RAG 里最容易被忽视的一环:Perplexity 的 Snippet 压缩是怎么做的
Query-Aware Context Compression:让搜索片段更精准
原文链接:https://research.perplexity.ai/articles/query-aware-context-compression-for-better-snippets
每一个答案的背后,都有证据支撑。在搜索系统里,这些证据通常来自文档——标题、摘要、片段(snippet)——然后打包送给下游的答案模型或智能体去处理。
但问题是,这些原始上下文往往很"脏"。一个网页可能确实包含用户想要的信息,但同时也夹杂着大量干扰项:导航栏文字、无关广告、元数据,各种乱七八糟的东西。把这些噪声一股脑塞给下游模型,会带来三个麻烦。
第一,准确率下降。 再强的模型也有容量上限。一大堆无关信息白白占用了模型的处理能力,形成所谓的"上下文腐化"(context rot)——模型更容易漏掉关键事实、过度依赖低质信息,或者生成难以溯源的内容。
第二,延迟上升。 上下文越长,下游模型要处理的 token 就越多,推理阶段尤其明显。噪声越多,模型要花更多的推理 token 去应对。
第三,成本增加。 每一个多余的 token 都是在多花钱——不仅输入 token 变多,推理 token 也跟着涨。结果就是:花了更多钱,换来了更差的效果。
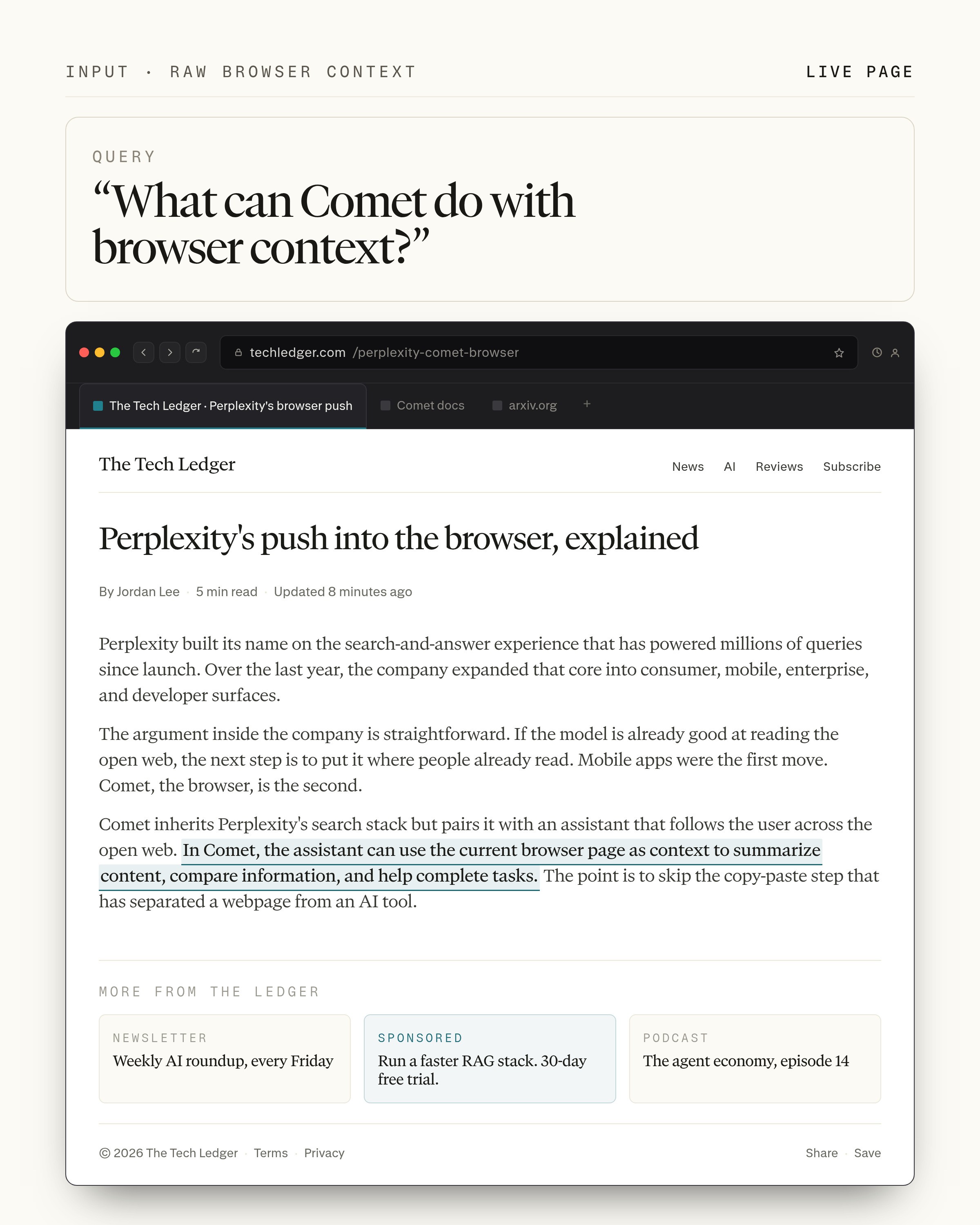
图1:原始检索上下文里,答案往往被一堆无关内容淹没。有用的证据确实在,但答案模型看到它之前,得先穿过一堆页眉页脚、样板文字、元数据和题外话。
