我用 RAG 搭建了企业知识库,效果比预期好太多
摘要
大模型很强大,但让它回答企业内部问题就经常"胡说八道"。RAG 技术能解决这个问题——通过检索私有数据增强生成,让 AI 回答更准确。本文从零开始搭建 RAG 系统,分享核心架构、实战经验和踩坑记录。
开篇引入
上周有个朋友问我:"公司想用大模型做个智能客服,但模型总瞎回答怎么办?"
这问题太典型了。大模型训练数据截止到某个时间点,你问它公司内部的产品信息、最新政策、技术文档,它怎么可能知道?强行让它回答,结果就是——一本正经地胡说八道。
后来我帮他搭了个 RAG 系统,效果立竿见影。今天就把这套方案分享出来,想落地的同学可以直接抄作业。
什么是 RAG?
RAG 全称 Retrieval-Augmented Generation,翻译过来叫"检索增强生成"。
听起来很玄乎,其实逻辑特别简单:
传统大模型:用户提问 → 模型直接回答
RAG 系统:用户提问 → 先去知识库里检索相关信息 → 把检索结果和问题一起喂给模型 → 模型基于检索内容回答
打个比方,传统大模型像个记忆力超群但信息过时的人,RAG 就是给这个人配了个实时搜索引擎,回答前先查资料。
核心架构拆解
一个完整的 RAG 系统,核心就三块:
1. 文档处理模块
这是地基。你得把各种格式的文档(PDF、Word、Markdown、网页)统一处理成模型能理解的文本。
这里有个坑:直接全文丢进去不行。文档太长会超出模型上下文窗口,而且检索精度也上不去。
我的做法是分块(Chunking):
# 按语义分块,不是简单按字数切
def chunk_document(text, chunk_size=500, overlap=50):
chunks = []
# 优先按段落、标题切分
# 保持语义完整性
return chunks
分块大小有讲究。太小了语义不完整,太大了检索不精准。我测试下来,中文文档 500-800 字一块比较合适,块之间留 50 字左右重叠,避免关键信息被切断。
2. 向量检索模块
这是 RAG 的心脏。把文本块转换成向量存起来,用户提问时也转成向量,然后找最相似的几个块。
向量数据库我推荐用 Chroma 或者 Milvus:
-
Chroma:轻量级,开发测试够用,一行代码就能跑
-
Milvus:企业级,支持海量数据,性能更强
嵌入模型(Embedding)的选择更关键。中文场景我用过几个:
-
text2vec:开源免费,效果还行 -
bge-large-zh:智源出品,中文效果最好 -
阿里云 DashScope:付费但省心,效果稳定
测试下来,bge-large-zh 在中文语义理解上确实领先一截,尤其是专业术语的匹配度。
3. 生成模块
最后一步,把检索到的相关文本块和用户问题一起拼成 Prompt,喂给大模型。
Prompt 设计有技巧:
你是一个专业的技术顾问。请根据以下参考资料回答问题。
如果参考资料里没有相关信息,请直接说"资料中没有找到相关内容",不要编造。
参考资料:
{retrieved_chunks}
用户问题:{question}
请回答:
关键点:明确告诉模型以参考资料为准,不知道就说不知道。这能大幅减少幻觉。

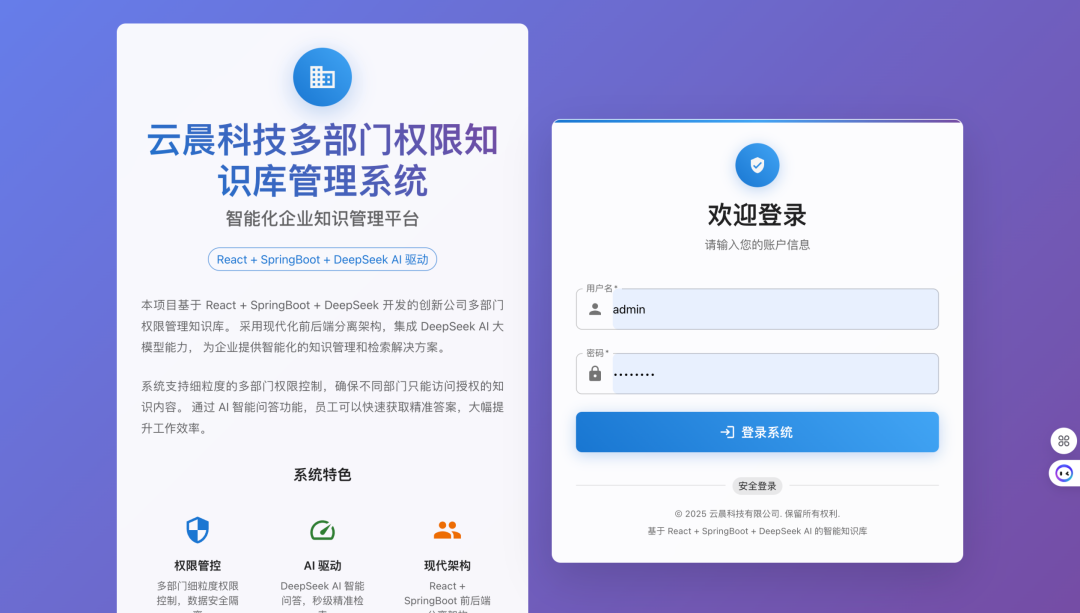
实战案例:搭建企业知识库
