大模型不同模型格式入门指南
本文深入探讨了大模型文件的核心构成,包括权重、架构配置、分词器和优化器状态,并详细解析了四大主流格式(PyTorch、Safetensors、GGUF、ONNX)的特点、优缺点及适用场景。重点介绍了Safetensors的安全性和高效性,GGUF的单文件打包和量化优势,以及ONNX的跨框架兼容性。此外,还补充了量化的概念及其对模型性能和资源占用的影响,为读者提供了实用的模型文件格式选型建议。
一、模型文件里到底装了什么?
很多人一上来就纠结格式,其实更重要的是先理解:一个"模型文件"本质上只是一堆数字。
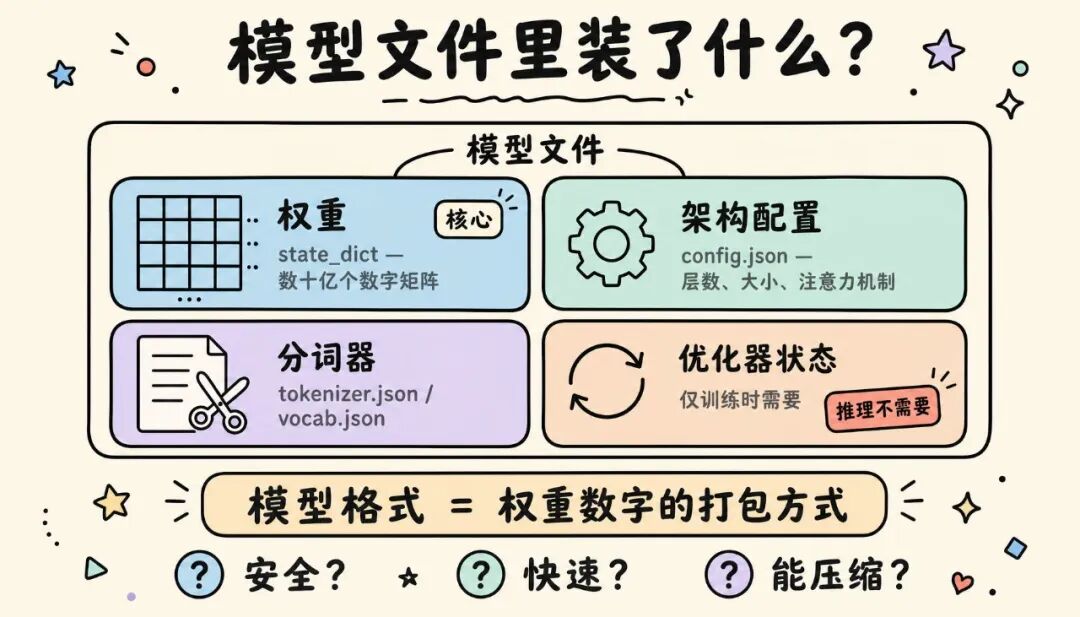
一个训练好的大模型,通常包含这几样东西:
-
- 权重(Weights/参数)——这是模型的"大脑",就是几十亿个数字。它本质上是一张"名字→数字矩阵"的对照表。PyTorch里管这张表叫
state_dict。
- 权重(Weights/参数)——这是模型的"大脑",就是几十亿个数字。它本质上是一张"名字→数字矩阵"的对照表。PyTorch里管这张表叫
-
- 架构配置(Config)——告诉程序这个模型有多少层、每层多大、用什么注意力机制等。通常存在一个
config.json里。
- 架构配置(Config)——告诉程序这个模型有多少层、每层多大、用什么注意力机制等。通常存在一个
-
- 分词器(Tokenizer)——负责把文字切成模型能理解的"词元",相关文件如
tokenizer.json、vocab.json、merges.txt。
- 分词器(Tokenizer)——负责把文字切成模型能理解的"词元",相关文件如
-
- 优化器状态(OptimizerState)——只在训练时需要,用来"断点续训"。纯推理(用模型生成文字)时完全用不到。
关键认知:所谓"模型格式",其实是在讨论"权重这堆数字用什么方式打包成文件"。
不同格式的差别,归根结底是在回答三个问题:
- • 打包方式安不安全?
