四个文件入门 Harness Engineering
“Our most difficult challenges now center on designing environments, feedback loops, and control systems.”
— OpenAI Harness Engineering 团队
Harness Engineering 的核心认知转变是:当 Agent 犯错时,问题几乎不是”代码写错了”,而是”环境缺了什么”。 修复方式不是”再试一次”,而是”诊断缺少的能力,然后让 Agent 自己把这个能力补上”。
工程师的角色从 代码作者 变为 系统设计师:设计约束、构建反馈回路、维护文档基础设施、管理 Agent 工作流

如果你已经开始用 Cursor、Claude Code、Codex 或其他 AI 编程工具,大概率遇到过这些场景:
- 明明刚说过的项目规则,Agent 下一轮又忘了;
- 修 Bug 修着修着,顺手把别的模块改坏了;
- 第一次生成很惊艳,第三次迭代开始变得混乱;
- 需求、架构、任务进度都散落在聊天记录里,换一个新会话就像重新开荒。
这时继续优化 Prompt 通常只能缓解一小部分问题。真正要解决的是:怎样给 Agent 设计一个能稳定,持久运行的工作环境?
这就是 Harness Engineering 要解决的问题。
来自 OpenAI的实践:
AGENTS.md ← 目录表(~100 行)
ARCHITECTURE.md ← 顶层领域地图
docs/
├── design-docs/ ← 带索引的架构决策
├── exec-plans/
│ ├── active/
│ ├── completed/
│ └── tech-debt-tracker.md
├── generated/
│ └── db-schema.md
├── product-specs/
├── references/ ← 外部库文档(为 LLM 重新格式化)
└── ...
可以看出Harness Engineering 的核心思路,是把“补上下文”从一项每次重复的人工操作,变成一项一次投入,持续生效的基础工程。
本文聚焦最小化实践方案 ,用四个 Markdown 文件,搭一个最小可用的 Harness,让 AI Agent 从“会写代码”变成“能按规则持续推进项目”。
你会读到什么
文章目录
-
- 你会读到什么
- 1. 为什么大家开始讲 Harness?
- 2. 理解起点:Prompt Engineering(提示词工程)
- 3. Context Engineering:让 AI 从“听懂指令”到“看见全貌”
- 4. Harness Engineering:给 Agent 设计一套可控工作系统
- 5. Prompt、Context、Harness 相互间的关系?
- 6. 最小可用 Harness:先从四个文件开始
- 7. AGENTS.md:Agent 的工作总纲
- 8. Product.md:让 Agent 知道“为什么做”
- 9. Architecture.md:让 Agent 知道“怎么做”
- 10. Session_Handoff.md:让下一轮不要从零开始
- 11. 用这四个文件启动 Agent
- 12. 新需求和 Bug 修复应该怎么走?
- 13. Harness 的核心原则:把经验写进系统
- 14. 一句话总结
- 可直接复制的最小目录结构
- 参考资料
如果只想收藏一句话:
Prompt Engineering 是写好一句指令;Context Engineering 是喂对背景信息;Harness Engineering 是设计一套让 Agent 可控、可验证、可持续工作的系统。
1. 为什么大家开始讲 Harness?