为了同时提升准确率、降低延迟、控制成本,Perplexity 在提升上下文精度上下了不少功夫,其中一个方向就是改进 snippet 生成算法。他们把 snippet 生成当成一个上下文压缩问题来处理。模型在寻找特定信息时,并不需要泛化的摘要或者文档节选,它需要的是最小化的、最精准的来源信息片段。其他的东西,能删就删。
一个好的 snippet 应该做到三点:
- 提升准确率:提供精准的证据,让模型的回答有据可查。
- 降低延迟和成本:在 LLM 调用之前就把无关上下文剔除掉。
- 保证可溯源性:保留原文措辞,确保引用的可信度。
这个月,Perplexity 在应用和 API 平台上部署了一套全新的、达到业界顶尖水平的 snippet 生成器。其核心是一个查询感知的上下文压缩模型,能针对每个查询和每个候选结果,判断哪些文本片段需要保留。这篇文章就来讲讲他们是怎么构建和训练这个模型的。
Snippet 即查询感知的压缩
首先得把任务定义清楚:模型要做什么,输入输出的格式是什么。
Snippet 方法大致分两类:一类是选取式,找到相关的段落或句子直接传下去;另一类是生成式,让模型基于页面内容写一个聚焦查询的摘要。
考虑到准确率、延迟和成本这三个核心目标,生成式方案基本可以排除——为每个页面生成摘要,这三项指标全都会变差。摘要可能改写原文,让引用对齐变得更难,还可能引入原文中不存在的措辞,而 snippet 是作为证据使用的,这种风险不可接受。加上生成本身的延迟和成本,更是雪上加霜。
所以他们把任务定义为查询感知的抽取式压缩:把检索上下文里有用的部分和干扰部分分开。具体来说,模型接收一个查询和一个候选结果,决定哪些文本片段要保留(能支持查询的),哪些要丢弃(其余的)。输出保留原文,不做改写,这样既方便引用和核验,传给下游模型的 token 数也更少。
举个例子,对于下面这个查询和检索结果——
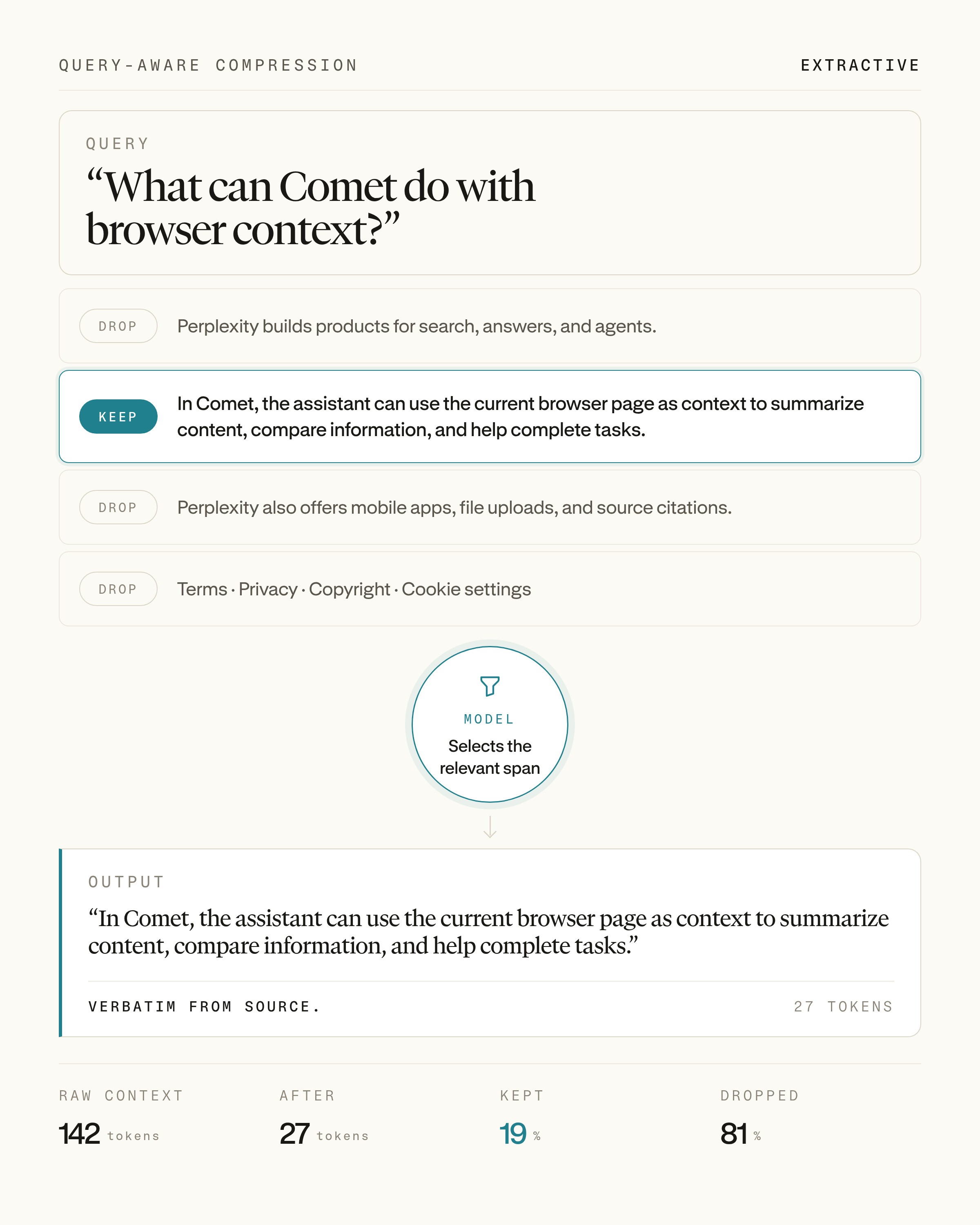
模型应该选出加粗的那句话:“In Comet, the assistant can …”。
