【机器学习】神经网络学习手册(四)损失函数
损失函数 Loss Function
用来衡量模型“错的有多离谱”
损失函数 = 模型预测值 vs 真实标签之间的差距
训练目标:找到一组权重,让损失函数的值最小化
- 损失越大 = 预测越差,需要优化
- 损失越小 = 预测越好,接近目标
常见的损失函数:
| 函数名 | 中文名 | 用途 |
|---|---|---|
| MSE | 均方误差 | 回归任务(预测房价、温度等连续值) |
| Cross-Entropy | 交叉熵 | 分类任务(猫狗识别、手写数字等) |
| BCE | 二分类交叉熵 | 二分类任务专用 |
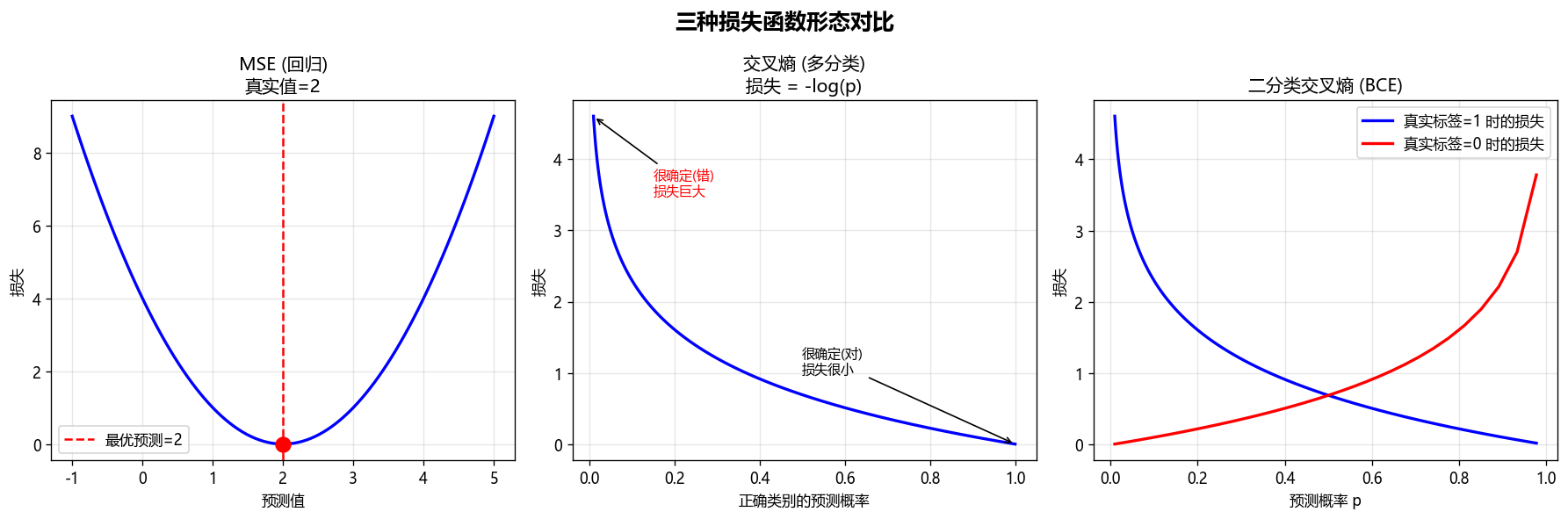
(1)均方误差
数学公式:
MSC=1n∗∑(ypred,i−ytrue,i)2 MSC = \cfrac 1n * \sum (y_{pred,i} -y_{true,i})^2 MSC=n1∗∑(ypred,i−ytrue,i)2
**特点:**对离群值敏感(误差被平方放大)
**用途:**房价预测 、股票预测、温度预测
代码实现:
def mse_loss(y_pred , y_true):
return np.mean((y_pred - y_true) ** 2)
MSE对预测值的梯度求导得:
∂L∂ypred=2n(ypred−ytrue) \frac{\partial L}{\partial y_{\text{pred}}} = \frac{2}{n} (y_{\text{pred}} - y_{\text{true}}) ∂ypred∂L=n2(ypred−ytrue)
代码实现:
def mse_gradient(y_pred, y_true):
n = len(y_pred)
return 2 * (y_pred - y_true) / n
(2)交叉熵
数学公式:
L=−1n∑i=1nlog(pi,ytrue,i) L = -\frac{1}{n} \sum_{i=1}^n \log(p_{i, y_{\text{true}, i}}) L=−n1i=1∑nlog(pi,ytrue,i)
其中 pi,ytrue,ip_{i, y_{\text{true}, i}}pi,ytrue,i 是第 iii 个样本正确类别的预测概率
特点:
- 对错误分类惩罚呈指数级增长
- 如果模型对正确类别给出高概率(如 0.99),损失很小(≈0.01)
- 如果模型对正确类别给出低概率(如 0.01),损失很大(≈4.6)
- 模型越不自信,惩罚越重
用途: 图像分类、文本分类、多类别识别任务
代码实现:
def cross_entropy_loss(probs, y_true_idx):
n = len(probs)
correct_probs = probs[np.arange(n), y_true_idx]
correct_probs = np.clip(correct_probs, 1e-12, 1.0) # 防止 log(0)
return -np.mean(np.log(correct_probs))
def softmax(x):
x_shifted = x - np.max(x, axis=-1, keepdims=True)
exp_x = np.exp(x_shifted)
return exp_x / np.sum(exp_x, axis=-1, keepdims=True)
(3)二分类交叉熵
数学公式:
L=−1n∑i=1n[yilog(pi)+(1−yi)log(1−pi)] L = -\frac{1}{n} \sum_{i=1}^{n} \left[ y_i \log(p_i) + (1 - y_i) \log(1 - p_i) \right] L=−n1i=1∑n[yilog(pi)+(1−yi)log(1−pi)]
其中 pip_ipi 是预测为正类的概率,yi∈{0,1}y_i \in \{0, 1\}yi∈{0,1} 是真实标签
特点:
- 专门用于二分类问题(是/否、真/假、正例/负例)
- 当预测正确且自信时损失接近 0
- 当预测错误时损失迅速增大
用途: 垃圾邮件检测、欺诈检测、疾病筛查、点击率预测
代码实现:
def binary_cross_entropy(y_pred, y_true):
"""
二分类交叉熵 (Binary Cross Entropy)
公式: L = -[y*log(p) + (1-y)*log(1-p)]
"""
epsilon = 1e-12
y_pred = np.clip(y_pred, epsilon, 1 - epsilon)
return -np.mean(y_true * np.log(y_pred) + (1 - y_true) * np.log(1 - y_pred))

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)