Voice-Pro 免费开源杀疯了:语音翻译、AI克隆、人声分离、YouTube下载全打包,狂省上千元
你是否也曾想过做视频,英文视频翻译成中文发到国内,或者把自己做的中文视频配上地道的英文,扬帆出海?
然而,现实往往会给你迎头痛击:
- 工具太碎片
:用 yt-dlp 下载了视频,要用 Demucs 提取人声,再找 Whisper 生成字幕,最后还得找翻译软件,折腾一圈,头都大了。
- 钱包吃不消
:市面上好用的 AI 声音克隆和翻译工具(比如业界标杆 ElevenLabs,或者各大 SaaS 平台 Maestra、Kapwing、VEED.IO),动辄每个月几十美金。如果处理一个 60 分钟的视频,算上字幕、翻译、配音,折合人民币少则 170 元,多则 350 元!对于刚起步的自媒体人来说,这简直是“还没赚钱,先亏一笔”。
就在最近,自媒体圈和开源社区迎来了一个极重磅的炸弹——知名 AI 语音全能工作站 Voice-Pro 宣布彻底开源、完全免费!
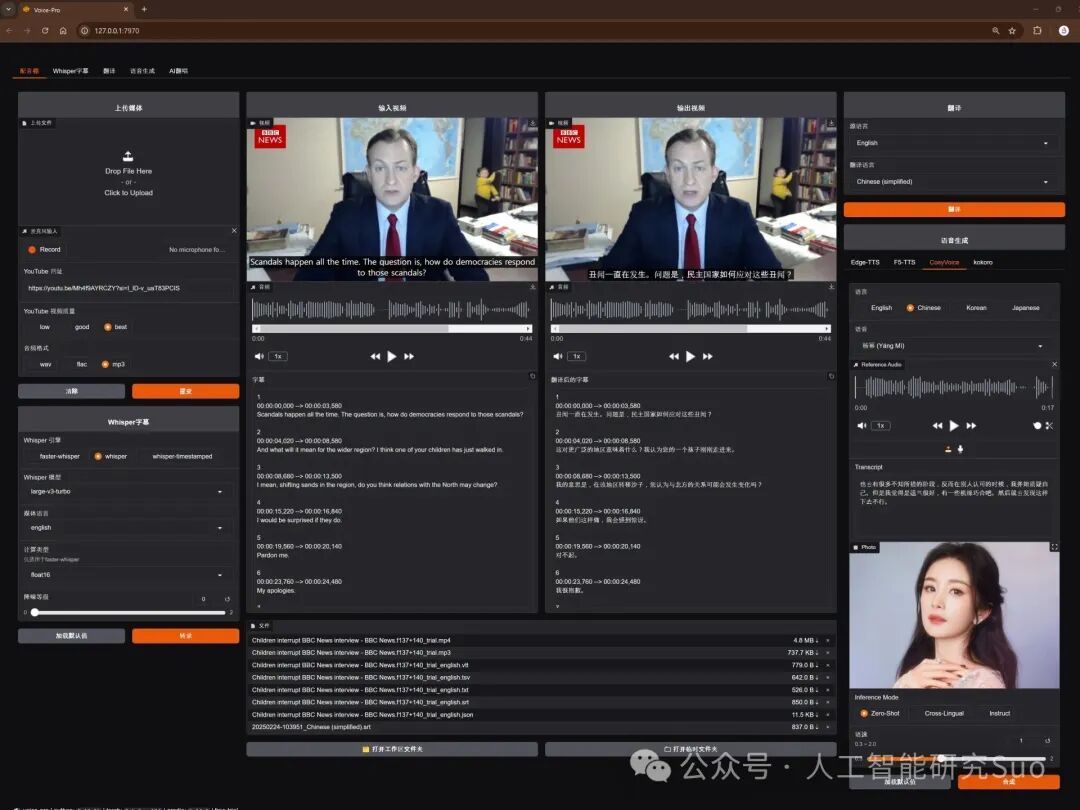
这家原本来自韩国的 AI 创业团队(ABUS),因为将重心转向全球文化交流应用 WeConnect 的开发,索性把这款曾经需要付费订阅(通过 Shopify 销售)的王牌商业软件毫无保留地全部公开。现在,你可以自由下载、自由修改,甚至在本地无限次运行,完全没有时长限制!
今天,这篇文章就带你深度拆解这款“自媒体出海的终极全能神器”,看看它到底有多强,以及你如何用它零成本搭建自己的“国际化内容生产线”。
零、 为什么说它是 ElevenLabs 的终极平替?
提到 AI 配音和声音克隆,大家首先想到的往往是 ElevenLabs。不可否认,它的效果很好,但价格也高得令人望而却步。而那些常见的视频处理 SaaS 平台,究竟有多贵?