这套思路和 FliCo、Provence、LooComp 等上下文压缩工作的大方向一致,但针对生产级搜索系统的 snippet 生成做了专门的适配。Perplexity 的检索系统本来就在子文档(即 snippet)层面运作,已经能很好地平衡精度和召回率。引入查询感知压缩模型,是在此基础上进一步拓展精度-召回率的帕累托边界。
如何构建和训练压缩模型
在开发模型时,他们重点考虑了三件事:对查询和上下文的联合理解、细粒度的句子级选择,以及满足极苛刻延迟要求的效率。
模型架构
他们用 pplx-diffusion 模型作为骨干网络,这和 pplx-embed-v1 是同一个模型家族。无论是之前的学术研究还是生产环境的 benchmark,都证明它是一个强大的双向编码器,擅长处理查询-上下文对。这类模型的关键特性在于双向上下文:每个 token 的表征在决定去留之前,都能同时关注到完整的查询和完整的候选上下文。
在骨干网络之上,他们训练了一个轻量级的压缩头,用来预测上下文的哪些部分应该保留。由于不涉及生成,这些预测可以在整个上下文上并行完成。在推理时,snippet 引擎在句子层面聚合这些预测,应用阈值,并裁剪到请求的 token 预算范围内。
监督数据流水线
训练这个压缩器需要足够细粒度的监督信号,文档级的相关性标签完全不够用。为此,他们构建了一条片段标注流水线,用来标记与查询相关的证据片段,以及应该被删除的干扰片段。
流水线采用 LLM-as-a-judge 的方式:给定用户查询和候选网页,judge 模型首先进行查询理解,分析查询并列出可能的用户意图;然后锚定这些意图,处理候选上下文,返回从原文逐字复制的片段,并给每个片段打上类别标签,方便后续检查。