- • 加载快不快、省不省显存?
- • 能不能顺便把数字"压缩"一下(量化)?
理解了这一点,后面所有格式的区别就都好懂了。
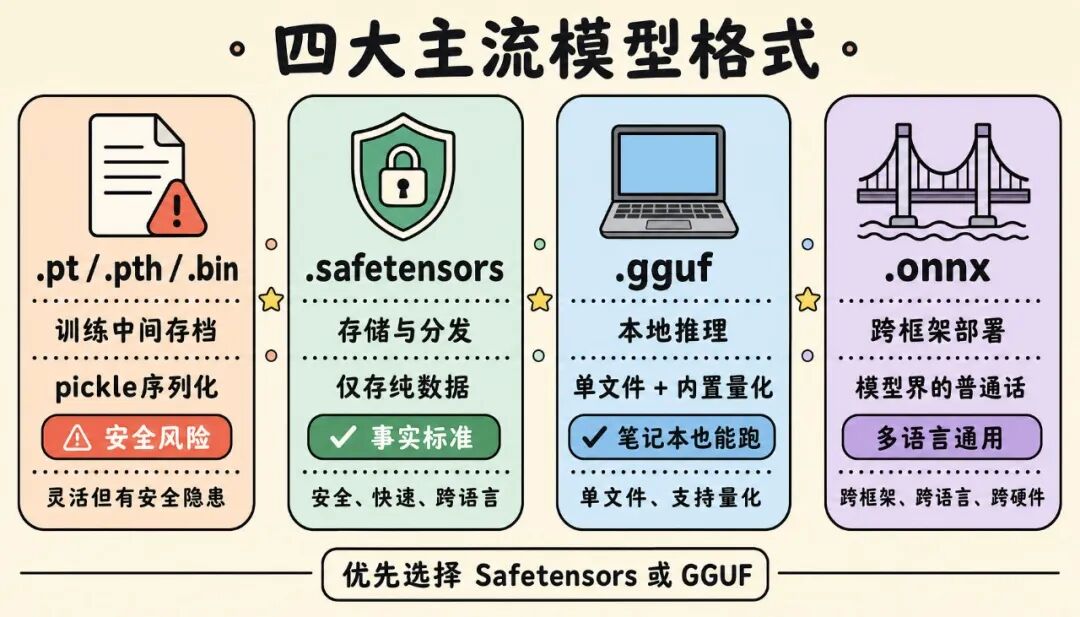
二、四大主流格式速览
| 格式 | 扩展名 | 谁开发的 | 主要用途 | 一句话印象 |
|---|---|---|---|---|
| PyTorch/Pickle | .pt / .pth/ .bin |
PyTorch | 训练时的中间存档 | 老格式,灵活但有安全隐患 |
| Safetensors | .safetensors |
HuggingFace | 存储与分发权重 | 安全、加载快,现在的事实标准 |
| GGUF | .gguf |
llama.cpp项目 | 本地跑模型(推理) | 单文件、支持量化、笔记本也能跑 |
| ONNX | .onnx |
微软等联合 | 跨框架部署 | 让模型能在不同框架/语言间通用 |
三、逐个详解
1.PyTorch格式(.pt/.pth/.bin)——最老的"原住民"
它是什么
PyTorch是最流行的深度学习训练框架。当你用torch.save()保存一个模型时,得到的就是.pt或.pth文件(.bin也常见,只是换了个后缀,内核一样)。
它底层用的是Python的pickle序列化机制。
举个栗子
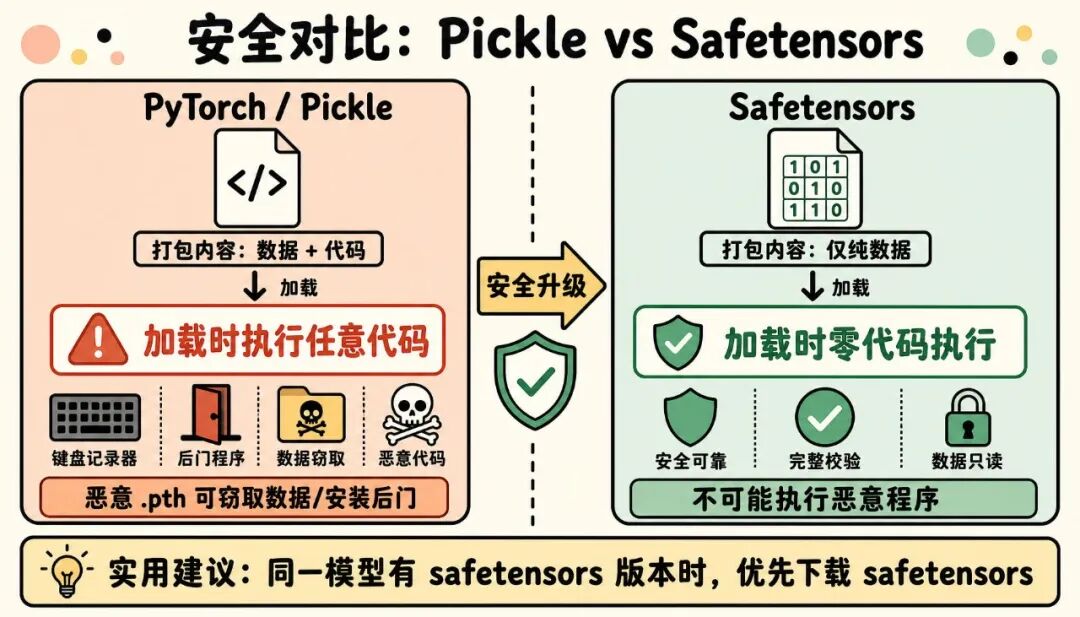
pickle 如同捆绑运行逻辑的打包文件,打包时连带对象运行环境、执行逻辑一并封存,本地自用便捷,外部文件存在代码注入安全隐患。
最大的问题:安全风险
因为pickle在加载时会执行里面附带的代码,所以一个被恶意篡改的.pth文件,在你运行torch.load()的那一刻,就可能在你电脑上偷偷执行任意命令——比如窃取数据、安装后门。
安全研究人员也确实在HuggingFace这样的可信平台上发现过植入了后门的恶意.pth文件,它们在被加载时会下载并运行木马程序。PyTorch官方文档自己也提醒:torch.load()默认方式容易受到反序列化攻击。
实用建议:只从你信任的来源加载
.pt/.pth/.bin文件。如果同一个模型同时提供了safetensors版本,优先下载safetensors。
2.Safetensors(.safetensors)——现在的"事实标准"
它是什么
