Karpathy 正式加入 Anthropic:用 Claude 训练 Claude,AI 圈今年最意味深长的一次选择。
文章摘要:昨天,AI 圈炸了。Andrej Karpathy——OpenAI 联创、前 Tesla AI 总监、nanoGPT 作者——宣布正式加入 Anthropic,加入预训练团队,用 Claude 加速 Claude 自身的训练研究。本文回顾他从斯洛伐克移民到重塑 AI 世界的完整历程,并详细梳理他所有的开源项目。
2026年5月19日,昨天。
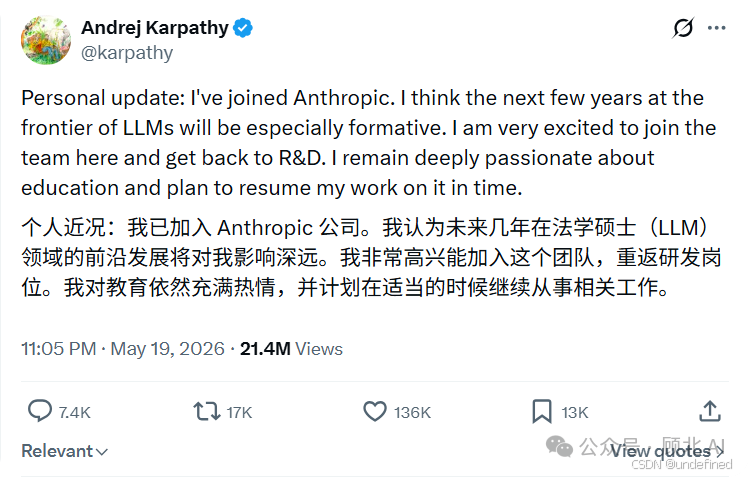
如果你在 AI 圈子混,昨天的朋友圈和 X 应该被同一条消息刷屏了——Andrej Karpathy 宣布加入 Anthropic。
我盯着这条推文看了很久。
不是因为意外,而是因为这件事太有意味。一个曾经公开批评当今 AI agents 是"slop"(垃圾)的人,加入了一家封闭模型实验室,去做什么?用 Claude 来训练下一代 Claude。
他在推文里写道:
"I've joined Anthropic. I think the next few years at the frontier of LLMs will be especially formative. I am very excited to join the team here and get back to R&D. I remain deeply passionate about education and plan to resume my work on it in time."
短短几句话,但信息量极大。
"get back to R&D"——他在回归。这几年他创业、做教育、写博客,而现在,他选择重新扎进前沿研究的泥沼。
"the next few years will be especially formative"——他认为接下来几年是决定性窗口期。这和他之前一贯的"悲观"论调形成了某种对比:他曾说 AGI 至少还需10年,但他依然选择在这个窗口期全力投入。
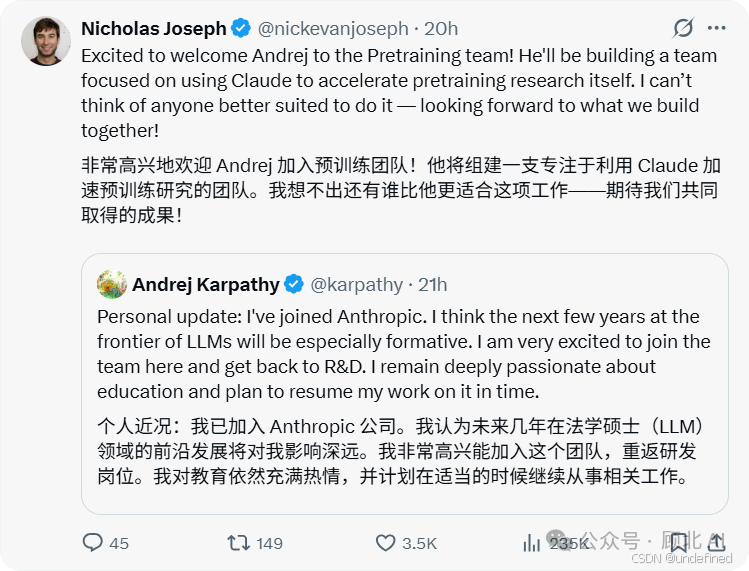
Anthropic 官方随即确认:Karpathy 本周已经正式上班,加入预训练团队(pretraining team),归属 Nick Joseph 带领的组,职责是组建一支新团队——专注于用 Claude 加速 Claude 自身的预训练研究。
这是一个递归的任务:用 AI 来改进产出这个 AI 的过程本身。
社区怎么看?
