MySQL 索引到底怎么工作的?一篇讲清 B+ 树、联合索引、覆盖索引和回表
很多人刚学 MySQL 索引时,第一反应都是:
加了索引,查询就会变快。
这句话没错,但它只说对了一半。
索引确实能提高查询效率,可它并不是“万能加速器”。如果不了解索引底层结构,不知道联合索引的匹配规则,也不清楚什么是覆盖索引和回表,那么在实际开发中很容易出现一种情况:明明建了索引,SQL 还是很慢。
这篇文章就围绕 MySQL 索引中最常见、也最容易被问到的几个知识点展开:
- B+ 树索引原理
- 联合索引最左前缀原则
- 覆盖索引
- 回表
适合 Redis、MySQL 刚入门到准备面试阶段的同学阅读。
一、为什么 MySQL 要用索引?
假设有一张用户表 user:
create table user ( id bigint primary key, name varchar(50), age int, phone varchar(20) );如果没有索引,执行下面这条 SQL:
select * from user where name = 'Jack';MySQL 只能从第一行开始,一行一行往后找。
如果表里只有几百条数据,问题不大;
如果表里有几百万、几千万条数据,全表扫描的成本就很高。
索引的作用,就是给数据建立一套更适合查找的结构,让 MySQL 不用每次都从头扫到尾。
可以简单理解为:
索引就像书的目录,先通过目录定位章节,再去看具体内容。
二、为什么 InnoDB 使用 B+ 树?
MySQL InnoDB 默认使用 B+ 树作为索引结构。
为什么不是普通二叉树、红黑树,或者 B 树呢?
1. 二叉树的问题
普通二叉树在极端情况下可能退化成链表:
1
\
2
\
3
\
4
这样查找数据还是接近全表扫描。
2. 红黑树的问题
红黑树虽然可以保持相对平衡,但它每个节点通常只存一个 key。
当数据量很大时,树的高度会比较高,查找时需要经过更多层节点。
数据库查询数据,经常涉及磁盘 IO。
树越高,访问磁盘的次数可能就越多。
3. B+ 树的优势
B+ 树有几个非常适合数据库索引的特点:
| 特点 | 说明 |
|---|---|
| 多路平衡 | 一个节点可以存多个 key,树的高度更低 |
| 非叶子节点只存索引 | 可以放下更多 key,减少磁盘 IO |
| 叶子节点存放完整索引数据 | 查询最终都会落到叶子节点 |
| 叶子节点之间有链表 | 非常适合范围查询 |
B+ 树大致长这样:
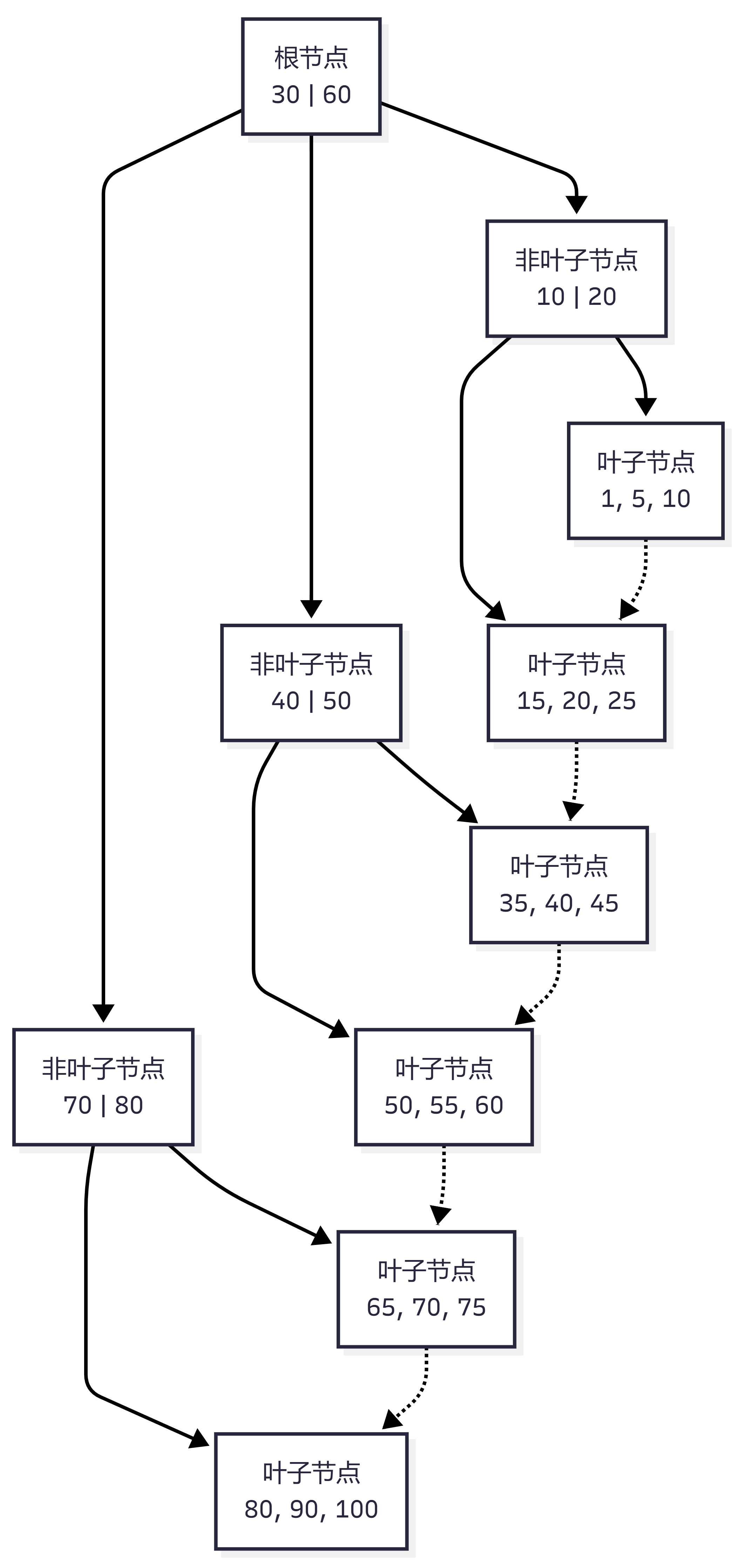
查询单条数据时,可以从根节点一路定位到叶子节点。