我们来看一组 Voice-Pro 官方整理的 2025 年最新主流平台处理 60 分钟视频的价格对比:
- Maestra
:处理 60 分钟需要约 $23.70(约合人民币 170 元)
- Kapwing (Pro)
:处理 60 分钟需要 $30 - $40(约合人民币 210 - 280 元)
- VEED.IO (Pro)
:处理 60 分钟需要 $24 - $36(而且还没有 TTS 配音功能)
- HappyScribe
:处理 60 分钟需要 $36 - $48(约合人民币 250 - 340 元)
- Descript (Creator)
:处理 60 分钟需要 $36 - $48而 Voice-Pro 现在的价格是:0 元!免费!无限时长! 只要你有一台配备 NVIDIA 显卡的 Windows 电脑(Linux 和 Mac 也已支持),你就可以在本地无限次压榨它的算力,省下来的全都是纯利润!
一、 “配音工作室”:一条龙全自动化内容流水线
Voice-Pro 的核心魅力在于它的超高集成度。它不是一个单一的工具,而是一个集成了当下全球最顶尖 AI 模型的“全功能网页应用程序(WebUI)”。
在其最核心的 “配音工作室 (Dubbing Studio)” 标签页里,你只需要输入一个 YouTube 链接,它就能在后台为你自动完成以下所有炸裂的操作:
- 一键下载与音频提取
:内置 yt-dlp 引擎,全自动爬取 YouTube 视频并抽取无损音频。
- 伴奏人声分离
:集成 Meta 开源的顶级音频分离神器 Demucs。做过视频的都知道,原视频里往往有背景音乐(BGM)和噪音,直接配音会显得非常嘈杂。Demucs 可以完美地把人声干净地剥离出来,只针对纯净人声做识别,同时保留或去除 BGM。
- 多语言自然翻译
:利用 spaCy 库进行智能断句,让中文和外语之间的转化不再是冷冰冰的字对字翻译,而是符合人类说话习惯的自然语句,支持超过 100 种语言的即时互译。
- 音调速度随心控
:在最终生成 AI 语音(TTS)时,你可以自由调节语速、音量和音调,确保声音和原视频画面完美对齐,再也不会出现“画面演完了,配音还没说完”的尴尬情况。
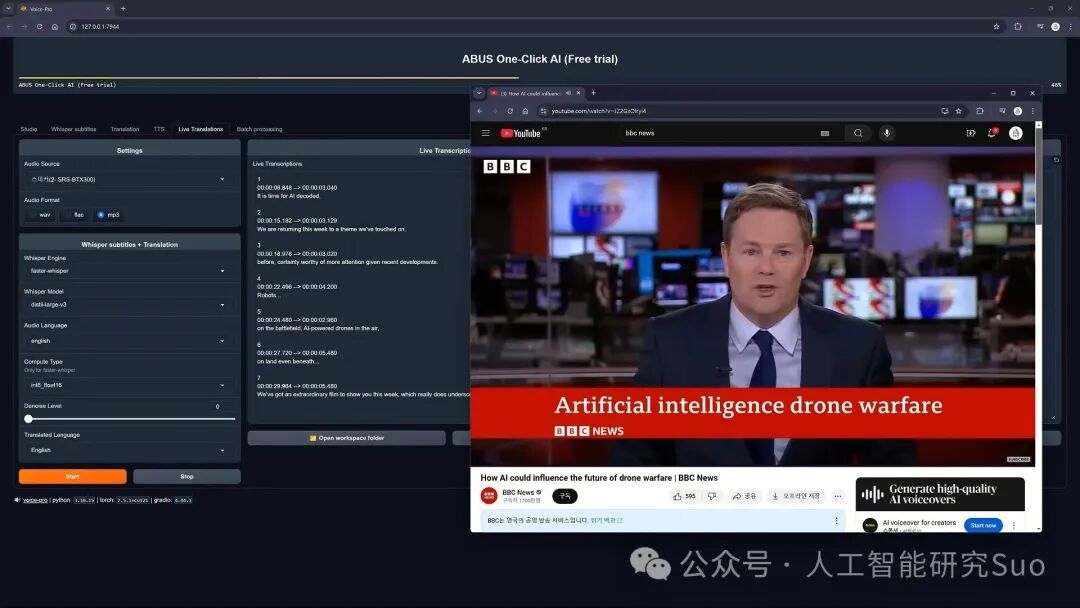
二、 语音技术天花板:地表最强开源模型群英会
Voice-Pro 之所以能达到商业级效果,是因为它把业内几乎所有拿过第一的开源 AI 模型全部“缝合”进去了。
