成都制造企业设备维修知识库怎么建?
维修知识库不是资料柜,而是设备经验的生产系统
成都制造企业推进数字工厂时,最容易忽视的一类知识,往往不是工艺图纸或质量标准,而是设备维修经验。产线出问题时,真正有价值的信息常常藏在几个地方:老员工的口头判断、班组长的微信群截图、设备厂家的 PDF 手册、纸质点检表、EAM 里的维修单,以及仓库里不完整的备件记录。
这些信息单独看都不算复杂,但一旦进入现场,就会变成管理难题。新员工不知道同类故障上次怎么处理;维修主管很难判断某个部件是否进入高频异常;采购部门不知道哪些备件应该提前备货;财务看到的是维修费用增加,却看不到背后的设备、班组和工况原因。
所以,设备维修知识库的目标不应只是把资料上传到一个系统里,而是把维修经验变成可以被搜索、引用、校验和持续更新的生产知识资产。它服务的对象不是文档管理员,而是车间主管、维修工程师、设备经理、仓库管理员和经营负责人。
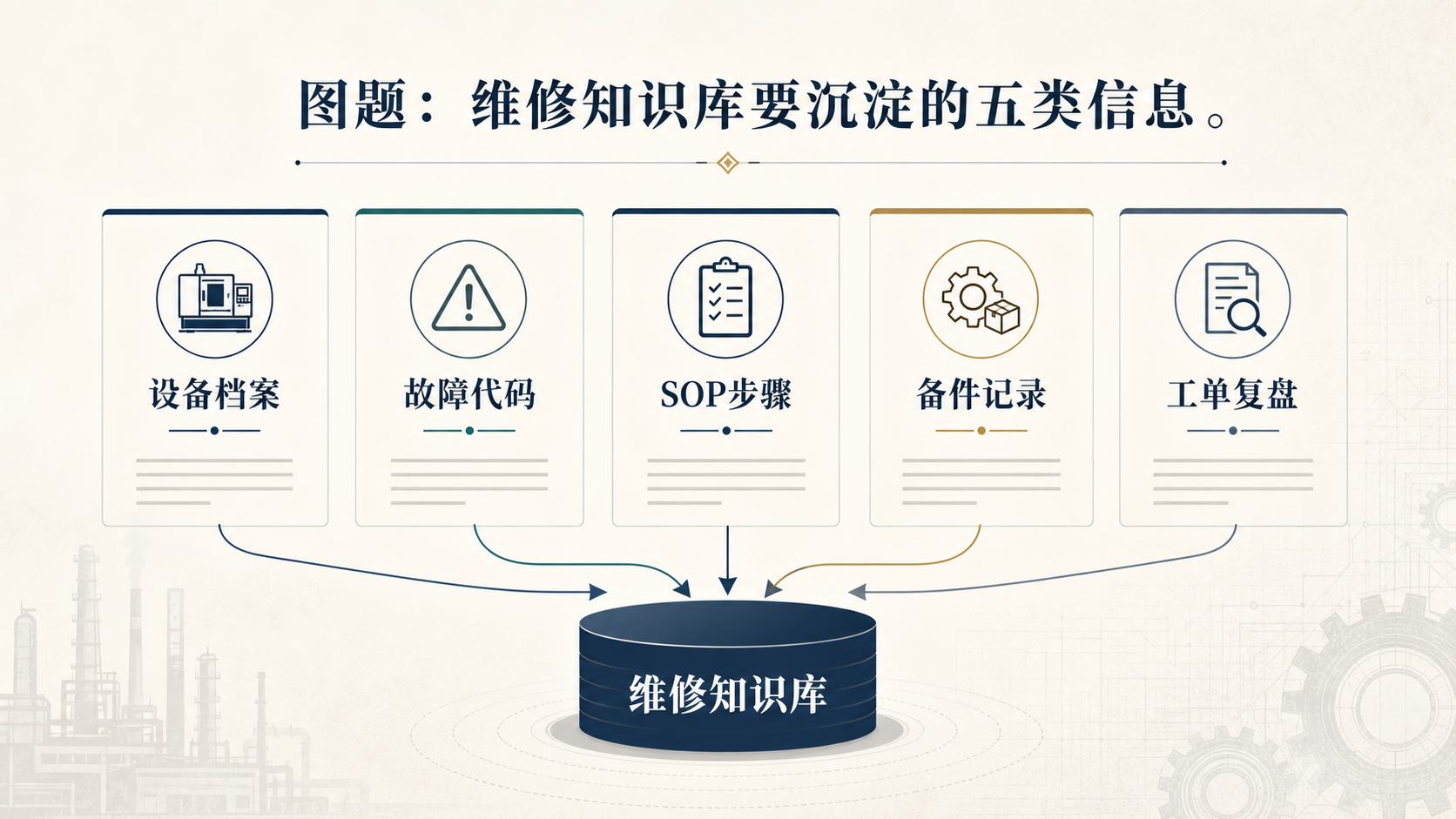
第一步:先选高频停机设备,不要从全厂大而全开始
很多企业做知识库失败,是因为一开始就想把全厂设备、全部资料、所有工单一次性整理完。结果项目周期拉长,现场人员配合成本高,知识格式也难统一。更稳妥的做法,是先选择三类设备:一是影响产线停机的关键设备,二是故障发生频率高的设备,三是维修经验依赖老师傅判断的设备。
