【论文阅读】Unified 4D World Action Modeling from Video Priors with Asynchronous Denoising
·
快速了解部分
基础信息(英文):
1.题目: Unified 4D World Action Modeling from Video Priors with Asynchronous Denoising
2.时间: 2026.05
3.机构: Tsinghua University, Xiaomi Robotics, Peking University, CASIA
4.3个英文关键词: 4D World Model, Asynchronous Denoising, Depth Adaptation
1句话通俗总结本文干了什么事情
本文提出了一种名为 X-WAM 的统一 4D 世界模型,能在预测机器人动作的同时,生成包含 3D 空间信息的高保真视频,且通过异步去噪技术保证了动作执行的实时性。
研究痛点:现有研究不足 / 要解决的具体问题
- 缺乏 3D 空间感知:现有的统一世界模型(如 UWM)大多停留在 2D 像素空间,无法处理 3D 几何结构,导致机器人容易产生物理上不合理的幻觉。
- 效率与质量的矛盾:生成高质量视频需要很多计算步骤,但机器人实时控制需要极低的延迟,如何在保证生成质量的同时快速解码动作是一个难题。
核心方法:关键技术、模型或研究设计(简要)
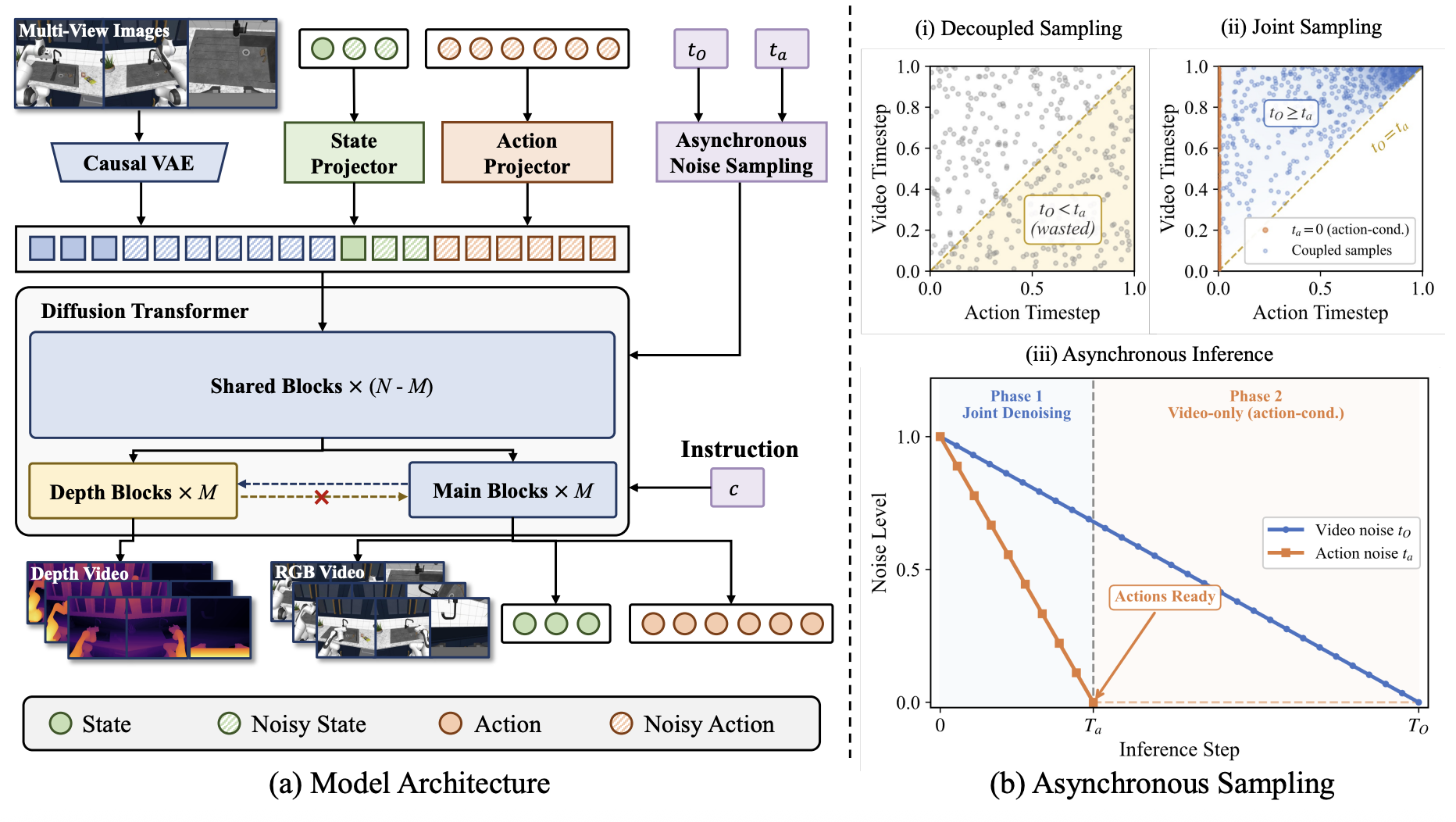
- 轻量级深度适配(Depth Adaptation):复制预训练 DiT 模型的最后几层构建专用深度分支,低成本地从 RGB 视频中预测深度信息,实现 4D 重建。
- 异步噪声采样(ANS):训练时模拟推理时的分布,让动作和视频以不同的速度去噪,推理时先快速解码动作执行,再慢慢补全视频细节。
深入了解部分
作者想要表达什么
一个统一的模型框架可以同时胜任**机器人控制(Policy)和世界模拟(World Modeling)**两项任务。通过引入显式的 3D 空间感知(4D 建模)和优化计算效率(异步去噪)
,这种模型不仅能像 VLA 那样精准控制机器人,还能像世界模型那样高保真地想象未来场景。
相比前人创新在哪里
- 从 2D 到 4D 的跨越:不同于前人只在 2D 空间建模,本文明确引入了 Depth(深度)预测,利用多视角几何重建 3D 空间,让模型具备了物理世界的几何直觉。
- 训练与推理分布对齐:针对动作和视频生成步数不同的问题,提出了 ANS 采样策略,通过联合分布采样解决了训练(独立采样)和推理(异步)之间的分布不匹配问题。
解决方法/算法的通俗解释
- 看透 3D(Depth Adaptation):就像人不仅能看颜色还能感知距离一样,模型在生成视频画面的同时,分出一个小分支专门去“猜”画面里物体的远近(深度)。这个分支很轻量,不增加太多计算负担。
- 手脚并用(Asynchronous Denoising):好比人做动作时,大脑先快速决定“现在要伸手抓杯子”(快速解码动作),然后在动作执行的过程中,再慢慢细化“杯子的花纹和倒影”(补全视频细节)。模型让动作先快速“显形”,视频慢慢“跟上”。
解决方法的具体做法