1. 语音转文本(STT):Whisper 全家桶
有些工具语音识别率低,错别字连篇,后期人工修改能让人抓狂。Voice-Pro 直接集成了 OpenAI 的 Whisper 衍生矩阵:
- Whisper & Faster-Whisper
:速度极快,准确率高。
- Whisper-Timestamped
:带精准时间戳,保证字幕一个字都不会错位。
- WhisperX
:支持单词级(Word-level)高亮显示,能够实现极其精准的对齐和降噪。
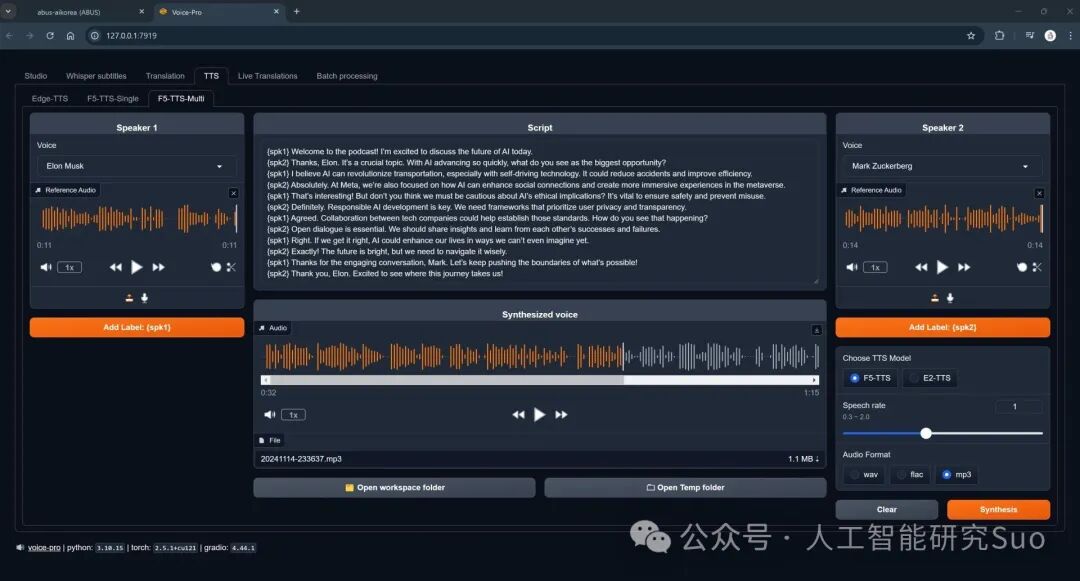
2. 文本转语音(TTS)与零样本声音克隆(Zero-Shot Voice Cloning)
这才是 Voice-Pro 真正封神的地方。它支持目前市面上最震撼的零样本(Zero-Shot)声音克隆技术。什么是零样本克隆?就是你只需要给它一段 3 到 5 秒的名人或你自己的语音样本,AI 就能立刻学会这个人的声音、语气和情感,并用这个声音去朗读任意文字!
它集成的模型包括:
- F5-TTS & E2-TTS
:目前开源界最火、效果最自然的语音克隆模型,支持微调,且官方已经内置了英语、中文、法语、日语、西班牙语、印地语、俄语等多种语言的混合说话人模型。
- CosyVoice
:阿里开源的顶级语音大模型,声音磁性逼真,情绪张力拉满。
- Kokoro
:在 HuggingFace TTS 竞技场中高居全球第二的超轻量高质感语音模型。
- Edge-TTS
:免去繁重模型加载,直接调用微软 Edge 强大的网络语音库,支持 100 多种语言、400 多种极高品质的内置声音。
3. 自带“顶级大咖”声音克隆库!
在项目的 Issues 和预设中,官方甚至贴心地为你整理和准备了全球各种顶流名人的声音样本。
- 英文大咖
:马斯克(Elon Musk)、奥特曼(Sam Altman)、扎克伯格(Mark Zuckerberg)、特朗普(Donald Trump)、贝佐斯(Jeff Bezos)、知名网红 MrBeast、乔·罗根(Joe Rogan)等。
- 中文顶流
:迪丽热巴、赵丽颖、杨幂、蔡依林等。
- 日韩巨星
:绫濑遥、BTS 的 Jin 和 RM、IU(李知恩)、李秉宪、李政宰、刘在石等。
想象一下,你可以用马斯克的声音去配音一段科技解说视频,或者用迪丽热巴的声音去读一段情感小说。这种自带流量的“吸睛效果”,在短视频平台上就是妥妥的爆款密码!