查询范围数据时,找到起点后,可以顺着叶子节点之间的链表继续往后扫。
这就是 B+ 树非常适合数据库索引的原因。
三、聚簇索引和二级索引
理解回表之前,先要搞清楚 InnoDB 的两类索引。
1. 聚簇索引
InnoDB 中,主键索引就是聚簇索引。
它的特点是:
叶子节点保存的是完整的一行数据。
比如:
select * from user where id = 1;如果 id 是主键,MySQL 通过主键 B+ 树找到叶子节点后,就能直接拿到整行数据。
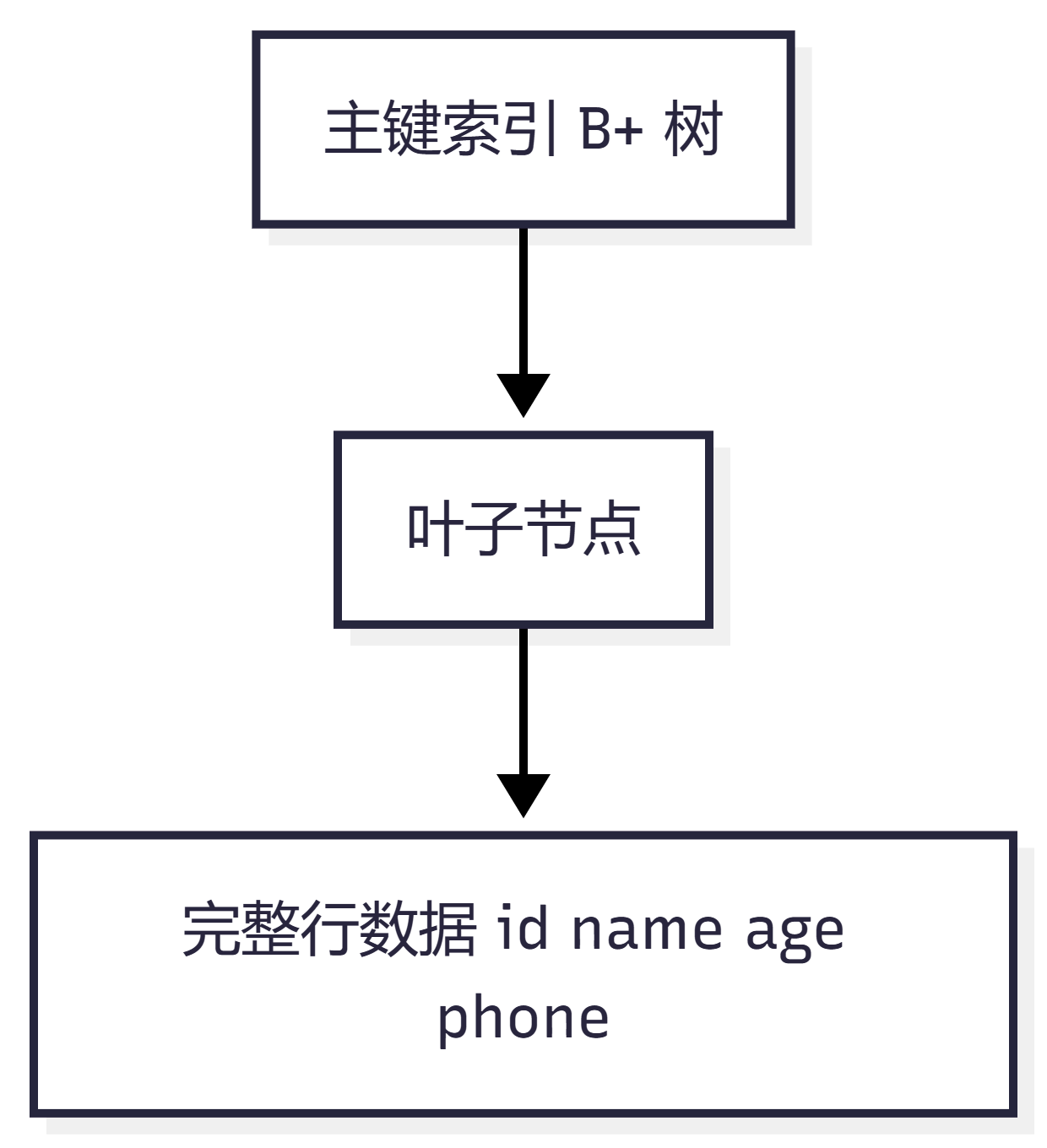
2. 二级索引
除了主键索引之外,自己创建的普通索引、唯一索引、联合索引,都属于二级索引。
二级索引的叶子节点保存的不是完整行数据,而是:
索引列的值 + 主键值
比如给 name 建索引:
create index idx_name on user(name);那么 idx_name 这个二级索引的叶子节点大概保存:
name = Jack, id = 1
name = Rose, id = 2
name = Tom, id = 3
也就是说,通过二级索引可以先找到主键 id,再根据主键 id 去主键索引里查完整数据。
这一步,就是后面要讲的“回表”。
四、什么是回表?