接下来,把返回的片段匹配回源文本。结果显示,大多数 judge 输出本来就是精确复制:朴素字符串匹配就能恢复 98% 的片段,加一个简单的正则匹配,能把片段恢复率拉到 100%。这样就得到了可靠的、细粒度的片段标注,可以转换成 token 级别的保留/丢弃监督信号。
在评估监督流水线时,他们用了一个小规模的人工标注数据集,对比了不同的 judge 模型、不同的 prompt 以及不同的步骤配置。表现最好的是两阶段流水线:先做查询理解,再做分类片段标注。此外,他们还通过 BrowseComp 和 SimpleQA 这两个下游可验证评测来验证提取的片段质量——仅使用保留的证据片段,得分依然很高,同时大幅减少了输入 token 数。
最终,他们用这条流水线标注了 75 万个查询-文档对,并用得到的片段以二元交叉熵损失训练压缩头。整个过程让查询感知压缩模型在保持原文完整的同时,精准剔除那些对下游模型没有帮助的上下文。
保证实时延迟
上下文压缩在下游模型之前执行,是一个阻塞操作,而且每次压缩都依赖当前查询。因此,线上路径需要在极其苛刻的延迟预算内,对每个候选文档完成查询-上下文对的打分。压缩模型太慢就得不偿失——高精度带来的延迟收益会被压缩本身的延迟抵消掉。但模型太弱,压缩决策的质量又会下降。
实际问题是:在压缩质量不明显下降的前提下,能砍掉多少模型容量?他们对比了完整的 28 层 pplx-diffusion 骨干网络,以及通过层剪枝得到的 11 层和 17 层变体。对每个变体,扫描压缩阈值,衡量两个指标:每次查询传给下游模型的平均上下文 token 数,以及压缩后有用证据的保留率。
图2展示了质量-效率边界。越靠近左上角越好:更少的下游 token,同时保留更多有用证据。28 层模型提供质量基准,11 层模型展示了压缩过激的风险。17 层剪枝模型居中:在饱和区间紧跟 28 层模型,但在大多数生产流量所在的陡峭区间有小幅差距。
