2026年AI网络爬虫工具指南:7大工具对比与避坑要点
AI 网络爬虫正在从“写规则抓页面”升级为“让模型理解页面”。与传统爬虫相比,AI 抓取工具更能适应网页结构变化、把杂乱页面转成结构化数据,适合用于市场研究、价格监控、SEO 监控、RAG 知识库、数据分析与自动化流程。不过它也带来新问题:速度与成本上升、抽取偶发不准、以及动态站点与反爬带来的稳定性挑战。
下面按选型维度介绍 7 类常见方案,并给出落地中最常踩的坑与解决思路,最后附上动态代理在 Python 中的配置示例,便于直接验证与接入。

一、什么是 AI 网络爬虫/抓取工具?
AI 网络抓取工具是利用自然语言处理与大模型能力,自动完成“定位信息—抽取字段—结构化输出”的工具。常见形态包括:
-
云端 API:输入 URL,返回 Markdown/JSON/表格等数据
-
开源库:在 Python/JavaScript 中集成,便于自建采集管线
-
无代码平台:用可视化方式创建抓取机器人,定时监控并输出结果
AI 抓取工具的优势是减少因页面改版带来的维护成本;不足是对复杂页面可能更慢,并且需要通过结构化约束与校验来降低错误输出(例如“幻觉字段”)。
二、选型时最关键的 8 个因素
-
抽取准确性与可验证性:是否支持 schema 约束、证据引用与回溯
-
动态渲染与交互:JS 渲染、滚动加载、点击翻页、等待元素出现
-
反爬与稳定性:限速处理、验证码、自动重试、失败回放
-
代理能力:住宅/移动/数据中心、地区选择、轮换策略与会话保持
-
吞吐与并发:批处理、异步接口、队列与并发控制
-
集成与扩展:LangChain/LlamaIndex/自动化平台/Webhook
-
成本结构:按请求/额度/记录计费,是否叠加模型调用成本
-
合规与安全:仅采集公开信息,避免触碰隐私与敏感数据边界
三、2026 年 7 大 AI 网络爬虫工具/方案概览
注:工具更新很快,功能与定价以官方最新信息为准。这里强调定位与使用侧重点,便于你按需组合。
1)Bright Data:企业级抓取平台
定位:面向企业的大规模数据采集与“高对抗”场景(封禁、验证码、地区限制、稳定性 SLA 等)。
核心能力:
-
企业级代理网络,支持多国家/地区出口
-
对复杂站点、访问限制和高并发任务支持较强
-
数据交付形式完整,适合批量采集和下游系统对接
适合人群:中大型团队、跨境业务、强稳定性要求、需要规模化与合规治理项目。
2)Crawl4AI:开源 Python,偏性能与工程化
定位:开发者友好的开源抓取/爬行库,强调效率与可控性,适合把抓取能力做成自家数据管线的一部分。
亮点:
-
支持动态页面处理和多种爬行策略
-
强调抓取效率与可控性
-
适合做自定义数据管线和深度抓取
适合人群:有工程能力、希望抓取融入自家数据平台的团队
3)ScrapeGraphAI:开源 + API,适合“提示词抽取结构化数据”
定位:用“图/管线”把抓取、清洗、LLM 抽取、结构化输出串起来,强调从页面到结构化数据的端到端体验。
亮点:
-
支持多种抓取管线,覆盖单页、多页和搜索结果
-
可结合 schema 进行结构化输出
-
适合接入 RAG、Agent 和自动化工作流
适合人群:RAG/Agent、分析工作流、字段抽取需求多且变化快的项目
4)Firecrawl:API 把网页转成 LLM 友好内容/结构化输出
