AI架构师/工程师高薪职位!上海/北京等你来挑战!
本文介绍了多个与AI相关的职位,包括AI基础设施系统架构师、大模型训练框架工程师、大模型训练系统工程师、AI推理框架工程师和大模型算法工程师等。这些职位要求应聘者具备扎实的计算机体系结构、分布式系统基础和高性能网络技术,熟悉GPU硬件架构和主流AI训练/推理基础设施生态。此外,应聘者还需要具备良好的沟通领导力、跨团队项目推动经验和良好的代码习惯。这些职位为AI领域的专业人士提供了广阔的发展空间和挑战机会。
一、AI基础设施系统架构师(Tech Lead) 上海/北京
职位描述
-
IaaS 平台架构设计:负责 AI IaaS 基础设施的架构设计与持续迭代,涵盖 GPU算力资源池化、多集群调度、弹性扩缩容等核心能力建设,提供一致性、可扩展、高可靠的平台技术底座
-
Infra 管理平台:规划并推进基础设施管理平台的建设,覆盖资产管理、容量管理、 故障自愈、可观测性等能力,提升大规模集群的运维效率和自动化水平
-
硬件方案创新与 TCO 优化:跟踪GPU/网络/存储等硬件技术演进,联合硬件研发、网络、存储、内核等团队推动方案创新 ,在性能、成本、可用性、可运维性等维度持续提升竞争力
-
算力中心规划与建设:Lead团队成员完成大模型训练/推理场景下的算力中心整体建设,包括机房选址评估、电力/散热容量规划、服务器选型与集群组网方案设计,端到端交付高性能 AI 基础设施
职位要求
-
5 年以上云计算/IDC 基础设施相关工作经验,有大规模 AI 算力集群(千卡以上)的规划、建设或运营经验优先
-
深入理解计算机体系结构, 对GPU 服务器、高速网络(IB/RoCE/NVLink/NVSwitch)、高性能存储等其中1个或多个方向有比较深入的熟悉和了解
-
了解大模型训练对基础设施的核心需求,熟悉主流 AI 训练/推理基础设施生态(NVIDIA DGX/HGX、集合通信、NCCL等)
4… 有 IaaS 平台或基础设施管理平台的设计与落地经验者优先(资源调度、CMDB、监控告警等)
5 具备跨团队项目推动经验和良好的沟通领导力,能带领 3-5 人项目组攻克复杂技术问题
加分项
- 有头部云厂商(阿里云/AWS/GCP/Azure)或 AI 公司基础设施团队经验
二、大模型训练框架工程师(训练框架 & RL 方向) 北京/上海
在某个领域有真正的深度——分布式系统、GPU 性能优化、RL 工程、推理加速,都行——同时对算法前沿保持真实的好奇心。
三、大模型训练框架研发工程师-生成模型方向 北京/上海
你将加入一支把“把万卡集群跑到极致”当日常的团队,与业内领先的通用大模型一起成长。你的核心任务是:突破大规模训练的速度、成本与稳定性的极限。
你将负责的核心工作:
- 大规模分布式训练系统研发(Scale Matters)
-
主导 Data / Tensor / Pipeline / Expert 并行 策略的研发与优化。
-
优化高性能通信、计算通信掩盖、显存复用,提升近万卡训练的集群利用率。
-
面向上百亿〜万亿参数模型,实践高效并行范式。
- 性能极限优化(Performance Engineering)
-
系统性分析训练吞吐瓶颈(comm / compute / IO / kernel / memory)。
-
针对关键路径做深度优化:算子融合、精度压缩、通信调度、显存管理策略。
-
与推理体系协同推进量化、MoE、Speculative Training 等最新机制的训练端落地。
- 前沿训练技术探索(Frontier Research → Engineering)
根据你的兴趣及特长,可主导其中一类:
-
前沿训练范式:Agentic RL、异步 RL等机制的系统工程化落地。
-
训练稳定性:大规模优化器、 动态容灾、divergence 检测与修复机制。
-
可扩展性研究:scaling law 工程落地、模型分布式形态设计、训练效率极限建模。
- 与硬件深度协作(System × Model)
-
与底层 kernel / runtime / compiler 团队协作,共同推进 compute-bound 和 comm-bound 场景的极限性能。
-
设计充分压榨 GPU/NPU 的训练模式,让硬件“跑在它没想过的速度”。
职位要求
我们希望你具备(不求全,但求强)
-
