社交媒体用户情绪行为数据分析
一、数据集来源
(一)数据基本信息
数据集下载
https://www.kaggle.com/datasets/emirhanai/social-media-usage-and-emotional-well-being
| 字段 | 说明 |
|
User_ID |
用户的唯一标识符。 |
|
Age |
用户的年龄。 |
|
Gender |
用户的性别(女性,男性)。 |
|
Platform |
使用的社交媒体平台(例如,Instagram,Twitter,Facebook,LinkedIn,Snapchat,Whatsapp,Telegram)。 |
|
Daily_Usage_Time (minutes) |
每天在平台上花费的时间(单位:分钟)。 |
|
Posts_Per_Day |
每天发布的帖子数量。 |
|
Likes_Received_Per_Day |
每天收到的点赞数。 |
|
Comments_Received_Per_Day |
每天收到的评论数。 |
|
Messages_Sent_Per_Day |
每天发送的消息数量。 |
|
Dominant_Emotion |
用户一天中的主要情绪状态(例如,Happiness(快乐),Sadness(悲伤),Anger(愤怒),Anxiety(焦虑),Boredom(无聊),Neutral(中性))。 |
(二)数据预处理
简单观察一下三份数据集,发现数据集有空行、有重复,编写代码合并三份csv文件,并完成自动删除空行,去重。

第一次数据处理出现了爆红,观察一下数据集发现是 val.csv 中第 90 行多了一列数据,导致 Pandas 读 CSV 时,发现这一行字段数和表头对应不起来。
仔细观察 val.csv 这个表,发现部分数据都多出一列,并且部分数据有错位的情况。

所以,我们通过采用 “暴力读取” 的方法,通过规则筛选出有效数据,保存到 social_media_clean.csv 表中。
