基于高通跃龙IQ-9100端侧多模态大模型赋能具身智能交互系统(2): LLM任务规划、语音交互与系统集成
👉 第一篇我们完成了端侧大模型的背景介绍和VLM场景理解节点的部署。接下来请继续阅读第二篇,我们将深入讲解:
- 基于Llama 2 7B的LLM任务链规划引擎(含完整代码)
- 语音交互集成(Whisper ASR + TTS)
- 系统完整演示(从“去厨房拿水”到45秒闭环)
- NPU资源动态调度策略
下方继续👇
摘要
接上一篇,本文继续在IQ-9100平台上实战:使用Llama 2 7B进行自然语言指令的任务分解与规划,集成Whisper语音识别和TTS语音合成,最终串联VLM、导航、抓取等技能,构建一个完整的端侧具身智能体。通过一个“去厨房拿水”的完整示例,展示从语音到执行的45秒闭环。
1. LLM任务链规划
1.1 任务规划引擎
任务规划节点负责:
- 接收自然语言指令
- 使用LLM生成结构化任务计划(JSON格式)
- 逐步执行并监控每个原子技能
- 异常时支持重试(最多3次)
可用技能定义
class SkillType(Enum):
NAVIGATE = "navigate" # 导航到指定位置
SEARCH = "search" # 视觉搜索物体
PICK = "pick" # 抓取物体
PLACE = "place" # 放置物体
SPEAK = "speak" # 语音播报
WAIT = "wait" # 等待
LOOK_AT = "look_at" # 转向观察
FOLLOW = "follow" # 跟随
PATROL = "patrol" # 巡逻
ASK_VLM = "ask_vlm" # 询问视觉模型
核心规划器代码(节选)
class TaskPlannerNode(Node):
SYSTEM_PROMPT = """
你是一个服务机器人的任务规划器。你需要将用户的自然语言指令分解为机器人可以执行的原子动作序列。
可用技能:
- navigate: 导航到指定位置 {"target": "位置名"}
- search: 视觉搜索物体 {"object": "物体描述"}
- pick: 抓取物体 {"object": "物体描述"}
- place: 放置物体 {"location": "放置位置"}
- speak: 语音播报 {"text": "播报内容"}
- wait: 等待 {"seconds": 数字}
- look_at: 转向观察 {"direction": "left/right/around"}
- ask_vlm: 询问视觉模型 {"question": "问题"}
已知位置: 大厅, 会议室, 厨房, 办公室, 充电桩, 前台, 仓库
输出JSON格式:
{"steps": [{"skill": "技能名", "params": {参数}}]}
示例:
用户:"去厨房拿一瓶水给我"
输出:
{"steps": [
{"skill": "speak", "params": {"text": "好的,我去厨房帮你拿水"}},
{"skill": "navigate", "params": {"target": "厨房"}},
{"skill": "search", "params": {"object": "水瓶"}},
{"skill": "pick", "params": {"object": "水瓶"}},
{"skill": "navigate", "params": {"target": "用户位置"}},
{"skill": "speak", "params": {"text": "水拿到了,给你"}},
{"skill": "place", "params": {"location": "用户面前"}}
]}
"""
def __init__(self):
super().__init__('task_planner')
self.declare_parameter('llm_model_dir', '/opt/models/llama2_7b')
self._current_plan = None
self._task_counter = 0
self._load_llm()
# 订阅语音/文本指令、技能执行结果、VLM响应
self.create_subscription(String, '/voice_command', self._command_callback, 10)
self.create_subscription(String, '/text_command', self._command_callback, 10)
self.create_subscription(String, '/skill_result', self._skill_result_callback, 10)
self.create_subscription(String, '/vlm/response', self._vlm_response_callback, 10)
# 发布技能执行、导航目标、TTS、VLM查询、状态
self.skill_pub = self.create_publisher(String, '/skill_execute', 10)
self.nav_goal_pub = self.create_publisher(PoseStamped, '/goal_pose', 10)
self.speak_pub = self.create_publisher(String, '/tts/text', 10)
self.vlm_query_pub = self.create_publisher(String, '/vlm/query', 10)
self.status_pub = self.create_publisher(String, '/task_status', 10)
self.create_timer(0.5, self._execution_loop)
self.get_logger().info('Task planner ready (LLM-powered)')
def _generate_plan(self, command: str) -> Optional[TaskPlan]:
"""使用LLM生成任务计划(支持NPU推理和规则回退)"""
# ... 详细实现见原文档,包含_llm_plan() 和 _rule_based_plan()
def _llm_plan(self, command: str) -> str:
"""LLM推理生成计划(NPU加速)"""
prompt = f"[INST] <<SYS>>\n{self.SYSTEM_PROMPT}\n<</SYS>>\n\n{command} [/INST]"
input_ids = self.tokenizer.encode(prompt, return_tensors="np")
generated = []
for _ in range(512): # 最多生成512个token
logits = self.llm.execute({"input_ids": input_ids})
next_token = int(np.argmax(logits[0, -1, :]))
if next_token == self.tokenizer.eos_token_id:
break
generated.append(next_token)
input_ids = np.concatenate([input_ids, np.array([[next_token]])], axis=1)
response = self.tokenizer.decode(generated)
# 提取JSON部分
json_start = response.find('{')
json_end = response.rfind('}') + 1
if json_start >= 0 and json_end > json_start:
return response[json_start:json_end]
return '{"steps": []}'
def _rule_based_plan(self, command: str) -> str:
"""基于规则的计划生成(回退方案)—— 支持导航、拿取、搜索等常见指令"""
# 详细实现见原文档,包含关键词匹配、位置/物体词典等逻辑
def _execution_loop(self):
"""任务执行主循环:依次执行计划中的每个步骤,支持重试"""