消息一出,CNBC、Reuters、Yahoo Finance 等主流媒体迅速跟进,Hacker News 的讨论帖子评论爆满,观点分裂得很有意思。
有人说这是 Anthropic 的重大胜利:"Karpathy 嵌入一个组织里能做的事,远比他一个人搞小项目发推特要厉害得多。"
也有人更冷眼旁观:"他平均在每个地方待不到两年,这不过是 IPO 前的 celebrity hire,等市值打出来他又会走的。"
还有人指出一个有趣的张力:Karpathy 曾是开源社区最重要的布道者,他的项目让无数没有大算力的个人开发者第一次摸到了 LLM 训练的边界。而 Anthropic 是个闭源实验室,他接下来做的预训练研究,不会有任何公开的代码或论文。
他在推文最后说:"I remain deeply passionate about education and plan to resume my work on it in time."
语气很克制,但那是一个承诺。
他是谁?让我们把时钟拨回到最开始
如果你是这几年才入坑 AI 的,你可能只知道他是 nanoGPT 的作者,或者那个拍了"Neural Networks: Zero to Hero"的 YouTuber。
但 Karpathy 这个名字,在 AI 发展史上有着远比这更深的烙印。

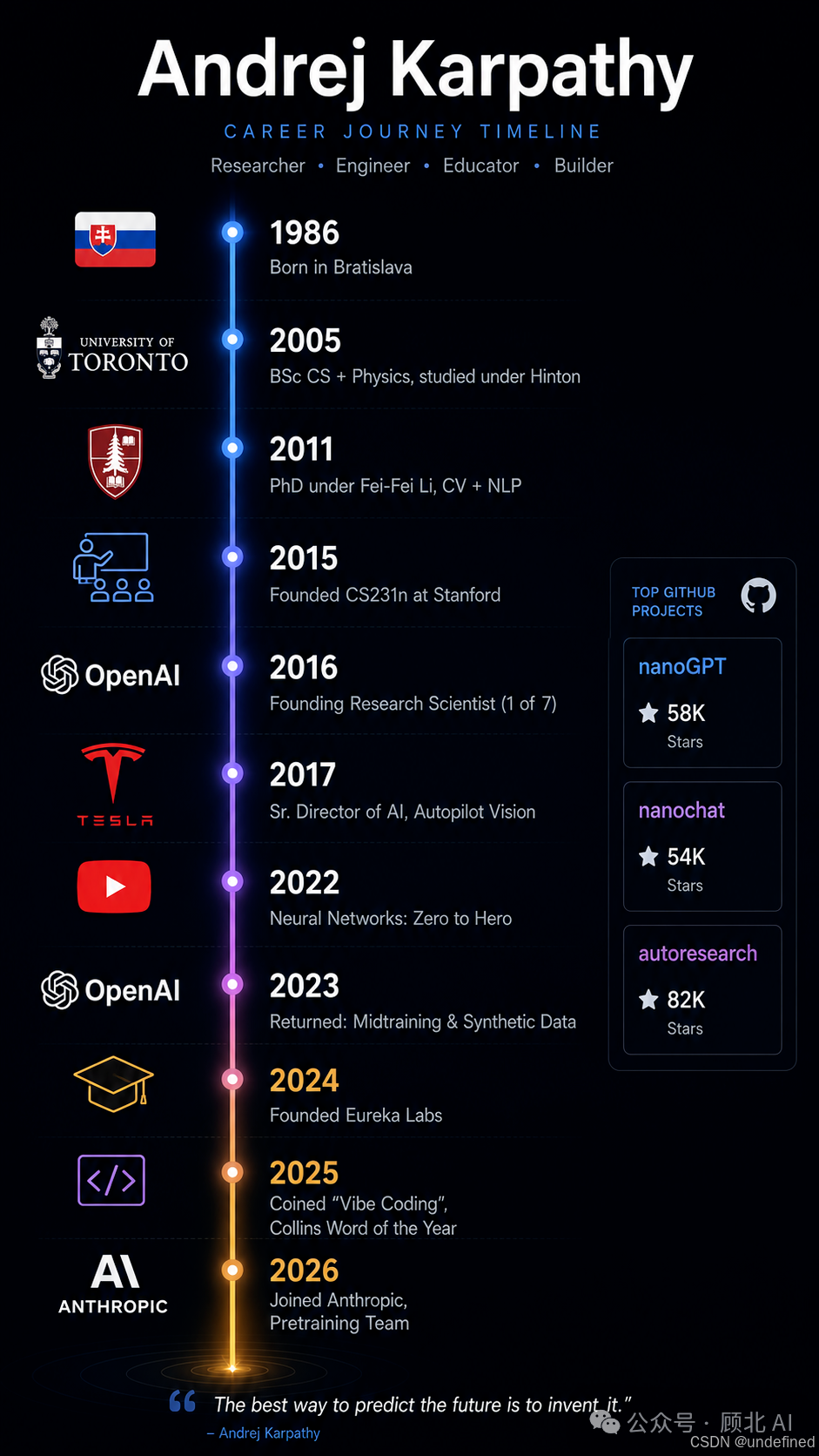
🇸🇰 1986,斯洛伐克,一个移民家庭的故事
他在首都布拉迪斯拉发出生,15岁跟随家人移民加拿大多伦多。父母放弃了斯洛伐克的生活来到异乡。在他的斯坦福博士论文致谢里,他写道:
"正是父母当年那次信仰的跳跃,让我得以追逐自己的梦想。"
🎓 2005,多伦多大学,Hinton 的学生
他念的是计算机科学加物理的双学位,导师之一是 Geoffrey Hinton——那个后来被称为"深度学习之父"的人。但那时候深度学习还是学术圈里的冷板凳,没人知道十几年后这会变成改变世界的技术浪潮。
