WSL环境安装MinerU
一、环境准备:
1.确保CPU的虚拟化是“已启用”。(在任务管理器看CPU页面)
2.确保WSL里的nvidia-smi列出的显卡正常且显存足够(8GB或以上)
3.windows11中安装docker desktop的步骤参阅小白安装dify的基础教程–2.安装docker desktop章节
二、安装部署MinerU
在WSL里选定并进入安装目录。(如果是/opt下面创建,可能要获取权限)
sudo mkdir /opt/mineru
#下面获取目录权限
sudo chown admin:admin /opt/mineru/
cd /opt/minieru
1. 克隆MinerU仓库文件
git clone https://github.com/opendatalab/MinerU.git mineru
(国内加速地址:
git clone https://gitee.com/open-data-lab/MinerU.git mineru)
检查克隆后的文件结构是否正确:
当前目录
mineru/docker$ ls
china compose.yaml global
china子目录
mineru/docker$ ls china/
Dockerfile dcu.Dockerfile kxpu.Dockerfile mlu.Dockerfile npu.Dockerfile
corex.Dockerfile gcu.Dockerfile maca.Dockerfile musa.Dockerfile ppu.Dockerfile
2. 按需编辑compose.yaml里的配置
cd mineru/docker
替换模型的源为国内魔塔modelscope:
sed -i 's/MINERU_MODEL_SOURCE: local/MINERU_MODEL_SOURCE: modelscope/g' compose.yaml
3. 进行本地构建mineru:latest镜像
显式指定使用 china 目录下的 Dockerfile 进行本地构建,并命名为 mineru:latest
docker build -t mineru:latest -f china/Dockerfile .
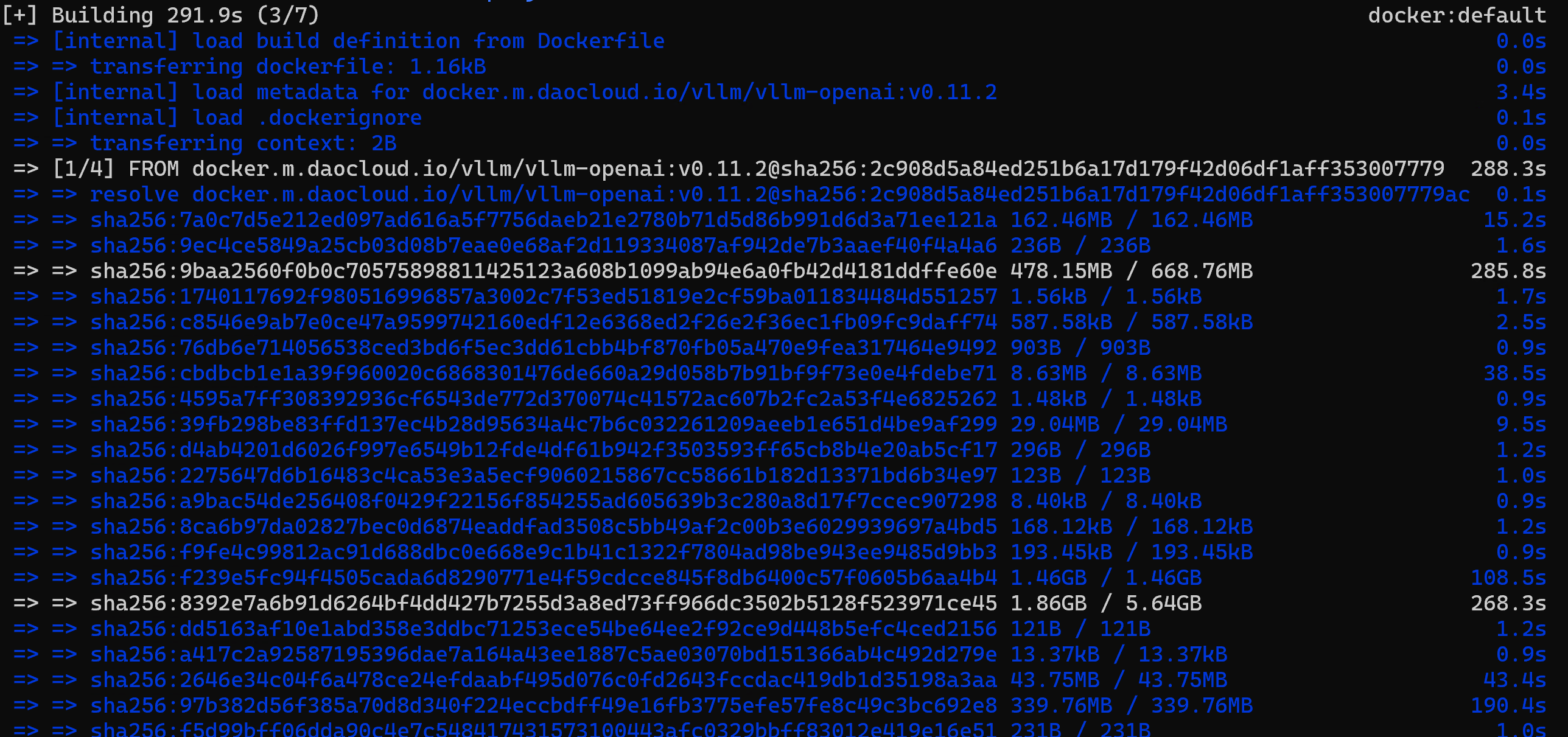
等待十几分钟,耐心等待它完全编译结束并显示 FINISHED。
4. 修改compose.yaml的显卡配置:
nano compose.yaml
GPU选择设置
默认的 compose.yaml 已经包含了 GPU 的预配置(deploy.resources.reservations.devices)。如果你有多张显卡,可以编辑该文件修改 device_ids
