基于 YOLOv8 的目标检测识别管理系统设计与实现
本文介绍了一个基于 YOLOv8 的目标检测识别管理系统。该系统提供了图形化操作界面,支持图片识别、视频识别、摄像头实时识别以及 RTSP/HTTP 实时流识别。系统通过 PySide6 构建桌面端界面,使用 Ultralytics YOLOv8 模型完成目标检测,并结合 OpenCV 进行图像与视频帧处理。用户可以通过按钮选择不同的识别源,系统会实时显示检测画面和检测结果,具有较好的交互性和实用性。
一、项目背景
随着人工智能和计算机视觉技术的发展,目标检测技术已经广泛应用于智慧安防、交通监控、工业检测、无人驾驶、行为分析等场景。YOLO 系列算法由于检测速度快、精度较高、部署方便,成为目标检测领域中非常常用的算法之一。
在实际应用中,如果只是通过命令行运行检测程序,操作不够直观,也不方便普通用户使用。因此,本文设计并实现了一个带有图形化界面的 YOLO 识别管理系统。用户无需输入复杂命令,只需要点击按钮即可完成图片、视频和实时摄像头检测。
本系统主要实现以下功能:
- 图片目标检测
- 视频目标检测
- 摄像头实时检测
- RTSP/HTTP 实时流检测
- 检测结果文字展示
- 检测画面实时显示
- 摄像头自动刷新与选择
- 多线程检测,避免界面卡死
二、开发环境
本项目使用 Python 语言开发,主要依赖如下:
Python 3.9+
PySide6
opencv-python
ultralytics安装依赖命令如下:
pip install PySide6 opencv-python ultralytics项目中使用的检测模型为 YOLOv8 官方模型:
yolov8n.pt其中 yolov8n.pt 是 YOLOv8 的轻量级模型,具有速度快、占用资源少的特点,适合普通电脑进行实时检测测试。
三、系统总体设计
本系统整体采用图形化桌面程序结构,主要由两部分组成:
第一部分是检测线程 DetectWorker,负责加载 YOLO 模型、读取图片或视频帧、执行目标检测,并将检测结果返回给主界面。
第二部分是主窗口 MainWindow,负责构建界面、响应用户操作、显示检测画面和检测结果。
系统结构如下:
YOLO 识别管理系统
│
├── MainWindow 主界面
│ ├── 图片识别按钮
│ ├── 视频识别按钮
│ ├── 实时流识别按钮
│ ├── 摄像头选择框
│ ├── 开始识别按钮
│ ├── 停止识别按钮
│ ├── 画面显示区域
│ └── 检测结果显示区域
│
└── DetectWorker 检测线程
├── 加载 YOLOv8 模型
├── 图片检测
├── 视频检测
├── 摄像头检测
├── 实时流检测
└── 返回检测画面和结果为了避免检测过程阻塞界面,系统使用 QThread 将检测任务放到子线程中执行。主线程只负责界面显示和用户交互,这样在视频和摄像头实时识别时,窗口不会出现卡顿或无响应的问题。
四、核心功能介绍
1. 图片识别功能
用户点击“图片识别”按钮后,可以选择本地图片文件。系统支持常见图片格式,例如:
jpg、jpeg、png、bmp选择图片后,点击“开始识别”,系统会调用 YOLOv8 模型进行目标检测,并将检测后的图片显示在左侧区域,同时在右侧显示识别结果。
核心代码如下:
def choose_image(self):
file_path, _ = QFileDialog.getOpenFileName(
self,
"选择图片",
str(Path.cwd()),
"图片文件 (*.jpg *.jpeg *.png *.bmp)"
)
if file_path:
self.current_source_type = "image"
self.current_source_value = file_path