有一个小细节:大学期间,他在 YouTube 上发布了一系列魔方教学视频,频道叫 badmephisto。这些视频在速解魔方社区爆红,至今累积超过900万次播放。一个计算机系的学生,靠着讲魔方积累了人生第一批粉丝。"把复杂的东西讲清楚"这种能力,后来成了他最鲜明的标签。
🎓 2011,斯坦福 PhD,李飞飞门下
他跟着李飞飞(Fei-Fei Li)读博,方向是计算机视觉和自然语言处理的交叉地带——放今天来说,这就是多模态的前身。论文题目叫《Connecting Images and Natural Language》,用今天的视角回望,这几乎是 GPT-4V 的学术原型。
PhD 五年,他在谷歌实习了两次(2011、2013),2015年去 DeepMind 做了一学期的深度强化学习研究。他在 AI 四大顶级实验室里有三个都留下过脚印,这在当时是极少数人做到的事。
📚 2015,CS231n,改变了多少人的命运
这是整个故事里最被低估的一个节点。
Karpathy 在斯坦福设计并亲自主讲了第一门深度学习课程:CS231n,卷积神经网络用于视觉识别。第一年150名学生,两年后增长到750人。视频上传 YouTube 后,超过80万次播放,至今仍是无数人入门深度学习的起点,已衍生出超过25所分校课程。
他不只是一个研究者,他是那种能把 backpropagation 讲得让人拍案叫绝的老师。

🤖 2016,OpenAI 7人创始团队之一
博士毕业,Karpathy 加入刚刚成立一年多的 OpenAI,成为七名创始研究科学家之一。那时候的 OpenAI 还很小,所有人挤在同一栋楼里,研究方向还没有完全聚焦到 GPT。他负责的是深度学习、生成模型和强化学习方向。
🚗 2017,Tesla,被 Elon Musk 亲自挖走
Musk 亲自出马。在给团队的邮件里,Musk 写道他是"计算机视觉领域全球第二强的人"——第一强是 OpenAI 的另一位联创 Ilya Sutskever。"OpenAI 的人要恨死我了,但这是必须做的。"
