AI很好,但你真的敢把公司核心数据喂给它吗?

上周开周会,我们团队的产品经理小王跟我说,这个月的某云API账单又超标了,因为团队用AI辅助开发越来越频繁,每次都把业务数据当成测试样本往上扔。我也没好意思说他,因为我自己也干过类似的事——赶项目的时候,谁有空花半小时整理脱敏数据?
直到我看到了一起近期曝光的数据泄露事件:某教育机构内部系统维护人员批量导出学生信息,导致大量个人数据在非正规渠道流转。更让人细思极恐的是,信息泄露的源头往往就在系统内部——维护商和数据平台要么被攻破,要么在管理上存在严重漏洞。
关我什么事?
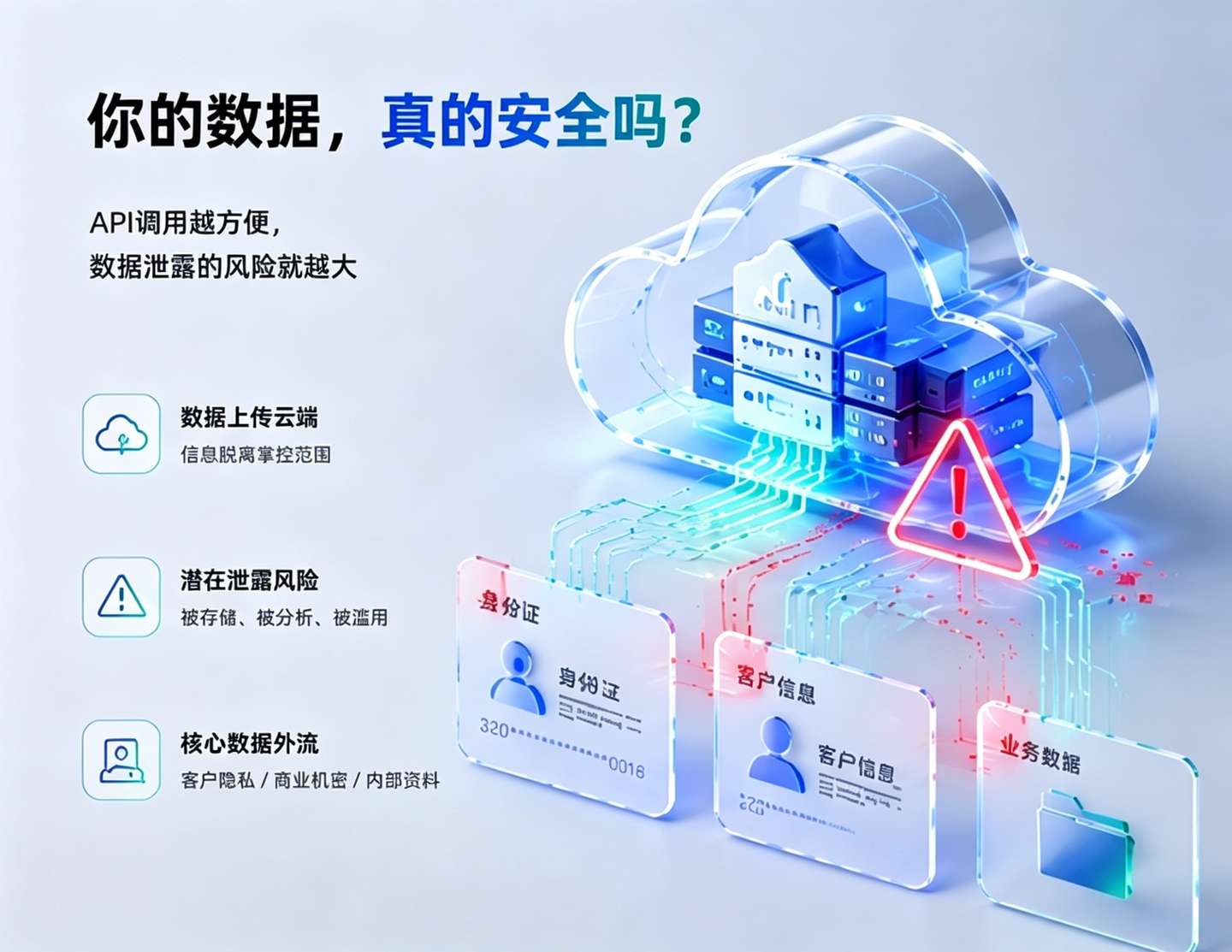
我们天天跟团队讲“数据驱动”,把业务数据往云端AI服务里灌,训练模型、做知识库检索、跑代码分析。但有没有想过一个问题:那些大模型API背后的公司,真的能管好你的数据吗?
我不是危言耸听。根据某国际研究机构的一份报告,企业部署AI时面临的两大阻力,排在最前面的就是数据隐私和数据主权。简单来说,你拿来训练模型的数据里面可能躺着客户身份证、商业机密、未公开的产品设计稿——这些东西一旦通过API流向训练语料库,就再也收不回来。你把数据喂给云端的AI模型,就像你把家钥匙给了一个陌生人,然后跟他说“别乱进”——他会听吗?
上述数据泄露事件就是个触目惊心的反面教材。泄露的数据包括姓名、身份证号、家庭住址等敏感信息,而信息系统的维护商和平台供应商都负有不可推卸的责任。你想,连这种正规业务关系中都可能存在管理失责,你在云端调用AI API的时候,谁能打包票你的业务数据不会被“顺手”存下来?
有评论指出,平台责任不能忽视——那些轻易流出数据的维护商,到底是主动违规还是管理松懈,都值得深究。放在AI云端服务上,这句话同样该问:那些你付费调用的模型服务方,会不会也存在数据使用的灰色地带?
所以我是怎么干的?
今年我带着团队做的第一个硬性决策:把AI基础设施从云端API全链迁移到本地化部署。
