【视觉表征模型】EVA-02: A Visual Representation for Neon Genesis
摘要
是什么:Transformer 架构的视觉表征模型,
怎么做:通过掩码图像建模预训练,
为什么:旨在重建强大且稳健的与语言对齐的视觉特征。
用什么:纯 Transformer 架构+巨型 CLIP 视觉编码器–> 预训练
效果:EVA-02 在多种代表性视觉任务上展现优秀。涵盖了基础视觉任务(分类、检测、分割)以及需要多模态对齐能力的开放词汇任务(图文检索、视频分类),并且同时展示了其在特定数据集微调和通用零样本泛化两方面的表现。
1、介绍
1.1 任务
这些任务主要分为**微调(Fine-tuned)任务和零样本(Zero-shot)**任务:
- 图像分类 (Classification)
- 微调 IN-1K 分类 (fine-tuned IN-1K cls): 在 ImageNet-1K 上进行微调后的分类准确率。
- 零样本 IN-1K 分类 (zero-shot IN-1K cls): 无需在 ImageNet-1K 上进行微调,直接利用预训练知识进行分类的准确率(图中标注了 1K val 数据集和 27 个数据集的平均值)。
- 语义分割 (Semantic Segmentation)
- 预测图像中每个像素所属的类别,但不区分同类中的不同个体。
- ADE20K: 这是一个常见的语义分割基准数据集。
- COCO164K: 使用 COCO 数据集的 164K 图像进行训练和评估。
- 实例分割 (Instance Segmentation)
- 与语义分割类似,但不仅识别物体类别,还能区分同一类别中的不同个体(例如区分图中的两辆不同的车)。
- COCO: 在 COCO 数据集上进行评估。
- LVIS (Large Vocabulary Instance Segmentation): 专注于具有大量类别(长尾分布)的实例分割数据集。
- 目标检测 (Object Detection)
- 识别图像中物体的位置(用边界框标出)及其类别。
- COCO: 在 COCO 数据集上进行评估。
- LVIS: 在 LVIS 数据集上进行评估。
- 图文检索 (Image-Text Retrieval / I2T)
- zero-shot I2T (COCO): 零样本下的图像到文本检索。给定一张图,在文本库中找到最匹配的文本描述。
- zero-shot I2T (Flickr30K): 在 Flickr30K 数据集上进行的零样本图像到文本检索。
- 文本到图像检索 (Text-to-Image Retrieval / T2I)
- zero-shot T2I (COCO): 零样本下的文本到图像检索。给定一段文字描述,在图像库中找到最匹配的图像。
- zero-shot T2I (Flickr30K): 在 Flickr30K 数据集上进行的零样本文本到图像检索。
- 视频分类 (Video Classification)
- zero-shot video cls: 零样本视频分类准确率,图中标注了平均在 4 个数据集上的表现。
- 多模态零样本通用评估
- zero-shot IN-1K cls (avg. 27 datasets): 这是一个更广泛的零样本评估指标,涵盖了 27 个不同的数据集,用于衡量模型在未见过的视觉任务上的泛化能力。