我们先来了解AI 编程工具的发展,大致可以分成三个阶段:
| 阶段 | 关键词 | 你在做什么 | 典型问题 |
|---|---|---|---|
| Prompt Engineering | 指令 | 把任务说清楚 | 复杂任务容易失控 |
| Context Engineering | 上下文 | 把背景材料给足 | 信息太多、质量不稳 |
| Harness Engineering | 系统 | 设计规则、反馈和验证闭环 | 需要工程化维护 |
早期我们主要研究“怎么写 Prompt”。后来发现,Prompt 写得再好,如果模型看不到项目上下文,也只能猜。
于是大家开始重视 Context Engineering:把需求、代码、架构、历史决策、错误日志等信息组织给 AI。
但再往后又会遇到一个新问题:
信息给足了,Agent 还是可能跑偏。
原因很简单:软件开发不是一次性问答,而是一个长期过程。长期过程需要规则、状态、反馈、验证和交接,而不是只靠一段聪明的提示词。
Harness Engineering 的价值就在这里:它把“让 Agent 干活”这件事,从聊天技巧升级成工程系统设计。
2. 理解起点:Prompt Engineering(提示词工程)
Prompt Engineering 的本质,是通过清晰的文本指令,把人的意图传达给 AI。
一个有效 Prompt 通常要包含四类信息:
- 任务目标:你要它完成什么;
- 上下文背景:它需要知道哪些材料;
- 输出格式:你希望结果长什么样;
- 约束条件:哪些事情不能做,哪些规则必须遵守。
在这里插入图片描述
比如:
请根据 Product.md 中的需求,在 components/ 目录下实现用户列表组件。
要求:
1. 使用项目已有的 UI 风格;
2. 不新增第三方依赖;
3. 完成后补充对应测试;
4. 如果发现 Product.md 与 Architecture.md 冲突,先指出冲突,不要直接猜。
这已经比“帮我写个用户列表”稳定很多。
但 Prompt 的边界也很明显:它适合驱动一次具体动作,却不适合承载一个项目的全部记忆。
当项目变复杂后,你会遇到三个问题:
- 上下文窗口有限:代码、需求、架构、历史决策不可能全塞进一轮对话;
- 工程记忆会丢失:长对话里早期规则容易被冲淡;
- 过程难以审计:Agent 为什么这么改?依据在哪里?下次还能接上吗?
所以,Prompt 是原子指令,但不是完整系统。
3. Context Engineering:让 AI 从“听懂指令”到“看见全貌”
Context Engineering 解决的是另一个问题:AI 不仅要听懂你刚说的话,还要看见项目的全貌。
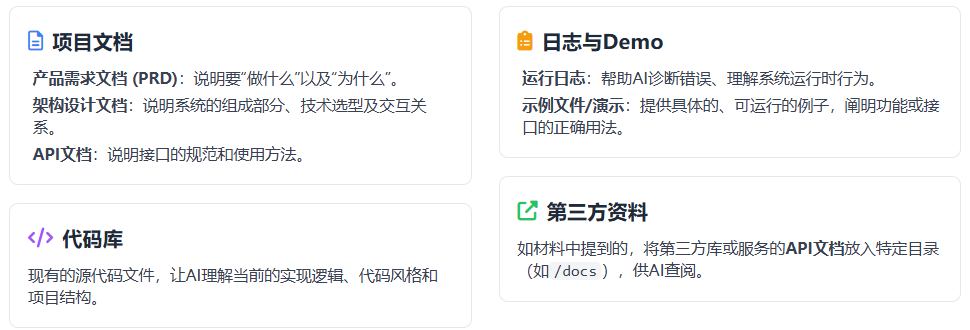
它不是把整个项目文件夹一股脑丢给 AI,而是有策略地提供关键材料:
- 产品需求:用户是谁、要解决什么问题、核心功能是什么;
