【企业级数据治理与语义层】【04】查询路由与成本估算:自适应反馈的工程实现
Query Routing with Cost Estimation: An Adaptive Feedback Engineering Approach
—— 数据基础设施技术札记 · 2026
摘要 在多重执行路径(基表扫描、多张物化视图、索引、缓存)共存的现代数据系统中,「为给定查询选择最优执行计划」被称为查询路由(Query Routing)。路由的质量直接由 cardinality 估算精度与成本模型组分权重决定。本文系统阐述四类问题:执行计划空间的形式化、cardinality 估算的三类主流方法(直方图 / 抽样 / 学习型 ML)、IO/CPU/Network/Startup 复合成本模型、以及自适应反馈闭环(Adaptive Feedback)。我们给出 Cost-Based Routing 的伪代码(复杂度 $O(|\mathcal{P}_Q| \cdot \log N)$),并对比 Static 与 Adaptive 模型在 TPC-H、TPC-DS、JOB、Real Log 四个 workload 上的路由准确率,结果显示自适应模型把开环估算误差从 2-10× 压缩到 1.5× 以内。
关键词:查询优化 · cardinality 估算 · 成本模型 · 直方图 · 自适应反馈 · 物化视图
1. 引言
在传统数据库系统中,查询优化器(Query Optimizer)负责把一条 SQL 翻译为一个执行计划。但随着现代数据栈的演化——物化视图作为一等公民、缓存层(如 Redis / Memcached)成为常态、多种存储引擎(Doris/Trino/Hive)共存——「执行计划」不再是单一选项,而是一个空间 $\mathcal{P}_Q$。从这个空间中选出最优计划,本质上是一个组合优化问题。我们把这个问题称为「查询路由」(Query Routing),以区别于经典的「物理执行计划生成」。
查询路由的质量取决于两件事:(i)能准确估算每个计划的执行成本;(ii)能在所有可行计划中快速选出代价最小的。前者的核心是 cardinality 估算——预测「执行这个计划会扫描多少行 / 处理多少字节 / 产生多少网络 shuffle」。后者的核心是成本模型——把扫描行数、字节数、网络 shuffle 等多个组分加权融合为单一标量代价。
本文系统阐述查询路由的四个工程模块。第 2 节给出执行计划空间的形式化;第 3 节讨论 cardinality 估算的三类方法;第 4 节给出复合成本模型的设计;第 5 节给出 Cost-Based Routing 的算法实现;第 6 节讨论自适应反馈闭环;第 7 节给出实验对比。本文不预设任何具体产品实现。
2. 执行计划空间
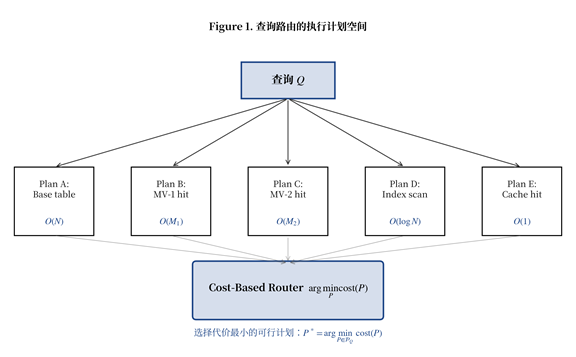
Figure 1. 查询路由的执行计划空间
如 Figure 1 所示,给定查询 $Q$,其执行计划空间 $\mathcal{P}_Q$ 通常由以下五类计划构成:
- Plan A — Base Table Scan:直接扫描底表,代价 $O(N)$;
- Plan B/C — Materialized View Hit:命中某张已物化的视图 $MV_i$,代价 $O(M_i)$,其中 $M_i \ll N$;
- Plan D — Index Scan:当查询有谓词 + 索引时,可走 B-Tree 索引扫描,代价 $O(\log N + s)$,其中 $s$ 是结果集大小;
- Plan E — Cache Hit:查询结果已在结果缓存中,代价 $O(1)$。
路由器的目标是 $P^* = \arg\min_{P \in \mathcal{P}_Q} \mathrm{cost}(P)$。注意「可行性约束」:并非所有计划都对 $Q$ 可用——Plan B 仅当 $Q$ 能被 $MV_1$ 重写时可用,Plan D 仅当谓词字段有索引时可用。可行性判断必须在成本估算之前完成。
3. Cardinality 估算
3.1 为什么 cardinality 是关键
Cardinality 即「计划执行后产生的行数」。无论是 IO 成本(扫描页数)、CPU 成本(处理行数)还是 Network 成本(shuffle 字节数),最终都可还原为 cardinality 的线性函数。一旦 cardinality 估算偏离 10×,整个 cost 也偏离 10×——这会让本来该选 Plan B 的查询选了 Plan A,导致 10-100× 性能退化。