Safetensors是HuggingFace专门为了解决上面pickle安全问题而开发的格式。名字直白——“safetensors”,安全的张量。
它好在哪
- • 安全:它只存"纯数据",不存任何代码,所以加载时不可能执行恶意程序。这是它取代pickle的核心原因。
- • 快:支持内存映射加载(memory-mapping/mmap)。打个比方——传统加载像是"先把整本书搬进房间才能读",而mmap像是"书还在书架上,需要哪页才翻哪页"。这意味着加载一个70B的大模型不会一下子撑爆你的内存。
- • 跨语言:不像pickle那样死绑Python,其他编程语言也能读写。
优点:安全、加载快、省内存、跨语言。
缺点:它只管"存权重",本身不像GGUF那样把分词器、配置都打包进去(这些通常是同目录下的几个独立文件)。
适合场景:训练框架的默认存储格式;在网上分享、从HuggingFace下载模型——基本都用它。如今主流训练库默认就用safetensors存取权重。
3.GGUF(.gguf)——为"在自己电脑上跑"而生
它是什么
GGUF全称GPT-GeneratedUnifiedFormat,由llama.cpp项目的作者GeorgiGerganov创建,是更早的GGML格式的继任者。
如果你听人说"我在自己笔记本上跑了个本地大模型",那他大概率使用的是GGUF格式(使用Ollama或者LM studio推理)。
它的三大特点
1.单文件:把权重、分词器、配置元数据全部打包进一个文件。下载一个.gguf就够了,不用管一堆零碎文件。非常方便分享。
2.内置量化(杀手锏):GGUF天生支持把模型"压缩"。这是它最强的能力,下一节详细讲。
3.为推理优化:专门为在普通硬件(CPU、消费级显卡、苹果芯片)上高效运行而设计。
举个栗子
以阿里Qwen3.5系列为例——它既有Qwen3.5-397B-A17B这样的大家伙,也有Qwen3.5-9B、乃至Qwen3.5-2B/0.8B这些小尺寸模型。大模型未压缩时需要的显存普通人根本扛不住;但转成GGUF并用Q4量化后,对内存的需求会大幅下降,一台高配的个人电脑就有机会跑起来。而像Qwen3.5-4B、Qwen3.5-9B这种小尺寸模型,量化成GGUF后在普通笔记本上跑得很轻松。
它被哪些工具支持:llama.cpp、Ollama、LMStudio等几乎所有主流"本地跑模型"的工具。GGUF最初主要用于语言模型,但现在也越来越多地用于图像生成、多模态等其他类型的模型。