- 技术架构:目录结构、模块边界、数据流、关键依赖;
- 代码规范:命名、测试、组件风格、提交规则;
- 历史决策:为什么这样设计,哪些方案被放弃过;
- 当前进度:已完成什么、正在做什么、还有哪些风险。
这里有一个非常重要的误区:
Context Engineering 不是“给得越多越好”,而是“给得越准越好”。
过期文档、无关文件、噪声日志、含糊需求,都会污染模型判断。真正有价值的上下文应该是:
- 精炼;
- 相关;
- 结构化;
- 可被 Agent 直接读取;
- 能随着项目变化持续更新。
Context Engineering 让 AI 从“盲人摸象”变成“心里有图”。但它仍然不够。
因为看见全貌,不代表一定能稳定执行。
4. Harness Engineering:给 Agent 设计一套可控工作系统
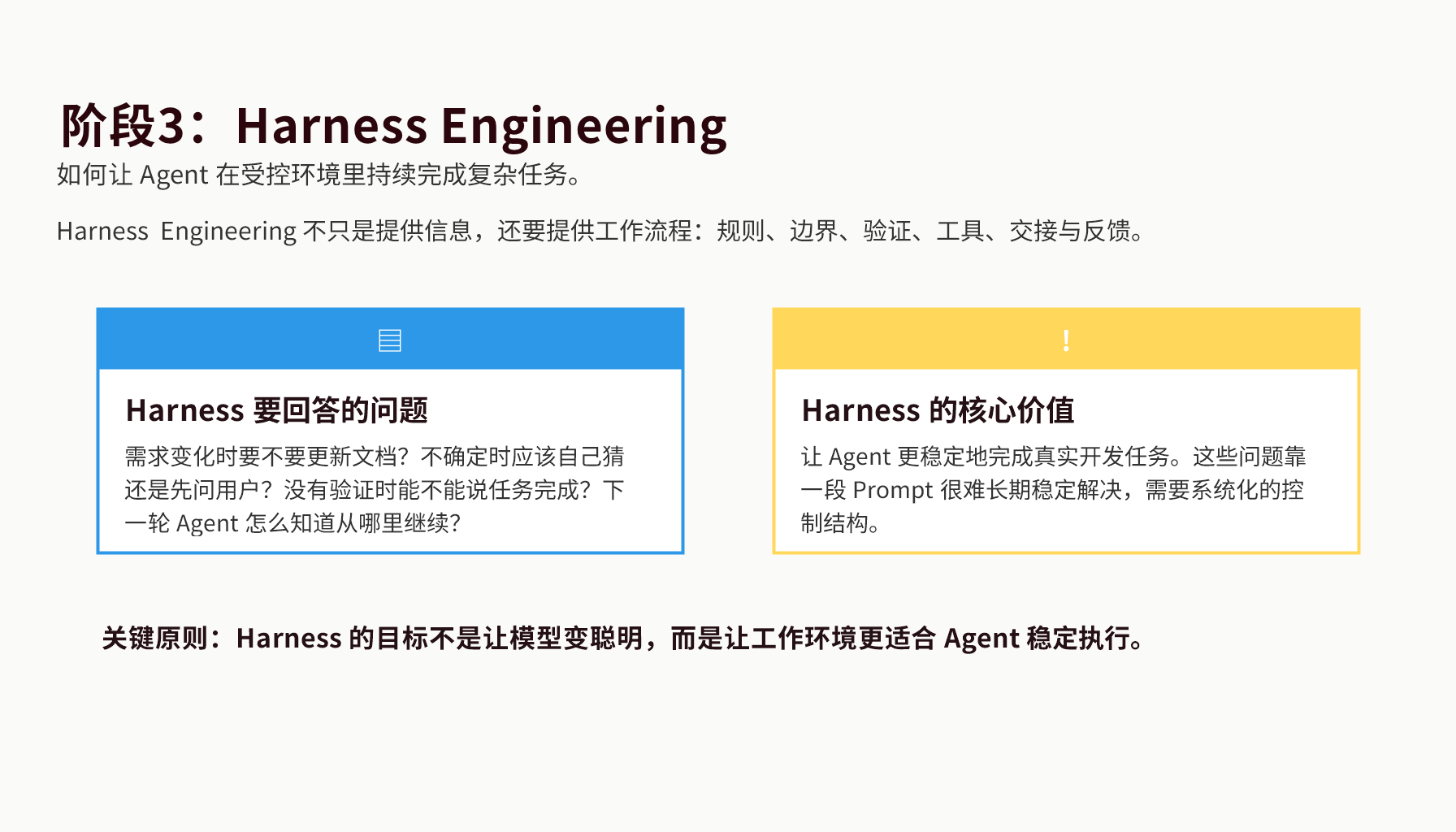
Harness 这个词,本义可以理解为“背带、套具、牵引装置”。它的核心含义是:把一种强大的力量接入到可控系统里。
放到 AI 编程里,Harness Engineering 就是:
为 AI Agent 设计一套能稳定工作的控制系统。
这套系统不仅告诉 Agent “你要做什么”,还要告诉它:
- 从哪里读需求;
- 从哪里读架构;
- 遇到冲突怎么处理;
- 每次改完要验证什么;
- 任务进度写到哪里;
- 新需求和新规则如何沉淀;
- 下一个会话如何无缝接手。
这也是为什么 OpenAI 会把难点总结为:环境、反馈循环和控制系统。
换句话说:
当 Agent 犯错时,问题不一定是“模型不够聪明”,更可能是“环境没有给它正确的轨道”。
Harness Engineering 的目标,不是把每个 Agent 都训练成天才,而是让普通 Agent 在一个更适合它的工程环境里工作。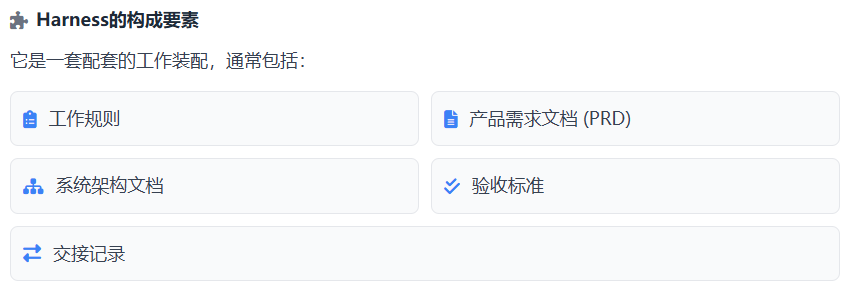
5. Prompt、Context、Harness 相互间的关系?

这三个概念不是互相替代,而是层层叠加。
| 能力层 | 解决的问题 | 典型产物 |
|---|---|---|
| Prompt | 单次任务怎么说清楚 | 指令、任务描述、输出要求 |
| Context | 项目信息怎么给完整 | 需求文档、架构文档、代码片段 |
| Harness | 长期协作怎么稳定 | 工作规则、验证流程、交接机制、反馈闭环 |
可以这样理解:
- Prompt 是“命令”;
- Context 是“地图”;
- Harness 是“工作系统”。
所以千万不要把 Harness 理解成“有了它就不用写 Prompt”。恰恰相反,Harness 是建立在好 Prompt 和好 Context 之上的更高层工程实践。
6. 最小可用 Harness:先从四个文件开始