三、 四大王牌功能模块,满足一切内容创作
Voice-Pro 的界面基于 Gradio 构建,操作非常直观,主要分为四大核心标签页:
- 配音工作室(Dubbing Studio)
: 自媒体人的主力战场。YouTube 下载、降噪、字幕提取、一键翻译、TTS 情感配音一条龙,支持输出 WAV、FLAC、MP3 等所有主流音频格式。
- Whisper 字幕专家(Whisper Subtitles)
: 专为写稿、做字幕准备。支持 90 多种语言的精准视频集成字幕显示,提供单词级高亮和高阶降噪选项。
- 全能翻译官(Translation)
: 不仅可以实时进行语音识别和双语翻译,还支持直接导入现有的字幕文件(ASS、SSA、SRT 等),一键翻译整个字幕,保留原有的时间戳。
- AI 语音生成器(Voice Generation)
: 播客主创的福音。你可以直接利用 Edge-TTS、F5-TTS、CosyVoice、Kokoro 等模型,导入你喜欢的声音样本,制作极高品质的多人对话播客、有声书或外语教学音频。
四、 硬件要求与避坑指南(小白必看)
既然是全套本地运行的 AI 商业级工具,对电脑自然有一定要求。
1. 系统要求
- 操作系统
:Windows 10/11(64位)运行最完美。Mac 和 Linux 目前也已经支持。
- 显卡(核心)
:强烈推荐NVIDIA(英伟达)显卡,且需支持 CUDA 12.4。
- 显存(VRAM)
:最低 4GB,推荐 8GB 以上。
- 内存
:4GB 以上。
- 硬盘空间
:预留 20GB 以上的可用空间。因为首次运行会下载很多高精度模型(例如 CosyVoice2-0.5B 模型就有 9GB,根据网速可能需要下载 1 小时以上)。
2. 官方独家调优技巧
在跑本地模型时,很多人容易遇到爆显存或质量不佳的问题,官方给出了几个非常实用的黄金技巧:
- 遇到 CUDA 内存不足(OOM)怎么办?
-
打开任务管理器检查 GPU 显存。
-
将“降噪级别(Denoiser)”调整为 0 或 1(级别 2 需要 8GB 以上显存)。
-
将计算类型(Compute Type)设置为 int 类型。虽然 float 类型质量最好,但 int 类型通过模型量化降低了显存占用,速度还会大幅提升!
- 如何白嫖更高字幕质量?
模型选择遵循 large > medium > small > base > tiny。如果有 8GB 以上显存,果断开启 large 或 medium 模型,并配合更高的降噪级别去除视频背噪,识别率会无限接近 100%。
- 万一运行报错崩溃了怎么办?
开源项目最怕配置冲突。官方给出了极简单的故障排除法:直接删除文件夹里的 installer_files 目录,然后重新依次运行 configure.bat 和 start.bat 即可完美解决 90% 的问题!
五、 如何快速安装入手?
由于官方已经做好了高度便携化的批处理脚本,安装完全不需要你懂复杂的 Python 编程,傻瓜式三步走:
- 下载源码
:去 GitHub Release 页面下载最新的 Source code (zip) 包,或者用 Git 命令克隆:
-
Bash
-
git clone https://github.com/abus-aikorea/voice-pro.git
- 一键环境配置
:双击运行 configure.bat。它会自动检测并为你安装 Git、FFmpeg 以及配置 NVIDIA CUDA 环境。这期间需要保持网络畅通,耐心等待下载完成。
- 一键启动
:配置完成后,双击运行 start.bat。它会拉起 Web 界面。如果浏览器没有自动弹出来,直接在浏览器地址栏输入命令行里显示的本地连接:http://127.0.0.1:7870 即可。
后续如果项目有更新,直接双击 update.bat 就能实现免重装快速升级,非常人性化。
结语
在 AI 技术日新月异的今天,像 Voice-Pro 这样原本走商业订阅路线、如今却选择全面开源并完全免费的项目,简直是科技界和创作者圈的“大慈善家”。
它不仅打破了 ElevenLabs 等行业巨头的收费垄断,更为广大的独立内容创作者、播客创作者以及出海自媒体人,提供了一把无限制的“生产力利器”。
如果你也想在 2026 年弯道超车,用 AI 赋能自己的视频内容,赶紧去 GitHub 给这个宝藏项目点个 Star(星星) 吧!在这个全员高声收费的时代,这样良心且强大的全能工具,错过了真的拍大腿!
- 项目开源地址
:https://github.com/abus-aikorea/voice-pro
更多transformer,VIT,swin tranformer
参考头条号:人工智能研究所
v号:人工智能研究Suo, 启示AI科技动画详解transformer 在线视频教程



AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献41条内容
已为社区贡献41条内容

所有评论(0)