来看一条 SQL:
select * from user where name = 'Jack';假设 name 字段有普通索引 idx_name。
执行过程大概是:
- 先走 idx_name 索引,找到 name = Jack 对应的主键 id
- 再拿着 id 去主键索引中查询完整行数据
- 返回查询结果
这个“从二级索引回到主键索引查完整数据”的过程,就叫回表。
流程图如下:
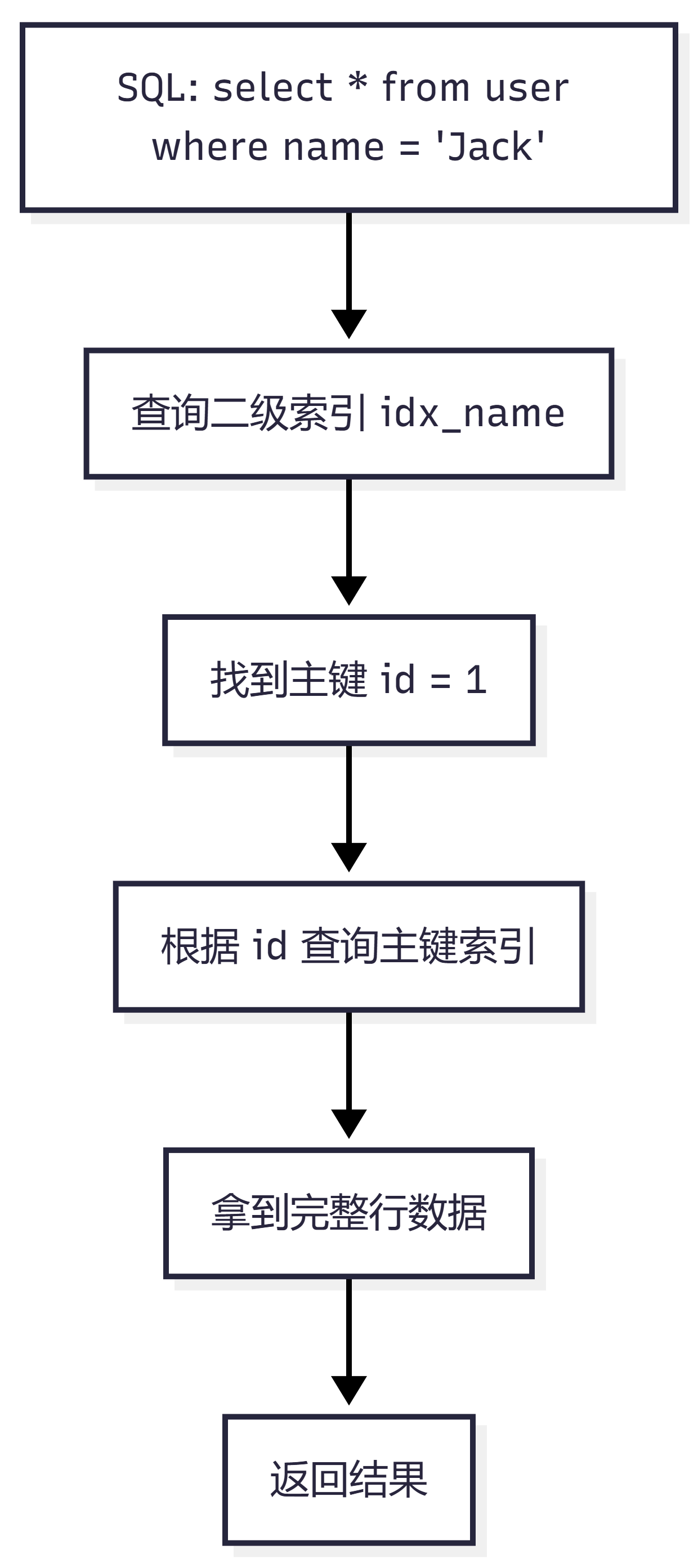
回表不是一定很慢,但如果回表次数很多,性能就会明显下降。
比如:
select * from user where age > 18;
select * from user where age > 18;如果 age 索引命中了几十万条记录,每条记录都要回表一次,那成本就很高了。
五、什么是覆盖索引?