为了弥合这个差距,他们用了 token 级知识蒸馏:在标准损失基础上加上一个软交叉熵项,使用教师模型的预测,并乘以蒸馏系数。这足以让学生模型追上教师,最终完全切换到蒸馏后的 17 层模型。
新的生产模型相比 28 层教师模型,推理延迟降低了 35-40%,整体 GPU 算力消耗降低了 40-45%,质量没有任何损失。线上延迟(p99)低于 20ms——小到完全可以加入服务路径,同时大幅减少传给答案模型的 token 总量。
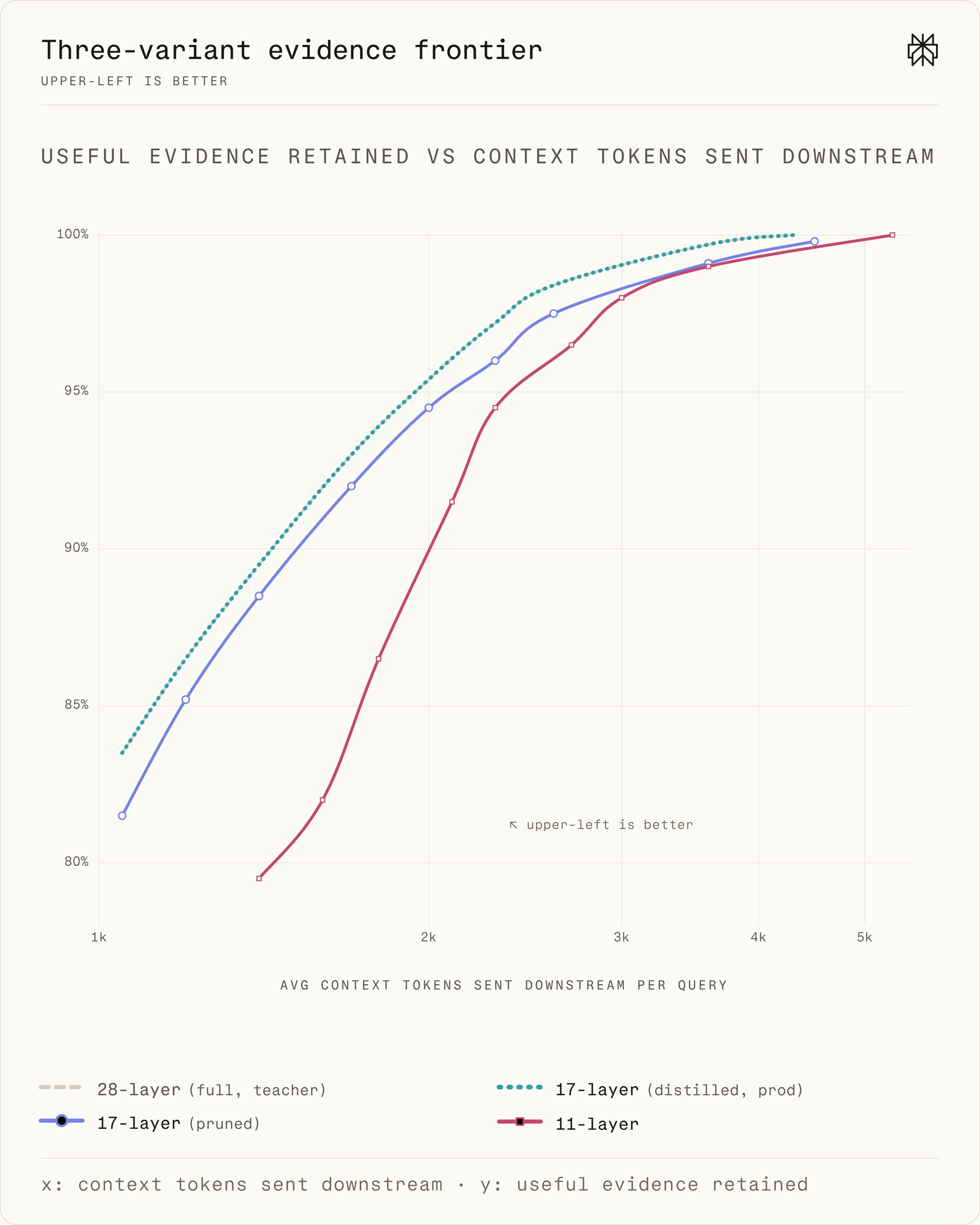
图2:不同模型深度的压缩性能。蒸馏后的 17 层学生模型(即生产模型)在所有阈值下都能追平 28 层教师模型,同时在线计算成本更低。
质量与 Token 效率
他们用 Perplexity 的 Agent API 作为测试平台,分析上下文压缩的实际效果。测试了三个上下文预设:
- "低"预设:每个结果集的 token 预算限制为 1000 tokens
- "中"预设:限制为 4000 tokens
- "高"预设:限制为 10000 tokens
有压缩和无压缩两种配置都遵守这些 token 预算。
多步骤 Agentic 搜索(BrowseComp)
首先测试压缩在 BrowseComp 上的效果,这个 benchmark 考察多步骤搜索工作流。他们用的是开源的 search_evals 框架,评分方式采用 OpenAI 的标准 BrowseComp LLM judge prompt,所有 run 保持一致。
关注两个维度:benchmark 准确率和 token 用量。Token 用量在查询级别衡量,而非单步级别,以反映整个请求生命周期的实际 token 消耗。
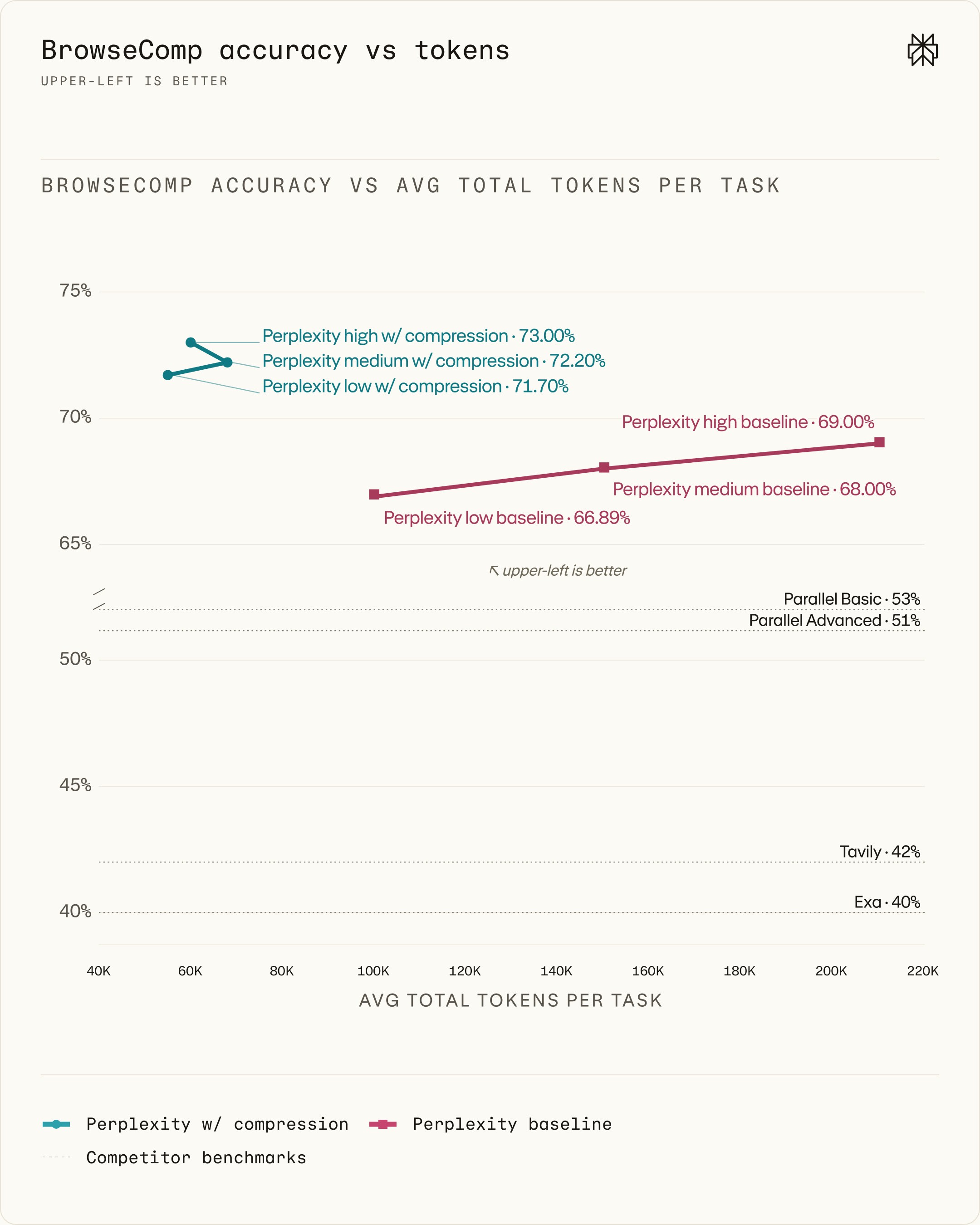