围绕这些设备,企业可以先整理五类内容:设备台账、故障代码、SOP 步骤、备件记录和工单复盘。设备台账解决“这台设备是谁、在哪里、什么版本”;故障代码解决“报警意味着什么”;SOP 步骤解决“标准处理动作是什么”;备件记录解决“换什么、库存够不够、替代件能不能用”;工单复盘解决“这次处理是否有效,是否值得沉淀”。
在这个阶段,不需要追求知识库看起来多么庞大。更重要的是让一线人员愿意用,并且能在真实故障场景里查到答案。一个覆盖 20 台关键设备、能够稳定解决 30 个高频故障的问题库,通常比一个堆满 PDF 却没人检索的知识库更有价值。
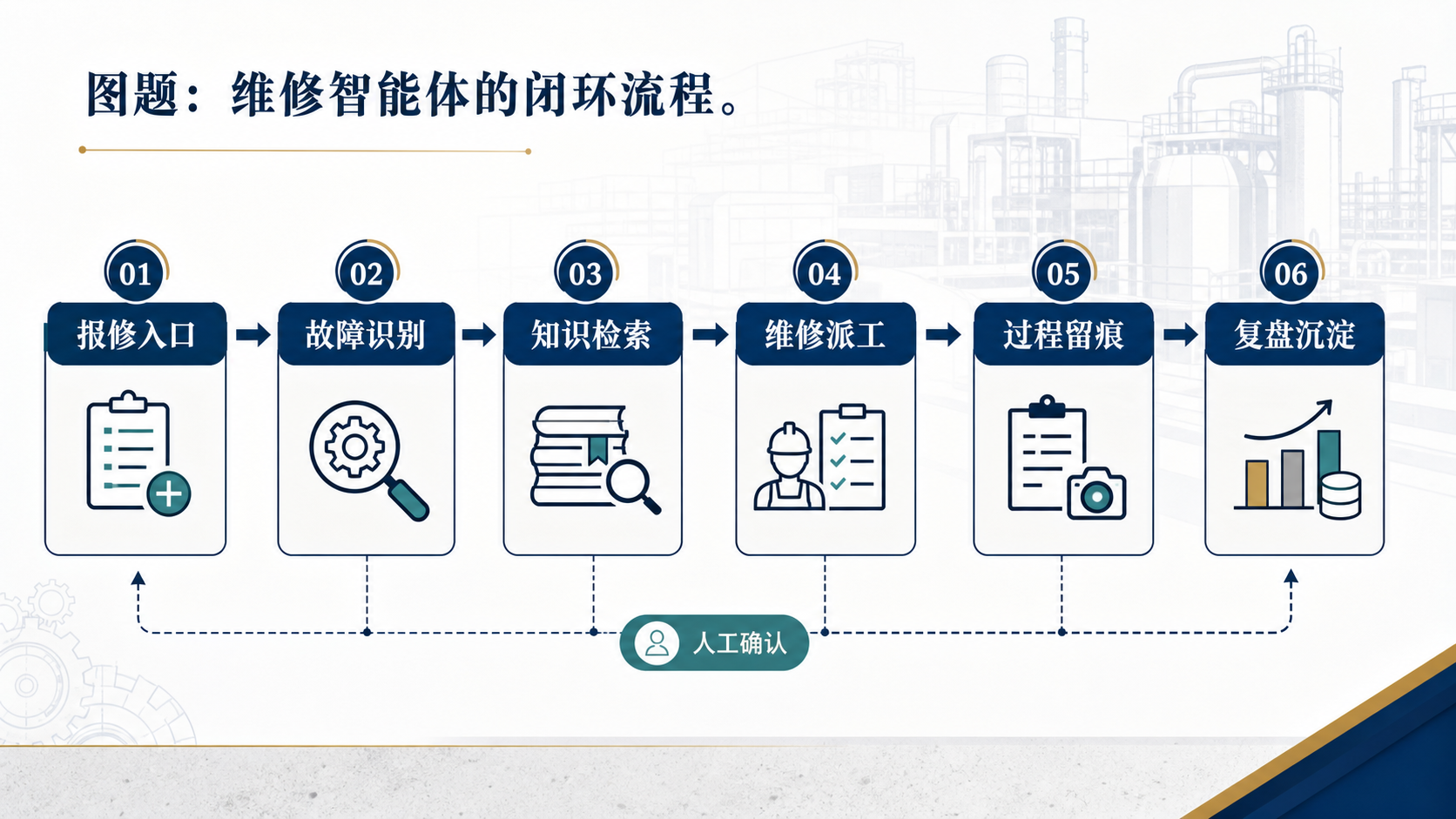
第二步:把维修智能体放进工单闭环,而不是单独做问答
设备维修知识库真正产生价值,通常发生在工单流转中,而不是员工坐在电脑前单独问问题。报修入口、故障识别、知识检索、维修派工、过程留痕、复盘沉淀,这几个环节必须连起来,维修智能体才有机会减少重复沟通和经验流失。
例如,操作工提交报修时,系统可以引导填写设备编号、报警代码、现场照片、停机影响和紧急程度;维修智能体根据历史工单和设备资料,给出可能原因、排查顺序、注意事项和备件建议;维修主管再根据权限和现场情况确认派工。维修结束后,智能体可以辅助生成复盘摘要,但最终确认仍应由维修负责人完成。
