YOLOv11厨房食材目标检测数据集-2499张-Meat-1_5
YOLOv11厨房食材目标检测数据集
📊 数据集基本信息
- 目标类别: [‘ayam’, ‘beef’, ‘pork’]
- 中文类别:[‘鸡肉’, ‘牛肉’, ‘猪肉’]
- 训练集:2256 张
- 验证集:164 张
- 测试集:79 张
- 总计:2499 张
📄 data.yaml 配置信息
该数据集提供了data.yaml文件,内容如下:
train: ../train/images
val: ../valid/images
test: ../test/images
nc: 3
names: ['ayam', 'beef', 'pork']
🖼️ 标注可视化
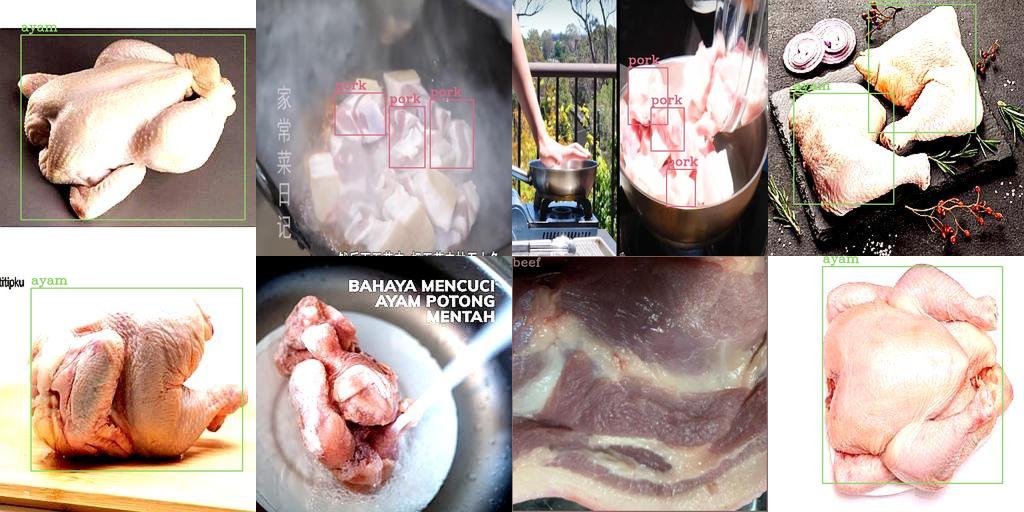

📝 数据集分析
YOLOv11厨房食材目标检测数据集
该数据集专注于厨房环境中各类生鲜肉类的精准识别,涵盖鸡肉、牛肉和猪肉等核心食材。通过高精度标注,为智能厨房设备、食品加工自动化系统及餐饮行业提供可靠的数据支撑,助力提升食材管理效率与食品安全水平。
数据集包含2499张标注图像,其中训练集2256张、验证集164张、测试集79张。这种分布比例符合机器学习最佳实践,能够有效支持模型训练、性能验证与最终评估,确保模型在不同场景下的泛化能力。
所有图像均经过专业人员严格标注,每个目标物体均有精确的边界框定位。标注过程遵循统一规范,确保各类食材(鸡肉、牛肉、猪肉)的识别边界清晰准确,为深度学习模型提供高质量的训练样本。
该数据集可广泛应用于智能厨房设备开发、食品加工生产线自动化、餐饮业食材管理系统等领域。其精准的目标检测能力有助于提升食材识别效率,保障食品加工过程的安全性与标准化,为智慧餐饮和家庭烹饪提供技术支持。
YOLOv11训练步骤
一、环境安装
pip install ultralytics
# 依赖要求:Python≥3.8,PyTorch≥1.8。安装完成后可通过 `yolo checks` 验证环境。
二、数据集准备(YOLO格式)
1. 目录结构
数据集必须严格按以下结构组织:
dataset/
├── train/
│ ├── images/ # 训练图片(jpg/png)
│ └── labels/ # YOLO格式标注(txt)
├── val/
│ ├── images/
│ └── labels/
└── data.yaml # 数据集配置文件
2. YOLO标注格式
每个 *.txt 文件对应一张图片,每行格式为:
class_id center_x center_y width height
所有数值均为相对于图片宽高的归一化值(0~1)。
3. data.yaml 配置文件
# data.yaml
path: ../dataset # 数据集根目录(相对或绝对路径)
train: train/images # 训练集图片路径
val: val/images # 验证集图片路径
test: test/images # 测试集图片路径(可选)
# 类别信息
nc: 2 # 类别数量
names: ['class1', 'class2'] # 类别名称列表
三、模型选择
YOLO11 提供 5 种尺度,官方命名规则为 yolo11{n/s/m/l/x}.pt:
| 模型 | 参数量 | 适用场景 |
|---|---|---|
yolo11n |
2.6M | 边缘设备、速度优先 |
yolo11s |
9.4M | 平衡精度与速度 |
yolo11m |
20.1M | 常规GPU训练 |
yolo11l |
25.3M | 高精度需求 |
yolo11x |
56.9M | 极致精度、算力充足 |
四、模型训练
方式1:Python API(推荐)
创建 train.py:
from ultralytics import YOLO
def main():
# 加载预训练模型(推荐:基于COCO预训练权重微调)
model = YOLO("yolo11m.pt")
# 训练参数
train_params = {
'data': 'data.yaml', # 数据集配置文件
'epochs': 100, # 训练轮次
'imgsz': 640, # 输入图像尺寸
'batch': 16, # 批次大小(根据显存调整)
'device': '0', # GPU设备号,'cpu'表示CPU训练
'workers': 8, # 数据加载线程数
'optimizer': 'SGD', # 优化器:SGD/Adam/AdamW
'lr0': 0.01, # 初始学习率
'patience': 50, # 早停耐心值
'save': True, # 保存模型
'project': 'runs/train', # 项目保存路径
'name': 'exp', # 实验名称
'single_cls': False, # 单类别检测设为True
'close_mosaic': 10, # 最后N轮关闭马赛克增强
}
# 开始训练
results = model.train(**train_params)
# 输出最佳模型路径
print(f"Best model saved at: {results.best}")
if __name__ == '__main__':
main()
三种模型加载方式对比:
# 方式A:从YAML构建全新模型(从头训练,适合网络结构改进)
model = YOLO("yolo11m.yaml")
# 方式B:加载预训练权重(最常用,推荐)
model = YOLO("yolo11m.pt")
# 方式C:构建新模型并迁移预训练权重(改进网络后使用)
model = YOLO("yolo11m.yaml").load("yolo11m.pt")