- 模型架构:基于预训练的 Video DiT,输入包括语言指令、初始 RGB 和状态。输出包括未来的 RGB 视频、深度图(Depth)、机器人状态和动作。
- 深度预测:不把深度图作为额外的 Token 拼接(那样太慢),而是复用主干网络最后几层的权重,构建一个平行的轻量级分支专门输出深度图。
- 异步采样(ANS):在训练时,故意让视频和动作的噪声步数不一致。一部分样本让动作先去噪(步数少),视频后去噪(步数多),以此模拟推理时的真实场景。
基于前人的哪些方法
- 基础模型:基于 Wan2.2-TI2V-5B(一个预训练的视频生成 Diffusion Transformer)。
- 统一建模范式:借鉴了 UWM (Unified World Models) 和 Motus 的思想,将视频生成和动作预测放在同一个序列里处理。
- 3D 重建原理:利用多视角几何(Multi-view Geometry),通过预测末端执行器位姿结合手眼标定矩阵来推算腕部相机位姿,从而融合点云。
实验设置、数据、评估方式、结论
- 数据:预训练使用了超过 5800 小时的机器人数据(包括 RoboCasa, RoboTwin 2.0, DROID 等)。
- 评估基准:
- 策略执行:在 RoboCasa 和 RoboTwin 2.0 上测试任务成功率(Success Rate)。
- 生成质量:评估 RGB 指标(PSNR, SSIM, LPIPS)和深度/点云指标(AbsRel, Chamfer Distance)。
- 结论:
- SOTA 表现:在 RoboCasa 上达到 79.2% 的成功率,超越了包括 Cosmos Policy 在内的所有基线。
- 4D 重建:生成的深度图和点云在几何指标上显著优于仅做 2D 预测再转 3D 的方法。
- 实机验证:在小米的双臂机器人 AC One 上完成了耳机装盒任务,证明了方法在复杂长程任务中的鲁棒性。
提到的同类工作
- UWM:统一世界模型的先驱,但仅限于 2D 像素空间。
- Cosmos Policy:将动作 Token 直接拼接到视频序列中进行联合预测。
- DreamZero:利用视频生成模型做零样本策略,但缺乏显式的 3D 空间建模。
和本文相关性最高的3个文献
- Cosmos Policy:同为基于视频生成模型的策略,本文直接将其作为主要对比基线,且在 RoboCasa 上超越了它。
- UWM:本文工作的直接前身,本文解决了 UWM 缺乏 3D 空间感知的缺陷。
- Wan2.2-TI2V-5B:本文所基于的预训练视频大模型底座,提供了强大的视觉先验知识。
我的
- 在视频生成基础上,加了一个深度图生成。把网络后面几层分支copy了一份来生成深度。
- 所谓异步采样,就是视频生成要50步去噪,动作10步去噪更快。那么为了省时间,推理时就要求动作去噪完成时就将动作信号发出让电机执行,然后视频生成继续剩下的去噪步骤。
- 然后为了匹配这个推理方案,他在训练的时候有一些改进。之前训练方案是独立给视频和动作随机分配噪声步数的,那么看上面的图,有一些情况下是浪费的,没必要训。现在是让视频的噪声步数依赖于动作的步数,也就是要求训练的时候动作的模糊程度必须低于视频的模糊程度。这样训练出来的模型,就知道“当动作干净时,视频可以继续去噪”这一逻辑。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)