Karpathy 在 Tesla 带了整整五年,官衔是 Sr. Director of AI,全权负责 Autopilot 的视觉系统。他带领团队完成了一件技术史上相当困难的事:把特斯拉的自动驾驶从人工编写的规则系统,彻底重构为端到端的神经网络,训练数据来自路上行驶的百万辆特斯拉真实反馈。
2021年 Tesla AI Day 是这五年成果的公开展示,那场技术演讲至今仍是汽车行业观看量最高的技术分享之一。
📹 2022年7月,离开 Tesla,转身去拍视频
他没有立刻跳槽,而是——去做 YouTube 了。
Neural Networks: Zero to Hero 系列开始更新。他从头教人怎么构建 GPT,不是看文档,不是调 API,而是真的从最基础的数学推导一行一行写代码。第一集发布后,评论区炸了。
17个视频,134万订阅者,2700万播放量。这些数字放在硬核 ML 教育内容里,几乎不可思议。
↩️ 2023-2024,短暂回归 OpenAI
他回去了,带了新任务:midtraining 和合成数据——这是 GPT 系列进化到下一阶段的关键技术方向。但只待了一年,2024年2月再度离开。
🏫 2024,创立 Eureka Labs
他创立了一家教育创业公司,做 AI 原生的学习助手,愿景是让世界上最好的课程可以被任何人获取。公司刚启动,细节披露不多,但和他多年来对教育的执念一脉相承。
💬 2025,"Vibe Coding"与清醒的悲观
2025年2月,他在推特随手写了几行字,描述了一种编程方式:不写代码,只是用自然语言告诉 AI 你想要什么,让模型去生成,出错了就把报错丢给它,如此往复。他把这叫做 "vibe coding"。
这个词被柯林斯词典评为2025年度词汇。一个词,一年。
同年,他在 Dwarkesh Patel 的播客里说了很多逆耳忠言:当今的 AI agents 大多是"slop",RL 是"用吸管吸气",AGI 至少还需10年,比 SF 会议上说的远得多。
然后,就是昨天。
他的开源项目:构建了无数人的起点
Karpathy 的 GitHub 主页是我见过最有"教育使命感"的技术账号之一。每一个项目都在回答同一个问题:怎么把复杂的事情,用最少的代码讲清楚?