图3:BrowseComp 上的得分-Token 边界。越靠上准确率越高,越靠左效率越高。所有预设下,压缩都改进了帕累托边界。虚线表示非 Perplexity 搜索系统的水平(包括 Parallel benchmarks)。智能体循环由 GPT-5.5 驱动。
压缩在各个设置下都带来了新的帕累托边界:对于每个设置,引入压缩后查询级 token 用量降低 10%-70%,准确率提升 4 到 4.81 个百分点。引入压缩后,即使是"低"预设也能超过无压缩的"高"预设,而且 token 用量还少了三倍多。
有个有意思的现象:启用压缩后,"高"预设比"中"预设准确率更高,这符合预期;但奇怪的是,"高"预设的 token 用量反而更少。这揭示了一个微妙但重要的效应——压缩之后,即使增加单步的上下文量,也可能让模型用更少的步骤得出正确结果。这种非单调性值得进一步探索。
SimpleQA:单步事实性问答
BrowseComp 压的是多步推理,但很多生产场景其实只需要单步事实查询。为了验证压缩在单步场景下同样有效,他们还在 SimpleQA 上做了测试——这个 benchmark 包含 4326 个问题,每个问题只需一步搜索作答。
同样画出得分对平均 token 用量的边界(图4)。虽然单步场景下效果量级更小,但压缩依然在所有预设下同时提升了准确率和效率。启用压缩后,中等预设以平均每文档仅 200 tokens 的代价达到了 95% 的准确率。考虑到平均文档长度超过 10000 tokens,这意味着压缩比超过了 50 倍,属于业界领先水平。
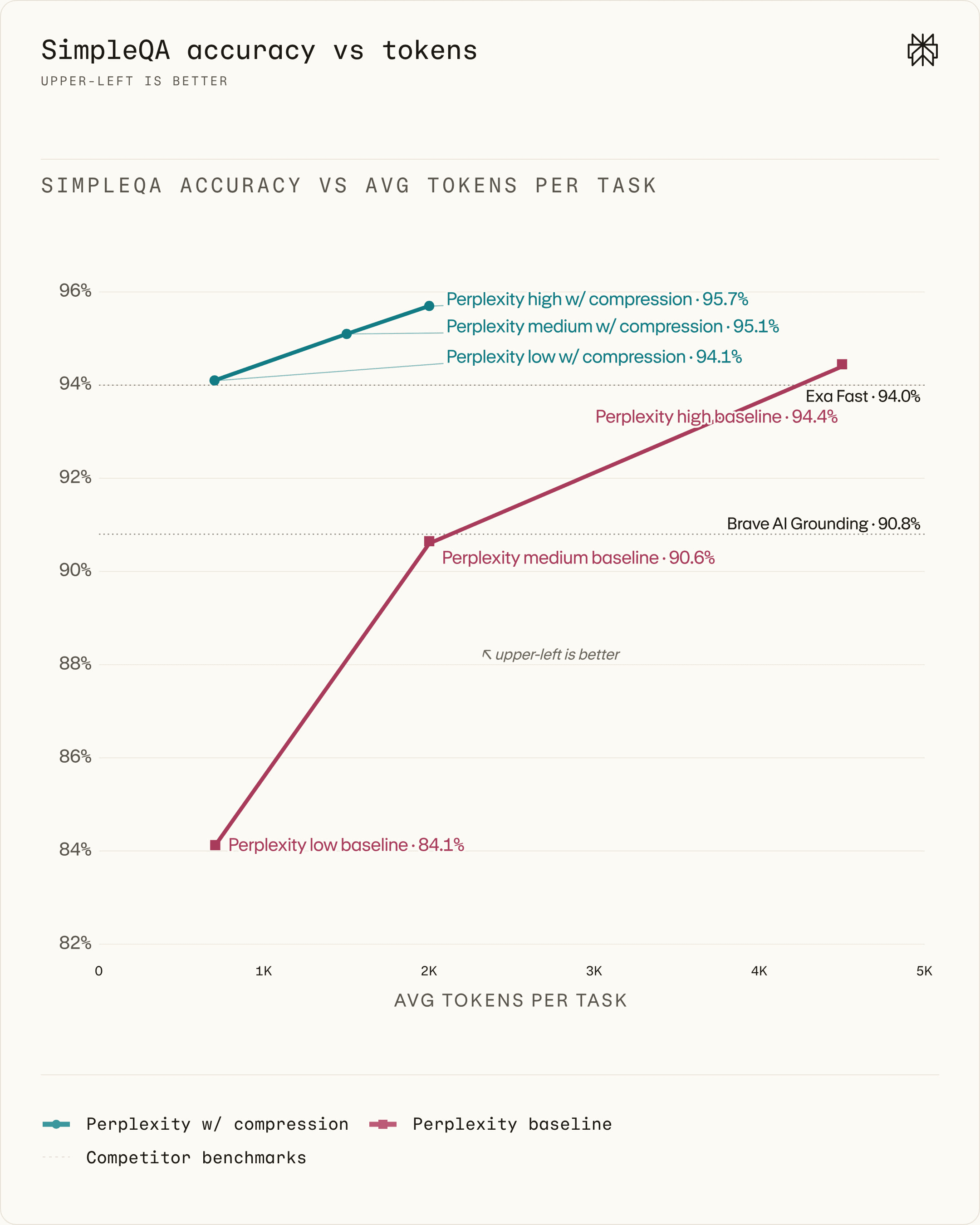
图4:SimpleQA 上的得分-Token 边界。压缩在所有预设下都改进了帕累托边界。虚线表示非 Perplexity 搜索系统的水平(包括 Exa API evals)。
Snippet 里到底留了什么?