# ...
def _execute_step(self, step: TaskStep):
"""根据技能类型调用对应的底层接口"""
if step.skill == SkillType.NAVIGATE:
self._navigate_to(step.params.get("target", ""))
elif step.skill == SkillType.SPEAK:
self.speak_pub.publish(String(data=step.params.get("text", "")))
self._step_complete(True)
elif step.skill == SkillType.SEARCH:
query = String(data=f"请找到画面中的{step.params.get('object','')}并描述它的位置")
self.vlm_query_pub.publish(query)
elif step.skill == SkillType.PICK:
self.skill_pub.publish(String(data=json.dumps({"skill":"pick","params":step.params})))
# ... 其他技能类似
def _navigate_to(self, target: str):
"""导航到预定义位置坐标"""
location_map = {
"大厅": (0.0, 0.0, 0.0), "会议室": (5.0, 3.0, 1.57),
"厨房": (-3.0, 2.0, 0.0), "办公室": (8.0, -2.0, 0.0),
"前台": (2.0, -1.0, 0.0), "仓库": (-5.0, -3.0, 3.14),
"充电桩": (-1.0, -1.0, 3.14), "用户位置": (0.0, 0.0, 0.0),
}
if target in location_map:
x, y, yaw = location_map[target]
goal = PoseStamped()
goal.header.stamp = self.get_clock().now().to_msg()
goal.header.frame_id = "map"
goal.pose.position.x = x
goal.pose.position.y = y
goal.pose.orientation.z = np.sin(yaw/2)
goal.pose.orientation.w = np.cos(yaw/2)
self.nav_goal_pub.publish(goal)
else:
self._step_complete(False, f'未知位置: {target}')
def _step_complete(self, success: bool, message: str = ""):
"""标记步骤完成,支持重试(最多3次)"""
# ...
完整代码包含步骤状态管理、重试逻辑、VLM响应回调等。
2. 语音交互集成
2.1 语音交互管线
