Training Language Models to Follow Instructions with Human Feedback论文阅读
在学习NLP过程中阅读了Training Language Models to Follow Instructions with Human Feedback论文做出一些阅读和理解,个人理解可能有所偏颇。
一、论文基本信息与摘要
1.1 基本信息
该论文由OpenAI团队完成,主要作者包括Long Ouyang、Jeff Wu、Xu Jiang等人,发表于2022年的NeurIPS会议。论文的核心贡献在于提出了InstructGPT模型,通过基于人类反馈的强化学习(Reinforcement Learning from Human Feedback, RLHF)技术,将GPT-3这样的大语言模型与人类意图进行对齐。
1.2 摘要
论文明确指出,增大语言模型的规模并不能天然地提升其遵循用户意图的能力。大型语言模型可能产生不真实、有害或对用户毫无帮助的输出——换言之,这些模型与用户的需求并未对齐。论文通过人类反馈微调的方法,证明了在广泛的任务范围内对齐语言模型与用户意图是可行的。
具体而言,该研究首先从标注员撰写的提示和OpenAI API用户提交的提示出发,收集了标注员展示理想行为的演示数据集,用于对GPT-3进行监督微调(SFT)。随后,收集模型输出的排序数据,用于训练奖励模型(RM)。最后,利用该奖励模型作为奖励函数,通过近端策略优化(PPO)算法进一步微调模型。最终得到的模型被命名为InstructGPT。
最令人印象深刻的结果是:在人类评估中,仅有1.3B参数的InstructGPT模型的输出,被偏好程度超过了175B参数的GPT-3模型的输出——尽管前者参数数量仅有后者的百分之一。此外,InstructGPT在真实性方面有所提升,在有害输出方面有所减少,同时在公开NLP数据集上仅有极小的性能衰退。
二、国内外研究现状
2.1 语言模型的对齐问题
在InstructGPT论文发表前后,大语言模型的对齐问题已成为学术界和工业界共同关注的核心议题。传统的语言模型训练目标——在互联网数据上预测下一个token——与“帮助、诚实、无害地遵循用户指令”这一目标存在根本性的不匹配。Bender等人(2021)、Bommasani等人(2021)和Weidinger等人(2021)系统性地阐述了语言模型可能产生的各种危害,包括生成虚假信息、偏见与歧视性内容、泄露隐私数据等。
Kentron等人(2021)对语言模型中由于未对齐导致的行为问题进行了分类,涵盖了有害内容生成、目标误用等。Askell等人(2021)提出了将语言助手作为对齐研究的试验平台,并研究了一些简单基线方法及其缩放性质。
2.2 指令微调相关工作
在指令遵循方面,此前已有大量研究探索跨任务泛化能力。FLAN(Wei等人,2021)和T0(Sanh等人,2021)等工作通过在广泛公开NLP数据集上微调语言模型(通常在每个任务前添加自然语言指令),并在不同的任务集上进行评估。这些研究的共同发现是:在带指令的多种NLP任务上微调语言模型,可以改善其在未见过的任务上的零样本和少样本性能。
然而,InstructGPT论文的一个重要洞见是:这些公开NLP数据集并“不能真实反映语言模型在实际中的使用方式”。公开数据集主要涵盖分类、问答等易于自动评估的任务,而OpenAI API的实际用户超过57%的使用场景是开放式生成和头脑风暴,这与NLP基准测试的任务分布存在显著差异。
2.3 基于人类反馈的学习方法
RLHF方法并非InstructGPT首创。该技术路线最早由Christiano等人(2017)提出,用于在模拟环境和Atari游戏中训练机器人。随后Ziegler等人(2019)和Stiennon等人(2020)将其应用于语言模型的文本摘要任务,Wu等人(2021)则将其扩展到书籍摘要领域。这些工作在较小的任务范围内验证了RLHF的有效性。
InstructGPT的核心突破在于:
- 将RLHF的应用范围从单一任务(摘要生成)扩展到大量多样化的自然语言任务(生成、问答、对话、改写、分类等)。