上面的结果是端到端的,但压缩究竟改变了单个 snippet 的内容构成?他们又做了一个专项评估,用 LLM judge 把每个检索 snippet 中的每个 token 分成六类:
- 核心内容:回答查询必不可少的证据
- 离题内容:对其他目的有用但与当前查询无关的信息
- 广告:分散注意力的无关广告
- 元数据:关于文档内容的元数据
- UI 与导航:前端展示和导航元素
- 重复内容:已出现过的重复信息
评估在验证集的 1000 条混合领域查询上运行,对比启用压缩和未启用压缩的生产栈。
结果如图5所示:压缩让每个 snippet 中核心内容的占比平均提升了 63%,同时无关 token 减少了 29%,其中 UI/导航减少 58%、元数据减少 46%、广告减少 43%。这直接揭示了质量-效率双重提升背后的机制:压缩大幅提高了每个 snippet 的信噪比。
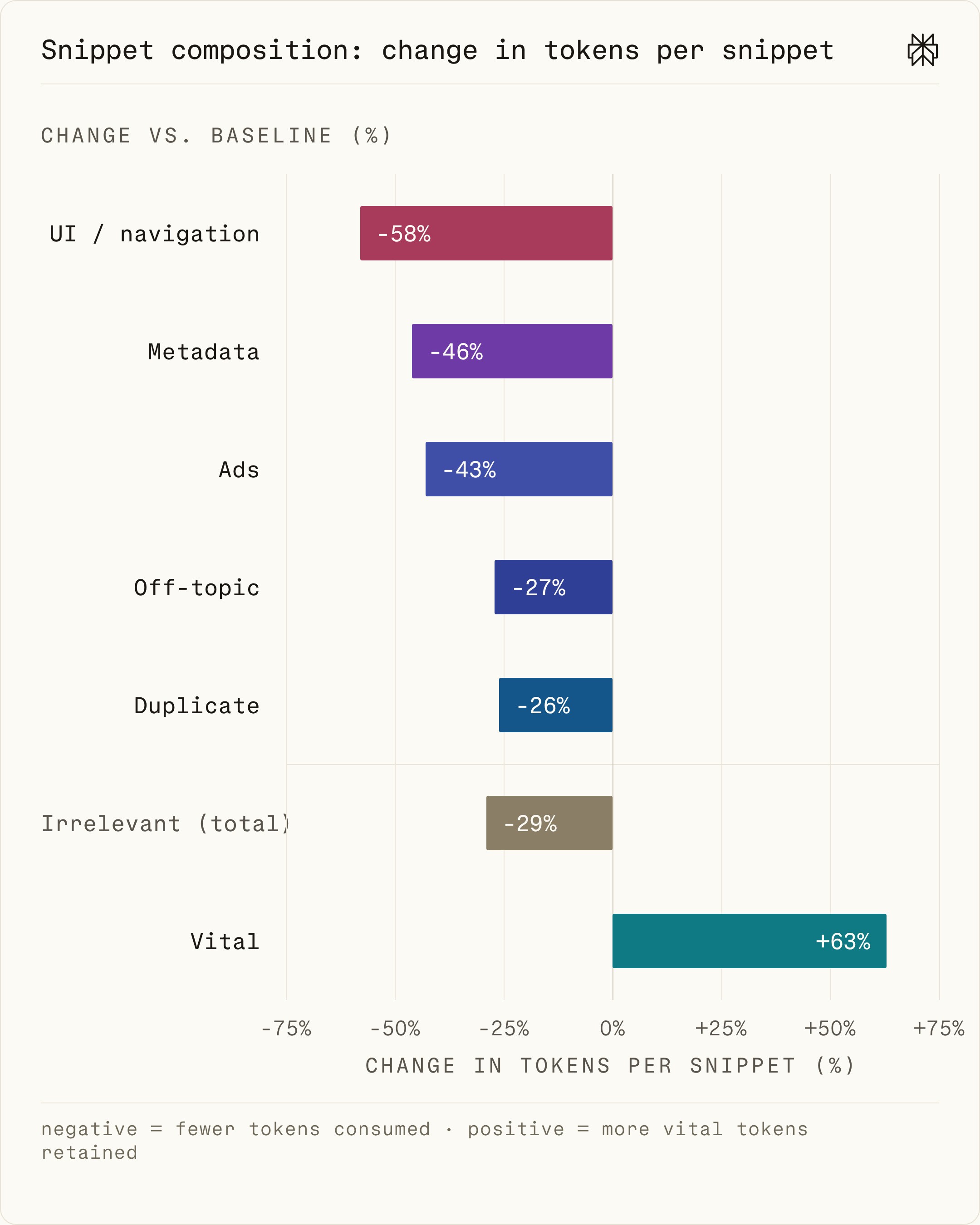
图5:压缩后每个 snippet 的 token 构成变化(1000 条查询的平均值)。核心内容占比上升,各类非核心内容相应减少。
图6用一个具体案例来说明这种变化。对于查询"6天大新生儿每次喂奶量",分别展示未压缩(基线)和压缩后的 snippet。压缩剔除了所有非核心内容,只保留了与新生儿喂养相关的信息。值得注意的是,压缩成功去掉了那些对页面而言整体相关但对这个具体查询(聚焦新生儿)并不相关的内容。