使其满足:
1. Age 必须是数字,且在合理范围(10-100岁)
2. Gender 必须是 Male/Female/Non-binary 中的一种
3. Platform 必须是已知平台之一
4. Daily_Usage_Time 必须是数字,且大于0
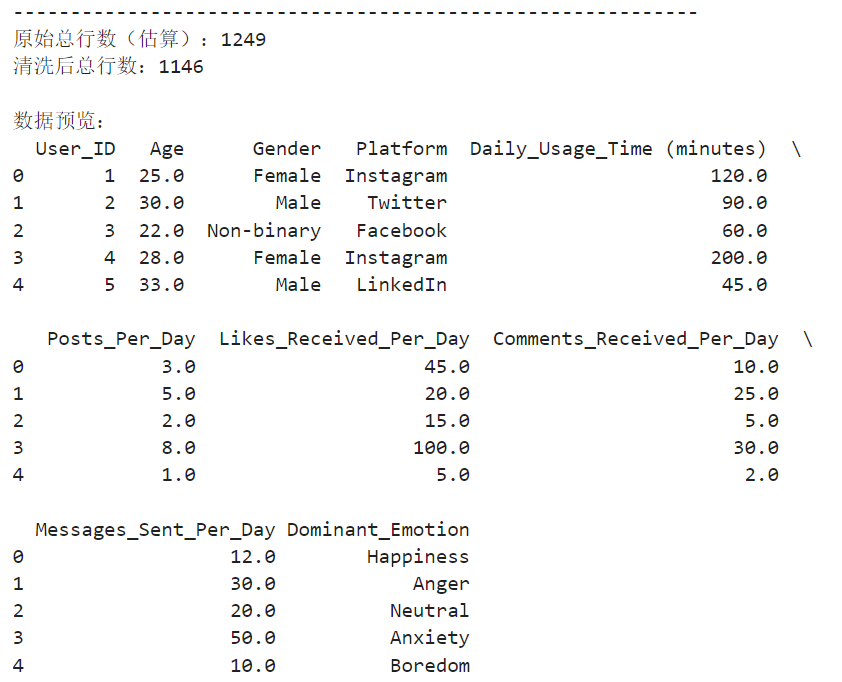
最后,再次检验数据格式是否正常。
import pandas as pd
df_new = pd.read_csv("social_media_clean.csv")
print(df_new.isna().sum().sum())
