RAG实战:从零搭建企业知识库
导航
- 企业知识库已成为AI落地的最短路径
- 本文提供从环境搭建到生产部署的完整实战指南
传统大语言模型主要依赖参数中的隐式知识进行回答,容易受到知识过期、幻觉和领域知识不足等问题影响。RAG(检索增强生成)的核心思想是:在生成答案之前,先从外部知识库中检索相关信息,再将这些信息作为上下文提供给大语言模型,从而提升回答的准确性、可追溯性和时效性。
根据2026年企业AI应用调研数据显示,采用RAG架构的企业知识库项目,成功率比传统微调方案高出47%,而部署成本仅为后者的1/3。
实战准备与环境搭建
搭建企业级RAG知识库,第一步是选对工具链。很多团队卡在环境配置上,还没开始就结束了。
基础环境要求
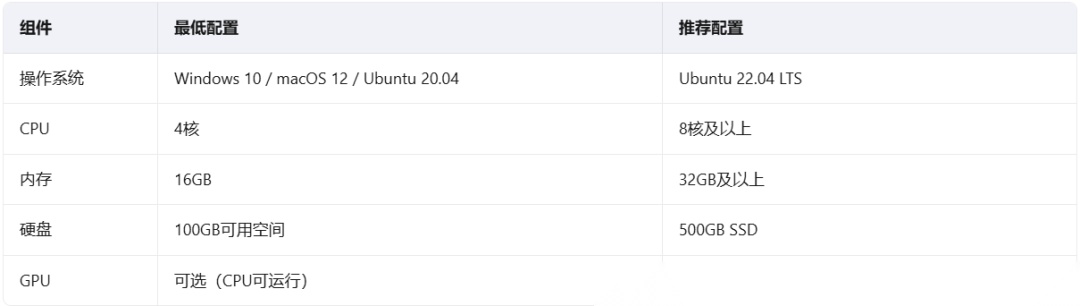
关键点:GPU不是必须的!很多轻量级部署(如FAISS + 小模型)在CPU上也能跑得很顺畅。
快速部署方案:Docker一键启动
对于企业用户,最稳妥的方式是容器化部署。以RAGFlow为例,官方提供了完整的Docker Compose配置,10分钟内可以完成环境搭建。
Step 1:安装Docker和Docker Compose
Windows用户推荐安装Docker Desktop,macOS和Linux用户直接命令行安装。
Step 2:克隆仓库并启动服务
关键点
:GPU不是必须的!很多轻量级部署(如FAISS + 小模型)在CPU上也能跑得很顺畅。
快速部署方案:Docker一键启动
对于企业用户,最稳妥的方式是
容器化部署
。以RAGFlow为例,官方提供了完整的Docker Compose配置,10分钟内可以完成环境搭建。
Step 1:安装Docker和Docker Compose
Windows用户推荐安装Docker Desktop,macOS和Linux用户直接命令行安装。
Step 2:克隆仓库并启动服务
执行后,Docker会自动拉取镜像并启动服务(包括Web前端、API后端、向量数据库等)。
Step 3:验证服务状态
docker-compose ps
当所有容器状态均为"Up"时,在浏览器中访问 http://你的服务器IP:9380 即可看到RAGFlow的Web管理界面。
注意:首次启动可能花费一些时间下载镜像,请耐心等待。
技术选型建议
企业级RAG系统的技术选型,直接决定了后续的可扩展性和维护成本。
