集成学习知识点讲解
·
集成学习知识点讲解
集成学习知识点讲解文档
知识导图(Plain Text)
集成学习
├─ 集成学习基础
│ ├─ 定义:多弱学习器组合成强学习器
│ ├─ 思想:弱者联盟,稳、准、抗过拟合
│ └─ 两类:Bagging、Boosting
├─ Bagging
│ ├─ 抽样:有放回随机抽样
│ ├─ 训练:并行、独立
│ └─ 输出:平权投票、多数表决
├─ Boosting
│ ├─ 训练:串行、关注前序错误
│ ├─ 权重:样本加权、学习器加权
│ └─ 输出:加权投票
├─ Bagging vs Boosting 对比
│ ├─ 采样方式
│ ├─ 并行/串行
│ └─ 投票机制
└─ 随机森林
├─ 基模型:CART决策树
├─ 双随机:样本随机 + 特征随机
├─ 构建步骤
├─ API与参数
└─ 案例:泰坦尼克号预测
核心名词解释
- 集成学习:组合多个弱学习器得到更精准、更稳定的强学习器。
- 弱学习器:效果一般、结构简单的基础模型。
- Bagging:并行式集成,有放回抽样,平权投票。
- Boosting:串行式集成,修正错误,加权投票。
- Bootstrap 抽样:有放回随机采样。
- 随机森林:Bagging + 决策树 + 双随机策略。
- 多数表决:Bagging 的预测方式,取票数最多结果。
- 加权投票:Boosting 的预测方式,按权重累加。
一、集成学习基础
1.1 什么是集成学习
集成学习通过组合多个弱学习器构建更强模型。
- 训练:依次训练多个弱模型
- 预测:所有弱学习器联合决策
- 优势:比单个模型更准、更稳、更不易过拟合
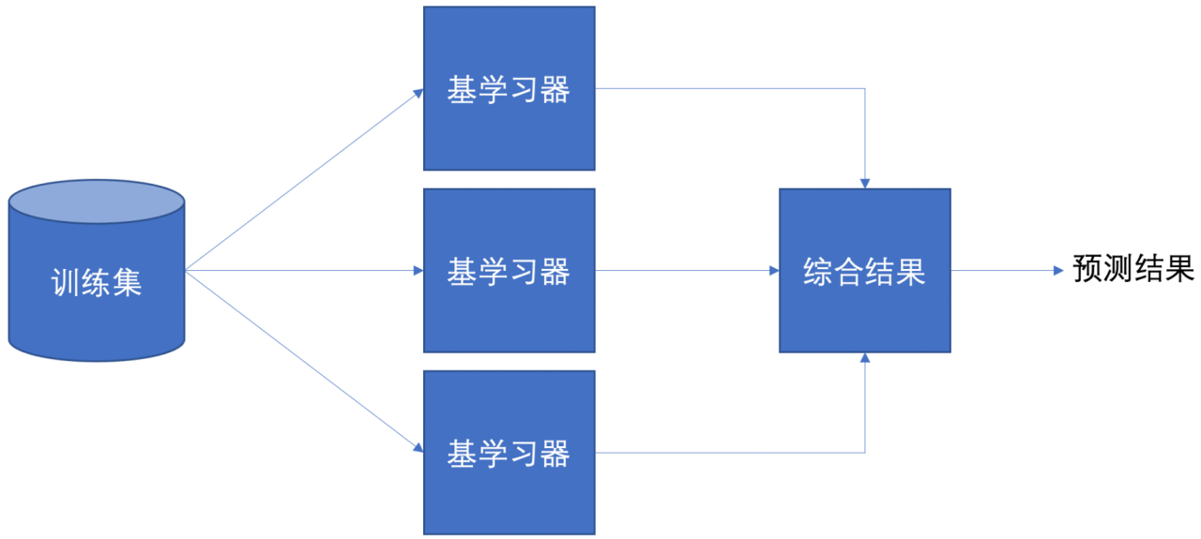
1.2 核心思想:弱者联盟