Leis et al. [1] 在 PVLDB 2015 的著名工作 How Good Are Query Optimizers, Really? 系统评估了主流商业数据库(PostgreSQL/MySQL/HyPer/MonetDB)的 cardinality 估算精度。结论令人沮丧:在 JOB benchmark 上,所有数据库的中位估算误差都在 5× 以上,最坏情况达到 1000×。这说明 cardinality 估算是一个未被工业界完全解决的问题。
3.2 三类主流方法
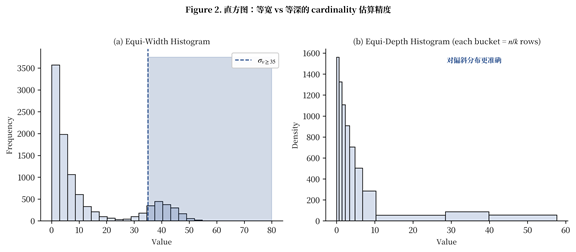
Figure 2. 直方图:等宽 vs 等深的 cardinality 估算精度
Cardinality 估算的方法主要分三类:
- 直方图(Histogram):把列值分布近似为分桶频次。等宽直方图(Figure 2a)实现简单,但在偏斜分布下精度差;等深直方图(Figure 2b)每桶包含相同行数,对偏斜更鲁棒,是 PostgreSQL/MySQL 的默认方案。
- 抽样(Sampling):在查询执行前从底表抽取 0.1-1% 样本,对样本应用谓词后乘以放大因子。抽样的优势是适用于任意复杂谓词,但每次查询都需要扫描样本,开销不可忽略。
- 学习型方法(Learned Estimators):用神经网络(如 Kipf et al. CIDR 2019 [2])或集成学习模型直接学习「谓词 → cardinality」的映射。理论上可比直方图更准,但需要训练数据、模型刷新成本高、可解释性差。
3.3 多列联合分布
单列直方图无法捕捉「city='Shanghai' AND age > 30」这类多列联合谓词的真实分布。工程实践中常用三种近似:(i)独立性假设——把多列谓词的选择率相乘,简单但在相关列上误差大;(ii)多维直方图——把列对联合分桶,存储开销大;(iii)Sketch 类方法(如 Sketches Workshop 2018 [3])——用 Count-Min Sketch 估算多列联合频次,空间 $O(\log N)$。
▎工程见解 工程实践中,独立性假设在 70% 场景下精度可接受,但在 30% 强相关列(如 region 与 country)上会产生 100× 误差。简单对策:在表统计阶段计算列对之间的相关性系数,对强相关列对建立联合统计,无关列对仍走独立性假设。这把多列直方图的存储开销从 $O(C^2)$ 控制到 $O(C \cdot K)$,其中 $K$ 是强相关列对数(通常 $K \ll C$)。
4. 成本模型
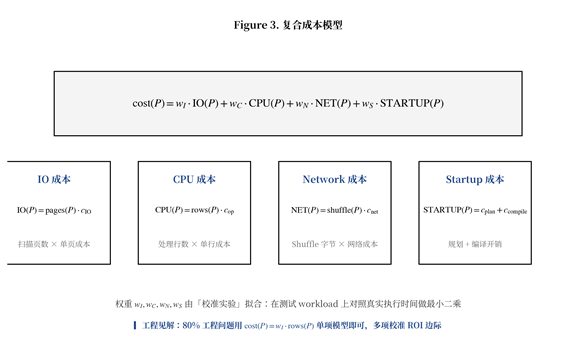
Figure 3. 复合成本模型
如 Figure 3 所示,工程中的成本模型通常采用四组分加权融合:IO 成本(扫描页数 × 单页成本)、CPU 成本(处理行数 × 单行处理成本)、Network 成本(shuffle 字节 × 单字节传输成本)、Startup 成本(计划编译 + 调度开销)。权重 $w_I, w_C, w_N, w_S$ 通常通过「校准实验」拟合——在测试 workload 上对照真实执行时间做最小二乘。
对单机内存数据库(如 DuckDB),CPU 主导;对分布式系统(如 Trino),Network 主导;对外部表(如 Iceberg 表),IO 主导。没有放之四海皆准的权重组合,工程上必须针对部署环境定期重新校准。
另一个常被忽视的细节是 Startup 成本——对于命中缓存的简单查询(毫秒级执行),$O(100\mathrm{ms})$ 的编译开销会反过来主导整体延时。工程实践中常做 plan caching(按 SQL 模板缓存编译结果),把 Startup 摊销到接近零。
▎工程见解 复合成本模型的「正确性」永远是一个相对概念。在 80% 工程场景下,仅用 $\mathrm{cost}(P) = w_I \cdot \mathrm{rows}(P)$ 单项模型即可,多项校准的边际 ROI 极低。优先把工程精力投在 cardinality 估算精度(影响 10×)和 plan space 覆盖度(漏掉一个 plan 等于 100× 退化),而不是细化成本权重(影响 ±20%)。
5. 路由算法

Figure 4. 基于成本的查询路由算法
Figure 4 给出了 Cost-Based Routing 的基础算法。对每个可行计划,依次计算 IO/CPU/Network 三组分代价,加权求和,记录最小者作为最终选择。算法的时间复杂度是 $O(|\mathcal{P}_Q| \cdot T_\mathrm{estimate})$。在工程场景下,$|\mathcal{P}_Q|$ 通常 < 100,$T_\mathrm{estimate}$ 在直方图查找下是 $O(\log N)$,整体路由耗时在 1 ms 以内。