优点:单文件好分享;加载快(同样支持mmap);量化方案灵活;二进制格式,不依赖特定库也能读。
缺点:大多数模型需要从PyTorch/safetensors转换而来,且不是所有模型都能转;模型一旦存成GGUF,再想微调(继续训练)就很麻烦。
适合场景:在本地(自己电脑)运行模型做推理;在开源社区分享现成可用的模型。
4.ONNX(.onnx)——跨框架的"普通话"
它是什么
ONNX(OpenNeuralNetworkExchange,开放神经网络交换格式)的目标是当一种"通用语":让在A框架(比如PyTorch)里训练的模型,能拿到B框架(比如TensorFlow)或别的运行环境里去用。
一个比喻:如果说PyTorch格式像"只有中文版的说明书",ONNX就像"翻译成多国语言的通用版",方便在C++、.NET、Java等不同语言和各种硬件加速器上部署。
优点:轻量、跨平台、在CPU/GPU上推理快。
缺点:从其他格式转换成ONNX时,偶尔会出现性能差异或兼容性问题。
适合场景:需要把模型部署到非Python环境,或需要在多种硬件上跑。对纯粹学LLM的初学者来说,ONNX接触得相对少一些,了解概念即可。
四、补个课:量化(Quantization)到底是什么?
因为GGUF文件名里那串神秘后缀(Q4_K_M、Q8_0……)可能会让很多人疑惑,这里专门讲清楚。
量化的基本原理
模型的每个权重,默认用16位浮点数(FP16/BF16存储,每个数占2个字节。
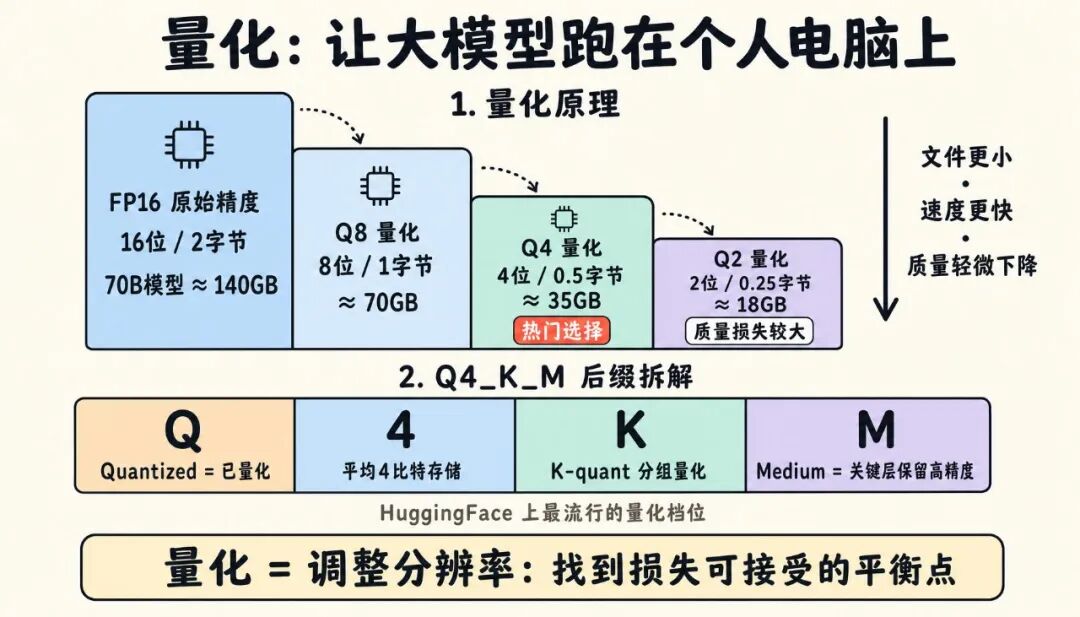
量化就是把这些数字用更少的位数来近似表示——比如压成8位、4位甚至2位的整数。
一个好理解的比喻:量化就像调整图片分辨率。高分辨率(FP16)最清晰但文件大;降低分辨率(Q4)文件小很多、加载快,但画质会有一点损失。关键是找到"损失可以接受"的那个平衡点。
量化带来的好处:文件更小、占用内存更少、生成速度更快——代价是模型质量会有轻微下降。正因为有量化,原本需要专业数据中心才能跑的模型,才能塞进你的游戏本甚至手机。
举个对比就很清楚:像DeepSeek-V4、KimiK2.5这类参数动辄上千亿、上万亿的旗舰模型,普通人本地基本跑不动;而经过量化的中小模型——比如Qwen3.5-27B——压成4位后,一台带独显的家用电脑甚至高配笔记本就能流畅运行。量化就是把"大模型"和"个人硬件"之间那道鸿沟填上的关键技术。