- 单个复杂模型 → 能力过强 → 容易过拟合
- 多个简单模型组合 → 能力变强、泛化更好
1.3 集成学习分类

- Bagging:随机森林
- Boosting:Adaboost、GBDT、XGBoost、LightGBM
二、Bagging 思想
2.1 Bagging 流程
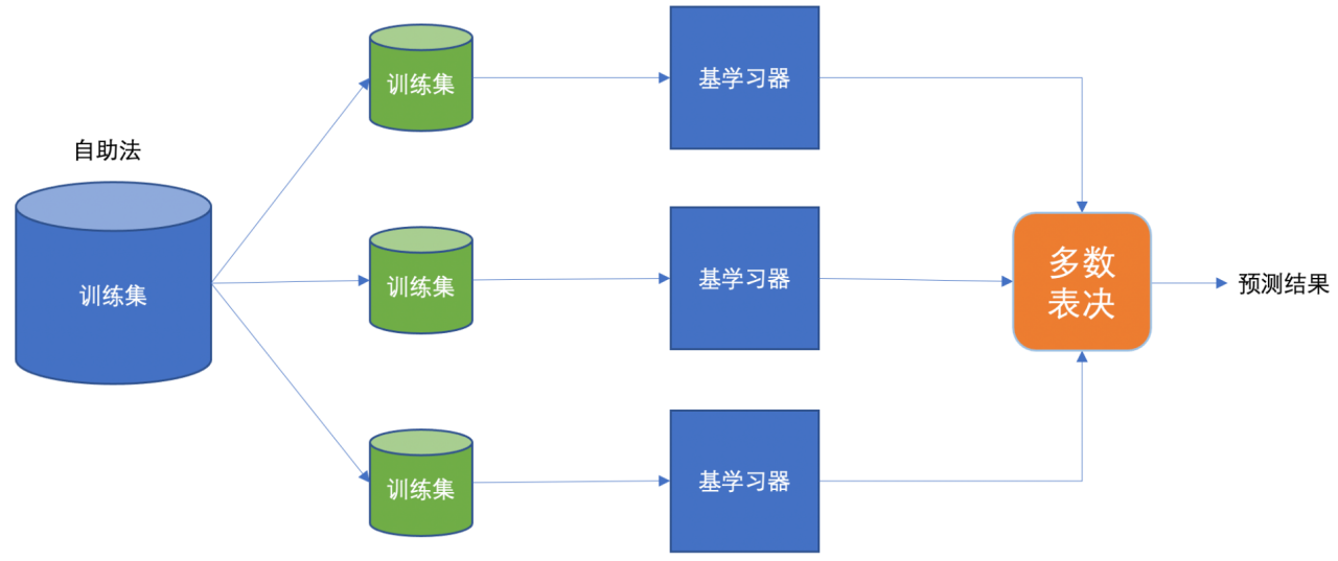
- 对训练集有放回随机抽样,生成多个训练集
- 并行训练多个独立学习器
- 平权投票、多数表决输出结果
2.2 Bagging 示例步骤
- 采样不同数据
- 训练分类器
- 平权投票得到最终结果
三、Boosting 思想
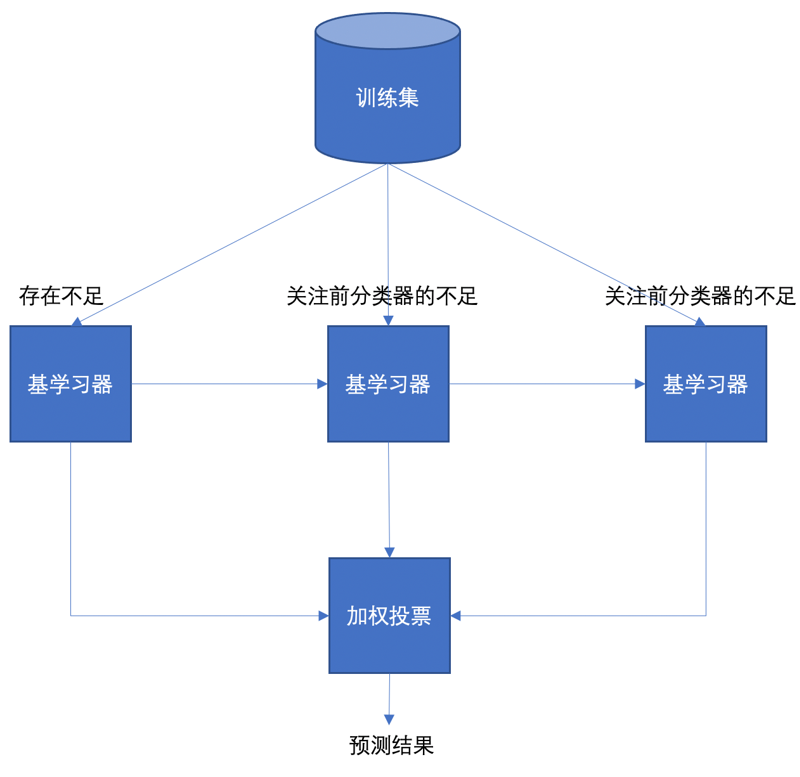
3.1 Boosting 流程
- 串行训练
- 每一个学习器重点纠正前一个的错误
- 加权投票得到最终结果
3.2 Boosting 举例
逐步变强、层层弥补不足
代表:Adaboost、GBDT、XGBoost、LightGBM
四、Bagging vs Boosting 对比
| 项目 | Bagging | Boosting |
|---|---|---|
| 数据采样 | 有放回随机抽样 | 全部样本,动态调整权重 |
| 训练方式 | 并行,无依赖 | 串行,有先后依赖 |
| 投票方式 | 平权投票,多数表决 | 学习器加权投票 |
4.1 本节总结
- 集成学习 = 多个弱模型组合
- Bagging:并行、有放回、平权投票
- Boosting:串行、纠错、加权投票
五、随机森林算法
5.1 随机森林定义
基于 Bagging + 决策树 的集成算法:
- 有放回抽样
- 随机选择部分特征
- 训练多棵 CART 树