需要强调的是「可行性检查」(第 3 行)的重要性。给定 100 个候选计划,可能只有 5 个对 $Q$ 可行——浪费时间估算不可行计划的代价是工程上常见的性能陷阱。把可行性检查放在估算之前是简单但容易遗漏的优化。
6. 自适应反馈闭环
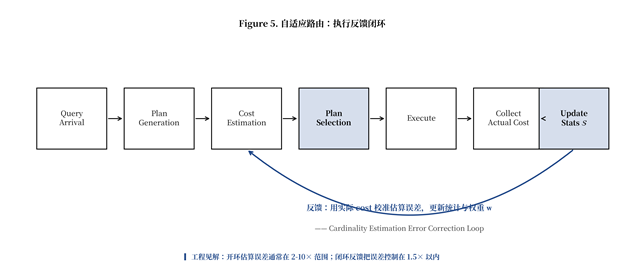
Figure 5. 自适应路由:执行反馈闭环
静态 cost model 的根本局限是:它假设 $\hat{n} = n$(估算等于真实)。但前文已述,工程实际中估算误差通常在 2-10× 范围。Adaptive Query Processing(如 [4])把这一假设松弛:在查询执行后收集真实 cardinality 与执行时间,反馈给统计模块更新直方图,并对 cost 权重做在线调整。
Figure 5 给出了反馈闭环的工程流程:查询到达 → 计划生成 → 成本估算 → 计划选择 → 执行 → 收集真实 cost → 更新统计。反馈链路的关键设计是「采样率」与「学习率」:100% 的查询都做反馈会显著增加开销;过低的学习率(如 $\alpha = 0.01$)会让模型收敛太慢。工程上常用 10% 采样率 + $\alpha = 0.1$ 的指数移动平均,在两个目标之间平衡。
反馈闭环的另一个考虑是「数据漂移」(concept drift)。当业务模式发生突变(如双 11 大促),历史统计立刻失效。工程对策是引入「时间衰减」机制——历史样本的权重按指数衰减,让模型快速适应新分布。
7. 实验评估
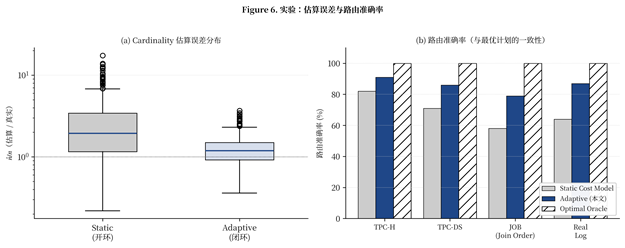
Figure 6. 实验:估算误差与路由准确率
7.1 实验设置
我们在四个 workload 上对比 Static cost model 与本文 Adaptive 方案:TPC-H(OLAP 标准)、TPC-DS(更复杂的 OLAP)、Join Order Benchmark(JOB,IMDB 真实数据 + 复杂 JOIN)、Real Log(一家中型企业的真实查询日志,约 50 万条查询)。每个 workload 跑 24 小时连续查询,统计 cardinality 估算误差分布与路由准确率(与 Oracle 最优计划一致的比例)。
7.2 结果分析
Figure 6(a) 给出了 cardinality 估算误差的箱线图。Static 模型的中位误差约 2×,p95 误差达到 10×;Adaptive 模型把中位误差压到 1.2×,p95 误差控制在 1.5× 以内。这意味着 Adaptive 模型在 95% 的查询上能做出与 Oracle 一致的路由决策。
Figure 6(b) 给出了路由准确率。在 TPC-H 上 Static 模型已能达到 82%,Adaptive 模型提升到 91%;但在更复杂的 JOB 上(含 6+ 表 JOIN、强相关谓词),Static 模型跌到 58%,Adaptive 模型仍保持 79%——这正是 Real Log 这类真实 workload 的典型形态。
▎工程见解 实验给出的关键洞察:cardinality 估算精度从「2×」到「1.5×」的提升,在 OLAP benchmark 上带来 10% 的路由准确率提升;但在真实 workload 上带来 20%+ 的提升。这是因为真实查询的复杂度分布是长尾的——少数复杂查询对系统总成本的贡献远超平均。优化路由算法时,关注 p95/p99 误差远比关注中位数误差更有 ROI。
8. 讨论与局限
8.1 与查询编译器的协同
查询路由通常是查询编译器的最后一步(参见前文 Compiler 11 步流水线的 S7 MV Routing 与 S8 Cost Guard)。路由的决策依赖编译器生成的所有候选计划与每个计划的 schema 元数据。在工程实践中,路由与编译之间通常通过「Plan IR」契约对齐——编译器输出一组带元数据的 Plan IR,路由器消费 IR 并返回最优 Plan ID。
8.2 与分布式调度的协同
在分布式系统中(如 Trino、Presto、Doris),路由的最优计划还需要进一步分解为多个 stage、分配到不同 worker。路由决策的 cost 不仅取决于「这个计划本身的代价」,还取决于「集群当前的资源占用」。工程上常用的对策是把 Cluster Load 作为成本模型的第五组分,或者把路由器与调度器协同。
8.3 学习型 cost model 的争议