self.result_text.append(f"已选择图片: {file_path}")检测图片时,程序调用 YOLO 的 predict() 方法:
results = model.predict(source=image_path, verbose=False)检测完成后,通过 r.plot() 得到带有检测框的图像:
self.frame_ready.emit(r.plot())五、视频识别功能
系统支持用户选择本地视频文件进行目标检测。点击“视频识别”按钮后,可以选择如下格式的视频:
mp4、avi、mov、mkv视频识别的本质是不断读取视频中的每一帧,然后将每一帧送入 YOLO 模型中进行检测。
核心代码如下:
def choose_video(self):
file_path, _ = QFileDialog.getOpenFileName(
self,
"选择视频",
str(Path.cwd()),
"视频文件 (*.mp4 *.avi *.mov *.mkv)"
)
if file_path:
self.current_source_type = "video"
self.current_source_value = file_path
self.result_text.append(f"已选择视频: {file_path}")在检测线程中,视频通过 OpenCV 打开:
cap = cv2.VideoCapture(cap_source)然后循环读取视频帧:
while self.running:
ok, frame = cap.read()
if not ok:
break
results = model.predict(source=frame, verbose=False)这样就可以实现对视频文件的连续目标检测。
六、摄像头实时识别功能
本系统还支持本机摄像头实时识别。程序启动时会自动扫描电脑可用的摄像头,并添加到下拉框中。
摄像头刷新代码如下:
def refresh_cameras(self):
self.combo_camera.clear()
found = 0
for idx in range(10):
cap = cv2.VideoCapture(idx)
if cap.isOpened():
self.combo_camera.addItem(f"摄像头 {idx}", str(idx))
found += 1
cap.release()
if found == 0:
self.combo_camera.addItem("未找到摄像头", "")
self.current_source_type = None
self.current_source_value = None
else:
self.combo_camera.setCurrentIndex(0)
self.choose_camera()这里程序会尝试打开编号为 0 ~ 9 的摄像头。如果某个编号能够成功打开,就说明该摄像头可用。
摄像头选择函数如下:
def choose_camera(self):
cam_data = self.combo_camera.currentData()
if cam_data:
self.current_source_type = "camera"
self.current_source_value = str(cam_data)
self.result_text.append(f"已选择摄像头: {cam_data}")
else:
self.current_source_type = None
self.current_source_value = None
self.result_text.append("未选择可用摄像头")这个函数非常重要。因为系统支持图片、视频和摄像头多种输入源,如果用户之前选择过视频,再想切换回摄像头,就必须更新当前识别源。通过 choose_camera() 方法,可以确保用户选择摄像头时,系统会将当前识别源切换为 camera。