看懂GGUF的量化后缀
以Q4_K_M为例拆解:
| 部分 | 含义 |
|---|---|
| Q | Quantized,表示这是量化过的 |
| 4 | 平均每个权重用约4个比特存储(数字越小,压得越狠、文件越小、质量损失越大) |
| K | 采用"K-quant"分组量化方案,比老式量化更聪明 |
| M | 档位:S(small)/M(medium)/L(large)。同样位数下,会对模型里更重要的层保留更高精度。M是常见的均衡选择 |
所以Q4_K_M的意思就是:4位的混合精度K-quant量化——平均4位,但关键层保留更高精度这是目前HuggingFace上最流行的量化档位。
以Qwen3.5-27B模型为例,该选哪个档位?(仅供参考)
| 你的显存(VRAM) | 推荐档位 | 说明 |
|---|---|---|
| 低于12GB | Q2_K / Q3_K_M | 仅能在低上下文(≤2K)下勉强运行,需同时开启内存交换,模型质量损失较明显,仅适合测试/学习用途,不推荐作为主力使用 |
| 12–16GB | Q3_K_M / Q4_K_S | 以Q3_K_M为主,可稳定运行4K上下文;Q4_K_S需严格限制上下文(≤2K),显存压力较大,模型质量损失较小 |
| 16–20GB | Q4_K_M(强烈推荐) | 27B模型的性价比之王!权重约16.5GB,搭配4K上下文总显存占用约18–20GB,在24GB显存的RTX 3090/4090上可流畅运行,质量损失较小 |
| 20–24GB | Q5_K_M / Q6_K | 更高精度选择:Q5_K_M(19.4GB权重)可稳定跑8K上下文;Q6\_K(22.1GB权重)在24GB卡上建议限制上下文≤4K,模型质量更接近原始版本 |
| 24GB以上 | Q8_0 | Q8_0(~28.9GB权重)需≥32GB显存才能流畅运行; |
特别提醒(涉及MoE模型):现在很多模型采用MoE(混合专家)架构——比如Qwen3.5系列里型号名带"A"的那些(如Qwen3.5-35B-A3B、Qwen3.5-122B-A10B,“A"后面的数字表示每次推理实际激活的参数量)。MoE模型本身就比较"稀疏”,对激进量化更敏感,建议别用低于Q5的档位,否则被选中的"专家"精度不够,输出质量会明显下滑。普通的稠密模型(如Qwen3.5-9B)则没这个顾虑。
五、总结:到底什么时候用哪个?