这里的关键不是让 AI 替人修设备,而是减少无效沟通、降低经验检索成本,并让每一次维修都成为下一次维修的知识输入。尤其对有多班组、多产线、多厂区的制造企业来说,这种闭环比单纯上线一个知识问答系统更接近业务结果。
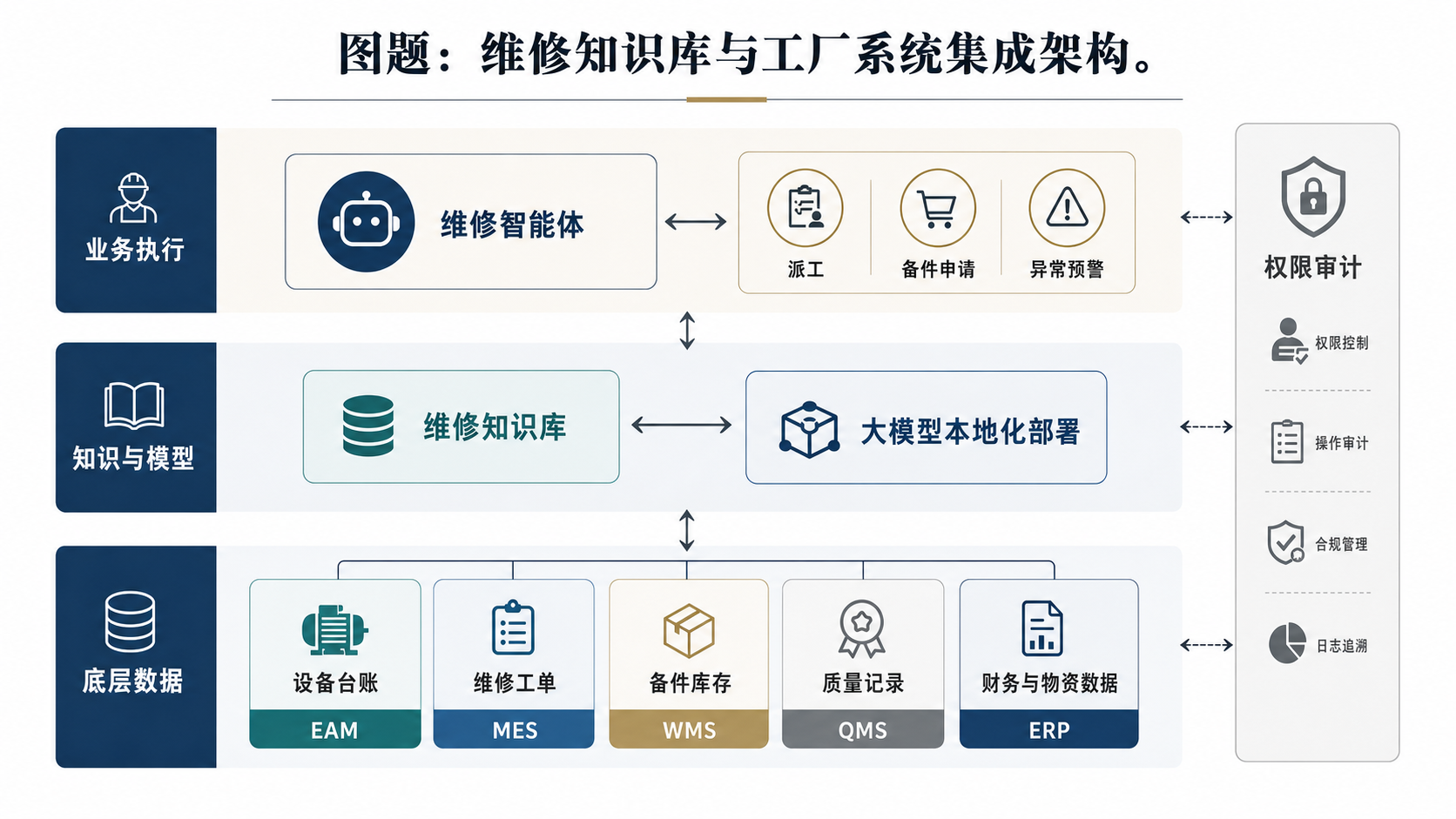
第三步:与 EAM、MES、ERP、WMS 打通数据口径
维修知识库如果只停留在文档层,后期很容易变成孤岛。设备维修牵涉多个系统:EAM 里有设备台账和维修工单,MES 里有产线、班次和停机信息,ERP 里有采购与成本,WMS 里有备件库存,QMS 里有质量异常。企业要让 AI 辅助判断,就必须把这些数据口径逐步对齐。
对成都制造企业来说,这一步不一定要一次性做成复杂的数据中台。更现实的路径,是先明确几个关键字段:设备编号、产线位置、故障类别、维修动作、备件编码、停机时长、责任班组、复发次数。只要这些字段在工单、库存和生产记录之间能被稳定关联,维修智能体就能开始做更可靠的检索和提示。
逐米时代在数字工厂和企业智能体项目中,会特别关注这种系统集成边界。因为企业 AI 应用的难点经常不在模型能不能回答,而在回答时能不能拿到正确的数据、遵守权限范围,并把结果回写到业务系统里。设备维修场景尤其如此,错一个备件、漏一个停机原因,后面都会影响成本和产能判断。