OpenAI 的实践里,一个成熟项目可能会有 AGENTS.md、ARCHITECTURE.md、docs/design-docs/、docs/exec-plans/、docs/product-specs/、docs/references/ 等完整文档体系。
但作为入门,不需要一上来就搭这么大。
我们先用四个文件:
AGENTS.md
Product.md
Architecture.md
Session_Handoff.md
它们分别解决四个问题:
| 文件 | 解决的问题 | 一句话定位 |
|---|---|---|
AGENTS.md |
Agent 怎么工作 | 工作规则与文档索引 |
Product.md |
项目要做什么 | 产品目标与需求边界 |
Architecture.md |
项目怎么实现 | 技术架构与实现约束 |
Session_Handoff.md |
现在做到哪了 | 任务进度与交接记录 |
这四个文件加起来,就是一个最小闭环:
目标 → 规则 → 实现边界 → 进度记录 → 下一轮继续。
7. AGENTS.md:Agent 的工作总纲
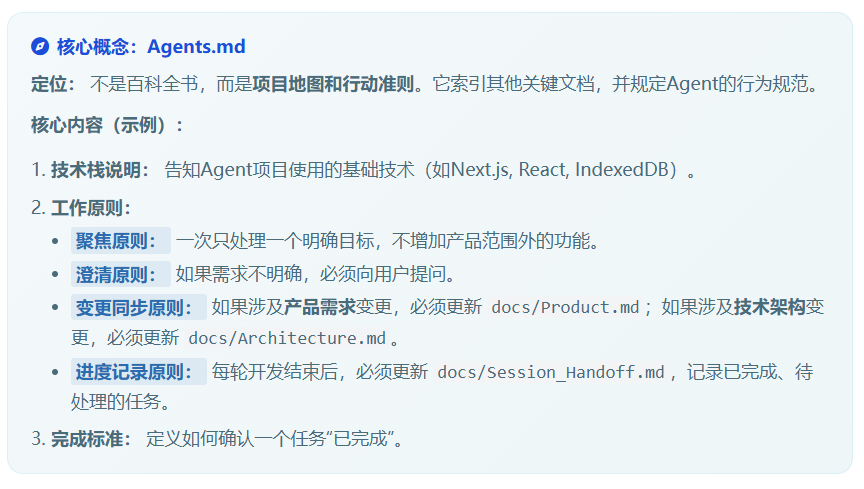
AGENTS.md 是 Agent 进入项目后最先阅读的文件。
它不应该写成一本百科全书,而应该像一张地图:告诉 Agent 去哪里找什么信息,以及必须遵守哪些工作规则。
一个入门版 AGENTS.md 可以这样写:
# AGENTS.md
## 工作原则
1. 每次只处理一个明确目标,不要顺手扩展无关功能。
2. 修改代码前,先阅读 Product.md 和 Architecture.md。
3. 如果需求与架构冲突,先向用户说明冲突,不要自行猜测。
4. 每次完成任务后,必须更新 Session_Handoff.md。
5. 如果实现过程中确认了新的产品需求,更新 Product.md。
6. 如果实现过程中改变了模块边界、数据流或技术约束,更新 Architecture.md。
## 文档索引
- 产品需求:Product.md
- 技术架构:Architecture.md
- 当前进度:Session_Handoff.md
## 验收要求
- 代码能运行;
- 关键路径有测试或手动验证记录;
- 文档与代码保持一致;
- 不引入未确认的新依赖。
AGENTS.md 最重要的作用有三个:
- 防止目标漂移:让 Agent 不要写着写着跑题;
- 打破信息孤岛:把需求、架构、进度都指向固定位置;
- 建立确定入口:无论换哪个 Agent,都知道从哪里开始读项目。
这里有个经验:
如果 Agent 反复犯同一种错误,不要只在聊天里骂它,应该把对应规则沉淀到 AGENTS.md。
这就是 Harness 的反馈循环。
8. Product.md:让 Agent 知道“为什么做”
Product.md 是产品需求文档。