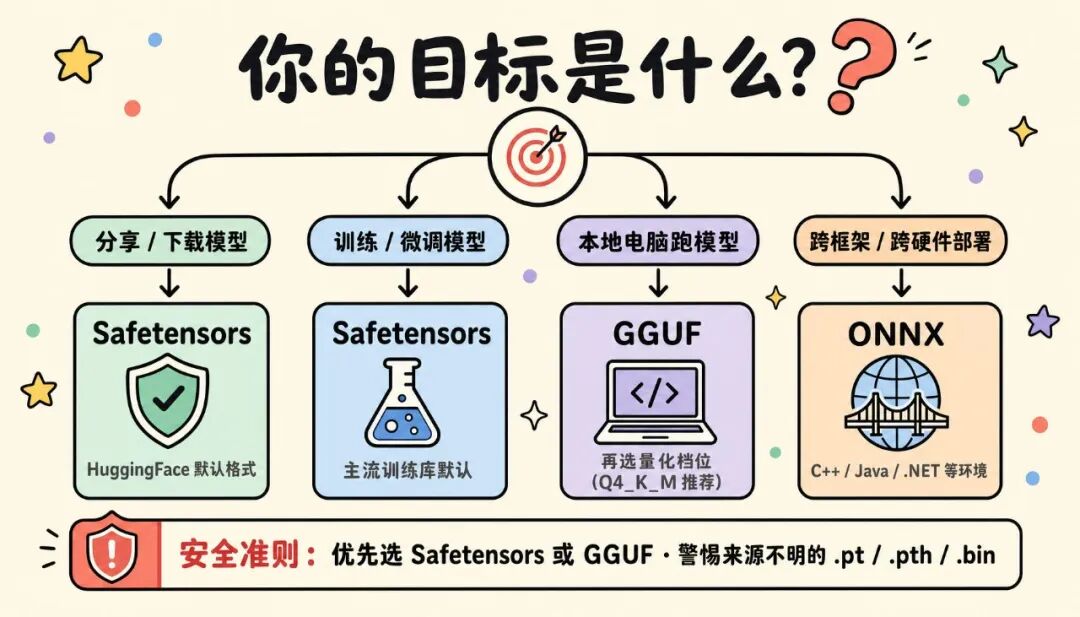
| 你的目标 | 推荐格式 |
|---|---|
| 在网上分享模型,或从HuggingFace下载 | Safetensors |
| 训练/微调模型,需要保存和加载权重 | Safetensors (主流训练库默认) |
| 在自己电脑(笔记本/消费级显卡/CPU)上跑模型 | GGUF (再选合适的量化档位) |
| 需要跨框架、跨语言、跨硬件部署 | ONNX |
| 在自己完全可信的环境里做训练中间存档 | .pt /.pth可以,但要小心来源 |
安全准则:使用别人的模型文件,优先选safetensors或GGUF;对来源不明的.pt/.pth/.bin需要警惕。
说真的,这两年看着身边一个个搞Java、C++、前端、数据、架构的开始卷大模型,挺唏嘘的。大家最开始都是写接口、搞Spring Boot、连数据库、配Redis,稳稳当当过日子。
结果GPT、DeepSeek火了之后,整条线上的人都开始有点慌了,大家都在想:“我是不是要学大模型,不然这饭碗还能保多久?”
我先给出最直接的答案:一定要把现有的技术和大模型结合起来,而不是抛弃你们现有技术!掌握AI能力的Java工程师比纯Java岗要吃香的多。
即使现在裁员、降薪、团队解散的比比皆是……但后续的趋势一定是AI应用落地!大模型方向才是实现职业升级、提升薪资待遇的绝佳机遇!