- 平权投票输出结果
5.2 随机森林构建步骤
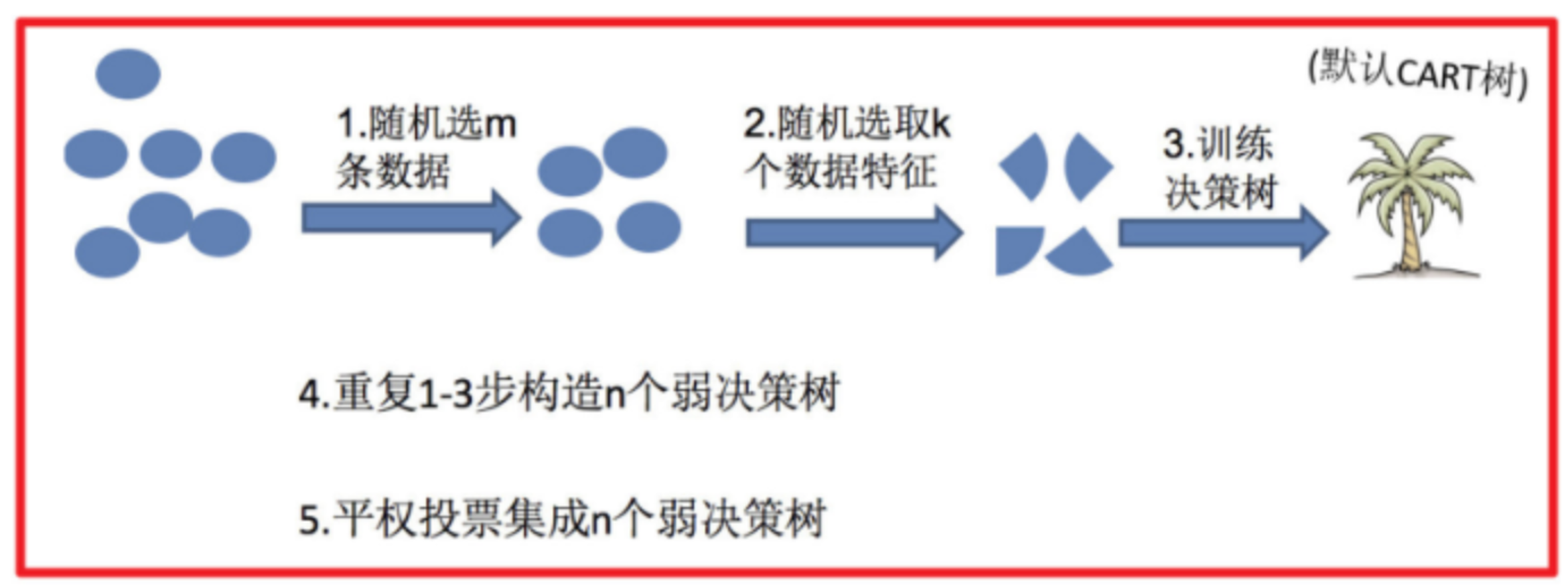
- 随机选 m 条样本(有放回)
- 随机选 k 个特征
- 训练一棵决策树
- 重复构建 n 棵树
- 投票输出
5.3 关键问题
- 为什么随机抽样?
不抽样 → 所有树完全一样,集成无意义。 - 为什么有放回?
使树之间既有差异又有重叠,投票更有效。
5.4 随机森林 API
from sklearn.ensemble import RandomForestClassifier
重要参数:


六、案例:泰坦尼克号生存预测
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV
def dm01_随机森林():
# 1 读取数据
titan = pd.read_csv("./data/titanic/train.csv")
# 2 特征与标签
x = titan[["Pclass", "Age", "Sex"]].copy()
y = titan["Survived"]
# 3 缺失值填充
x['Age'].fillna(titan["Age"].mean(), inplace=True)
# 4 One-Hot 编码
x = pd.get_dummies(x)
# 5 数据集划分
x_train, x_test, y_train, y_test = train_test_split(
x, y, random_state=22, test_size=0.2
)
# 6 单一决策树
dtc = DecisionTreeClassifier()
dtc.fit(x_train, y_train)
print('决策树准确率:', dtc.score(x_test, y_test))
# 7 随机森林
rfc = RandomForestClassifier(max_depth=6, random_state=9)
rfc.fit(x_train, y_train)
print('随机森林准确率:', rfc.score(x_test, y_test))
# 8 网格搜索调参
estimator = RandomForestClassifier(random_state=9)
param = {
"n_estimators": [40,50,60,70],
"max_depth": [2,4,6,8,10]
}
grid = GridSearchCV(estimator, param, cv=2)
grid.fit(x_train, y_train)
print('最优准确率:', grid.score(x_test, y_test))
print('最优模型:', grid.best_estimator_)
6.1 本节总结
- 随机森林 = Bagging + 决策树 + 双随机
- 步骤:抽样 → 选特征 → 建多棵树 → 投票
- API:RandomForestClassifier
- 效果明显优于单决策树
6.2 练习
答案:B → A → D → C
七、全章总结
- 集成学习:组合弱学习器,提升精度与稳定性
- Bagging:并行、有放回、投票(随机森林)
- Boosting:串行、纠错、加权(GBDT/XGBoost)
- 随机森林:双随机策略,抗过拟合、效果强
- 实战:泰坦尼克号预测,随机森林明显更优

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)