第四步:权限和审计要提前设计,不能等上线后补
设备维修知识库看似是内部技术资料,但里面可能包含供应商价格、备件替代策略、产线瓶颈、设备故障弱点和生产节拍信息。不同角色能看到什么、能修改什么、能让智能体执行什么动作,需要在项目初期就定义清楚。
一线操作工可以提交报修和查看标准处理建议,但不应随意修改设备 SOP;维修工程师可以补充故障复盘,但关键知识更新应经过审核;仓库人员可以看到备件库存和领用建议,但不应查看全部维修成本;管理层可以看停机趋势和成本分析,但不必进入每个技术细节。
如果企业计划做大模型本地化部署或私有化部署,权限审计更要和知识库、工单系统、账号体系一起设计。否则 AI 看似提高了检索效率,却可能把原来分散在系统里的敏感信息一次性暴露出来。
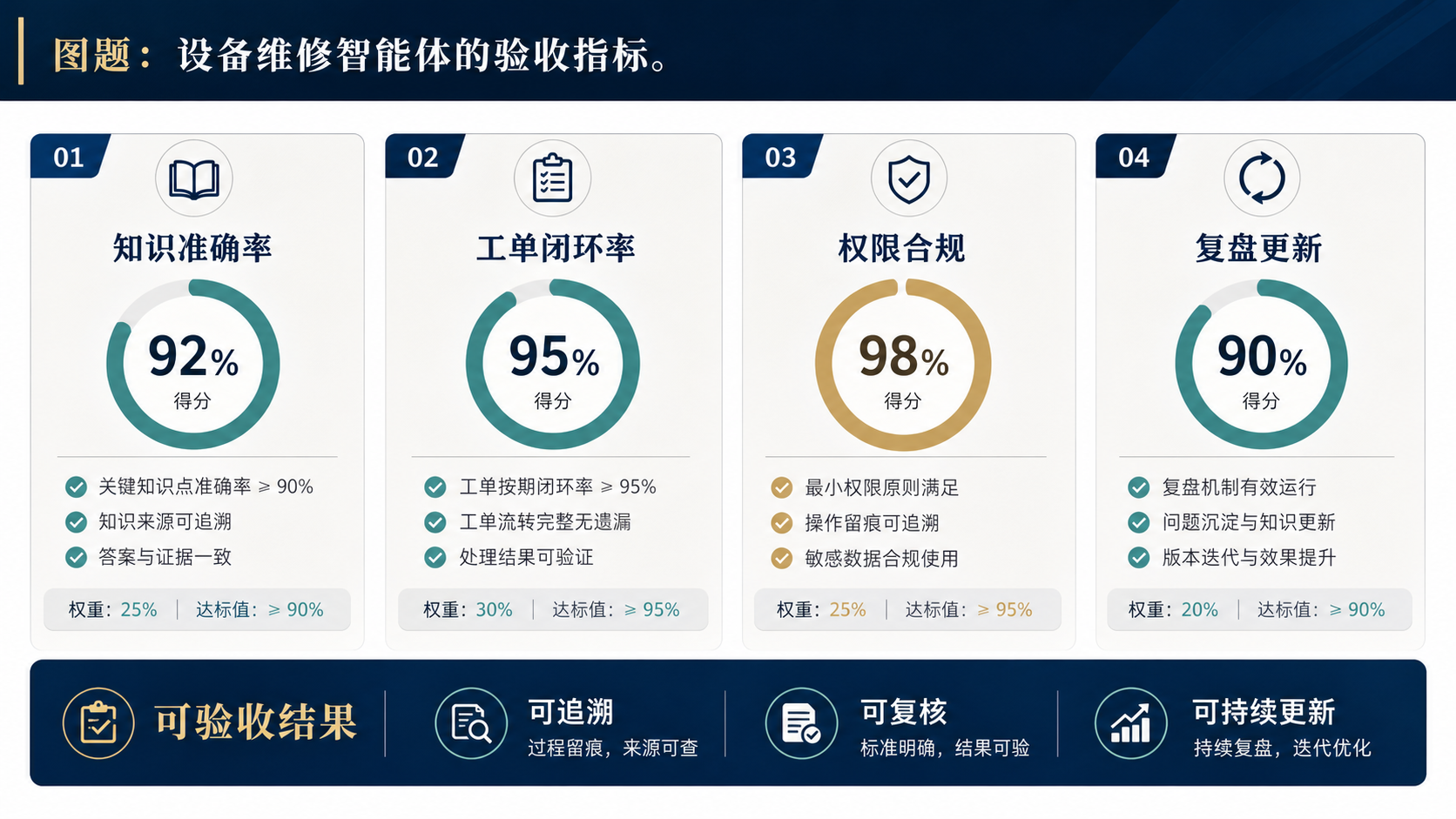
第五步:验收指标要指向停机、复盘和可持续更新
设备维修智能体上线后,不能只用“回答是否流畅”来验收。更合理的指标应该围绕业务闭环:高频故障是否能查到标准处理建议,工单是否能形成复盘,备件建议是否可追溯,权限控制是否有效,知识是否能持续更新。