这绝非空谈。数据说话
2025年的最后一个月,脉脉高聘发布了《2025年度人才迁徙报告》,披露了2025年前10个月的招聘市场现状。
AI领域的人才需求呈现出极为迫切的“井喷”态势
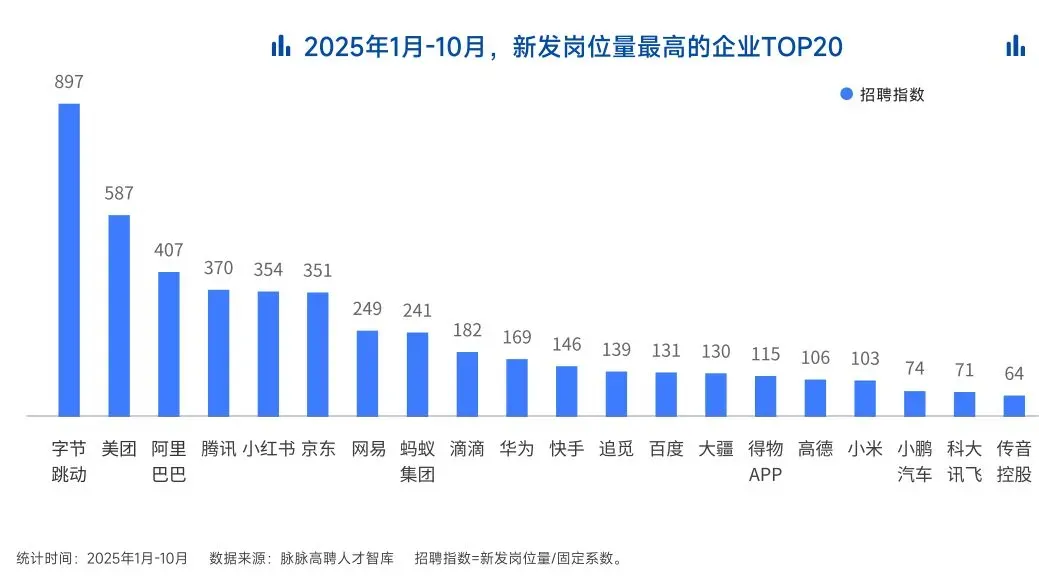
2025年前10个月,新发AI岗位量同比增长543%,9月单月同比增幅超11倍。同时,在薪资方面,AI领域也显著领先。其中,月薪排名前20的高薪岗位平均月薪均超过6万元,而这些席位大部分被AI研发岗占据。
与此相对应,市场为AI人才支付了显著的溢价:算法工程师中,专攻AIGC方向的岗位平均薪资较普通算法工程师高出近18%;产品经理岗位中,AI方向的产品经理薪资也领先约20%。
当你意识到“技术+AI”是个人突围的最佳路径时,整个就业市场的数据也印证了同一个事实:AI大模型正成为高薪机会的最大源头。
最后
我在一线科技企业深耕十二载,见证过太多因技术卡位而跃迁的案例。那些率先拥抱 AI 的同事,早已在效率与薪资上形成代际优势,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在大模型的学习中的很多困惑。
我整理出这套 AI 大模型突围资料包【允许白嫖】:
- ✅从入门到精通的全套视频教程
- ✅AI大模型学习路线图(0基础到项目实战仅需90天)
- ✅大模型书籍与技术文档PDF
- ✅各大厂大模型面试题目详解
- ✅640套AI大模型报告合集
- ✅大模型入门实战训练
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

①从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点

② AI大模型学习路线图(0基础到项目实战仅需90天)
全过程AI大模型学习路线
③学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的

④各大厂大模型面试题目详解

⑤640套AI大模型报告合集

⑥大模型入门实战训练

👉获取方式:
有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 2
2 0
0- 0



 已为社区贡献151条内容
已为社区贡献151条内容

所有评论(0)