发现,维度漏了人能补充,结论不靠谱人能判断。人是最后一道安全网。
Agent 时代,安全网消失了。Agent 拿到什么口径就用什么口径。90% 准确率不够了,因为那 10% 的错误是自动执行的错误决策,在没人审核的情况下生效。
从"参考级"到"执行级",不是提更高 SLA,是换评价体系。参考级要求数据"能看",执行级要求数据"能做决策依据"。参考级容忍口径多样性,执行级要求口径唯一性。
以前数据治理是 IT 部门的效率问题,现在是 Agent 能不能用对数据的生存问题。而这,可能是接下来两三年里,企业数据栈最深刻的一次价值重估。
回到开头那个裂缝。
Agent 的热度与信任之间的裂缝,短期内不会消失。越来越多 Agent 产品上线,越来越多企业尝试"一句话做分析",越来越多决策者经历"看起来对但实际错"的挫败。
但裂缝不会一直存在。那些先把业务上下文、数据底座、判断链路从"参考级"升级到"执行级"的企业,会最先跨过去。
到那时,分水岭不再是"谁家的 Agent 更好用",而是"谁家的数据地基能支撑 Agent 做对的事"。
幻觉不是 Agent 的宿命。是数据基础设施还没跟上的症状。地基打对了,信任就回来了。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 5
5 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)