它的重点不是写得多漂亮,而是让 Agent 清楚:
- 这个项目服务谁;
- 用户要完成什么任务;
- 当前版本做哪些功能;
- 哪些功能暂时不做;
- 什么结果才算完成。
入门版模板:
# Product.md
## 项目目标
构建一个本地项目看板,用于管理 AI Agent 开发任务、任务状态和交接记录。
## 目标用户
- 使用 AI 编程工具的独立开发者;
- 需要管理多个 Agent 会话的开发团队。
## 核心功能
1. 创建任务卡片;
2. 标记任务状态:待开始、进行中、已完成;
3. 查看每个任务的最近一次交接记录;
4. 支持按状态筛选任务。
## 暂不支持
- 多人权限系统;
- 云端同步;
- 复杂报表。
## 验收标准
- 用户可以新增、编辑、删除任务;
- 刷新页面后任务不丢失;
- 至少覆盖一个完整任务流:创建 → 进行中 → 完成。
在 Harness 系统里,Product.md 不是一次性文档,而是“活文档”。
当用户新增需求,例如“增加历史对话功能”,Agent 不应该只改代码,还应该把这个需求同步写回 Product.md。
这样下一次会话开始时,项目目标仍然完整。
9. Architecture.md:让 Agent 知道“怎么做”
Architecture.md 是技术架构文档。

它负责告诉 Agent:代码应该长在哪里,模块怎么分,数据怎么流动,哪些边界不能越过。
入门版模板:
# Architecture.md
## 技术栈
- 前端框架:Next.js
- 样式方案:Tailwind CSS
- 数据存储:浏览器 localStorage
- 测试:项目现有测试工具
## 目录结构
```text
src/
├── app/ # 页面入口
├── components/ # 通用 UI 组件
├── features/tasks/ # 任务看板业务逻辑
├── lib/ # 通用工具函数
└── styles/ # 全局样式
```
## 模块边界
- `features/tasks/` 只负责任务领域逻辑;
- `components/` 不直接读写 localStorage;
- 数据读写统一放在 `features/tasks/task-storage.ts`;
- 页面层只负责组装组件,不写复杂业务逻辑。
## 数据结构
```ts
type Task = {
id: string;
title: string;
status: "todo" | "doing" | "done";
handoffNote?: string;
updatedAt: string;
};
```
## 约束
- 不新增状态管理库;
- 不把业务逻辑写进 UI 组件;
- 所有状态变更必须通过任务领域函数完成。
Architecture.md 的价值,是把隐性的架构经验显性化。