1.2 EVA-02 和VLM是什么关系?
EVA-02 是 VLM(视觉语言模型)的一个组件,一个专门为 VLM 设计的、高性能的视觉编码器(Visual Encoder)。
我们可以这样理解它们的关系:
-
VLM (视觉语言模型) 的整体架构:
一个典型的 VLM(如 CLIP、Flamingo、BLIP 等)通常包含两个核心部分:- 视觉编码器 (Visual Encoder): 负责将输入的图像转换为计算机可以理解的数字特征向量(Embedding)。这个部分处理“视觉”信息。
- 语言模型 (Language Model): 负责处理文本输入和输出。这个部分处理“语言”信息。
- 对齐机制 (Alignment Mechanism): 将视觉编码器的输出和语言模型的输入联系起来,让模型理解图像和文本之间的对应关系。
-
EVA-02 的角色:
- EVA-02 本身是一个强大的视觉编码器。它基于 Transformer 架构,通过大量的图像数据进行预训练,能够学习出非常强大、鲁棒的视觉特征表示。
- 它的设计目标之一就是“重建强大且稳健的语言对齐的视觉特征”(reconstruct strong and robust language-aligned vision features)。这意味着它在预训练时就考虑到了后续与语言模型进行对齐的需求。
- EVA-02 提供了多个不同大小的模型变体(从 6M 到 304M 参数),使得用户可以灵活地将其集成到 VLM 中,以平衡性能和计算资源。
-
EVA-02 如何赋能 VLM:
- 当开发者想要构建一个新的 VLM 时,他们需要选择一个好的视觉编码器。EVA-02 就是一个非常出色的候选者。
- 研究人员可以将 EVA-02 作为 VLM 的“眼睛”,将图像输入到 EVA-02 中,EVA-02 会生成高质量的图像特征向量。
- 然后,这些特征向量可以被送入 VLM 的其他部分(如语言模型和对齐机制)进行进一步处理,从而实现图像理解、图文匹配、视觉问答等 VLM 的核心功能。
1.3 最近
最近的研究进展促使人们越来越关注视觉 [81, 44, 124, 17] 以及视觉-语言 [140, 123, 30, 139] 表示的规模化扩展。这些工作基于一种信念,即增加参数数量、数据规模和计算资源预算,最终将带来性能的提升 [63, 142, 134, 93]。
然而,计算机视觉领域出现了日益扩大的差距:一方面是在性能和规模上达到最先进的大模型,另一方面是广大研究社区能够负担得起的模型。训练、微调以及评估这些超大规模视觉模型需要大量的计算资源,其成本高昂且耗时严重,往往令人望而却步。因此,大型视觉表示(isual representations )通常以少样本甚至单样本的方式进行训练,这限制了将整个训练流程充分优化的能力。
在本工作中,我们提出 EVA-02,这是一系列经过稳健优化的纯视觉转换器(ViTs)[118, 41],模型规模适中,并具备可迁移的双向视觉表征 [40, 80],这些表征通过掩码图像建模(MIM)预训练 [5] 从一个强大的 CLIP [95, 44] 视觉编码器中学习得到。
- 非单向的信息流动:
* 传统的自回归语言模型或某些单向Transformer使用自注意力机制时,Token只能“看到”它之前已经处理过的Token(因果注意力)。
* 而双向注意力允许当前的Token同时关注它之前和之后的所有其他Token。这意味着在计算每个Token的特征时,模型能够整合整个图像上下文的信息,而不是逐步累积信息。- 在EVA-02中的具体实现:
* EVA-02通过**掩码图像建模(Masked Image Modeling, MIM)**预训练来学习这种双向表征。在MIM任务中,图像的一部分被掩码(隐藏),模型需要根据可见的部分来预测掩码的部分。
* 为了准确预测被掩码的区域,模型必须能够双向地理解图像中各个部分之间的关系。这种训练方式迫使视觉Transformer学习图像中全局的、双向的上下文依赖关系,从而提取出更丰富、更鲁棒的特征。
EVA-02 参数量对比 ViT
-
ViT (Vision Transformer) 变体:
- ViT-B/16: 大约 1.88 亿参数 (187M)
- ViT-B/32: 大约 1.88 亿参数 (187M)
- ViT-L/14: 大约 3.08 亿参数 (308M)
- ViT-L/14@336px: 大约 3.08 亿参数 (308M)
- ViT-H/14: 大约 4.46 亿参数 (446M) - 这是 CLIP 中最大的 ViT 模型之一。
-
ResNet 变体 (较早版本):
- ResNet-50: 大约 2.5 亿参数 (250M)
- ResNet-101: 大约 4.4 亿参数 (440M)
- 常见的、广泛使用的 CLIP 模型(如 ViT-B/16, ViT-B/32, ViT-L/14)的参数量通常在 1.8亿 到 3亿 之间。
- 最大的 CLIP 视觉编码器(如 ViT-H/14)参数量约为 4.46亿。
- 相比之下,EVA-02 最大的变体(EVA-02 304M)有 3.04亿 参数,与 ViT-L/14 相当。
令人瞩目的是,
- 仅使用3800万条公开可访问的数据,EVA-02的轻量级变体(仅含2200万参数)在ImageNet-1K验证集[105]上实现了85.8%的微调top-1准确率;
- 而包含3.04亿参数的大型模型则达到了90.0%的优异微调top-1准确率。
此外,我们表明,通过MIM预训练的EVA-02表示来初始化CLIP的图像编码器,可在IN-1K验证集上实现高达80.4%的零样本top-1准确率,优于此前参数量约为其1/6、图像-文本训练数据量约为其1/6的规模最大且性能最优的开源CLIP-Giant模型[1]。
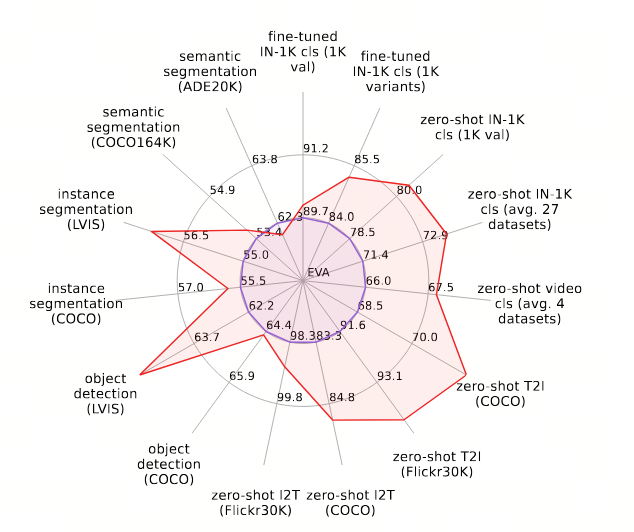
- EVA-02在其他代表性视觉任务上也取得了最先进的性能,包括在LVIS[50]上的目标检测和实例分割(验证集上APbox为65.2,APmask为57.3)和COCO[78]上的目标检测和实例分割(test-dev集上APbox为64.5,APmask为55.8),以及在COCO-stuff-164K[16](mIoUss为53.7)和ADE20K[147](mIoUss为61.7,mIoUms为62.0)上的语义分割。关于EVA-02性能的定量总结,请参阅表1。

2. Approach
2.1. Architecture
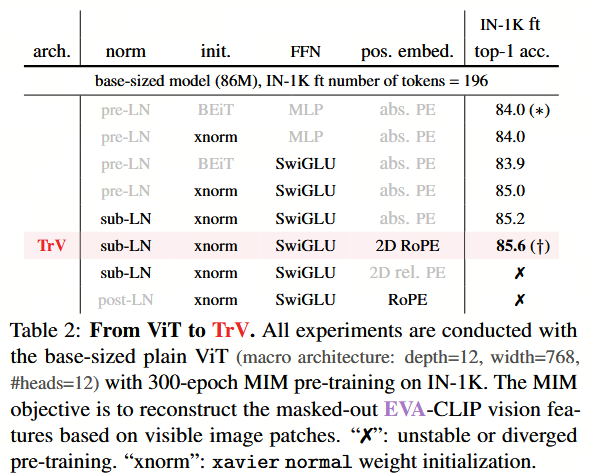
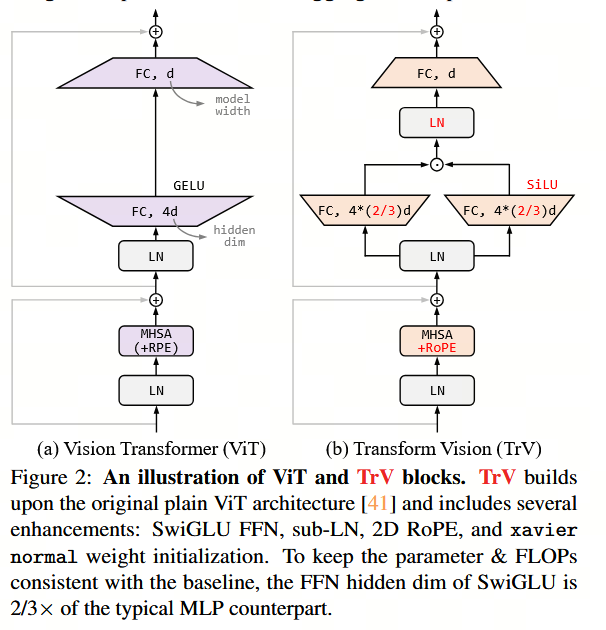
尽管自2020年提出以来,基础视觉Transformer(ViT)的块内微架构持续演进[109, 117],但我们注意到,语言模型中一些重要的架构进展尚未在视觉表征学习中得到充分探索。这些进展包括:
- 将带有Sigmoid线性单元(SiLU)[56]或Swish激活[99]的门控线性单元(Gated Linear Unit)[37, 110]用作前馈网络;
- 采用子层归一化(sub-LN)[4, 122]作为归一化层;
- 以及使用2D旋转位置编码(RoPE)[113]注入位置信息。
2.2. Pre-training Strategy
(1) 较小规模教师 VQKD-B [92] 和 CLIP-B [95] 相比,当学生模型为在 IN-1K 上进行 300 轮预训练时,使用 EVA-CLIP 作为目标教师的准确率下降
(2)我们推测,随着教师模型变强,学生模型在短时间内学会鲁棒且可迁移表示的难度也随之增加。
(3)因此,学生模型需要更长时间的预训练,才能充分掌握教师的知识。当我们把预训练周期延长至 1600 轮(约 100 万步)时,以 EVA-CLIP 为 MIM 教师的 TrV 相较于 BEiTv2 [92] 取得了 1.3 个点的非平凡提升。
2.3 掩码图像建模(Masked Image Modeling, MIM)
掩码图像建模(Masked Image Modeling, MIM)是一种在计算机视觉中强大的自监督学习技术。其核心思想是:随机遮挡图像的一部分,然后让模型根据可见的部分去预测或重建被遮挡的部分。