内存占用设置:
command: --host 0.0.0.0 --port 30000 #--gpu-memory-utilization 0.5
改为:
command: --host 0.0.0.0 --port 30000 --gpu-memory-utilization 0.5
(详细含义看后面的四、问题排查)
3. 启动 MinerU 服务
MinerU 提供了多种服务 Profile(例如 Web API、OpenAI 兼容接口、Gradio WebUI 等)。对于大多数日常可视化使用的用户,推荐直接启动带 Gradio WebUI 的界面:
# 使用 --profile 参数指定启动 gradio 界面
docker compose -p mineru -f compose.yaml --profile gradio up -d
如果你只需要后端的集成的 API 服务,可以直接运行:
docker compose -p mineru -f compose.yaml up -d
三、访问与使用
访问前端界面: 当日志显示服务启动成功后,打开 Windows 宿主机的浏览器,访问:
http://localhost:7860 (如果是特定端口,请检查 logs 中输出的 Gradio 端口)。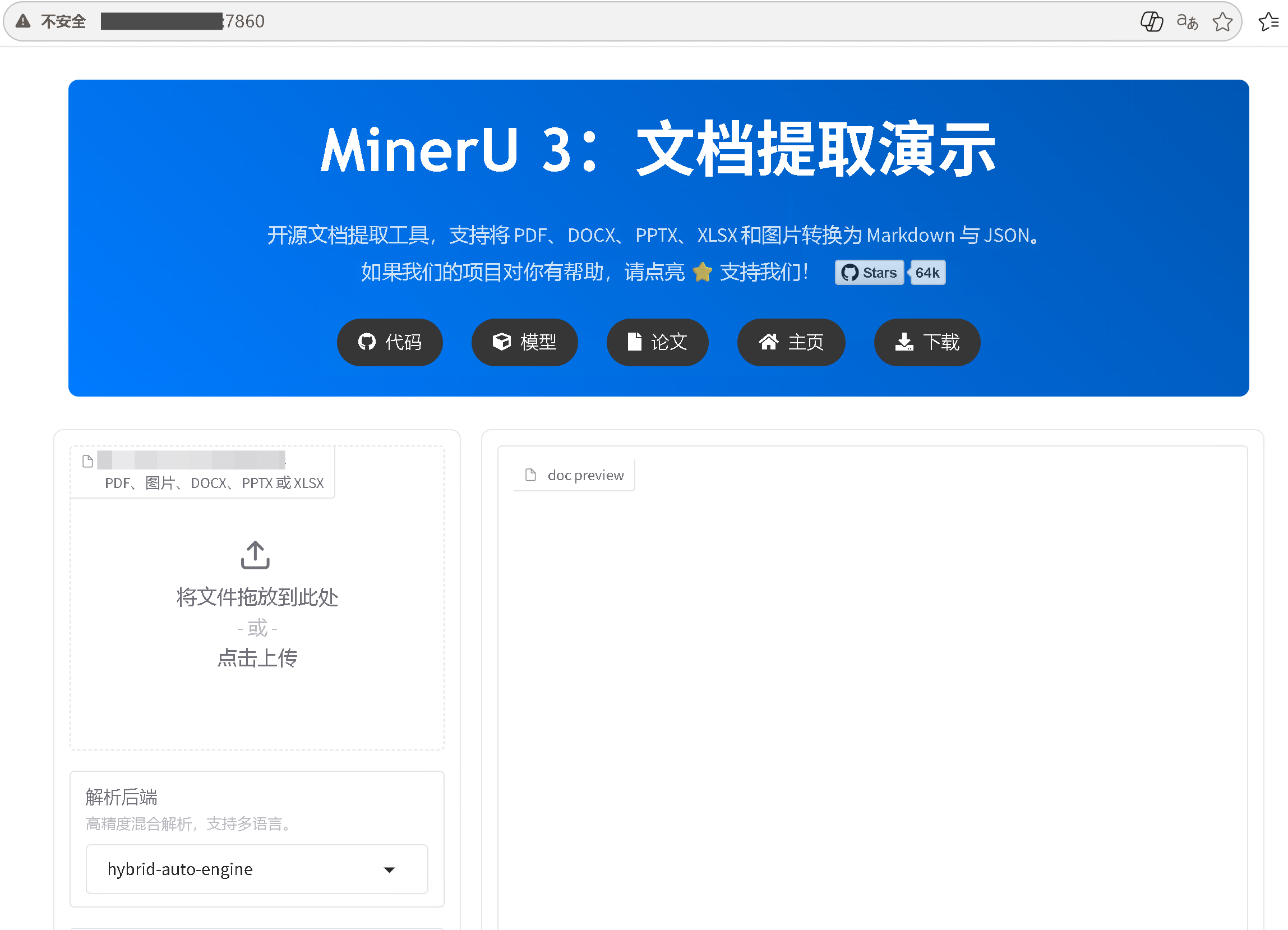
API 文档: 如果你启动了 Router 统一入口,可以通过浏览器访问 http://localhost:8002/docs 查看 Swagger API 文档,方便集成到 Dify、LangChain 等大模型编排工具中。
四、常见问题与排查
下载模型极慢或连接失败:
如果遇到网络问题导致模型无法下载,可以编辑 compose.yaml,在相关的 service 环境变量 environment: 下添加:
environment:
MINERU_MODEL_SOURCE: local
改为:
environment:
MINERU_MODEL_SOURCE: modelscope
切换到国内的魔搭社区(ModelScope)源,可以大幅提升国内环境下的下载速度。
显存溢出 (OOM):
如果你的显卡刚好只有 8GB 显存,可能会在运行 VLM 后端时遇到显存不足。可以在 compose.yaml 中为 mineru-openai-server 或 mineru-api 的启动命令添加或取消注释参数:
command: --host 0.0.0.0 --port 30000 --gpu-memory-utilization 0.5