覆盖索引不是一种新的索引类型,而是一种查询现象。
如果一条 SQL 查询需要的字段,在某个索引里已经全部包含了,那么 MySQL 只查这个索引就能拿到结果,不需要回表。
这就叫覆盖索引。
比如有一个联合索引:
create index idx_name_age on user(name, age);执行:
select name, age from user where name = 'Jack';
这条 SQL 只需要 name 和 age 两个字段,而这两个字段都在 idx_name_age 索引中。
所以 MySQL 查询二级索引后,就可以直接返回结果,不需要再根据主键 id 回表。
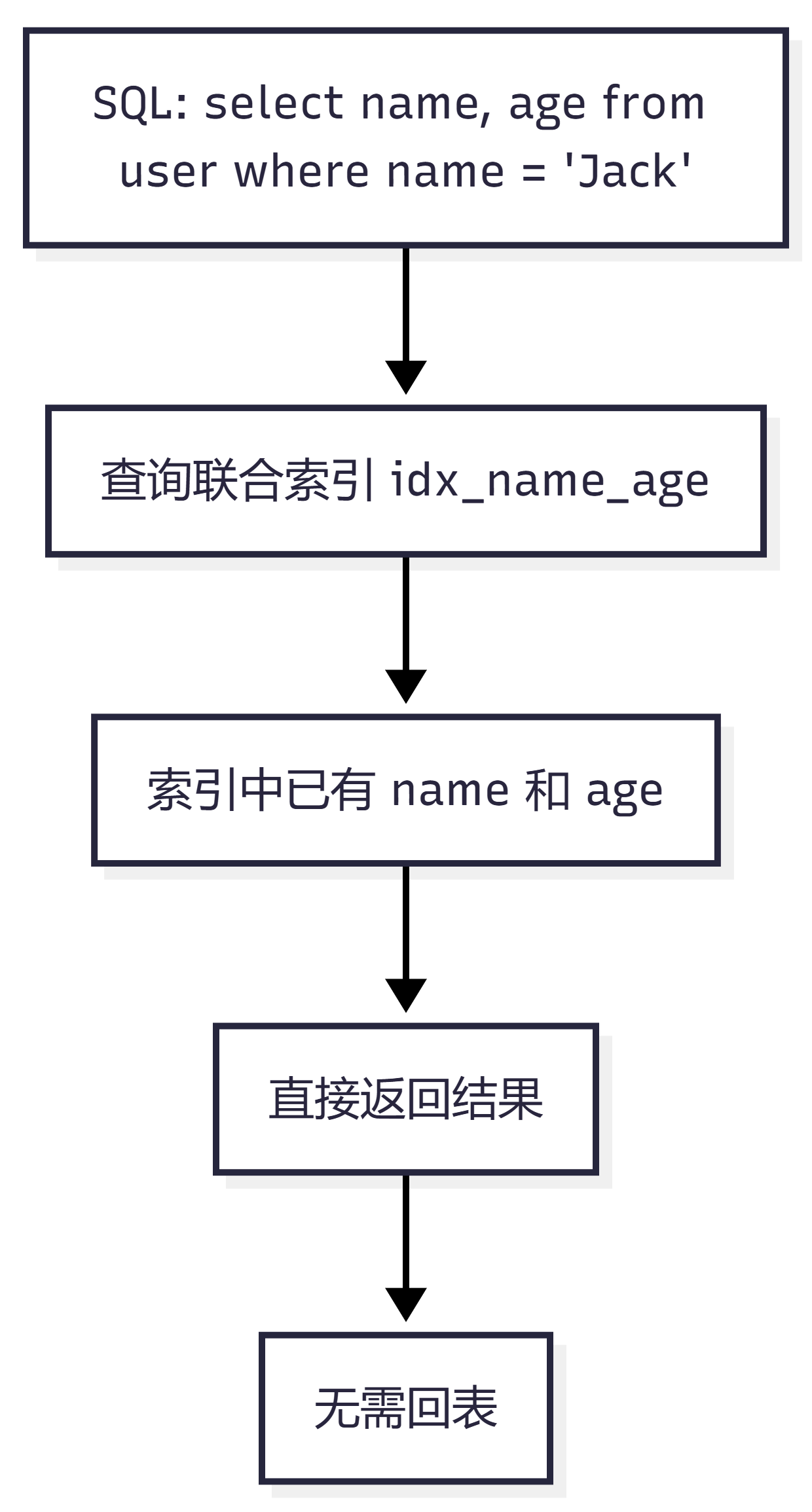
如果执行的是:
select * from user where name = 'Jack';因为 phone 等字段不在 idx_name_age 中,所以仍然需要回表。
如何判断是否使用覆盖索引?