七、实时流识别功能
除了本机摄像头,系统还支持输入 RTSP 或 HTTP 视频流地址。例如网络摄像头、监控摄像头等设备通常可以提供 RTSP 地址。
点击“实时流识别”按钮后,系统会弹出输入框:
def choose_stream(self):
stream_url, ok = QInputDialog.getText(
self,
"实时流识别",
"请输入实时流地址,例如 RTSP / HTTP:"
)
if ok and stream_url.strip():
self.current_source_type = "stream"
self.current_source_value = stream_url.strip()
self.result_text.append(f"已设置实时流: {stream_url.strip()}")输入流地址后,系统会通过 OpenCV 打开该视频流:
cap = cv2.VideoCapture(cap_source)如果视频流可以正常打开,就会逐帧读取并进行 YOLO 检测。
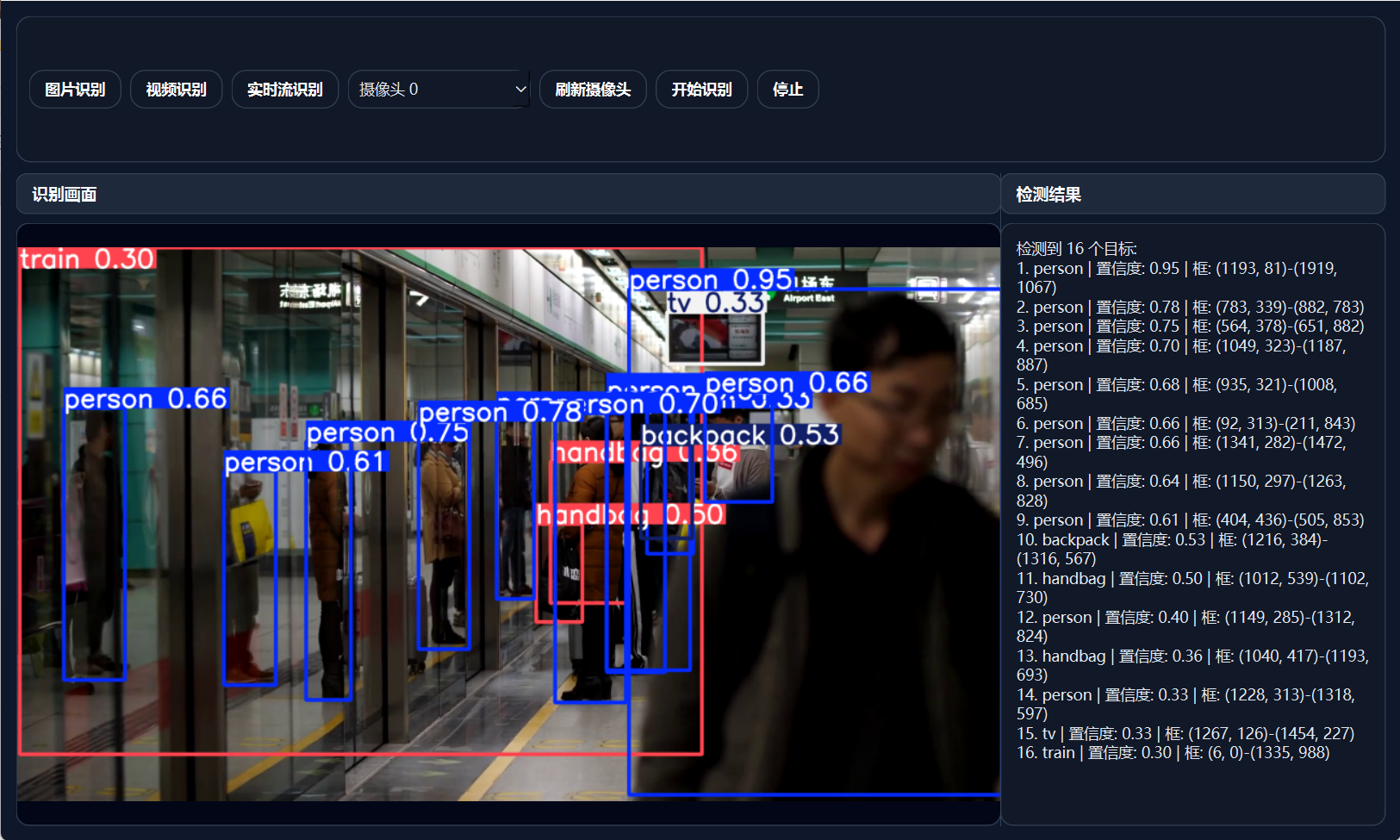
八、检测结果展示
为了方便用户查看识别结果,系统不仅显示检测框,还会在右侧文本框中显示每个目标的类别、置信度和边界框坐标。
检测结果使用 DetectionItem 数据类保存:
@dataclass
class DetectionItem:
cls_name: str
conf: float
x1: float
y1: float
x2: float
y2: float每个检测目标包含:
类别名称
置信度
左上角坐标
右下角坐标检测结果格式化代码如下:
def _format_result_text(self, items: list[DetectionItem]) -> str:
if not items:
return "未检测到目标"
lines = [f"检测到 {len(items)} 个目标:"]
for i, it in enumerate(items, start=1):
lines.append(
f"{i}. {it.cls_name} | 置信度: {it.conf:.2f} | "
f"框: ({int(it.x1)}, {int(it.y1)})-({int(it.x2)}, {int(it.y2)})"
)
return "\n".join(lines)最终显示效果类似:
检测到 3 个目标:
1. person | 置信度: 0.86 | 框: (120, 80)-(320, 450)
2. car | 置信度: 0.79 | 框: (400, 180)-(680, 390)
3. dog | 置信度: 0.72 | 框: (50, 220)-(180, 410)九、界面设计
系统采用深色主题界面,整体风格简洁清晰。顶部为功能按钮区域,左侧为检测画面显示区域,右侧为检测结果显示区域。
界面主要由以下组件组成:
QMainWindow 主窗口
QPushButton 功能按钮
QComboBox 摄像头选择框
QLabel 图像显示区域
QTextEdit 检测结果区域
QSplitter 左右分栏布局
QThread 检测线程核心界面布局如下:
splitter = QSplitter(Qt.Horizontal)
left_panel = QWidget()
right_panel = QWidget()
splitter.addWidget(left_panel)
splitter.addWidget(right_panel)
splitter.setSizes([920, 360])左侧用于显示实时画面,右侧用于显示检测结果:
self.video_label = QLabel("等待开始识别...")