定位:把抓取、清洗、结构化输出封装成 API,目标是让网页内容“直接可喂给 LLM / 可入库”。
亮点:
-
支持抓取后输出 Markdown、JSON 等格式
-
适合做内容清洗、站点映射和批量处理
-
可直接用于知识库、检索和分析场景
适合人群:需要快速上线、以“内容清洗与交付”为主的团队
5)Browse AI:无代码抓取与监控平台
定位:把“抓取与监控”产品化,让非开发者也能完成:抽取字段、定时运行、结果推送/导出。
亮点:
-
点击式配置,降低使用门槛
-
支持定时任务、结果导出和常见集成
-
更适合做持续监控而不是复杂工程化采集
适合人群:运营/市场/分析类需求,或技术资源有限的小团队
6)LLM Scraper:TypeScript/JavaScript + Playwright + Schema
定位:在 JS/TS 工程体系内,把网页自动化(Playwright)与 LLM 抽取结合,强调结构化与可复用脚本。
亮点:
-
基于 Playwright,可处理复杂交互页面
-
支持 Zod schema 约束输出结构
-
适合工程化集成和强类型项目
适合人群:偏 JS 技术栈、对抽取结构要求严格的项目
7)Jina Reader:把 URL 转成干净文本/Markdown/JSON 的 Reader 类 API
定位:把网页中的核心文本提取出来,去掉脚本、广告等噪音,输出更适合 LLM 使用的内容。
亮点:
-
去除脚本、广告等噪音,提取核心文本
-
输出更适合 LLM 使用的 Markdown/JSON
-
可作为知识库构建前的预处理步骤
适合人群:知识库构建、信息抽取前的文本预处理、轻量采集任务
四、快速对比表(按落地常用维度)
|
方案 |
形态 |
动态渲染/交互 |
结构化抽取 |
上手成本 |
更适合的使用方式 |
|
Bright Data |
企业平台 |
强 |
强 |
中-高 |
大规模稳定采集 |
|
Crawl4AI |
开源 Python |
中-强 |
强 |
中 |
自建管线与策略 |
|
ScrapeGraphAI |
开源+API |
中 |
强 |
中 |
提示词抽取/工作流 |
|
Firecrawl |
API+SDK |
中-强 |
中-强 |
低-中 |
快速清洗与交付 |
|
Browse AI |
无代码平台 |
中 |
中 |
低 |
监控、表格输出 |
|
LLM Scraper |
开源 TS |
强 |
强 |
中 |
JS 工程化抽取 |
|
Jina Reader |
API |
中 |
中 |
低 |
清洗层/预处理 |
五、常见避坑要点(直接影响成功率与成本)
-
别把抽取结果当“最终事实”
对关键字段(价格、时间、评分等)做格式校验与范围校验;尽量保留原文片段,方便回溯核对。 -
先解决“能打开”,再谈“抽得准”
动态站点常见 JS 渲染、滚动加载、弹窗遮挡。需要浏览器渲染、等待关键元素出现,并处理点击/滚动等操作。 -
高并发要做节奏控制与容错
把限速、指数退避、超时、重试、失败队列、幂等设计当作基础设施,才能避免“偶发成功、整体失控”。 -
用结构化约束提升一致性
优先选择支持 schema(如 Pydantic/Zod)的工具,明确字段类型、必填项、枚举值;再配合规则校验,减少脏数据流入下游。 -
采集链路要可观测