- 基于真实用户的API提示数据而非人工构造的NLP数据集进行训练,使模型行为更贴近实际使用场景。
- 首次系统性地在175B规模的模型上验证了RLHF在指令遵循方面的有效性。
在国际上,RLHF已成为主流的对齐技术之一,并直接影响了后续的ChatGPT(GPT-3.5/GPT-4)、Claude(Anthropic)等模型的训练范式。在国内,百度的文心一言、阿里的通义千问、清华的ChatGLM等大语言模型也纷纷采用了基于人类反馈的对齐技术,形成了广泛的技术共识。
三、创新点分析
InstructGPT论文的核心创新可从以下几个维度来理解:
1.将RLHF从狭窄任务推广到通用指令遵循
此前RLHF在语言模型上的应用主要集中在摘要生成这一单一任务上。InstructGPT将其扩展到涵盖生成、开放式问答、头脑风暴、对话、改写、摘要、分类、信息提取等多种任务的通用场景,并在真实用户数据上进行验证。这是一个量级上的跃升,使得RLHF从实验室技术变成了可工程化部署的方案。
2."小模型胜过大模型"的实证发现
论文证明仅有1.3B参数的InstructGPT模型在遵循指令方面胜过了175B参数的GPT-3。这一发现具有深远的实践意义:它意味着提升模型对齐度的性价比远高于单纯扩大模型规模。论文指出,训练GPT-3需要3640 petaflops/s-days,而训练175B InstructGPT仅需60 petaflops/s-days,SFT模型则仅需4.9 petaflops/s-days。
3.对齐税(Alignment Tax)的缓解策略
RLHF微调不可避免地会损害模型在某些公开NLP数据集上的性能——即"对齐税"。论文的PPO-ptx变体通过在PPO梯度中混合预训练梯度(即同时优化PPO目标和预训练损失),成功地在保持人类偏好评分的同时,大幅减少了在SQuAD、DROP、HellaSwag等基准上的性能下降。
4.系统性的人类实验设计
论文设计了包含训练标注员和预留标注员的双重评估体系,验证了InstructGPT的输出不仅被训练标注员偏好,也被从未参与训练数据的"预留标注员"所偏好,说明模型并非简单地过拟合到特定标注员的偏好上。
5.自动评估与人类评估的互补
论文展示了自动评估与人类评估的差异和互补性,为后续研究中如何综合运用两种评估方式提供了方法论参考。
四、方法具体实现
InstructGPT的方法论遵循Ziegler等人(2019)和Stiennon等人(2020)的框架,共分为三个步骤,如图2所示。以下对各步骤进行详细拆解。

图1:RLHF三步骤示意图(原论文Figure 2):(1)监督微调SFT, (2)奖励模型RM训练, (3)基于PPO的强化学习
4.1 第一步:监督微调(Supervised Fine-Tuning, SFT)
在这一阶段,研究团队首先需要获取高质量的演示数据。他们从两个来源收集提示(prompt):(1) 标注员自行撰写的提示(分为Plain、Few-shot和User-based三种类型);(2) OpenAI API用户在Playground界面中提交的提示。
数据标注过程:研究团队通过Upwork和ScaleAI平台雇佣了约40名合同工进行数据标注。所有标注员需经过筛选测试,评估其识别和处理敏感话题的能力。标注员的任务是针对每个提示写出理想的模型回复——即"演示数据"(demonstrations)。
模型训练:使用监督学习在GPT-3预训练模型的基础上进行微调。训练16个epoch,采用余弦学习率衰减和0.2的残差dropout。有趣的是,论文发现虽然模型在1个epoch后就在验证损失上过拟合了,但继续训练更多epoch有助于提高RM分数和人类偏好评分——这提示SFT阶段的"过拟合"某种程度上是有益的。
SFT数据集包含约13k个训练提示(来自API和标注员撰写)。论文最终通过验证集上的RM分数进行模型选择。
4.2 第二步:奖励模型训练(Reward Model, RM)
奖励模型的目标是学习一个函数,给定提示和回复,输出一个标量分数来预测人类标注员会更偏好哪个回复。