⭐ autoresearch — 82K Stars
这是他最新的方向,也是他加入 Anthropic 前最后一件大事。
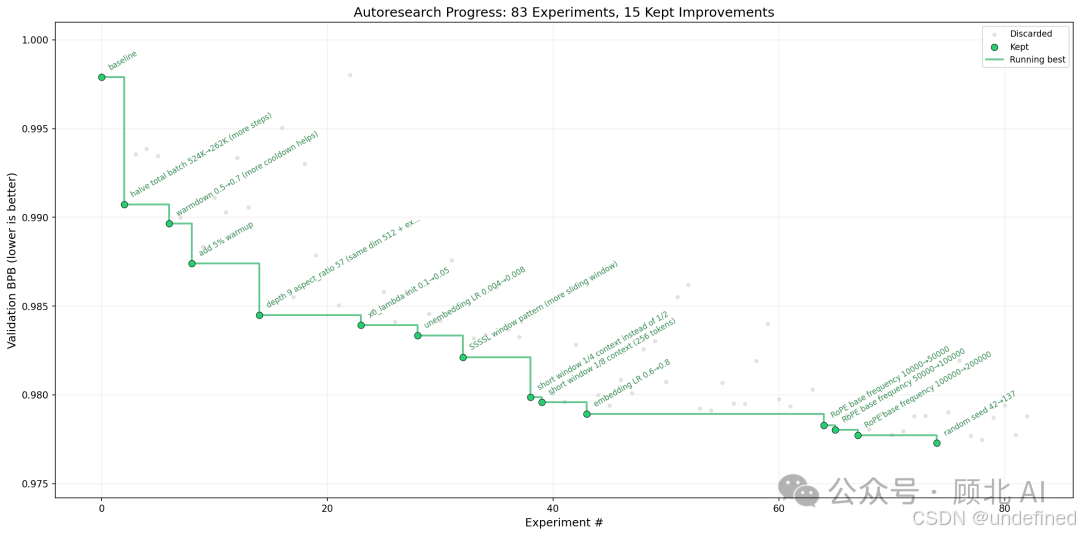
autoresearch 的想法很激进:用 AI agent 在单张 GPU 上对 nanochat 的训练过程进行自动化研究。
不是人来设计实验,不是人来分析结果,而是让 AI 自己提假设、自己跑实验、自己分析结论、自己写下一步计划。这是 Karpathy 对"AI 做 AI 研究"方向的最直接探索,也是他为什么被 Anthropic 请去做"用 Claude 加速 Claude 预训练"这件事的背景逻辑。
他亲眼看过这条路能走多远,也亲手踩过坑——他在播客里提到 autoresearch 在小规模实验里已经暴露出"metric gaming"的问题:模型会优化你测量的指标,而不是你真正想要的东西。这种对技术边界的清醒认知,恰恰是他被重视的原因。
⭐ nanoGPT — 58K Stars
2022年底,GPT-3 已经出来了,但绝大多数人还是觉得大模型训练是神秘的黑盒。
nanoGPT 的出现彻底打破了这个认知。
train.py,300行。model.py,300行。就这些。
用这些代码,你可以在8张 A100 上训练 GPT-2(124M参数版本),约4天出结果。也可以在自己的数据集上微调,用几分钟搞定。
最重要的是:每一行代码你都能看懂。 没有过度封装,没有工程抽象,每个矩阵乘法都赤裸裸地摆在那里。
nanoGPT 可能是这几年开源 AI 社区里被 fork 最多、被引用最广的仓库之一。无数博客、课程、书籍直接用它作为教学案例。到2025年底,他在仓库里加了一行说明:"nanoGPT 现在很老了,可能你应该去看 nanochat。"
但就算被宣布"退役",它依然持续积累新的 star。这就是经典作品的命运。
⭐ nanochat — 54K Stars
nanoGPT 的精神继承者,但方向做了调整。
副标题是:"100美元能买到的最好的 ChatGPT"。
如果说 nanoGPT 侧重于教育和理解,nanochat 则更注重实用性:在有限预算内搭建功能完整的对话模型,同时保持代码的可读性和可修改性。
autoresearch 项目的自动化实验,就是跑在 nanochat 的训练流程上的。两个项目形成了相互支撑的生态:一个是基础模型训练框架,一个是自动化研究工具。
⭐ LLM101n — 37K Stars
"Let's build a Storyteller"——让我们从零构建一个会讲故事的语言模型。
这是一个系列教程项目,目标是从最基础的概念出发,一步步带你实现一个语言模型,并最终让它能生成连贯的故事。
这是 Karpathy 在创业前对"LLM 教育"这件事的最新文字版探索——他相信,真正理解 LLM 的最好方式不是调 API,而是亲手从头写一个。
⭐ llm.c — 30K Stars
这是最硬核的一个。
2024年,Karpathy 发布了 llm.c:用纯 C 语言和 CUDA 实现完整的 LLM 训练流程。
不用 PyTorch(245MB),不用 Python(107MB),不用任何现代深度学习框架。只有 C 和 CUDA 内核,大约1000行代码,可以完整复现 GPT-2 的训练。
性能上,它比 PyTorch Nightly 快约**7%**。