可以使用 EXPLAIN:
explain select name, age from user where name = 'Jack';如果 Extra 中出现:
Using index
通常说明使用了覆盖索引。
注意,Using index 和 Using index condition 不是一回事:
| Extra | 含义 |
|---|---|
| Using index | 覆盖索引,不需要回表 |
| Using index condition | 索引下推,可能仍然需要回表 |
六、联合索引是什么?
联合索引就是多个字段组成的索引。
例如:
create index idx_name_age_phone on user(name, age, phone);这个索引不是给 name、age、phone 分别建了三个独立索引,而是按照字段顺序组成了一个整体索引。
联合索引内部大致是这样排序的:
先按 name 排序 name 相同,再按 age 排序 age 相同,再按 phone 排序
例如:
Jack, 18, 13800000001 Jack, 20, 13800000002 Rose, 19, 13800000003 Tom, 22, 13800000004
因为联合索引是有顺序的,所以字段顺序非常重要。
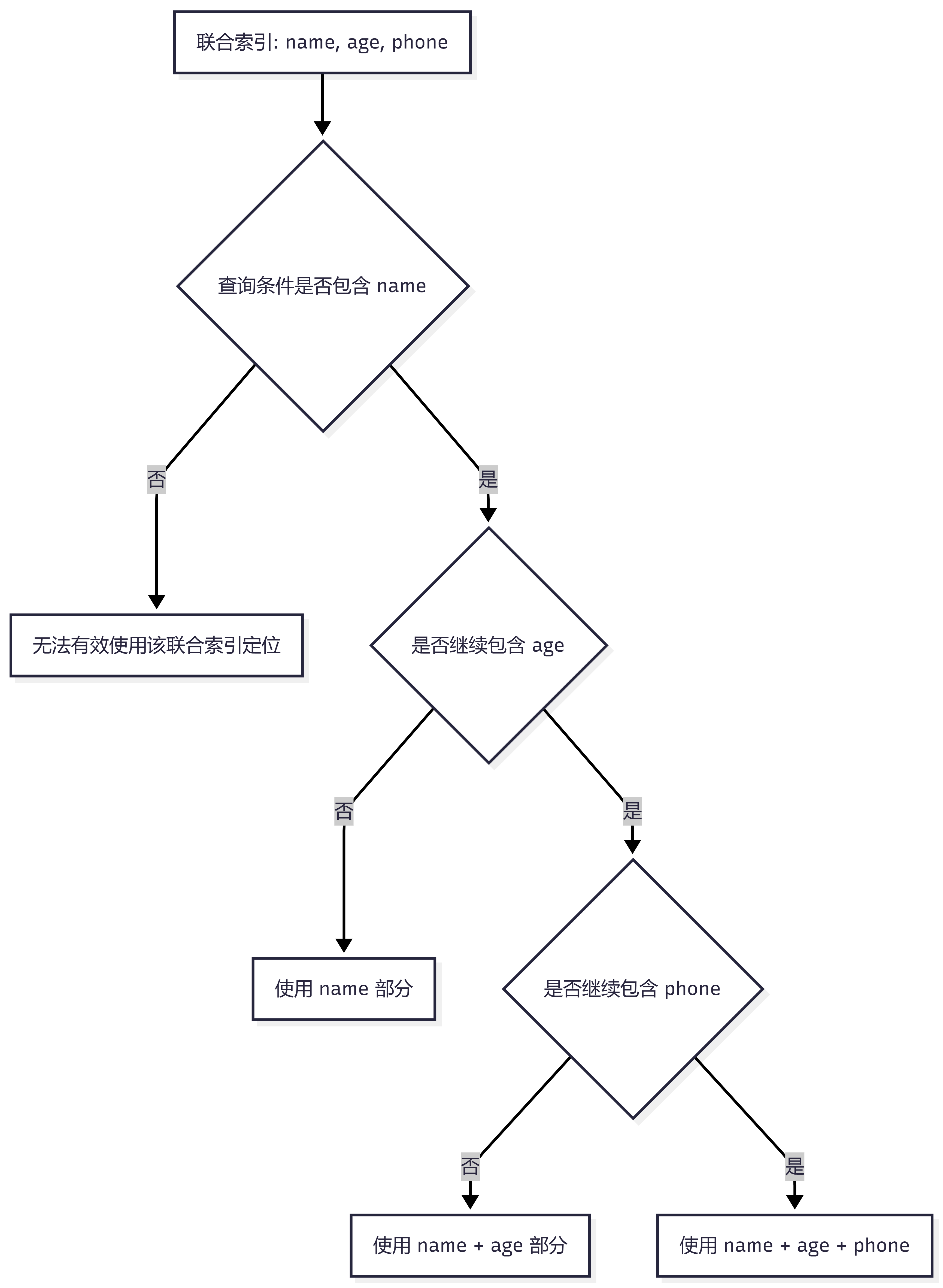
七、最左前缀原则
联合索引遵循一个很重要的规则:
最左前缀原则。
简单来说,使用联合索引时,要从索引最左边的字段开始连续匹配。
比如联合索引是:
(name, age, phone)
下面这些查询可以较好使用索引:
where name = 'Jack'
where name = 'Jack' and age = 18
where name = 'Jack' and age = 18 and phone = '13800000000'因为它们都是从最左边的 name 开始匹配。
但下面这个就不太行:
where age = 18
因为跳过了最左边的 name,联合索引无法直接按 age 定位。
可以用下面的流程理解:
八、范围查询会影响后续字段吗?
联合索引中还有一个常见细节:
如果某个字段使用了范围查询,后面的字段通常不能继续用于索引定位。
比如索引:
(name, age, phone)
SQL:
select * from user where name = 'Jack' and age > 18 and phone = '13800000000';这条 SQL 中:
- name = 'Jack' 可以使用索引
- age > 18 可以使用索引范围扫描
- phone = ... 一般不能继续用于索引定位
原因是索引先按 name 排,再按 age 排。
当 age 是一个范围时,后面的 phone 顺序就不再是一个可以直接连续定位的区间。
不过在 MySQL 5.6 之后,如果满足条件,phone 可能会通过索引下推在存储引擎层提前过滤,但这和继续用于完整索引定位不是同一回事。
九、联合索引字段顺序怎么设计?
联合索引不是字段越多越好,也不是随便排。
一般可以参考几个原则:
| 原则 | 说明 |
|---|---|
| 高频查询字段靠前 | 经常出现在查询条件中的字段优先 |
| 区分度高的字段靠前 | 过滤效果更好的字段适合放前面 |
| 等值查询字段放范围查询字段前面 | 避免范围查询影响后续字段 |
| 兼顾排序和分组 | 如果 SQL 有 order by、group by,也要考虑索引顺序 |
比如经常查询:
where user_id = ? and status = ? order by create_time desc可以考虑建立:
create index idx_user_status_time on order_info(user_id, status, create_time);这样既能过滤用户和状态,又有机会利用索引顺序减少排序成本。
十、覆盖索引和联合索引的关系
覆盖索引经常依赖联合索引来实现。
比如订单表:
create table order_info ( id bigint primary key, user_id bigint, status int, create_time datetime, amount decimal(10,2) );如果页面只需要展示订单状态、时间和金额:
select status, create_time, amount from order_info where user_id = 1001;可以建立联合索引:
create index idx_user_order on order_info(user_id, status, create_time, amount);这样查询条件里的 user_id,以及查询结果中的 status、create_time、amount 都在索引里,MySQL 可以直接从索引中返回数据。
这就是通过联合索引实现覆盖索引。
不过也不要为了覆盖所有查询,把索引建得特别长。
索引越多、越大,写入和维护成本也越高。
十一、如何减少回表?