可以 0 优化经验,但在其他领域有过优秀成果。
-
熟悉高级编程语言,具备扎实的数据结构、并行编程、系统基础。
-
对 PyTorch、DeepSpeed、Megatron、Horovod、JAX、XLA 等之一有体系化理解。
-
对以下任一方向有深入经验或潜力:
-
大型分布式训练(DP/TP/PP/MoE)
-
GPU/多机通信优化(NCCL、RDMA、通信拓扑)
-
训练框架/执行引擎研发
-
大模型训练的性能与稳定性优化
- 对前沿训练问题有明确兴趣,如:
-
训练端:scaling law、混合并行策略、优化器系统、极致显存压缩
-
推理端协同:量化训练、KV cache aware training、speculative training
-
有大规模模型训练经验(千卡〜万卡)者优先。
-
有顶会论文、开源贡献、或工程项目能展示你能力者,是加分项但非必要。
为什么加入我们
-
你将直接参与 领先通用大模型的核心训练体系,工作成果会快速转化为真实产品力。
-
足够高的解决问题自由度,我们的工作不仅局限于特定scope,也不受限于特定工程算法方案,只要能够挑战更高的极限,可以放下当前所有的约束。
-
和有“偏执工程美学”的伙伴一起,把“更快、更稳、更大规模”做成一种乐趣。
四、大模型训练系统工程师 北京/上海
职位描述
-
建设超大规模AI训练集群,保证训练的稳定性,提升资源效率和硬件效率;
-
深度参与大模型技术迭代,构建预训练、SFT、RLHF等算法方向的工程架构,解决底层基建问题,提升模型整体的迭代效率;
-
探索业界前沿的AI Infra技术,建设行业领先的大模型基础设施解决方案。
职位要求
-
扎实的计算机体系结构和分布式系统基础,熟悉GPU硬件架构,具备Kubernetes及云原生技术栈,了解 RDMA、InfiniBand、NVLink 等高性能网络技术;
-
扎实的工程素养,良好的代码习惯(Golang/Python/C++),善于使用AI Coding提升工作效率;
-
对大模型架构和工程链路有了解,了解Megatron、Verl、Ray等训练框架;
-
优秀的学习能力,对AI有热情和好奇心,追求技术成长和认知快速迭代,表达清晰,逻辑严谨;
-
良好的沟通协作能力,能够与算法团队紧密配合,一起探索大模型新技术,推动模型快速迭代。
五、AI推理框架工程师 北京/上海
职位描述
-
针对特定端到端推理任务,实现zero-overhead标准的推理服务。
-
针对特定硬件的极限性能压榨。
-
端到端系统架构的研究、开发、维护。
-
性能优化相关算法研究与开发工作。
职位要求
-
计算机及相关专业,本科及以上学历。
-
有端到端性能分析能力,可以正确理解性能表现的原理。包括但不局限于gpu性能分析。
-
有扎实的编程能力和代码品位,良好的数据结构和算法基础。
-
理解操作系统基本原理。
-
能熟练使用C++/C、python等高级语言。
-
有良好的可靠性意识,包括不限于监控、容灾等。
-
有良好的团队沟通和协作能力,有良好的责任心。
-
有良好的自驱力和学习能力。
加分项:
icpc、oi、mo、asc等竞赛获奖经历
六、大模型算法工程师 北京/上海
研发超大规模基础模型(LLM&MLLM),并进行极致的系统优化;
职位要求
-
有强烈的技术追求和和热情,真的想要用技术给现实世界带来改变;
-
具备优秀的研究素养和创新能力,在国际顶会或期刊发表过高质量论文;
-
有良好的工程和动手能力,能够广泛利用各种工具解决问题,主导或者参与过有影响力的大规模机器学习项目;
加分项
-
有大规模分布式训练相关经验、在理解算法原理的同时,也掌握实现细节者优先;
-
有ACM/NOI/超算等各类竞赛获奖经历者优先;
-
有强化学习经验优先;
七、大模型算法工程师-co design 北京/上海
职位描述
寻找深度理解大模型算法,同时具备顶尖系统工程设计能力的专家。你将作为算法研究与工程落地的核心桥梁,主导优化大模型训练/推理效率、性能与成本,确保前沿算法在大规模系统中高效实现。
- 协同设计与优化:
-
深入理解大模型算法(架构、训练/推理技术),评估其工程可行性、性能瓶颈与成本。
-
主导设计下一代训练/推理框架或核心组件,确保原生支持高效算法实现(如高效Attention、通信优化)。
-
系统性解决训练/推理工作负载的性能瓶颈(计算、通信、存储)。