记录耗时、失败原因、验证码比例、字段缺失率等指标。很多“抓不到”并非工具问题,而是缺少定位问题的数据。
六、稳定性与全球出口:为什么代理经常是“分水岭”
当抓取规模上来,或者目标站点存在地区差异与反爬限制时,经常会遇到:
-
同一站点在不同国家/地区返回内容不同(价格、库存、展示信息差异)
-
访问频率提高后出现限速、验证、短期封禁
-
部分页面对特定网络环境不稳定或不可访问
因此,很多团队会在采集链路中加入“网络出口能力”,用于 地区选择、IP 轮换、会话保持与失败切换。这通常是为了让对公开信息的采集更稳定、可控,而不是把抓取建立在“碰运气”上。
在代理服务选择上,如果你需要覆盖多场景与多类型出口,可以考虑 IPFoxy 代理服务。IPFoxy 提供的产品类型包括:
-
静态独享数据中心 IPv4 / IPv6 代理
-
静态住宅 ISP 代理
-
动态住宅代理
-
动态移动代理
可用于网页数据抓取代理、市场研究、SEO 监控、价格对比、社交媒体营销、广告验证、品牌保护等业务场景,为全球范围业务提供代理支持。
七、Python 配置动态代理
配置前请注意:Python 需要在海外网络环境下执行,才能使代理生效。
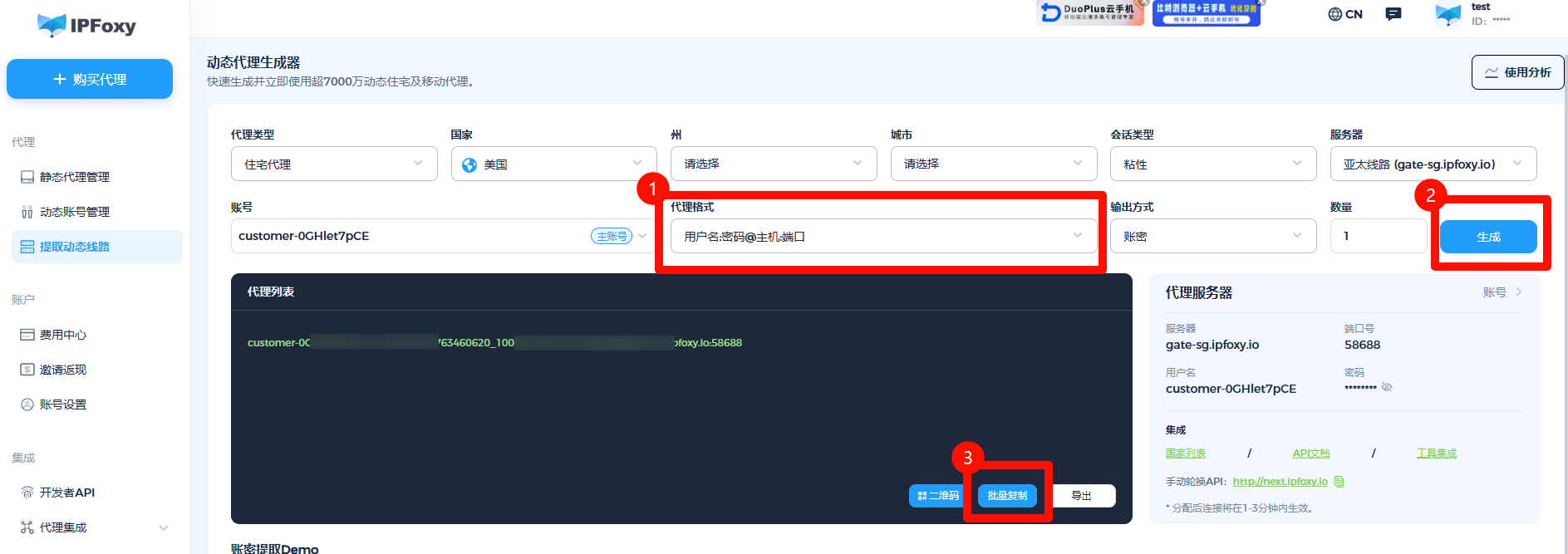
1)页面生成代理连接信息
进入IPFoxy【动态住宅代理】页面,按下列方式生成:
-
协议类型:
http -
格式:
Username:Password@Host:Port -
生成代理
-
复制连接信息
示例:username:password@gate-us-ipfoxy.io:58688
2)Python 代码示例(urllib)
将连接信息粘贴到代码中:
复制代码
import urllib.request
if __name__ == '__main__':
proxy = urllib.request.ProxyHandler({
'https': 'username:password@gate-us-ipfoxy.io:58688',
'http': 'username:password@gate-us-ipfoxy.io:58688',
})
opener = urllib.request.build_opener(proxy, urllib.request.HTTPHandler)
urllib.request.install_opener(opener)
content = urllib.request.urlopen('http://www.ip-api.com/json').read()
print(content)执行后可通过输出确认出口 IP 已改变,用于验证代理配置是否生效。

总结
AI 网络爬虫的核心价值是降低维护成本、加快结构化数据交付,但要稳定落地,需要同时处理动态渲染、限速与容错、结构化校验,以及在必要时补齐地区出口与 IP 轮换能力。选工具时建议从“你的目标站点类型、规模、预算与技术栈”出发:清洗型 API 适合快速交付,自建开源库适合可控扩展,而面向高对抗与全球化的采集则更依赖完善的代理与稳定性设计。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 14
14 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)