数据收集方式:与SFT阶段每次只收集一个演示不同,RM阶段让标注员对同一提示下的多个模型输出进行排序(一般K=4到9个回复)。这种方法大幅提高了数据收集效率——每次标注可获得C(K,2)个比较对。
损失函数设计:论文采用以下损失函数:
loss(θ) = -1/C(K,2) × E[log(σ(rθ(x,y_w) - rθ(x,y_l)))]
其中rθ(x,y)是奖励模型对提示x和回复y的输出,y_w是被偏好的回复,y_l是不被偏好的回复。
关键设计细节:与Stiennon等人(2020)将每个比较对视为独立数据点不同,InstructGPT将所有C(K,2)个比较作为一个批次元素训练。这样做一方面大幅提升了计算效率(只需对每个回复进行一次前向传播),另一方面避免了模型在单个epoch内过拟合的问题,显著提高了验证准确率和log loss。
论文主要使用6B参数的奖励模型(6B RM),因为175B RM训练不稳定且计算成本高。RM数据集包含约33k个训练提示。最终,RM的损失对reward的平移不变,论文通过将标注员演示的平均分设为0来进行归一化。
4.3 第三步:强化学习优化(Reinforcement Learning with PPO)
这是RLHF的最后一步——利用训练好的奖励模型作为信号,通过强化学习优化策略(即语言模型本身)。
环境设置:这是一个赌博机(bandit)环境,每次向模型呈现一个随机的客户提示,模型生成回复,然后奖励模型根据提示和回复给出一个标量奖励,并结束该幕。
KL惩罚项:为防止奖励模型被过度优化(reward over-optimization),论文在PPO目标中加入了每个token的KL散度惩罚,约束RL策略与SFT模型之间的差异。最终的目标函数为:
objective(φ) = E[rθ(x,y) - β×log(π_RL(y|x)/π_SFT(y|x))] + γ×E[log(π_RL(x))]
其中β是KL奖励系数,γ是预训练损失系数。
PPO vs PPO-ptx:"PPO"模型仅使用奖励信号进行优化。"PPO-ptx"模型在PPO梯度中混合了预训练梯度(γ>0),以缓解对齐税。除非特别说明,论文中的InstructGPT默认指PPO-ptx模型。
PPO数据集包含约31k个训练提示(仅来自API)。价值函数从RM初始化。训练中使用了批次大小为512,小批次大小为64(考虑GPU利用率后的折中选择)。
五、实验设计
5.1 评估体系
论文构建了一个双轨并行的评估体系:
- API分布评估
这是核心评估方式。在预留的、未出现在训练数据中的客户提示上进行人类评估。主要指标是标注员的偏好评分(pairwise preference),即比较两个模型的输出哪个更好。辅助指标包括1-7 Likert量表整体质量评分、是否遵循正确指令、是否包含幻觉、是否恰当等多维度元数据(见表3)。
- 公开NLP数据集评估
在标准NLP基准上进行自动评估,涵盖三类任务:(a) 安全相关——真实性(TruthfulQA)、毒性(RealToxicityPrompts)、偏见(Winogender, CrowS-Pairs);(b) 传统NLP任务——SQuAD(问答)、DROP(数学推理)、HellaSwag(常识推理)、WMT翻译(法英翻译)等;(c) 摘要任务——CNN/DailyMail、TLDR。

图2:人类评估结果(原论文Figure 1):InstructGPT在各参数量级上均显著优于GPT-3基线
5.2 基线模型
论文构建了全面的基线体系以确保评估的公正性:
- GPT-3(原始模型)
- GPT-3 prompted——在提示前添加精心设计的few-shot前缀,引导模型进入指令遵循模式
- SFT——仅经过监督微调的基线
- FLAN和T0——在公开NLP数据集上微调的175B GPT-3
5.3 模型规模设计
论文在三个参数量级上进行训练和评估:1.3B、6B和175B参数,所有模型均使用GPT-3架构。这种多规模的实验设计使得论文能够分析RLHF效果在不同规模下的缩放规律。
5.4 关键实验结果