将 gpu-memory-utilization(显存占用比例)降低至 0.5 或 0.6 以适配小显存设备。(意思是:只允许该模型服务占用显卡总显存的 50%或60%(不设置是0.9)。模型本身固定要5GB,剩下部分是缓存池。12GB显存*90%可以一口气处理数百页的文件。)
五、minerU核心模型清单
MinerU 在启动时,会默认去下载一整套由官方定制和微调的 文档高精度解析模型合集。在底层,这些模型主要服务于两大解析体系(Pipeline 模式 和最新升级的 VLM 模式)。
全套模型权重文件总计大约在 20GB ~ 30GB 左右。
MinerU 默认下载的核心组件模型主要来自于 PDF-Extract-Kit 算法库,具体分为以下几大模块:
1. 布局检测模型 (Layout Detection)
用于识别 PDF 页面中的各种元素区域(如段落、标题、表格、图片、公式等)。
默认模型: DocLayout-YOLO(基于 YOLO 架构专门针对文档版面优化的模型,对多栏、中英文混合排版定位非常精准)。
2. 公式识别模型 (Formula Detection & Recognition)
处理文档中最头疼的数学、物理、化学公式。
公式检测 (MFD): YOLO_v8_MFD,用于精准圈出页面中的行内公式和行间公式。
公式识别 (MFR): UniMERNet(通常为 unimernet_small),负责把圈出来的公式图片转化为标准 LaTeX 源码。
3. 表格识别模型 (Table Recognition)
将表格图片还原为可编辑的结构化数据(如 Markdown 表格、HTML 或 LaTeX 代码)。
默认模型: StructEqTable 或 TableMaster / RapidTable。
注:StructEqTable 是一个非常强大的端到端表格识别模型,特别擅长处理学术论文和财报中带复杂跨行/跨列的表格。
4. OCR 文本识别模型 (Optical Character Recognition)
针对扫描件、图片 PDF 进行文字提取。
默认模型: 通常内置集成了经过微调的 PaddleOCR 或自研 OCR 模块,支持中英文的高精度字符定位与识别。
5. 主力视觉语言模型 (VLM Mode)
在最新版本中,MinerU 引入了端到端的视觉大语言模型(VLM)来处理更复杂的版面(如跨页表格合并、图表内容深度理解)。
默认模型: MinerU2.5-Pro-1.2B(或同系列的端到端文档解析多模态小模型)。
如果你需要把MinerU集成到Dify,请参阅
把MinerU集成到Dify

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)