减少回表是 SQL 优化中很常见的思路。
常见方式有:
| 方法 | 说明 |
|---|---|
| 避免 select * | 只查询真正需要的字段 |
| 使用覆盖索引 | 让查询字段都包含在索引中 |
| 优化联合索引顺序 | 提高索引过滤效率 |
| 控制返回数据量 | 配合分页、条件过滤,减少扫描和回表次数 |
| 用 EXPLAIN 分析 SQL | 看是否走索引、是否覆盖索引 |
比如:
select * from user where name = 'Jack';可以改成:
select id, name, age from user where name = 'Jack';再配合索引:
create index idx_name_age on user(name, age);因为 InnoDB 的二级索引叶子节点会保存主键值,所以 id、name、age 都可以从索引中拿到,这时就可能避免回表。
十二、用 EXPLAIN 看索引使用情况
实际开发中,不要只凭感觉判断 SQL 有没有走索引,最好用 EXPLAIN 看一下。
示例:
explain select name, age from user where name = 'Jack';重点关注几个字段:
| 字段 | 说明 |
|---|---|
| type | 访问类型,越接近 const 越好 |
| possible_keys | 可能使用的索引 |
| key | 实际使用的索引 |
| rows | 预估扫描行数 |
| Extra | 额外信息 |
如果看到:
Using index
说明可能使用了覆盖索引。
如果看到:
Using where
说明还需要在 Server 层继续过滤条件。
如果看到:
Using filesort
说明排序没有很好利用索引,可能需要优化。
十三、常见误区
1. 建了索引就一定会变快?
不一定。
如果表数据量很小,或者查询返回的数据太多,优化器可能认为全表扫描更划算。
2. 联合索引等于多个单列索引吗?
不是。
(name, age, phone) 是一个整体索引,不等于分别给 name、age、phone 建三个索引。
3. 最左前缀要求 SQL 条件顺序必须一致吗?
不一定。
比如联合索引是:
(name, age)
下面两种写法通常都可以:
where name = 'Jack' and age = 18
where age = 18 and name = 'Jack'
优化器会调整条件顺序。
最左前缀关注的是联合索引的字段顺序,不是 SQL 里条件书写的先后顺序。
4. 覆盖索引必须单独创建吗?
不用。
覆盖索引不是一种单独的索引类型,而是某条 SQL 查询的字段刚好被某个索引覆盖了。
5. 回表一定不好吗?
不是。
少量回表很正常,真正需要关注的是大量回表。
如果一条 SQL 回表几十万次,就可能成为性能瓶颈。
总结
MySQL 索引优化的核心,不是盲目多建索引,而是理解索引怎么工作。
简单总结一下:
| 概念 | 一句话理解 |
|---|---|
| B+ 树索引 | 多路平衡树,层级低,适合范围查询 |
| 聚簇索引 | 主键索引,叶子节点保存完整行数据 |
| 二级索引 | 普通索引,叶子节点保存索引值和主键值 |
| 回表 | 通过二级索引找到主键后,再去主键索引查整行数据 |
| 覆盖索引 | 查询字段都在索引中,不需要回表 |
| 联合索引 | 多个字段组成一个有序索引 |
| 最左前缀 | 联合索引要从最左字段开始连续匹配 |
真正写 SQL 的时候,可以多问自己几个问题:
- 这条 SQL 有没有走索引?
- 查询字段是否可以被索引覆盖?
- 是否存在大量回表?
- 联合索引字段顺序是否合理?
- EXPLAIN 的执行计划是否符合预期?
把这些问题想清楚,索引优化就不再只是“加个索引试试看”了。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)