2.3.1. 核心流程
-
输入处理:
- 输入一张图像。
- 将图像分割成多个小块(Patches),例如 14×1414 \times 1414×14 像素的方块。
- 将这些小块转换为 Token(类似于自然语言处理中的 Word Token)。
-
掩码(Masking):
- 随机遮蔽:随机选择一部分 Patch,将其从输入中移除,并用一个特殊的
[MASK]Token 替换。 - 掩码比率:通常保留约 60% 的 Patch 可见,掩码掉约 40%-90% 的 Patch(EVA-02 使用的是块状掩码,掩码率为 40%)。
- 目的:强迫模型不仅仅依靠局部特征,而是必须理解图像的全局上下文结构。
- 随机遮蔽:随机选择一部分 Patch,将其从输入中移除,并用一个特殊的
-
编码器处理(Encoder):
- 将包含
[MASK]Token 的 Patch 序列输入到一个 Transformer 编码器(如 ViT)中。 - 注意:在 MIM 中,
[MASK]Token 通常也会作为输入参与注意力计算,或者在计算注意力时被排除,具体取决于实现,但目标是根据可见区域推断掩码区域。
- 将包含
-
预测头(Prediction Head):
- 编码器输出每个位置的特征向量。
- 对于可见的 Patch,通常不需要预测(或者作为上下文)。
- 对于被掩码的 Patch,模型通过一个轻量级的预测头(通常是多层感知机 MLP)来预测这些位置应该是什么。
-
计算损失(Loss Function):
- MIM 需要一个“靶子”(Target)来进行对比。
- EVA-02 的做法:使用一个强大的、预先训练好的教师模型(如 EVA-CLIP)提取被掩码 Patch 对应的特征向量,作为目标特征(Target Representation)。
- 传统 MIM 的做法:直接预测原始像素值(如像素 RGB 值)或离散化的代码(如 VQGAN 生成的 code)。
- 损失计算:计算模型预测的特征与教师模型提取的真实特征之间的差异。常用损失包括:
- 均方误差(MSE Loss)
- 负余弦相似度(Negative Cosine Similarity):EVA-02 使用此方法,最大化预测特征与目标特征的相似度。
-
反向传播与更新:
- 根据损失值反向传播,更新学生模型(Student Model,即正在训练的 ViT)的参数。
3.2.2. MIM 的关键优势
- 捕捉全局上下文:由于遮挡比例高,模型必须理解图像的整体语义才能填补缺失部分,这比传统的对比学习(如 SimCLR,主要关注局部增强)能学到更丰富的全局特征。
- 自监督:不需要人工标注标签(Label-free),只需大量无标签图像。
- 通用性:学到的特征可以迁移到各种下游任务(分类、检测、分割等)。
3.2.3. EVA-02 中 MIM 的特殊之处
,EVA-02 对 MIM 进行了以下优化:
- 教师模型(Teacher):使用一个十亿参数(1B)的 EVA-CLIP 作为教师,提取语言对齐的视觉特征作为 MIM 的目标。这比直接预测像素值更能学到语义丰富的表示。
- 双向注意力:使用纯 Transformer(Plain ViT)并开启双向注意力,允许每个 Token 访问全局信息。
- 架构优化:引入了 SwiGLU 前馈网络、Sub-LN 归一化和 2D RoPE 位置编码,提升了 MIM 训练的稳定性和效果。
- 块状掩码(Block-wise Masking):不是随机掩码单个 Patch,而是随机掩码连续的块,这更符合人类视觉感知的逻辑。
2.4 预训练目标
预训练目标与 EVA [44] 类似,即仅基于可见的图像块,回归被遮蔽的图像-文本对齐视觉特征。我们使用 [MASK] 标记对输入图像块进行损坏,并遵循 [5, 44] 采用块级掩码策略,掩码比例为 40%。MIM 预训练的目标表征来自公开可用的、拥有一十亿参数的 EVA-CLIP [44] 视觉塔。EVA-02 的输出特征首先进行归一化 [4],然后通过一个线性层投影至与 EVA-CLIP 视觉特征相同的维度。我们使用负余弦相似度作为损失函数。
