【论文阅读】Stable Video Infinity: Infinite-Length Video Generation with Error Recycling
快速了解部分
基础信息(英文):
1.题目: Stable Video Infinity: Infinite-Length Video Generation with Error Recycling
2.时间: 2025.10
3.机构: EPFL
4.3个英文关键词: Video Generation, Diffusion Transformer (DiT), Error Accumulation
1句话通俗总结本文干了什么事情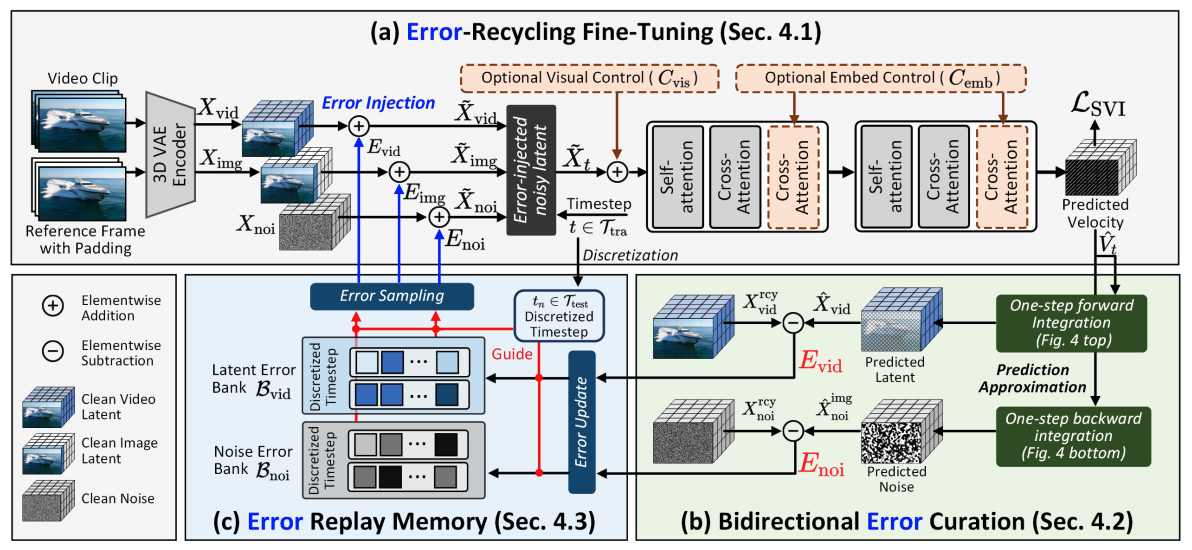
本文提出了一种名为 Stable Video Infinity (SVI) 的方法,通过“循环利用”模型自己犯的错误来训练视频生成模型,从而实现无限长度、高质量且画面连贯的视频生成。
研究痛点:现有研究不足 / 要解决的具体问题
现有长视频生成方法在生成长视频时会出现“画面漂移”(Drifting)和质量下降,这是因为模型在训练时只见过完美的干净数据,但在生成视频(测试)时却必须基于自己上一步生成的、带有瑕疵的画面进行预测,这种“训练与测试的假设不一致”导致错误不断累积放大。
核心方法:关键技术、模型或研究设计(简要)
提出 Error-Recycling Fine-Tuning (ERFT),即在训练时故意将模型过去生成的错误(如模糊、色偏)重新注入到干净的训练数据中,让模型学会如何识别并纠正这些自己犯下的错误,从而适应无限长度的自回归生成。
深入了解部分
作者想要表达什么
作者认为解决长视频生成的核心不在于如何“避免”错误,而在于如何让模型学会“容忍并纠正”自己犯下的错误。通过打破“训练数据必须完美”的假设,让模型在训练时就习惯处理带有自身瑕疵的画面,从而在推理时能实现无限长度的稳定生成。
相比前人创新在哪里
前人工作多关注于修改采样器、增加锚点帧或调整噪声调度来“缓解”错误累积,这只能治标;本文创新在于直接针对“训练-测试假设不一致”这一根本病因,通过“错误循环利用”让模型具备了主动“修复”自身错误的能力,且不增加推理成本,支持无限长度。
解决方法/算法的通俗解释
这就像是教一个学画画的学生。传统方法是只让他临摹大师的完美作品(训练),但他一旦自己创作(测试)出现笔误就无法收场。本文的方法是在训练时,故意在他画错的画上继续让他练习,或者把他的常见错误(如画歪的眼睛)P到新的画纸上让他重画,逼着他学会如何修正错误,从而成为一个能独立完成长篇巨作的画家。
解决方法的具体做法
- 错误注入:在训练阶段,随机将模型过去生成的错误(存放在 Replay Memory 中)叠加到当前的干净视频帧、噪声和参考图上。
- 双向误差计算:通过单步积分快速估算模型在错误干扰下的预测偏差。
- 动态存储与采样:建立一个错误回放缓冲区,动态存储不同时间步的错误,并在训练时随机采样注入,模拟长期累积的复杂错误。
- LoRA微调:仅使用 LoRA 对 DiT 模型进行微调,预测“错误回收后的速度”,使模型指向干净的潜在变量。
基于前人的哪些方法
基于 Video Diffusion Transformer (DiT) 架构;利用了 Flow Matching (流匹配) 理论;借鉴了 Federated Learning (联邦学习) 中的思路用于错误缓冲区的更新;兼容并扩展了现有的条件控制方法(如 Audio, Skeleton control)。
实验设置、数据、评估方式、结论
设置:建立了三个基准测试(一致性生成、创意生成、多模态条件生成),包含50秒至250秒的超长视频。
数据:使用了 MixKit, Hallo 3, TikTok 等数据集进行微调(数据量较小,约300-6k视频)。
评估:使用 Vbench++ 的6项核心指标(主题一致性、背景一致性、美学质量等)及特定指标(Sync-C, FVD)。
结论:SVI 在保持高质量和高动态性的同时,显著优于 Wan 2.1、StreamingT2V 等 SOTA 方法,实现了无限长度生成且无明显质量下降。
提到的同类工作
StreamingT2V, HistoryGuidance, FramePack, Wan 2.1, Self-Forcing++, LoViC, LongLive.
和本文相关性最高的3个文献
- StreamingT2V (Henschel et al., 2025) <2025.02>
- Wan 2.1 (Wang et al., 2025a) <2025.03>
- Self-Forcing (Huang et al., 2025) <2025.06>
我的
- 长视频生成工作,思想很好。主要思想就是先生成一个长视频,后面会有ERROR,把这些ERROR存下来,在训练模型的时候把ERROR注入,让模型知道有这个ERROR的时候如何生成好视频。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 4
4 0
0- 0



 已为社区贡献36条内容
已为社区贡献36条内容

所有评论(0)