print(df_new.duplicated().sum())
print(df_new.shape)
print(df_new.columns)
发现重复值还是存在,那我们再次进行去重处理。
将148行重复值全部找出来。
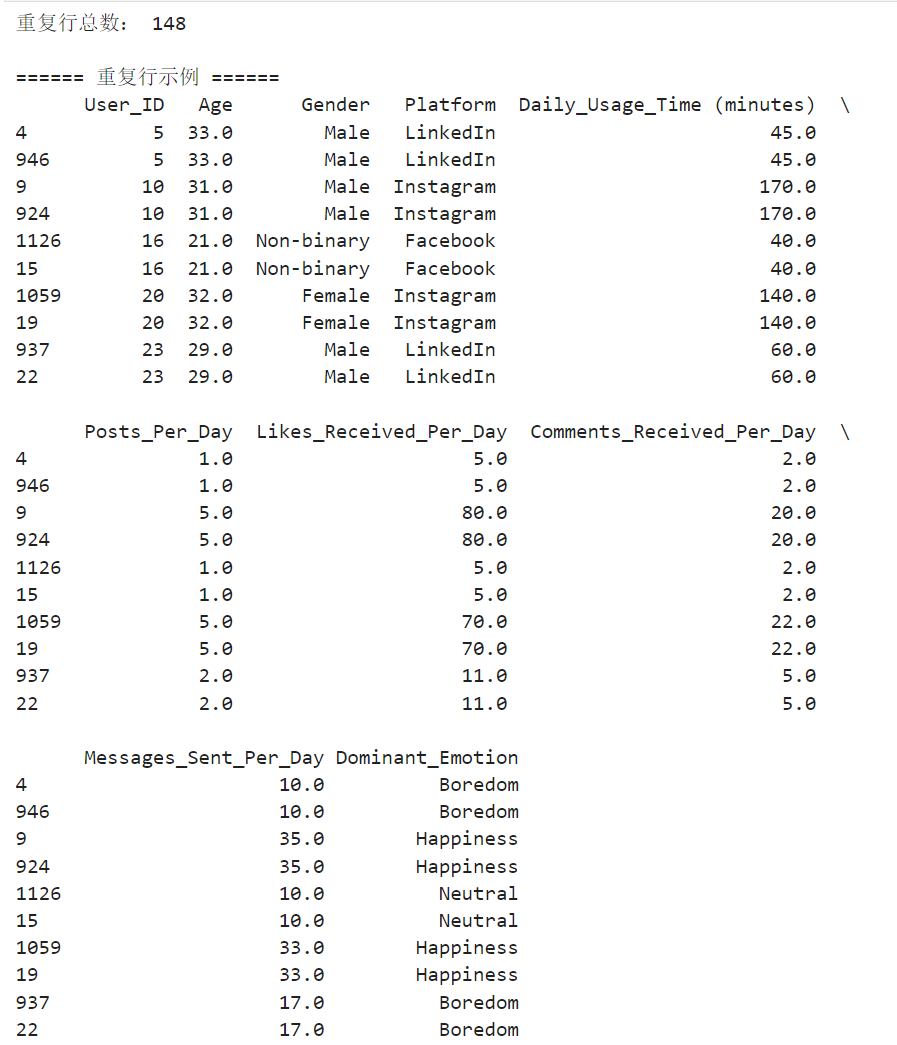
由运行结果可以发现问题:重复总行数148行,有User_ID完全重复的
解决方法:再次清洗数据,按照User_ID 去重

再次查看数据情况,格式正常,无重复值,无空行,共有937行数据。

二、导入数据库
在虚拟机中启动 mysql ,将数据集从本地导入到里面。