你现在可以搜到很多讨论“AI私有化”的文章。所谓AI私有化,就是把大模型部署在自己的机房或者私有云里,所有业务数据和运行日志都留在内网,全程不往外传一滴水。这样做的代价是开发部署成本确实比直接用API高不少,还需要配备专门的硬件资源和管理团队。
但性价比怎么算?我举个例子。假设你们公司一年有500个用户调用云端AI API来做知识库问答或者代码分析。按照现在主流的模型收费标准,云端调用的年费可能需要数十万人民币。换成本地化部署,一次性模型授权加硬件投入可能上百万,但账面上多了什么? 不仅仅是省钱。你多了什么?数据安全、合规保障、以及最重要的是——你不会因为数据泄露风险而陷入被动的法律纠纷。
当然,你要是有个CTO朋友在公司预算会上为了说服CEO多投50万买GPU吵架吵到脸通红的经历,你一定会更理解我说的“这钱花得值”——反正我已经熬过那个阶段了,现在的状态是:CEO觉得我有点偏执,但合规一查,谁也不吭声。

一点不成熟的建议
如果你现在正在选型企业级的AI解决方案,别只盯着功能和价格。去问问供应商一句话——“我们的数据,你们到底拿不拿?”
我见过太多项目上线前报价比价谈得风生水起,结果上线半年后才发现合同角落里写着“数据可用于模型优化”。我也见过团队为了图省事,直接把包含客户敏感信息的测试集贴在提示词框里——每次看到这种情况,我都难免紧张。
这些层出不穷的数据泄露事件,就是给你我的一个预警:数据不放在自己手里,就等于在给别有用心的人送钱。 AI时代的技术红利当然要拥抱,但底线必须划清楚:数据主权,寸步不让。
讨论问题
-
你们的团队在用云端的AI API时,会定期做数据脱敏自检吗?有没有遇到过“数据可能被滥用”的真实场景?
-
如果你的CEO/老板坚持用便宜甚至免费的云端AI服务,你会怎么说服他/她多花钱做本地化安全部署?

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 14
14 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)