实现唤醒词检测 → ASR语音识别 → 发布文本指令以及接收文本 → TTS语音合成 → 音频播放的双向闭环。
class VoiceInteractionNode(Node):
def __init__(self):
super().__init__('voice_interaction')
self.declare_parameter('asr_model', '/opt/models/whisper_tiny')
self.declare_parameter('language', 'zh')
self._load_asr()
self._load_tts()
self.command_pub = self.create_publisher(String, '/voice_command', 10)
self.listening_pub = self.create_publisher(Bool, '/voice/listening', 10)
self.create_subscription(String, '/tts/text', self._tts_callback, 10)
self._audio_thread = threading.Thread(target=self._audio_capture_loop, daemon=True)
self._audio_thread.start()
self.get_logger().info('Voice interaction ready')
def _load_asr(self):
try:
import whisper
self.asr_model = whisper.load_model("tiny", download_root=self.get_parameter('asr_model').value)
except ImportError:
self.asr_model = None
self.get_logger().warning('whisper not available')
def _load_tts(self):
try:
import pyttsx3
self.tts_engine = pyttsx3.init()
self.tts_engine.setProperty('rate', 180)
self.tts_engine.setProperty('volume', 0.9)
except ImportError:
self.tts_engine = None
def _tts_callback(self, msg):
text = msg.data
self.get_logger().info(f'TTS: "{text}"')
if self.tts_engine:
self.tts_engine.say(text)
self.tts_engine.runAndWait()
# 音频采集和识别循环(略)
3. 系统集成与演示场景
3.1 完整交互流程示例
用户语音指令:“小高,去厨房帮我拿一瓶水”
系统处理全流程:
| 步骤 | 模块 | 动作 | 耗时 |
|---|---|---|---|
| 1 | ASR | 语音识别 → “去厨房帮我拿一瓶水” | ~200ms |
| 2 | LLM | 任务分解 → 生成JSON计划(见下方) | ~1.5s |
| 3 | TTS | 播报“好的,我去厨房帮你拿水” | 实时 |
| 4 | Nav2 | 导航到厨房(自动避障) | ~15s |
| 5 | VLM | 观察场景:“桌面左侧有一个蓝色水瓶” | ~2s |
| 6 | 抓取 | 视觉搜索→定位→抓取 | ~8s |
| 7 | Nav2 | 导航回用户位置 | ~15s |
| 8 | TTS | 播报“水拿到了,给你” | 实时 |
| 9 | 放置 | 将水瓶放在用户面前 | 包含在上步 |
总耗时:约45秒(导航占主要部分)
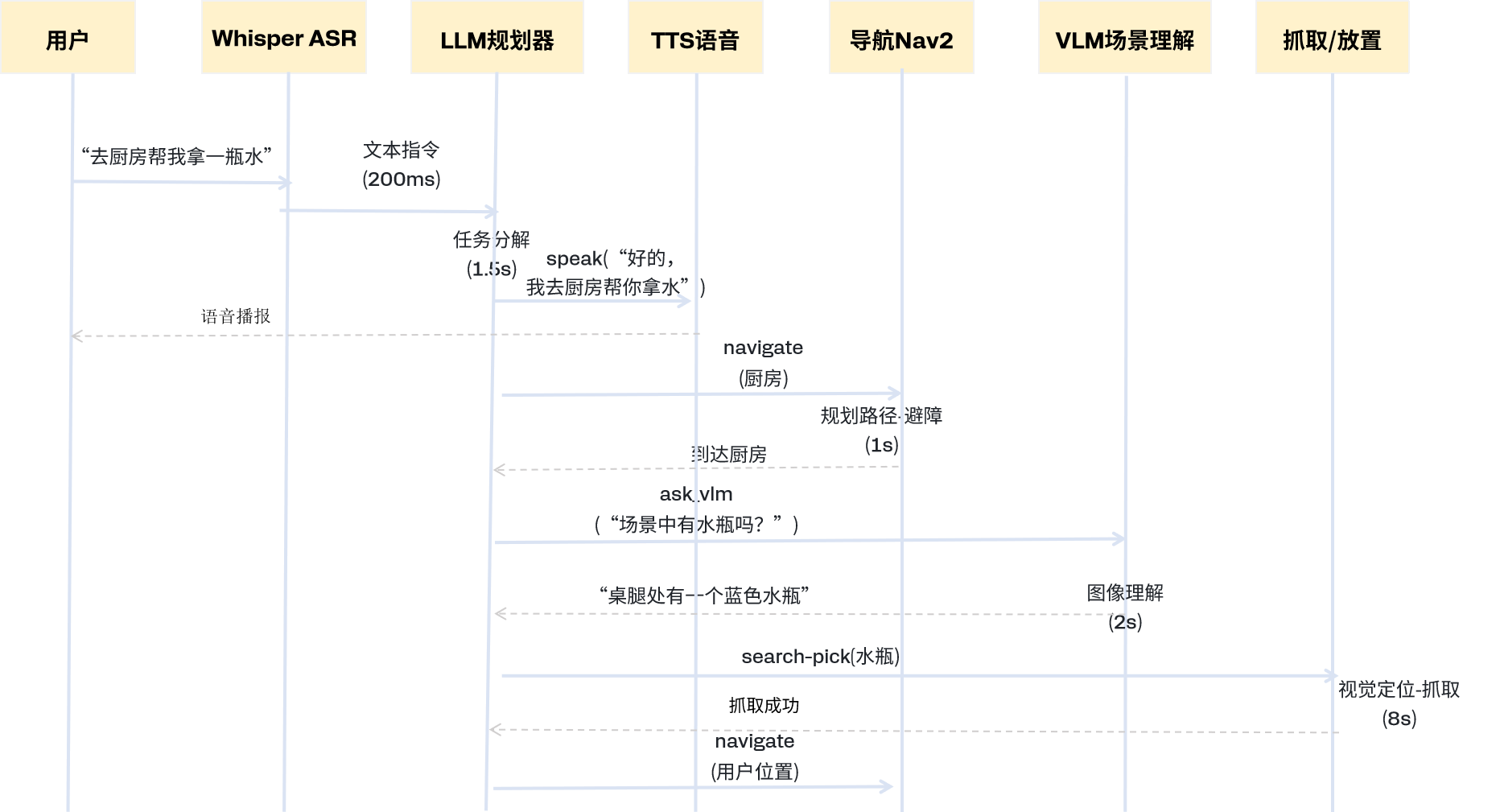
LLM生成的JSON计划:
{
"steps": [
{"skill": "speak", "params": {"text": "好的,我去厨房帮你拿水"}},
{"skill": "navigate", "params": {"target": "厨房"}},
{"skill": "ask_vlm", "params": {"question": "场景中有水瓶吗?在什么位置?"}},
{"skill": "search", "params": {"object": "水瓶"}},
{"skill": "pick", "params": {"object": "水瓶"}},
{"skill": "navigate", "params": {"target": "用户位置"}},
{"skill": "speak", "params": {"text": "水拿到了,给你"}},
{"skill": "place", "params": {"location": "用户面前"}}
]
}
3.2 NPU资源动态调度
以下是NPU资源调度示例图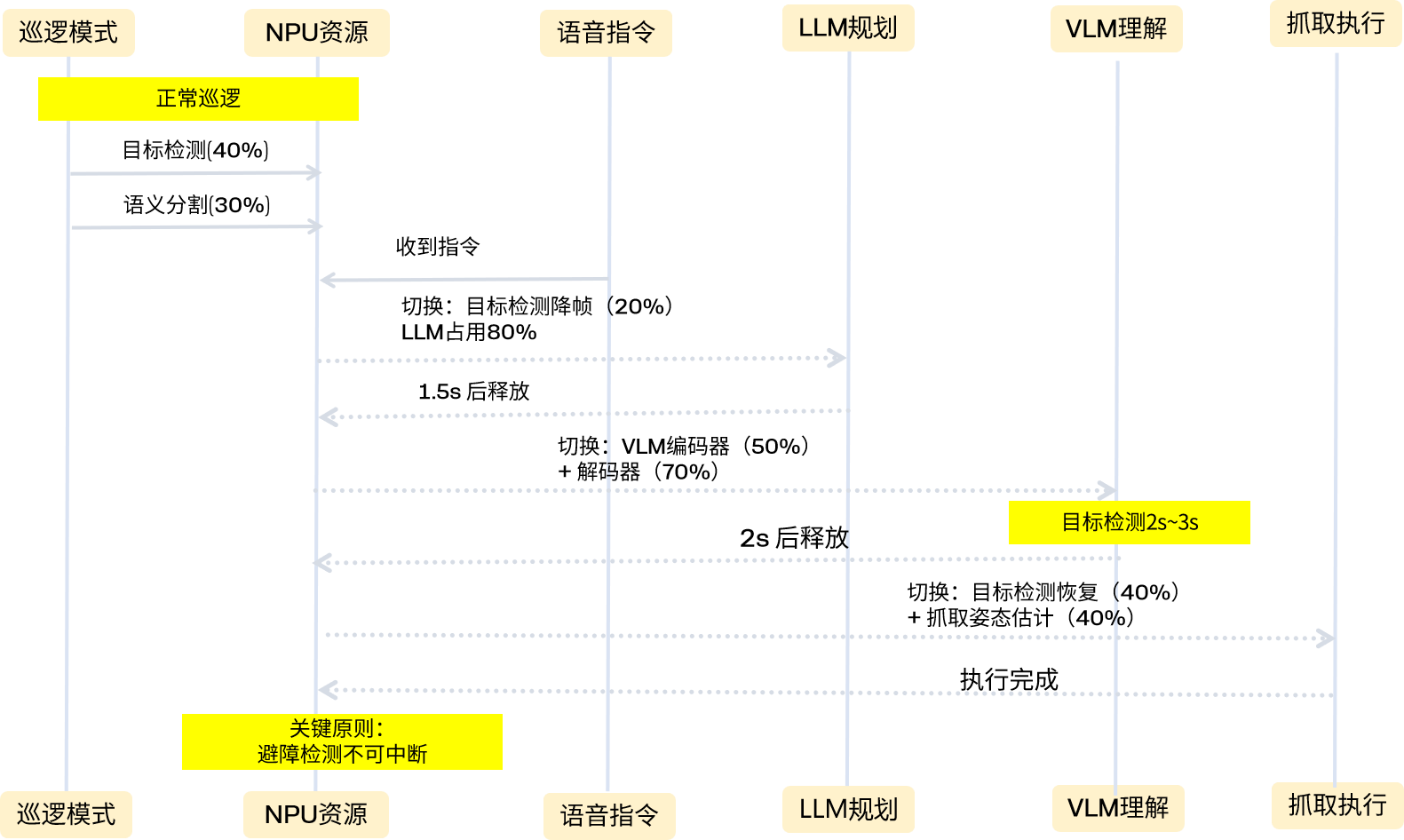
在大模型任务期间,NPU资源按优先级切换:
- 正常巡逻模式:目标检测( ~ 40% NPU)+ 语义分割(~30% NPU)
- 收到语音指令:目标检测降帧(~ 20%),LLM任务规划占用(~80%),耗时约1.5s
- VLM场景理解:VLM视觉编码器(~ 50%)+ 文本解码器(~70%),目标检测暂停2-3秒
- 抓取执行时:目标检测恢复(~ 40%),抓取姿态估计(~40%),剩余给MoveIt碰撞检查
关键原则:
- 安全相关(避障检测)优先级最高,不可中断
- 大模型推理是短暂突发,用完立即释放
- 通过任务队列管理NPU切换,避免冲突
大模型任务期间的 NPU 资源切换:
正常巡逻模式:
├── TP0: 目标检测 (持续运行, ~40%)
├── TP1: 语义分割 (持续运行, ~30%)
└── 剩余: 空闲
收到语音指令时:
├── TP0: 目标检测 (降帧率, ~20%)