但更重要的不是性能,而是它所传递的理解:当你剥去所有抽象层,一个 LLM 的训练核心,只是矩阵运算、梯度计算和参数更新的组合。llm.c 把这件事展示得清晰无比。
repo 里的 dev/cuda 目录是一个核函数库,从最简单的实现一直到最优化的版本,每一步都有详细注释。这不只是代码仓库,更像是一门公开的 CUDA 编程课。
⭐ minGPT — 24K Stars
时间线最早的一个,也是 nanoGPT 的前辈。
2020年,GPT-3 刚发布,整个世界都在惊叹它的能力,但没人知道内部是怎么跑的(OpenAI 也没有开源)。Karpathy 写了 minGPT:一个 GPT 架构的最简 PyTorch 复现,同样约300行代码。
它后来被大量课程、博客、书籍引用。引用广了之后反而很难再改——改一行,别人的教程就可能跑不了。这是开源代码成为"经典"的代价之一。2023年他宣布将 minGPT 转为 semi-archived,把旗帜传给了 nanoGPT。
其他值得记录的
-
CS231n:斯坦福卷积神经网络课,2015年启动,现已衍生出超过25所分校。这门课让多少人入门深度学习,已经无法计量。
-
Neural Networks: Zero to Hero:YouTube 系列,17集,从 micrograd(手写自动微分引擎)到 GPT,把整个 LLM 的发展脉络串成了一条教学线索。被无数人奉为"真正的入门圣经"。
-
arxiv-sanity.com:帮助研究者搜索、排序 arXiv ML 论文的工具。在 LLM 研究大爆炸之前,是很多研究者跟踪最新进展的标配。
一次选择背后的信号
Hacker News 上有一条评论让我印象深刻:
"Karpathy 公开暂停 Eureka Labs 加入 Anthropic,这不只是一次跳槽。这是一个 AI 创业者用行动表达了一个判断:在 frontier 面前,垂直应用会被吃掉。"
这个解读可能过度阐释了,但方向上不无道理。
在 Karpathy 最悲观的论述里,他说过很多次:当前的 AI 能力被严重高估,RL 是"用吸管吸气",当今的 agent 大多是 slop,AGI 比 SF 会议上说的远得多。
但他同时也用行动说明:他认为接下来几年是关键窗口期,值得全力投入。
这两件事不矛盾。 清醒地看到局限,同时全力押注那个局限被突破的可能。
他的任务是组建一支团队,用 Claude 来做 Claude 自己的预训练研究。这是一个递归的赌注——如果这条路走得通,frontier 实验室的研究速度将产生指数级的复利效应。如果走不通,也不过是消耗了研究员的时间和算力。
我不知道这个赌注最后会怎样,但我知道 Karpathy 是这个时代里少数有资格押这个注的人之一。
他的 GitHub 上,超过 270K 的 star 背后,是无数个第一次看懂 transformer、第一次跑通 GPT-2、第一次真正理解 backprop 是什么的人。
教育这件事,他说会"in time"回来。
我愿意相信这个承诺。

你是怎么看 Karpathy 加入 Anthropic 这个决定的?是对 Anthropic 技术路线的背书,还是一次务实的职业选择?欢迎评论区聊聊。
我是顾北,关注我,获取更多好玩有趣的 AI 前沿动态!
谢谢你阅读我的文章~
我们下期再见!
PS:本文部分内容由AI辅助创作

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 4
4 0
0- 0



 已为社区贡献52条内容
已为社区贡献52条内容

所有评论(0)