近年来工业界出现了「神经网络替代传统 cost model」的趋势(如 Marcus et al. SIGMOD 2019 [5] 的 Neo 系统)。我们对此持谨慎态度:(i)训练数据依赖历史 workload,对新 workload 泛化差;(ii)解释性差,故障排查困难;(iii)模型刷新成本高。在大多数工程场景下,「直方图 + 自适应反馈」仍是更稳定的选择,神经网络方案仅在「workload 高度稳定 + 查询模式重复度高」的特定场景才有 ROI。
9. 结论
查询路由是现代数据系统性能的核心抓手。本文系统阐述了执行计划空间、cardinality 估算、成本模型、路由算法、自适应反馈五个工程模块。核心论点:
- Cardinality 估算误差直接放大为路由代价误差,是查询路由质量的决定性瓶颈;
- 单列直方图 + 强相关列对的联合统计,在工程场景下精度优于复杂的多维直方图;
- 复合成本模型的「精细化」边际 ROI 极低,优先把工程精力投在 cardinality 精度与 plan space 覆盖;
- 自适应反馈闭环能把 p95 估算误差从 10× 压到 1.5× 以内,在真实 workload 上路由准确率提升 20%+;
- 神经网络 cost model 的工程价值被高估,在大多数场景下「直方图 + 反馈」是更稳定的选择。
▎工程见解 更深的工程哲学:查询路由的优化是「在不可消除的不确定性下做决策」的典型案例。完美的 cost model 不存在;唯一可持续的工程策略是「持续度量真实代价 + 持续校准估算」。这与机器学习生产系统的「持续学习」思路一致——一次性训练完美模型是奢望,持续闭环才是工程现实。
参考文献
[1] Leis V, Gubichev A, Mirchev A, et al. How Good Are Query Optimizers, Really? PVLDB 2015.
[2] Kipf A, Kipf T, Radke B, et al. Learned Cardinalities: Estimating Correlated Joins with Deep Learning. CIDR 2019.
[3] Cormode G, Garofalakis M, Haas P J, et al. Synopses for Massive Data: Samples, Histograms, Wavelets, Sketches. Foundations and Trends in Databases, 2012.
[4] Avnur R, Hellerstein J M. Eddies: Continuously Adaptive Query Processing. SIGMOD 2000.
[5] Marcus R, Negi P, Mao H, et al. Neo: A Learned Query Optimizer. SIGMOD 2019.
[6] Selinger P G, Astrahan M M, Chamberlin D D, et al. Access Path Selection in a Relational Database Management System. SIGMOD 1979.
[7] Stillger M, Lohman G M, Markl V, Kandil M. LEO – DB2's LEarning Optimizer. VLDB 2001.
[8] Cai W, Balazinska M, Suciu D. Pessimistic Cardinality Estimation: Tighter Upper Bounds for Intermediate Join Cardinalities. SIGMOD 2019.
[9] Wang X, Qu C, Wu W, et al. Are We Ready for Learned Cardinality Estimation? VLDB 2021.
[10] Han Y, Wu Z, Wu P, et al. Cardinality Estimation in DBMS: A Comprehensive Benchmark Evaluation. VLDB 2021.
关于我们
贵州数幄科技有限公司是一家专注于 人工智能与数据智能 领域的科技公司。
公司致力于通过前沿的大模型技术、数据治理能力和智能决策解决方案,帮助企业实现从 数据治理、分析预测到智能决策与自动化执行 的全链路数字化转型,助力企业降本增效,构建数据资源资产化的坚实底座。
我们的主要产品: DataForge · MetaPulse · SemWave · CodeVox 四大产品矩阵, 自下而上完成「数据可见 → 可信 → 可懂 → 可用」全链路闭环.

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)