2.5 具体实现
我们采用了开源的 EVA 实现 [91, 44, 43]。在训练过程中,我们使用 DeepSpeed [102] 并配置 ZeRO Stage-0/Stage-1 优化器,结合带有动态损失缩放 [98] 的 fp16 精度。所有多头自注意力(MHSA)操作均通过 xFormers [72] 进行加速。尽管我们的掩码图像建模(MIM)教师模型包含十亿参数,但其实际预训练时间较官方发布的 BEiT 系列实现 [5, 92] 缩短了约 10%。
2.5.1 1. BEiT Series (基于 BERT 的图像预训练系列)
BEiT (BERT pre-Image) 是由微软亚洲研究院(MSRA)提出的一系列视觉预训练方法。它的核心灵感来自自然语言处理中的 BERT 模型,旨在将 NLP 中的成功范式迁移到计算机视觉领域。
-
核心思想:
传统的视觉预训练(如 ImageNet 分类)需要标签,而对比学习(如 MoCo, SimCLR)虽然无需标签,但存在负样本采样等复杂问题。BEiT 提出使用自监督的离散预测任务。- 首先使用 VQ-VAE 将图像量化为一组离散的“视觉词”(Visual Tokens/Words),构建一个视觉词典(Visual Dictionary)。
- 然后,将图像视为由这些“视觉词”组成的序列。
- 随机掩盖一部分视觉词,让模型根据上下文预测被掩盖的视觉词。这被称为掩码图像建模(Masked Image Modeling, MIM)。
-
BEiT Series 的演进:
- BEiT-1:提出了基于离散 token 预测的 MIM 预训练框架,证明了 MIM 在视觉上的有效性。
- BEiT-2:引入了双向编码(Bi-directional Encoding),即 Transformer 中的注意力机制可以同时看到前后文,从而提取更丰富的双向特征表示。
- BEiT-3:进一步扩展,提出了多模态预训练框架,能够同时处理图像、文本和视觉-语言对齐,是通往 CLIP 类模型的重要一步。
-
与 EVA-02 的关系:
在文中,BEiT 系列被视为 MIM 预训练的基线(Baseline)或先驱。EVA-02 的作者通过实验证明,在保持 MIM 框架的同时,通过改进架构(如 TrV)、使用更强大的教师模型(EVA-CLIP)和更长的训练时间,可以超越之前 BEiT 系列的最佳性能。
2.5.2. ZeRO Stage-0 / -1 Optimizer (DeepSpeed 中的优化器加速技术)
DeepSpeed 是微软开发的一个深度学习优化库,旨在加速大规模模型的训练和推理。ZeRO (Zero Redundancy Optimizer) 是 DeepSpeed 的核心技术,用于解决分布式训练中的内存瓶颈。它通过减少冗余数据来节省显存,从而允许训练更大的模型或使用更大的批次大小。
DeepSpeed 提供了不同阶段的 ZeRO,Stage-0 和 Stage-1 是最基础的两个阶段,主要关注优化器状态的优化:
-
ZeRO Stage-0:
- 功能:这是最基础的模式。它主要对 Optimizer States(优化器状态,如动量、方差)和 Gradients(梯度)进行分割(Partitioning)。
- 内存节省:每个 GPU 只保存属于自己的那部分优化器状态和梯度,而不是每个 GPU 都保存一份完整的副本。这可以节省大量显存。
- 适用场景:当模型参数本身占用显存不多,但优化器状态占用较多时(例如 Adam 优化器需要保存均值和方差,占用 2 倍参数量的显存)。
-
ZeRO Stage-1:
- 功能:在 Stage-0 的基础上,进一步对 Gradients(梯度)进行分割。
- 内存节省:除了优化器状态,梯度也被分割存储在每个 GPU 上。前向传播时,每个 GPU 计算自己的梯度并存储;反向传播时,梯度被收集、聚合以更新参数,然后再次分割存储。
- 适用场景:当模型参数、优化器状态和梯度都较大时,Stage-1 能进一步减少显存占用。
-
为什么 EVA-02 使用 ZeRO Stage-0/-1?