没有它时,Agent 会自己猜目录、猜数据结构、猜模块边界。猜得好叫惊喜,猜得不好就是返工。
有了它,Agent 就像拿到施工图纸:它可以更快生成代码,也更不容易破坏整体结构。
10. Session_Handoff.md:让下一轮不要从零开始
Session_Handoff.md 是任务交接清单。

它解决的是长任务最痛的问题:上下文断了,下一轮不知道之前发生过什么。
入门版模板:
# Session_Handoff.md
## 当前目标
完成本地项目看板 MVP。
## 已完成
- [x] 初始化项目结构
- [x] 创建任务卡片 UI
- [x] 实现任务状态切换
## 进行中
- [ ] 将任务数据持久化到 localStorage
## 待处理
- [ ] 增加状态筛选
- [ ] 补充基础测试
- [ ] 优化空状态页面
## 重要决策
- 当前版本使用 localStorage,不引入后端服务;
- 任务状态只保留 todo、doing、done 三种,避免过早复杂化。
## 下一次会话建议
1. 先阅读 AGENTS.md;
2. 再阅读 Product.md 和 Architecture.md;
3. 从“进行中”任务开始:实现 localStorage 持久化;
4. 完成后更新本文件。
任务复杂后,不建议所有交接都塞在一个文件里。可以按日期或功能拆分,例如:
docs/handoffs/
├── 2026-05-20-task-board-mvp.md
├── 2026-05-21-history-feature.md
└── latest.md
但入门阶段,一个 Session_Handoff.md 已经足够。
11. 用这四个文件启动 Agent
当四个文件准备好后,可以这样启动 Agent:
请先完整阅读 AGENTS.md、Product.md、Architecture.md 和 Session_Handoff.md。
阅读后,请根据这些文档继续推进当前项目。
要求:
1. 先复述你理解的当前目标和约束;
2. 只处理 Session_Handoff.md 中标记为“进行中”的任务;
3. 修改代码后进行验证;
4. 完成后更新 Product.md、Architecture.md 或 Session_Handoff.md 中需要同步的部分。
一个正常工作的 Agent,应该表现出这些行为:
- 先读
AGENTS.md,明确工作规则; - 再读
Product.md,理解需求目标; - 再读
Architecture.md,确认实现边界; - 最后读
Session_Handoff.md,接上当前进度; - 实现功能后,更新交接记录;
- 如果需求或架构发生变化,同步更新对应文档。
这时你会发现,协作方式开始变化:
以前你是在“提醒 Agent 不要忘”;
现在你是在“维护一个让 Agent 不容易忘的系统”。
12. 新需求和 Bug 修复应该怎么走?