在这里,因为我在虚拟机中也下载了 jupyter notebook ,所以就用 jupyter 来连接数据库中的数据。
三、数据分析
(一)分析前准备
打开虚拟机中的 notebook , 当然你也可以选择直接把本地文件放这里。
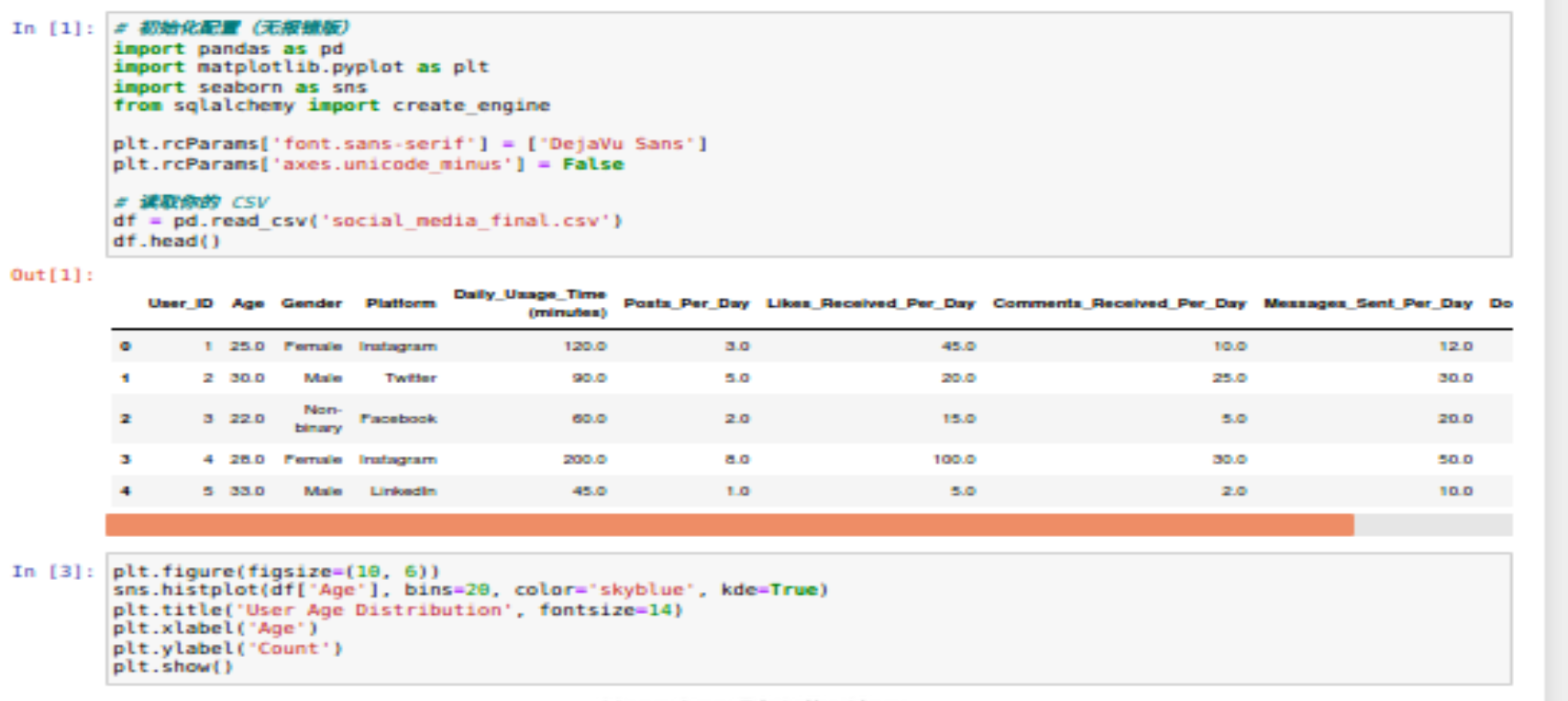
(二)用户数据基本分布
1. 各平台用户数
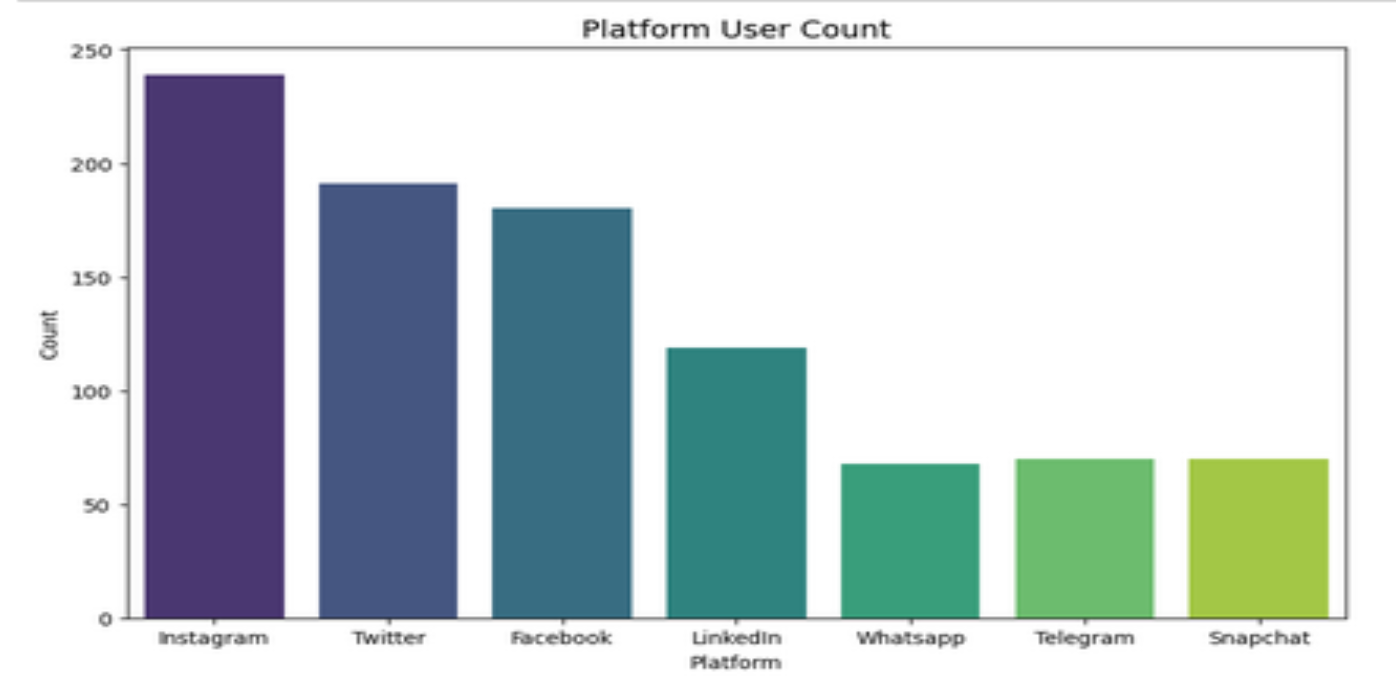
2. 不同年龄的分布
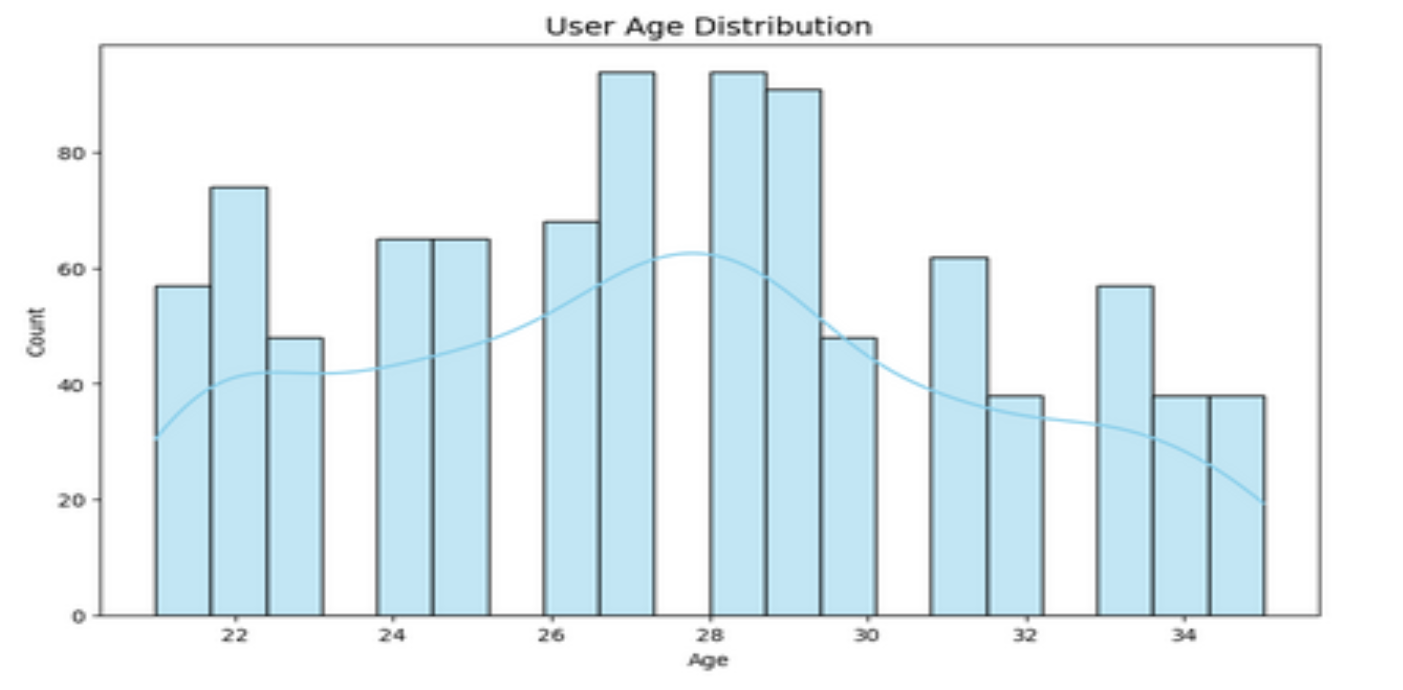
3. 不同群体(性别)分布