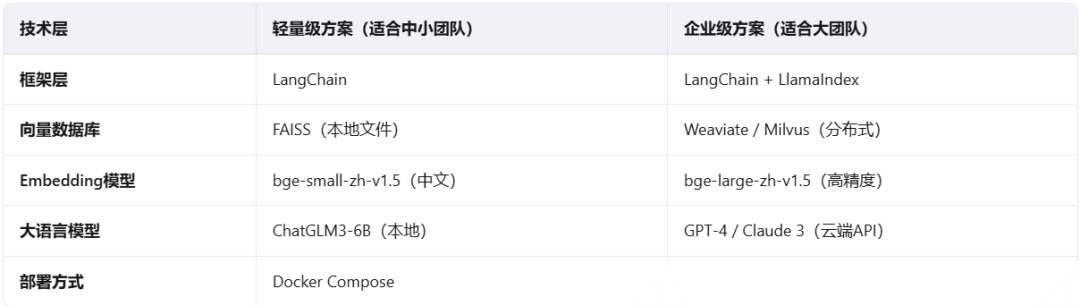
选型建议:
- 小团队(<10人):FAISS + ChatGLM3-6B + LangChain,成本低,部署简单
- 中型企业(10-100人):Weaviate + GPT-4 API + LangChain,兼顾性能和成本
- 大型企业(100人+):Milvus集群 + 多模型路由 + 微服务架构,高可用
数据准备与知识库构建
环境搭好了,接下来是最关键的一步:把你的企业文档变成RAG系统能理解的知识。
数据采集及格式转换
企业知识库的数据源通常很杂:Word、PDF、网页、数据库、内部Wiki…
常见问题:

格式转换实战:
对于PDF文档,推荐使用RAGFlow的内置解析器,它支持:
- 自动识别标题、段落、表格
- 保留文档结构(目录层级)
- 处理多栏排版
# 使用RAGFlow SDK上传文档示例
from
ragflow
import
RAGFlow
client = RAGFlow(api_key=
"your_api_key"
)
# 上传PDF文档
with
open
(
"企业手册.pdf"
,
"rb"
)
as
f:
dataset = client.create_dataset(name=
"企业知识库"
)
dataset.upload_document(file=f)
文本分块策略
文本分块(Chunking)是RAG系统中最容易被忽视,但影响最大的环节。
错误示例:固定512字符切分,可能把"违约责任"和"触发条件"拆到两个块里,导致检索时无法获取完整信息。
正确策略:
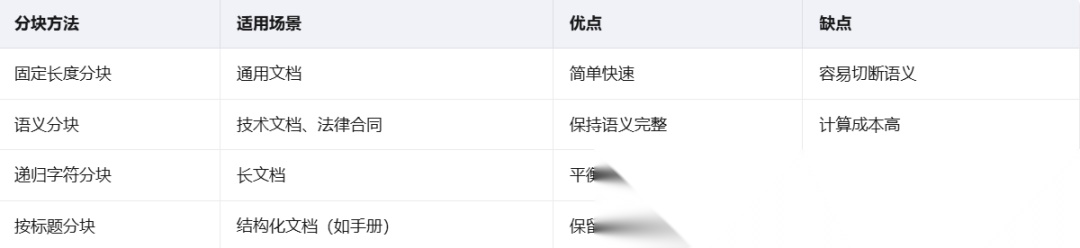
推荐配置:
- 块大小(chunk_size):512-1024字符
- 重叠大小(chunk_overlap):50-100字符
- 分块方法:递归字符分块(优先按段落,其次按句子)
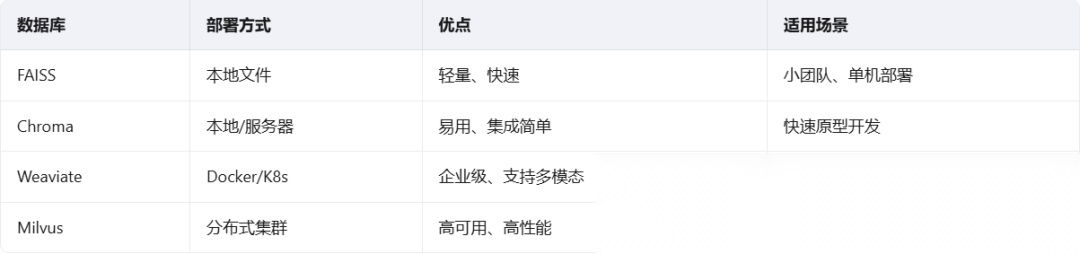
向量化与存储
文本分块完成后,需要将其转换为向量表示,并存储到向量数据库中。
Embedding模型选择:
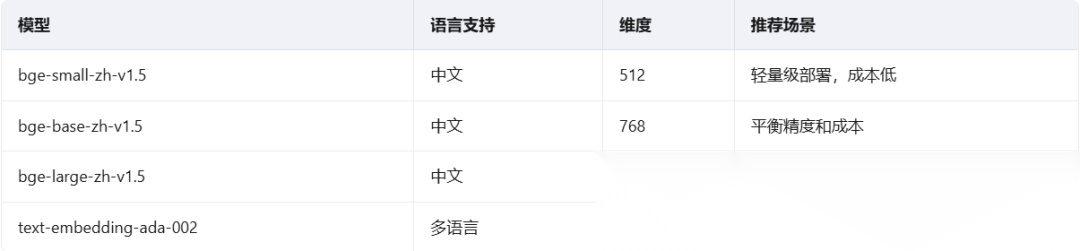
:
(使用LangChain + FAISS):
from