新需求流程
假设你说:
为 Agent 面板增加历史对话功能。
有 Harness 的项目里,Agent 不应该直接开写。它应该:
- 阅读
AGENTS.md,确认变更规则; - 更新
Product.md,补充历史对话功能描述; - 更新
Architecture.md,说明数据结构和模块边界; - 实现代码;
- 验证核心流程;
- 更新
Session_Handoff.md,记录完成情况和遗留问题。
Bug 修复流程
假设你发现:
Agent 面板没有把完整对话历史传给 LLM,导致模型无法理解上文。
一个更好的 Bug 描述是:
Bug:Agent 面板的提示词组装逻辑没有包含完整对话历史。
预期:
LLM 请求中应包含同一会话内的历史消息,保证模型能理解上下文。
实际:
只传入了当前用户输入,导致模型无法记住前文提到的项目目标。
请根据 Architecture.md 定位相关模块,修复后补充验证记录,并更新 Session_Handoff.md。
重点是:你不只是让 Agent 修一个 Bug,而是让它把“问题、修复、验证、交接”都沉淀下来。
13. Harness 的核心原则:把经验写进系统
做 Harness Engineering,最重要的不是文件名,而是这三个原则。
原则一:AGENTS.md 是地图,不是百科全书
不要把所有细节都堆进 AGENTS.md。
它应该告诉 Agent:
- 产品需求去哪里看;
- 架构规则去哪里看;
- 测试命令去哪里看;
- 当前进度去哪里看。
真正的细节放在更专门的文档里。
原则二:规则必须在仓库里
凡是你希望 Agent 遵守的规则,都不要只放在聊天记录里。
应该写进项目仓库,例如:
AGENTS.mdProduct.mdArchitecture.mddocs/rules.mddocs/testing.mddocs/decisions/xxx.md
因为 Agent 能读仓库文件,却不一定能稳定记住上一段聊天。
原则三:建立反馈循环
Harness 不是一次搭完就结束。
它应该不断进化:
- Agent 犯了同类错误 → 把规则写进文档;