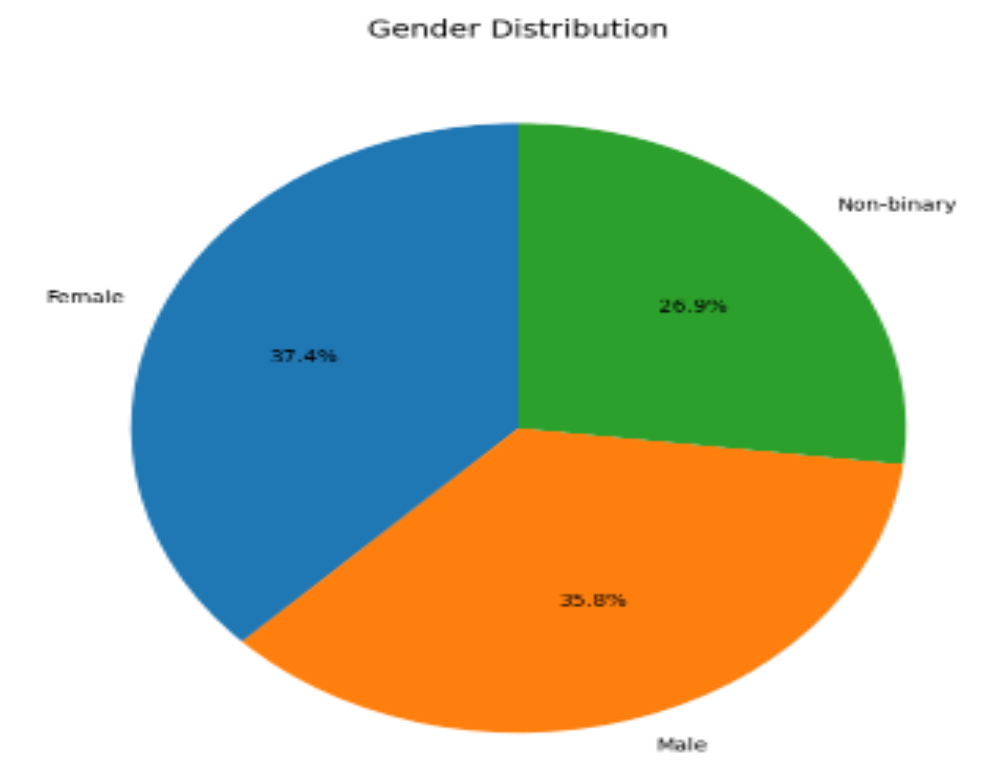
(三)用户情绪行为分布
1. 用户情绪分布
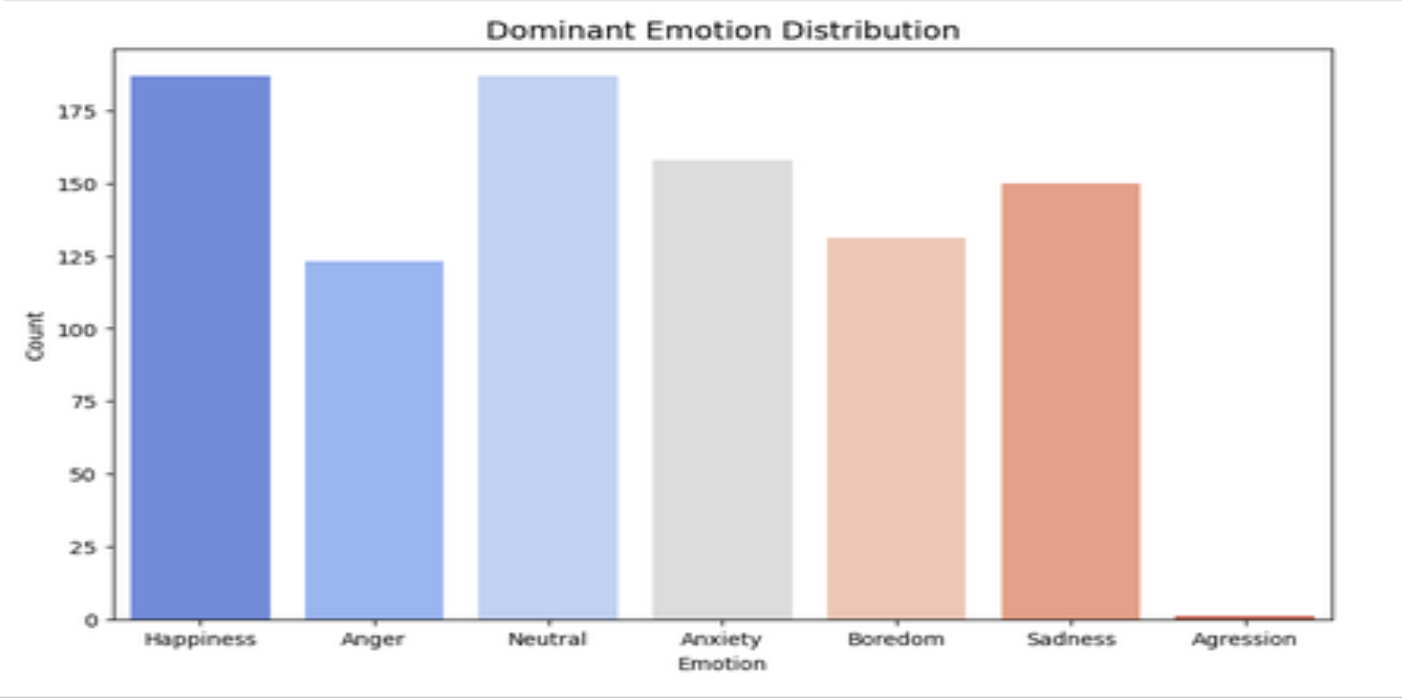
2. 年龄 vs 点赞数
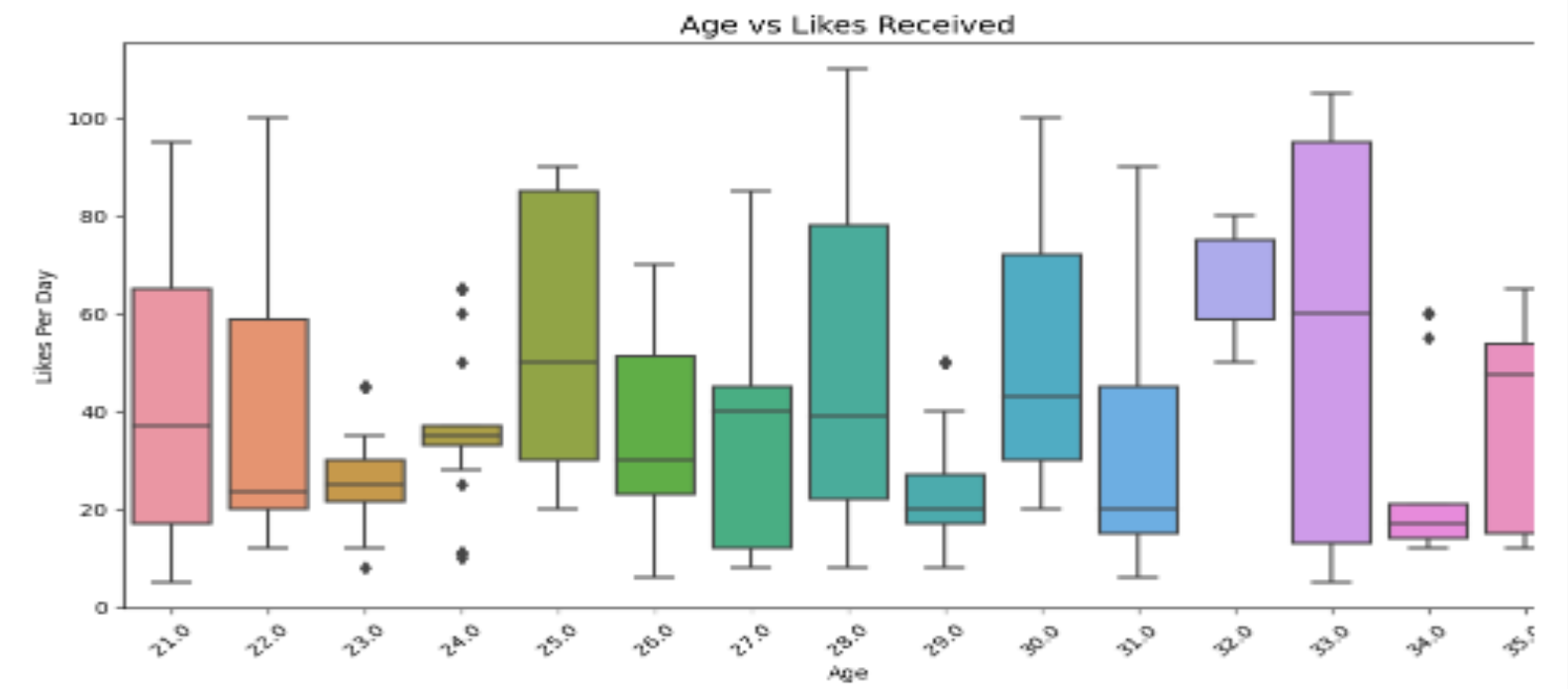
虚拟机上的像素有限,个别图片有些不清楚。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 5
5 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)