langchain_community.vectorstores
import
FAISS
from
langchain_community.embeddings
import
HuggingFaceEmbeddings
# 加载Embedding模型
embeddings = HuggingFaceEmbeddings(model_name=
"BAAI/bge-small-zh-v1.5"
)
# 构建向量库
vectorstore = FAISS.from_documents(documents=splits, embedding=embeddings)
# 保存到本地
vectorstore.save_local(
"knowledge_base"
)
RAG系统核心模块
知识库构建完成后,需要搭建检索和生成模块,形成完整的RAG流水线。
检索器配置
检索器的质量直接决定了RAG系统的上限。
检索器类型对比:

推荐配置:混合检索(BM25 + 向量检索),用Reranker重排序。
重排序优化
检索器召回的Top-K文档中,真正相关的可能排在后面,这就是"Lost in the Middle"现象——LLM倾向于关注上下文的头部和尾部,中间的信息容易被忽略。
解决方案:使用Reranker模型对检索结果重新排序。

实战代码:
from
langchain_community.document_compressors
import
HuggingFaceCrossEncoder
# 加载Reranker模型
reranker = HuggingFaceCrossEncoder(model_name=
"BAAI/bge-reranker-v2-m3"
)
# 对检索结果重排序
reranked_docs = reranker.compress_documents(documents=retrieved_docs, query=query)
Prompt工程
Prompt是连接检索器和生成器的桥梁,设计好坏直接影响答案质量。
基础Prompt模板:
根据以下已知信息,简洁、准确地回答用户的问题。
如果已知信息不足以回答问题,请回答"我无法从已知信息中找到答案"。
请不要编造答案。
已知信息:
{context}
用户问题:
{question}
答案:
进阶技巧:
-
要求引用来源
:在Prompt中要求模型标注答案来源(如"根据文档第3页…"),提升可追溯性