- 需求发生变化 → 更新产品文档;
- 架构边界被突破 → 更新架构约束或增加检查;
- 任务无法接续 → 改进交接文件;
- 验证经常遗漏 → 把验证步骤固化。
真正的 Harness,是会随着项目经验越来越强的。
14. 一句话总结
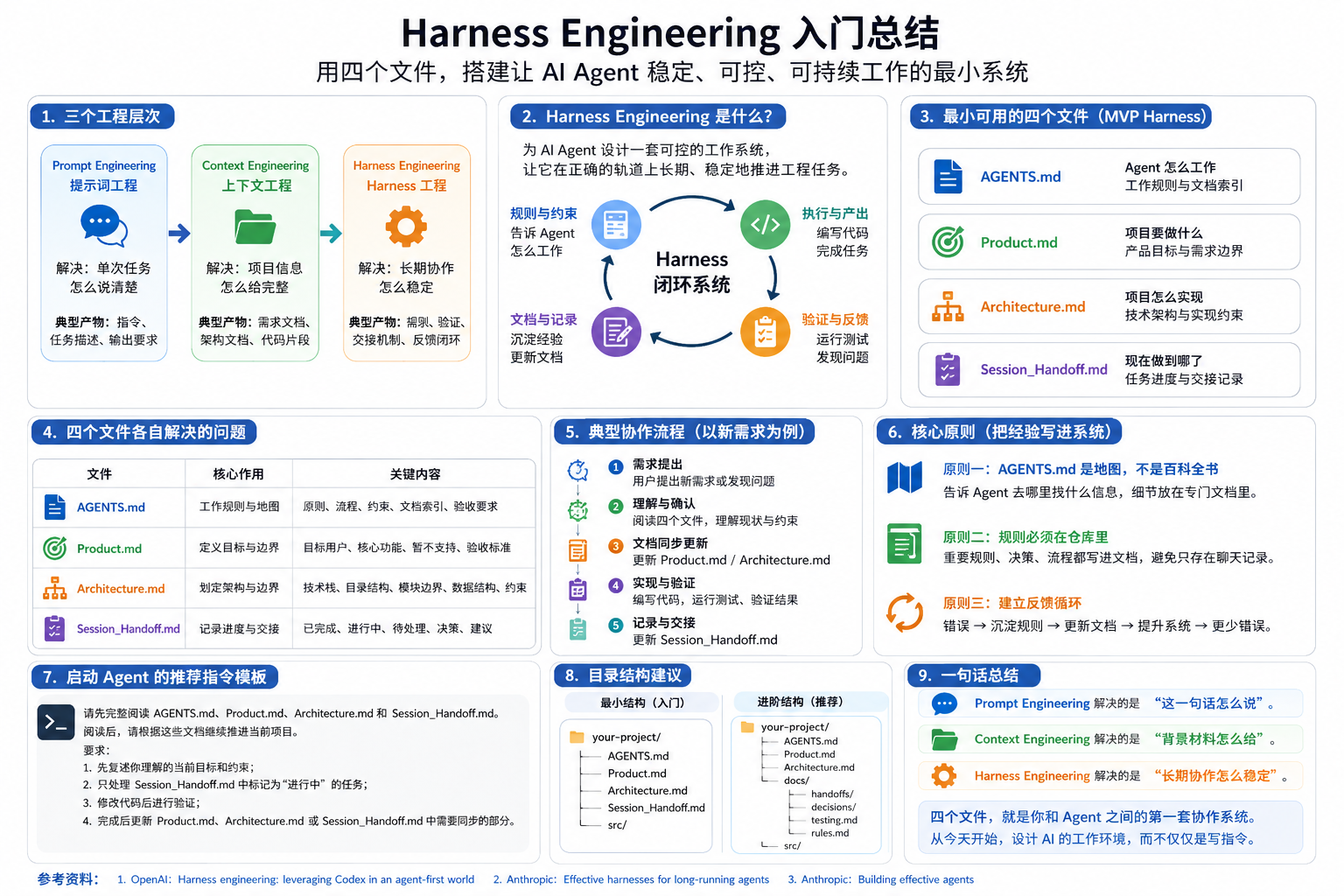
Prompt Engineering 解决的是“这一句话怎么说”。
Context Engineering 解决的是“背景材料怎么给”。
Harness Engineering 解决的是“长期协作怎么稳定”。
如果你只把 AI 当成聊天助手,Prompt 就够了。
如果你想让 AI 参与真实项目,Context 很重要。
如果你想让 AI Agent 长期、稳定、可验证地推进工程任务,就必须开始设计 Harness。
最小起步不复杂:
AGENTS.md # 工作规则与文档索引
Product.md # 产品目标与需求边界
Architecture.md # 技术架构与实现约束
Session_Handoff.md # 当前进度与任务交接
这四个文件,就是你和 Agent 之间的第一套协作系统。
真正的变化也从这里开始:
你不再只是写代码的人,而是设计 AI 工作环境的人。
可直接复制的最小目录结构
your-project/
├── AGENTS.md
├── Product.md
├── Architecture.md
├── Session_Handoff.md
└── src/
如果项目稍微复杂一点,可以升级成:
your-project/
├── AGENTS.md
├── Product.md
├── Architecture.md
├── docs/
│ ├── handoffs/
│ │ └── latest.md
│ ├── decisions/
│ ├── testing.md
│ └── rules.md
└── src/
参考资料

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)