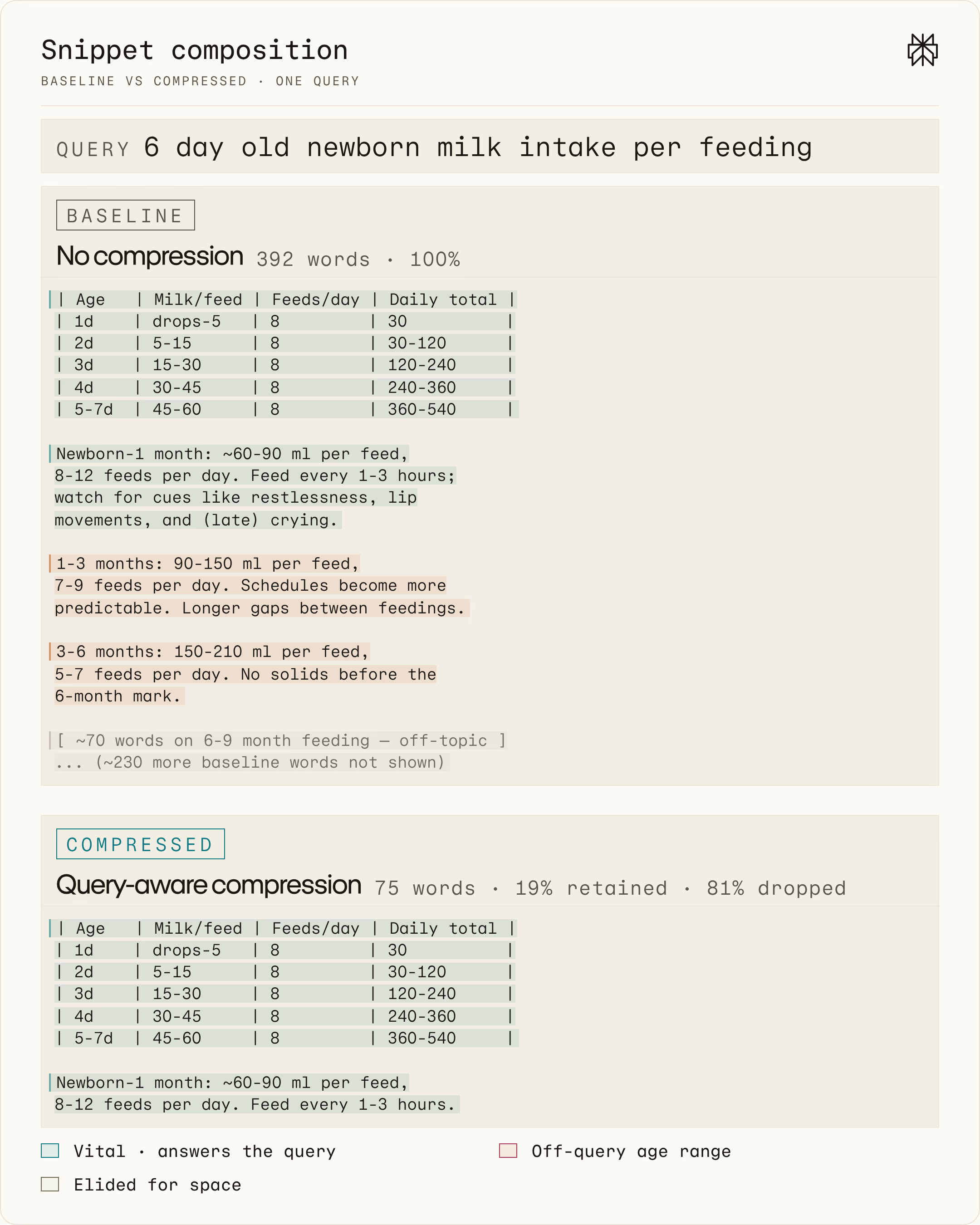
图6:同一查询-文档对,基线(未压缩,上)和压缩后(下)的 snippet 对比。压缩只保留了基线 snippet 的前 19%,丢弃了剩余 81% 的无关内容。
总结
AI 系统要聪明高效地服务用户,依赖的是高信噪比的信息。这些信息必须尽可能精准,才能最大化对每个请求的相关性。Perplexity 新的查询感知压缩模型做的正是这件事——最大化每个 snippet 中的有效证据,同时大力删减无关干扰项。
把这些新模型部署进搜索栈之后,无论是产品用户还是 API 客户,都能获得更快、更好的回答。而且这套方案还提供了一个简单的调节旋钮,可以根据需求在召回率、延迟和成本之间灵活权衡。
上下文精选(context curation)还是一个快速发展的领域,要优化当今前沿智能系统中每个 token 的价值,还有很多事情可以做。模型改进和系统架构两条路都在持续推进,让这套技术发挥更大的作用。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 5
5 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)