-
禁止编造
:明确要求模型不要编造信息,减少幻觉
-
格式化输出
:要求模型按指定格式输出(如JSON、Markdown表格)
系统评估与优化
RAG系统上线前,必须建立评估体系,否则就是"盲人骑瞎马"。
检索质量评估
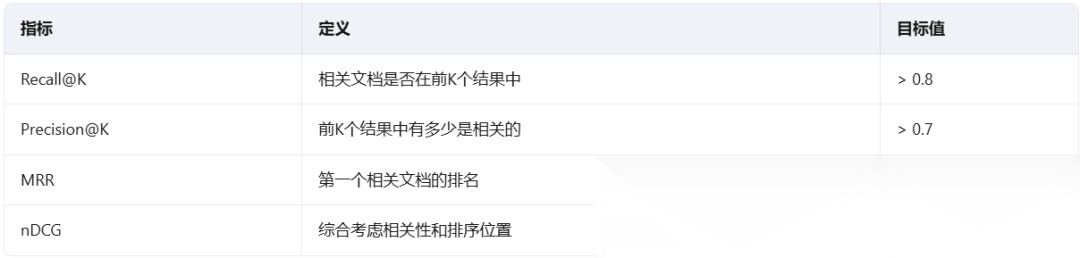
评估工具:可以使用RAGAS、LangSmith等工具自动化评估。
生成质量评估
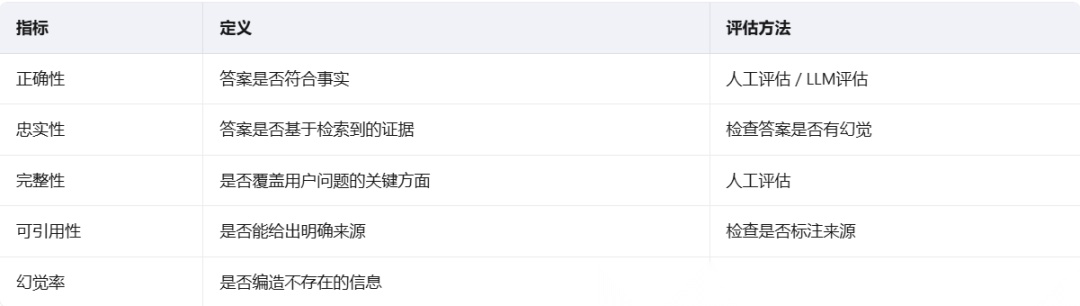
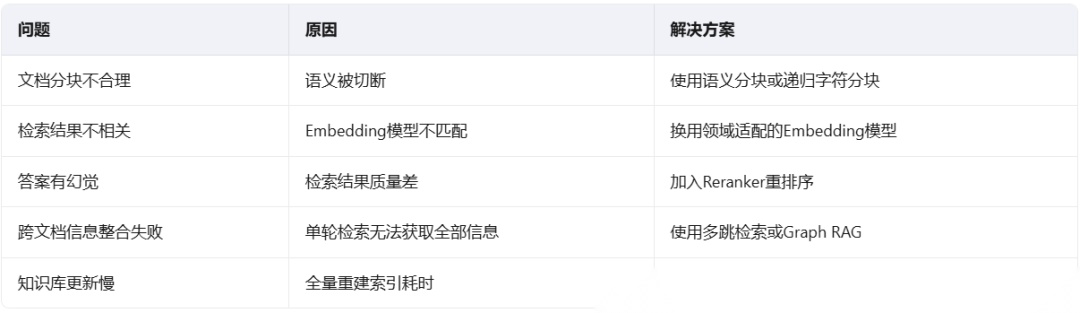
常见问题与解决方案
根据企业RAG挑战赛(Enterprise RAG Challenge)的实战数据,以下是最高频的问题及解决方案:
生产环境部署
原型跑通后,如何部署到生产环境?这是很多企业卡住的地方。
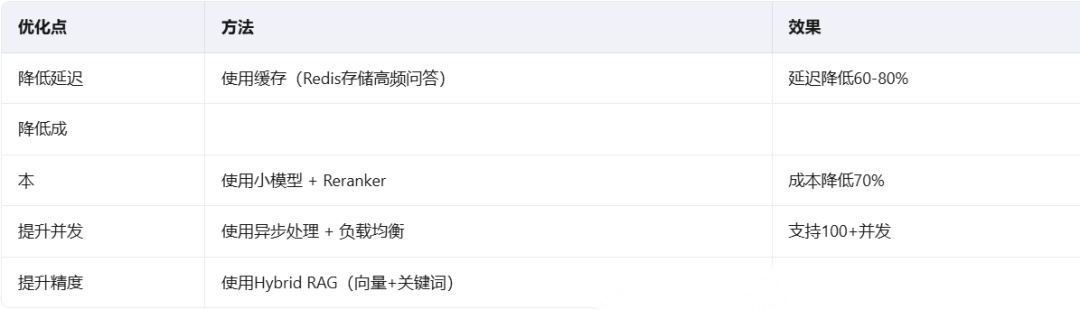
性能优化
安全与权限控制
企业知识库必须做权限控制,否则就是数据泄露隐患。
权限控制层级:

实战建议:使用元数据(Metadata)标记每个Chunk的权限级别,检索时根据用户的角色过滤。
监控与维护
RAG系统上线后,需要持续监控和维护。
监控指标:
- 检索质量指标(Recall@K、Precision@K)
- 生成质量指标(忠实性、幻觉率)
- 系统性能指标(延迟、QPS、错误率)
- 业务指标(用户满意度、问答准确率)
维护任务:
- 定期更新知识库(增量Embedding)
- 定期评估检索和生成质量
- 根据用户反馈优化Prompt和分块策略
写在最后
从零搭建企业级RAG知识库,看起来复杂,但其实拆解开来就是环境搭建 → 数据准备 → 核心模块开发 → 评估优化 → 生产部署这五个步骤。
2026年,RAG已经成为企业AI落地的主流架构。根据最新调研,83%的企业计划在未来12个月内部署或扩展RAG系统。
但技术只是工具,真正的挑战在于:
- 你的企业文档是否准备好了?
- 你的业务流程是否需要AI辅助?
- 你的团队是否具备运维能力?
想清楚这三个问题,再开始搭建,成功率会高很多。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献187条内容
已为社区贡献187条内容

所有评论(0)