├── TP1: LLM任务规划 (临时占用, ~80%) ← 切换
└── 耗时: ~1.5s
VLM场景理解时:
├── TP0: VLM视觉编码器 (临时, ~50%) ← 切换
├── TP1: VLM文本解码器 (临时, ~70%) ← 切换
├── 目标检测暂停 2-3 秒
└── 耗时: ~2s
抓取执行时:
├── TP0: 目标检测 (恢复, ~40%)
├── TP1: 抓取姿态估计 (临时, ~40%) ← 切换
└── 剩余: MoveIt 2 碰撞检查
关键原则:
1. 安全相关(避障检测)优先级最高, 不可中断
2. 大模型推理是短暂突发, 用完立即释放
3. 通过任务队列管理 NPU 切换, 避免冲突
4. 总结与展望
4.1 系列回顾
本系列两篇文章完整构建了一个基于IQ-9100的具身智能机器人技术栈:从VLM场景理解、LLM任务规划、语音交互到最终的系统集成。当感知、导航、操作、交互四大能力在IQ-9100上完整闭环,我们就得到了一个真正的具身智能体——它能看懂环境、听懂指令、自主规划、安全执行。
4.2 IQ-9100具身智能方案核心优势
| 能力维度 | IQ-9100方案 | 传统多板方案 |
|---|---|---|
| 感知 | 16路摄像头 + 100T NPU | 感知板 + 加速卡 |
| 导航 | 8核CPU运行SLAM+Nav2 | 规划板 |
| 操作 | NPU抓取估计 + MoveIt 2 | 独立计算板 |
| 交互 | 端侧7B/13B大模型 | 云端API |
| 安全 | SIL3安全岛 + CAN-FD | 独立安全MCU |
| 集成度 | 一颗芯片 | 3-5块板卡 |
| 功耗 | ~35W | ~80-120W |
| 成本 | 中 | 高 |
4.3 未来方向
- 更大模型:随着高通下一代工业机器人芯片(IQ10系列)问世,端侧可运行更大参数的多模态模型
- 世界模型:机器人通过VLM+LLM构建内部世界模型,实现更复杂的推理和规划
- 持续学习:在设备端进行微调和适配,让机器人在新环境中快速学习
- 多机协作:多台IQ-9100机器人通过TSN以太网实时协同
参考资料
- Qualcomm Dragonwing IQ9 Series
- QIR SDK (GitHub)
- LLaVA: Visual Instruction Tuning
- HuggingFace 高通模型
- OpenAI Whisper
- MoveIt 2
作者结语:当感知、导航、操作、交互四大能力在IQ-9100上完整闭环,我们就得到了一个真正的具身智能体——它能看懂环境、听懂指令、自主规划、安全执行。这不再是科幻,而是正在发生的技术变革。IQ-9100的100 TOPS NPU + SIL3安全岛 + 端侧大模型的组合,为具身智能提供了一个功耗仅35W的“大脑”。感谢你阅读本系列全部2篇文章,希望对你的机器人开发之旅有所帮助!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献31条内容
已为社区贡献31条内容

所有评论(0)