人类偏好胜利:175B InstructGPT的输出在85±3%的时间里被偏好于175B GPT-3,在71±4%的时间里被偏好于few-shot GPT-3。1.3B InstructGPT甚至在偏好评分上超过了175B GPT-3。
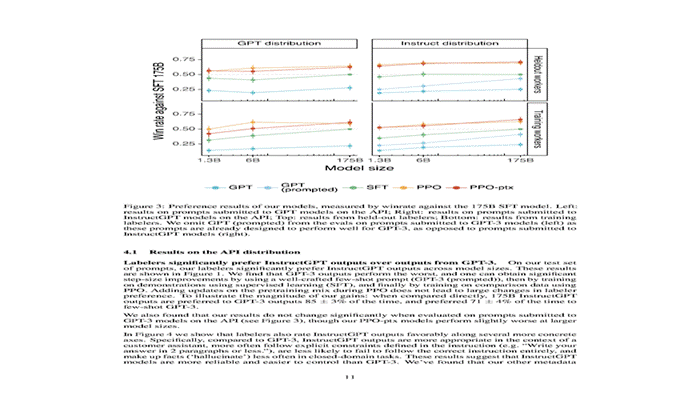
图3:不同模型规模的偏好率(原论文Figure 3):训练标注员与预留标注员的结果高度一致
真实性提升:在TruthfulQA基准上,InstructGPT生成真实且信息丰富的回答的频率约为GPT-3的两倍。在封闭域任务上,InstructGPT的幻觉率(21%)约为GPT-3(41%)的一半。
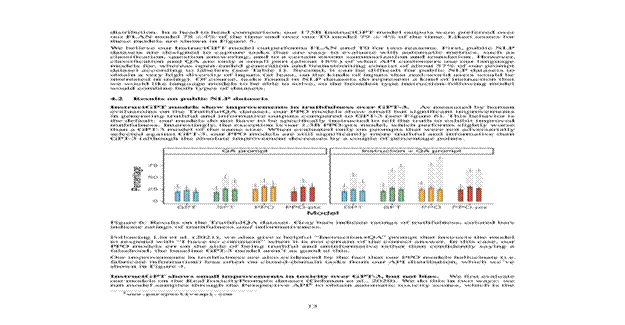
图4:TruthfulQA结果(原论文Figure 6):PPO模型在真实性和信息性上有显著提升
毒性降低:在要求模型以尊重方式输出时,InstructGPT比GPT-3减少了约25%的有毒输出。但在无特定指令或要求偏见的指令下,差异不明显甚至反向。
对齐税与PPO-ptx的缓解:PPO-ptx通过混入预训练梯度,显著恢复了对齐税导致的性能下降,在HellaSwag上甚至超过了GPT-3,但在SQuAD v2、DROP和翻译任务上仍存在差距。
泛化能力:InstructGPT展示了令人兴奋的泛化能力——能够用其他语言遵循指令(虽然输出有时会回到英语),能够理解和描述代码,尽管这些类型的提示在微调数据中极为稀少。
六、数据层面的优势
InstructGPT在数据层面的优势主要体现在以下几个方面:
6.1 真实用户数据
与FLAN和T0等使用人工构造的NLP数据集不同,InstructGPT的训练提示来自OpenAI API的真实用户。这带来了两个关键优势:(1) 数据分布反映了用户实际使用语言模型的真实需求——开放式生成和头脑风暴占了约57%,而分类和问答仅占约18%;(2) 提示的多样性远高于任何公开NLP数据集,涵盖了从创意写作到代码问答的广泛场景。
6.2 多源提示设计
论文设计了三种类型的标注员撰写的提示:Plain(任意任务)、Few-shot(带示例的指令)、User-based(基于API等待列表中的用例),与真实API提示形成互补。这种组合确保了初始数据集的覆盖面和多样性,使得模型在各种任务类型上都能获得训练信号。
6.3 比较数据的效率优化
在RM数据收集阶段,让标注员对K个回复排序而不是两两比较,效率提升显著。每次标注产生C(K,2)个比较对,而论文巧妙地通过将同一提示下的所有比较作为一个批次元素来处理,既避免了过拟合,又大幅降低了计算成本。
6.4 数据规模与标注员质量
SFT数据集约13k提示、RM数据集约33k提示、PPO数据集约31k提示。相比GPT-3预训练所需的数千亿token,RLHF所需的数据量相对很小。标注员经过严格筛选,标注员间一致性达到72.6±1.5%,与Stiennon等人(2020)的研究者-研究者一致性(73±4%)相当,说明尽管任务复杂多样,标注质量仍然可靠。
6.5 预留标注员验证
论文引入了一组未参与任何训练数据生产的预留标注员进行独立评估。结果发现,预留标注员对InstructGPT的偏好率与训练标注员高度一致,验证了模型并未过拟合到特定标注员的偏好上——这是数据质量的有力佐证。
七、发展方向与未来可能方向
7.1 RLHF技术的演进
InstructGPT论文奠定了RLHF在大语言模型对齐中的核心地位,但其后的发展已经超越了该论文的原始框架:
- ChatGPT和GPT-4的迭代:
OpenAI在InstructGPT基础上进一步优化了RLHF管线,引入了更多的人类反馈数据和更复杂的奖励模型,推出了ChatGPT(基于GPT-3.5)。GPT-4则在RLHF中融合了基于规则的奖励模型和基于人类偏好的奖励模型,进一步提升了安全性和可控性。
- Constitutional AI:
Anthropic提出的宪法AI(Bai等人,2022)是对RLHF的重要改进——使用一组原则(宪法)替代部分人类反馈,让模型通过自我批评和修订来学习行为约束,减少了对人工标注的依赖。
- DPO(Direct Preference Optimization):