- 效率高:Stage-0 和 Stage-1 带来的通信开销相对较小,计算效率高。对于 EVA-02 这样参数量适中(最大 304M)但通过 MIM 需要大量数据并行训练的模型,这些阶段足以显著降低显存占用,而不会像更高阶段(如 Stage-3,会分割模型参数本身)那样引入过大的通信瓶颈。
- 配合 FP16:文章提到使用 fp16(16位浮点数)和 动态损失缩放(Dynamic Loss Scaling)。FP16 本身就将参数和梯度的显存占用减半。结合 ZeRO Stage-0/1,可以在保证训练速度的同时,将显存需求降至最低,使得在有限数量的 GPU 上训练大规模 MIM 模型成为可能。
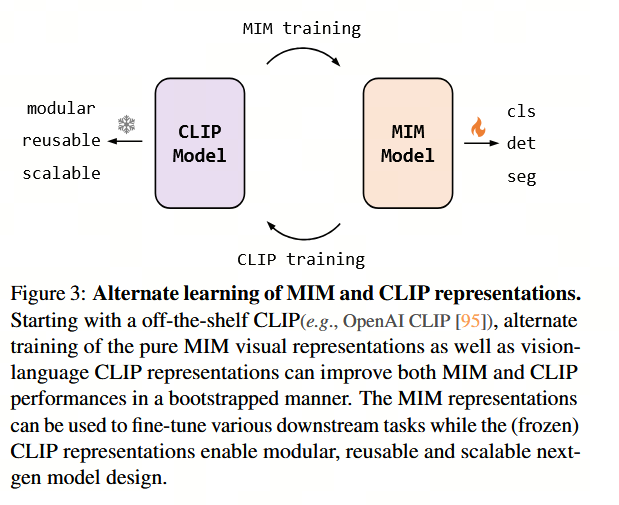
2.6 自举提升
纯 MIM 视觉表示与视觉-语言 CLIP 表示的交替训练可以以自举的方式提升 MIM 和 CLIP 的性能(见图 3)。这表明了一种有前景且可扩展的预训练方法,可用于不同规模的视觉和视觉-语言表示的预训练,值得在未来研究中进一步探索。
5. 讨论与结论
在本研究中,我们旨在为视觉和视觉-语言表征学习的持续研究做出贡献。我们并未提出一种全新的架构或方法,而是对现有的基于MIM预训练、以CLIP视觉特征作为预文本任务目标的方法进行了深入的评估。我们的实验表明,如果在鲁棒性优化得当的情况下,该方法能够生成高性能、低成本且具备良好迁移能力的表征,其表现优于规模更大的先进专用模型。
我们的分析揭示,小型和大尺寸的EVA-02模型可以被有效利用,以获取紧凑且表达能力强的CLIP表征,这有望为未来模块化、可复用且可扩展的模型设计提供助力 [100, 3, 26, 73]。我们对中等规模模型的研究发现,也为未来在模型和表征缩放方面的研究提供了有价值的参考。
此外,结合EVA [44],我们证明了交替训练纯MIM视觉表征以及视觉-语言CLIP表征,能够以自举(bootstrapped)的方式同时提升MIM和CLIP的性能(如图3所示)。这表明了一种前景广阔且可扩展的预训练方法,可用于训练不同规模的视觉和视觉-语言表征,值得在未来的研究中进一步探索。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 5
5 0
0- 0



 已为社区贡献34条内容
已为社区贡献34条内容

所有评论(0)