- 高性能系统实现:
- 设计并实现高性能核心(如定制Kernel)、优化通信与数据流水线。
- 分布式架构:
-
设计构建大规模分布式训练系统(DeepSpeed/Megatron-LM/FSDP)。
-
设计构建高并发、低延迟的大模型推理服务平台。
- 前瞻探索与协作:
-
跟踪领域前沿,探索验证新技术(新硬件、非Transformer架构等)。
-
高效沟通,跨团队(算法、工程、平台)协作推动方案落地。
职位要求
-
学历/经验: 计算机/人工智能等相关领域本科及以上,或具备同等杰出实践经验。
-
大模型基础: 深刻理解Transformer架构及大模型训练/推理等相关核心技术。
-
工程硬实力:
-
精通 PyTorch 及其分布式训练(DDP/FSDP),有大规模分布式系统设计开发调优经验
-
扎实的计算机体系结构/操作系统/网络基础。
-
丰富的“性能调优”经验(Nsight Systems, Profiler等)。
加分项
-
参与 DeepSpeed/Megatron-LM/vLLM/SGLang 等核心框架开发。
-
GPU Kernel优化 (CUDA/Triton) 经验。
-
千亿参数级模型训练/部署经验。
-
熟悉云平台大规模AI负载管理。
说真的,这两年看着身边一个个搞Java、C++、前端、数据、架构的开始卷大模型,挺唏嘘的。大家最开始都是写接口、搞Spring Boot、连数据库、配Redis,稳稳当当过日子。
结果GPT、DeepSeek火了之后,整条线上的人都开始有点慌了,大家都在想:“我是不是要学大模型,不然这饭碗还能保多久?”
我先给出最直接的答案:一定要把现有的技术和大模型结合起来,而不是抛弃你们现有技术!掌握AI能力的Java工程师比纯Java岗要吃香的多。
即使现在裁员、降薪、团队解散的比比皆是……但后续的趋势一定是AI应用落地!大模型方向才是实现职业升级、提升薪资待遇的绝佳机遇!
这绝非空谈。数据说话
2025年的最后一个月,脉脉高聘发布了《2025年度人才迁徙报告》,披露了2025年前10个月的招聘市场现状。
AI领域的人才需求呈现出极为迫切的“井喷”态势
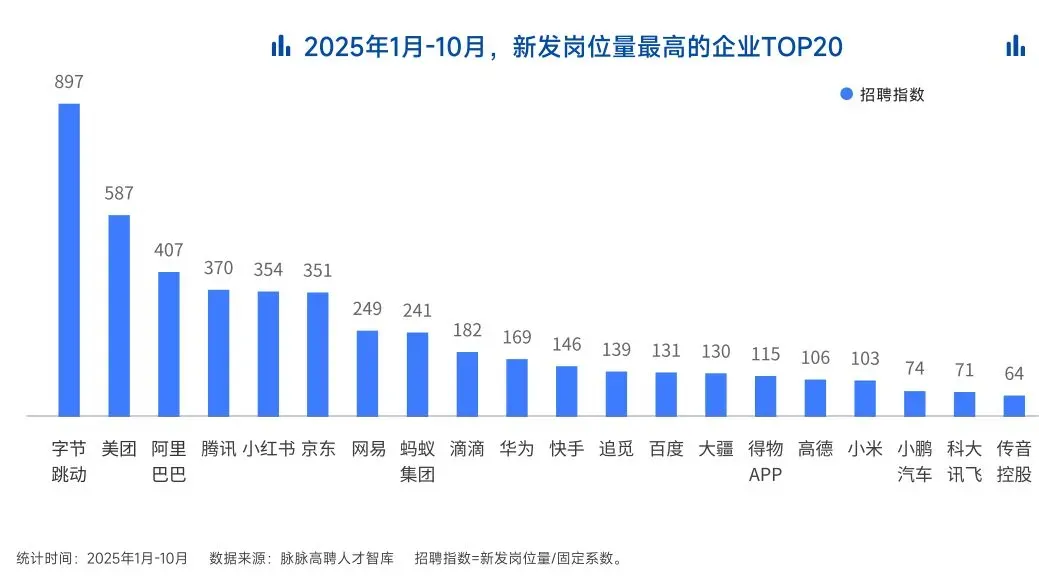
2025年前10个月,新发AI岗位量同比增长543%,9月单月同比增幅超11倍。同时,在薪资方面,AI领域也显著领先。其中,月薪排名前20的高薪岗位平均月薪均超过6万元,而这些席位大部分被AI研发岗占据。
与此相对应,市场为AI人才支付了显著的溢价:算法工程师中,专攻AIGC方向的岗位平均薪资较普通算法工程师高出近18%;产品经理岗位中,AI方向的产品经理薪资也领先约20%。
当你意识到“技术+AI”是个人突围的最佳路径时,整个就业市场的数据也印证了同一个事实:AI大模型正成为高薪机会的最大源头。
最后
我在一线科技企业深耕十二载,见证过太多因技术卡位而跃迁的案例。那些率先拥抱 AI 的同事,早已在效率与薪资上形成代际优势,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在大模型的学习中的很多困惑。
我整理出这套 AI 大模型突围资料包【允许白嫖】:
- ✅从入门到精通的全套视频教程
- ✅AI大模型学习路线图(0基础到项目实战仅需90天)
- ✅大模型书籍与技术文档PDF
- ✅各大厂大模型面试题目详解
- ✅640套AI大模型报告合集
- ✅大模型入门实战训练
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

①从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点

② AI大模型学习路线图(0基础到项目实战仅需90天)
全过程AI大模型学习路线
③学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的

④各大厂大模型面试题目详解

⑤640套AI大模型报告合集

⑥大模型入门实战训练

👉获取方式:
有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 5
5 0
0- 0



 已为社区贡献176条内容
已为社区贡献176条内容

所有评论(0)