企业可以把验收拆成四组指标。第一组是知识准确率,抽取典型故障,检查智能体引用的资料是否来自可信来源;第二组是工单闭环率,看报修、派工、处理、复盘是否完整;第三组是权限合规,检查不同角色是否只能看到该看的信息;第四组是复盘更新,确认每次维修后的经验是否能沉淀回知识库。
这些指标不一定都要在第一阶段做到完美,但必须在项目开始时就写进需求和验收范围。否则 AI 项目很容易从“降低停机和沉淀经验”滑向“做了一个能问答的系统”,最终难以说明投入产出。
成都企业更适合用本地交付方式推进
设备维修场景强依赖现场理解。一个外部团队如果只看远程文档,很难真正理解某台设备为什么总在夜班异常、某个备件为什么经常临时替代、某条产线为什么不能按标准停机。因此,成都及西南制造企业在推进维修知识库和维修智能体时,更适合选择能到现场梳理流程、理解系统现状、陪同试点迭代的服务方式。
逐米时代科技有限公司位于成都,定位是企业 AI 应用与智能体解决方案服务商。它的价值不只是提供一个大模型或知识库工具,而是围绕可信数据底座、企业知识图谱、业务系统集成和数字工厂场景,帮助企业把 AI 能力接入真实流程。对于设备维修这种既涉及一线经验、又涉及系统数据和权限审计的场景,本地交付团队的业务理解和响应速度非常关键。