self.result_text = QTextEdit()为了让界面更加美观,系统使用了 Qt 样式表进行美化:
self.setStyleSheet(
"""
QMainWindow, QWidget {
background: #0f172a;
color: #e2e8f0;
font-family: 'Microsoft YaHei UI';
font-size: 14px;
}
QPushButton {
background: #1d4ed8;
color: #ffffff;
border: none;
border-radius: 10px;
padding: 8px 14px;
font-weight: 600;
}
QPushButton:hover {
background: #2563eb;
}
"""
)十、多线程设计
目标检测是一个比较耗时的任务,尤其是在视频和实时摄像头识别时,如果直接在主线程中运行检测,会导致界面卡死。
因此,本系统创建了一个 DetectWorker 类,继承自 QThread:
class DetectWorker(QThread):
frame_ready = Signal(object)
log_ready = Signal(str)
finished_ok = Signal()
error_occurred = Signal(str)其中定义了四个信号:
frame_ready:返回检测后的图像帧
log_ready:返回检测结果文本
finished_ok:检测结束信号
error_occurred:错误信号主窗口通过信号槽机制接收检测结果:
self.worker.frame_ready.connect(self.update_frame)
self.worker.log_ready.connect(self.update_result)
self.worker.error_occurred.connect(self.on_error)
self.worker.finished_ok.connect(self.on_finished)这样,检测任务在子线程中运行,界面更新在主线程中完成,保证了程序运行的稳定性和流畅性。
十一、系统运行流程
系统的整体运行流程如下:
启动程序
↓
加载主界面
↓
刷新摄像头列表
↓
用户选择识别源
↓
点击开始识别
↓
启动检测线程
↓
加载 YOLOv8 模型
↓
读取图片 / 视频 / 摄像头 / 实时流
↓
执行目标检测
↓
显示检测画面
↓
显示检测结果
↓
用户点击停止或检测结束十二、关键问题与解决方案
在开发过程中,遇到了一个比较典型的问题:
用户先选择视频识别,然后再选择摄像头实时识别时,系统仍然会使用上一次的视频路径,导致摄像头识别无法正常切换。
出现这个问题的原因是程序中保存了当前识别源:
self.current_source_type
self.current_source_value当用户选择视频后,这两个变量会变成:
self.current_source_type = "video"
self.current_source_value = file_path如果后面没有主动切换为摄像头,程序就会一直使用视频作为识别源。
解决方法是给摄像头下拉框绑定选择事件:
self.combo_camera.activated.connect(self.choose_camera)然后在 choose_camera() 方法中主动修改当前识别源:
def choose_camera(self):
cam_data = self.combo_camera.currentData()
if cam_data:
self.current_source_type = "camera"
self.current_source_value = str(cam_data)
self.result_text.append(f"已选择摄像头: {cam_data}")这样就可以实现图片、视频、摄像头和实时流之间的正常切换。
十三、系统优点
本系统具有以下优点:
第一,操作简单。用户不需要输入命令,通过图形化按钮即可完成识别操作。
第二,功能完整。系统支持图片、视频、摄像头和实时流多种识别方式。
第三,界面美观。采用深色主题设计,整体界面简洁直观。
第四,运行稳定。使用 QThread 多线程处理检测任务,避免界面卡死。
第五,扩展方便。后续可以继续增加模型切换、检测结果保存、截图保存、数据库管理等功能。
十四、后续改进方向
虽然当前系统已经实现了基础目标检测功能,但仍然可以继续扩展,例如:
- 增加模型选择功能,支持用户加载自己的
.pt模型。 - 增加检测结果保存功能,将检测结果导出为 TXT、CSV 或 Excel。
- 增加截图保存功能,保存带检测框的图片。
- 增加视频检测结果保存功能,生成带检测框的视频。
- 增加置信度阈值设置功能。
- 增加检测类别筛选功能。
- 增加登录模块和用户管理模块。
- 增加数据库,将检测记录保存到 MySQL 或 SQLite。
- 增加统计图表,展示不同类别目标数量。
- 打包为 exe,方便在 Windows 上直接运行。
十五、总结
本文设计并实现了一个基于 PySide6 和 YOLOv8 的目标检测识别管理系统。系统通过 PySide6 构建桌面端图形界面,通过 OpenCV 读取图片、视频、摄像头和实时流数据,并调用 Ultralytics YOLOv8 模型完成目标检测。
系统支持多种识别方式,能够实时显示检测画面和检测结果,具有较强的实用性和扩展性。通过多线程设计,程序在执行检测任务时不会阻塞界面,用户体验较好。
该系统可以作为计算机视觉课程设计、毕业设计、人工智能项目实践或目标检测应用开发的基础案例。后续可以在此基础上继续扩展模型管理、结果保存、数据库管理和可视化统计等功能,使其更加接近实际应用场景。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)