说个真实项目。给一家 SaaS 公司做产品知识库,需求是客服能快速查到产品功能、定价、API 文档。
第一步:数据整理
他们文档散落在 Notion、Confluence、GitBook 三个地方。我先写了个脚本统一抓取:
# 伪代码示意
docs = []
docs += fetch_from_notion(space_id)
docs += fetch_from_confluence(base_url)
docs += fetch_from_gitbook(book_id)
总共 300+ 文档,处理后得到 2000+ 文本块。
第二步:向量化存储
用 bge-large-zh 做嵌入,Chroma 做存储。2000 块数据,向量化大概花了 10 分钟,查询响应在 100ms 以内。
第三步:集成到客服系统
把 RAG 接口对接到他们的企业微信客服机器人。客服收到问题,先走 RAG 检索,有匹配结果就返回,没有就转人工。
效果怎么样?
上线两周,客服常见问题解决率从 45% 提升到 78%,人工咨询量降了一半。最明显的是,模型不再瞎编产品功能了——因为检索不到就说不知道。

技术对比:RAG vs Fine-tuning
经常有人问:RAG 和微调(Fine-tuning)选哪个?
我的建议:
|
场景 |
推荐方案 |
|---|---|
|
私有知识库、频繁更新 |
RAG |
|
特定领域风格学习 |
Fine-tuning |
|
两者结合 |
RAG + 轻量微调 |
RAG 的优势是数据更新成本低——新文档丢进去向量化就行,不用重新训练。微调的话,每次数据更新都得重新训,成本高还不一定及时。
但 RAG 也有局限:检索不到的信息还是回答不了。所以复杂场景可以组合使用——用微调让模型学会领域表达风格,用 RAG 提供实时知识。
踩坑记录
这几个坑是我真实踩过的,帮大家避一下:
坑 1:检索相关但答案不对
有时候检索出来的文本块看起来相关,但实际不包含答案。解决方案是提高检索数量,从 top-3 提到 top-5,让模型有更多上下文判断。
坑 2:多文档冲突
不同文档对同一问题的描述可能不一致。我在 Prompt 里加了优先级说明,让模型优先参考最新版本的文档。
坑 3:检索速度慢
数据量上来后检索变慢。优化方案:加元数据过滤(比如按文档类型、时间范围先筛一遍),再向量检索,能快 3-5 倍。
坑 4:中文分词问题
有些嵌入模型对中文专业术语理解不好。测试阶段一定要用真实业务问题做评估,别只看公开 benchmark。
注意事项
最后说几个落地建议:
-
从小规模开始:先选一个垂直场景验证,别一上来就搞全公司知识库
-
持续评估效果:定期抽样检查回答质量,记录 bad case 持续优化
-
权限控制:企业场景要注意文档权限,不同人能检索的内容应该不同
-
成本控制:向量存储和 API 调用都有成本,设计时考虑缓存和限流
结尾
RAG 不是银弹,但确实是大模型落地最实用的技术之一。
我这套方案已经帮三家公司落地了,效果都还不错。如果你也在做类似项目,欢迎交流踩坑经验。
互动一下:你们公司有用大模型做什么场景?遇到过哪些问题?评论区聊聊。
如果觉得这篇文章有帮助,点个"在看"支持一下,也欢迎转发给需要的同事。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)