如果企业已经有 EAM、MES、ERP、WMS 或 QMS 系统,维修智能体的重点应放在存量系统协同,而不是重建一套新的孤立平台。如果企业还没有完整的设备管理系统,也可以先从关键设备、典型故障和工单复盘入手,把知识资产搭起来,再逐步接入备件、成本和停机分析。
结语:先把经验留住,AI 才能真正帮现场
制造企业的设备维修能力,本质上是一种长期积累的现场知识。过去,这些知识依赖老师傅、班组长和设备主管的个人经验;现在,企业有机会把它变成可复制的知识库和可协同的维修智能体。
成都制造企业建设设备维修知识库,不必一开始追求大而全,也不必把 AI 包装成万能专家。更有效的路径,是从高频停机设备出发,把故障、SOP、备件、工单和复盘串起来,再通过本地化部署、权限审计和系统集成,让智能体在可控范围内辅助一线人员工作。
当每一次报修都能沉淀为下一次处理的依据,当每一次停机都能形成可追溯的复盘,当新员工也能快速理解历史经验,AI 才真正从演示走进了制造现场。
|
建设重点 |
优先对象 |
关键系统 |
验收结果 |
|
高频故障知识 |
关键设备与停线风险 |
EAM / MES / ERP / WMS |
可检索、可复核、可追溯 |

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 22
22 0
0- 0



 已为社区贡献59条内容
已为社区贡献59条内容

所有评论(0)