方式2:命令行 CLI
# 基础训练
yolo detect train data=data.yaml model=yolo11m.pt epochs=100 imgsz=640 batch=16 device=0
# 多GPU训练
yolo detect train data=data.yaml model=yolo11m.pt epochs=100 device=0,1
# 从YAML+预训练权重训练
yolo detect train data=data.yaml model=yolo11m.yaml pretrained=yolo11m.pt epochs=100
五、关键训练参数说明
| 参数 | 说明 | 建议值 |
|---|---|---|
epochs |
训练总轮次 | 100~300 |
imgsz |
输入尺寸 | 640(标准) |
batch |
批次大小 | 8/16/32(根据显存) |
device |
训练设备 | 0(单GPU)、0,1(多GPU)、cpu、mps(Apple芯片) |
workers |
数据加载线程 | 8~16(Windows建议≤8) |
optimizer |
优化器 | SGD(默认)、Adam、AdamW |
lr0 / lrf |
初始/最终学习率 | 0.01 / 0.01 |
momentum |
SGD动量 | 0.937 |
weight_decay |
权重衰减 | 0.0005 |
single_cls |
单类别模式 | True/False |
resume |
恢复中断训练 | True(需指定last.pt) |
amp |
自动混合精度 | True(默认开启,省显存) |
六、模型验证
创建 val.py:
from ultralytics import YOLO
def main():
# 加载训练好的最佳权重
model = YOLO('runs/train/exp/weights/best.pt')
# 验证
metrics = model.val(
data='data.yaml',
split='val', # 验证集:'val' 或 'test'
imgsz=640,
batch=16,
iou=0.6, # NMS IoU阈值
device='0',
save_json=False, # 是否保存COCO格式JSON
)
# 输出关键指标
print(f"mAP50-95: {metrics.box.map}") # mAP@0.5:0.95
print(f"mAP50: {metrics.box.map50}") # mAP@0.5
print(f"mAP75: {metrics.box.map75}") # mAP@0.75
if __name__ == '__main__':
main()
CLI 方式:
yolo detect val model=runs/train/exp/weights/best.pt data=data.yaml
七、模型推理/预测
创建 predict.py:
from ultralytics import YOLO
import cv2
def main():
model = YOLO('runs/train/exp/weights/best.pt')
# 单张图片推理
results = model.predict(
source='test_images/', # 图片路径、文件夹、URL或摄像头索引(0)
imgsz=640,
conf=0.25, # 置信度阈值
iou=0.45, # NMS IoU阈值
device='0',
save=True, # 保存结果图
show=False, # 是否弹窗显示
)
# 遍历结果
for result in results:
boxes = result.boxes # 检测框
masks = result.masks # 分割掩码(如使用分割模型)
probs = result.probs # 分类概率
# 获取坐标、置信度、类别
for box in boxes:
x1, y1, x2, y2 = box.xyxy[0].tolist()
conf = box.conf[0].item()
cls = int(box.cls[0].item())
print(f"Class: {cls}, Conf: {conf:.2f}, Box: [{x1:.1f}, {y1:.1f}, {x2:.1f}, {y2:.1f}]")
if __name__ == '__main__':
main()
CLI 方式:
yolo detect predict model=runs/train/exp/weights/best.pt source=test_images/ save=True
## 数据集下载> 小郭AI日志
t(f"Class: {cls}, Conf: {conf:.2f}, Box: [{x1:.1f}, {y1:.1f}, {x2:.1f}, {y2:.1f}]")
if name == ‘main’:
main()
CLI 方式:
```bash
yolo detect predict model=runs/train/exp/weights/best.pt source=test_images/ save=True
## 数据集下载> 小郭AI日志

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 0
0 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)