Rafailov等人(2023)提出的DPO方法绕过了显式的奖励模型训练,直接从人类偏好数据优化策略。DPO在保持性能的同时显著简化了训练流程,已成为RLHF的重要替代方案。
7.2 国内研究现状
国内在大语言模型对齐方面也取得了重要进展:
- 清华ChatGLM系列在其训练中引入了基于RLHF的对齐流程。
- 百度的ERNIE Bot(文心一言)在训练过程中使用了多轮人类反馈对齐技术。
- 阿里的通义千问系列在训练中采用了RLHF及多种对齐技术。
- 上海AI实验室的InternLM等开源模型也逐步将RLHF纳入训练管线。
国内研究在RLHF方面的特色在于:更注重中文场景下的安全对齐和文化敏感性,同时也在探索更加高效的偏好优化方法。
7.3 未来可能方向
- 多模态对齐
InstructGPT仅处理文本模态。随着GPT-4V、Gemini等多模态模型的发展,如何将RLHF扩展到图像、视频、音频等多模态输入输出是一个重要方向。多模态对齐涉及的问题更加复杂,如视觉真实性和不同模态间的一致性。
- 可扩展监督(Scalable Oversight)
InstructGPT论文已经引出了这个问题:当模型能力超越人类评估能力时,如何继续提供有效的监督信号?Wu等人(2021)的书籍摘要工作展示了RLHF在人类难以直接评估的任务上的应用。未来的方向包括通过辩论、递归奖励建模等方式实现可扩展的监督。
- 多偏好群体对齐
论文明确指出其对齐的是特定标注员群体的偏好,而非普世的"人类价值观"。未来需要研究如何构建可以条件化于不同群体偏好(即同一个模型可以根据需要表现不同价值观的行为),以及在多方利益相关者冲突时如何公平权衡。
- 自动化的对齐评估
InstructGPT主要依赖人工评估,这既昂贵又难以规模化。开发可靠、高效、多维度的自动评估方法(如LLM-as-a-judge方法)是当前的热点方向。但论文也提醒了我们:自动评估和人类评估之间存在差异,需要谨慎对待。
- 减少有害输出的鲁棒性
论文发现InstructGPT在要求产生偏见输出时会比GPT-3产生更有害的内容——对指令的遵循反而成为双刃剑。如何让模型既能遵循合法、有益的指令,又能在面对有害指令时保持安全,是需要持续研究的问题。对抗性数据收集(Dinan等人,2019b)等方法可能有助于解决这一挑战。
7.4 对齐研究的长期影响
InstructGPT论文的价值不仅在于技术贡献,更在于其为AI安全领域的对齐研究提供了一个清晰的实证反馈循环。论文提出的"对齐税"概念、RLHF的成本效益分析(对齐投资比扩大模型规模更具回报)、以及从真实部署中学习的方法论,对后续研究产生了深远影响。
正如论文在讨论中所强调的,对齐研究的目标是找到通用且可扩展的方法——不仅适用于今天的语言模型,也适用于未来的、能力更强的AI系统。InstructGPT证明,即使是相对简单的RLHF技术,也能在广泛的任务范围内显著改善模型行为,这为更高级的对齐技术奠定了基础。
八、总结与评价
InstructGPT论文是语言模型对齐领域的一个里程碑式工作。它的核心贡献在于:用严密的实验证明了基于人类反馈的强化学习能够使大规模语言模型在遵循用户指令方面获得质的提升,且这种提升的性价比远超单纯扩大模型规模。
论文的实验设计严谨、评估体系全面、分析深入透彻。特别是多规模(1.3B/6B/175B)的实验设计、训练/预留双标注员评估体系、对齐税的识别与缓解策略等,都为后续研究树立了方法论的标杆。
同时,论文也坦诚地指出了自身工作的局限性:标注员群体的代表性有限、模型仍然会犯简单错误、对有害指令的服从反而可能产生更大危害、以及对齐的是特定群体的偏好而非普世价值等。这些局限性至今仍是大语言模型对齐研究的核心挑战。
从更宏观的角度来看,InstructGPT论文展示了一条从实验室研究到真实部署的闭环路径——在真实用户场景中验证技术方案的有效性,从部署中收集反馈来改进技术。这种"研究-部署-反馈"的迭代模式,是大语言模型研究快速进步的重要驱动力。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)