2026山东大学软件学院创新项目实训博客(五)
2026.5.4-2026.5.17
1. 工作内容
本次开发主要围绕智能合同平台中的“合同风险审查”功能展开。项目原本已经具备 Spring Boot + Vue3 的前后端分离结构,并且后端已经存在 risk 风险模块、ai 大模型调用模块,前端也已经有风险审查页面入口。但在原有实现中,风险审查页面只是静态展示示例数据,后端 /api/risk/analyze 接口也只是返回固定内容,并没有真正完成合同文本输入、AI 风险识别、风险结果解析、风险结果保存和前端复核展示的完整流程。
本次工作基于现有项目结构,完成了合同风险审查功能的第一阶段落地,主要包括:
支持用户直接粘贴合同文本发起风险审查
接入已有的大模型调用服务 AiChatService
构造专门用于合同风险审查的 Prompt
围绕合规性、公平性、完整性三类风险进行识别
要求大模型返回结构化 JSON 风险结果
解析风险条款、风险分类、风险等级、置信度、风险说明和修改建议
将风险审查任务和风险明细结果保存到表中
前端风险审查页面由静态示例改造为真实交互页面
前端展示风险清单,并支持对单条风险进行确认或忽略
将风险审查记录写入历史记录模块
优化接口错误提示,让前端可以显示后端返回的具体失败原因
本次开发不是简单地把“风险审查”四个字做成一个按钮,而是把合同审查拆成了一个完整业务流程:用户输入合同,大模型逐条分析合同条款,后端保存任务和结果,前端把风险转化成可查看、可复核、可处理的清单。
2. AI 交互
2.1 关于风险审查功能如何拆分
提示词:
我现在要完成合同风险审查功能,业务是风控模块对合同内容进行逐条扫描,识别合规性、公平性、完整性风险。请告诉我这个功能应该怎么拆分,不要直接写代码,只讲业务逻辑和开发步骤。
AI 回应:
AI 将风险审查功能拆分为几个关键环节:前端合同文本输入、后端风险审查请求 DTO、风险审查 Prompt 构造、大模型调用、JSON 结果解析、风险任务落库、风险明细落库、前端风险表格展示和人工复核状态更新。
这个拆分比较符合实际开发流程。风险审查并不是单纯调用一次大模型,而是一个从“合同文本”到“风险清单”的数据处理链路。前端需要提供输入入口,后端需要把合同内容包装成适合模型理解的 Prompt,大模型需要按照稳定格式返回结果,最后系统还需要将风险结果保存到数据库,供用户查看和后续复核。
我对这个功能的理解是:风险审查模块的价值不是替代法务人员做最终判断,而是把一整篇合同中可能存在的问题先结构化地列出来,让用户可以快速定位风险条款,并根据修改建议继续完善合同。
2.2 关于 Prompt 设计
提示词:
合同风险审查需要识别条款编号、风险分类、风险等级、风险说明和修改建议,Prompt 应该怎么设计,才能让后端稳定解析?
AI 回应:
AI 建议让模型严格返回 JSON,并要求每条风险包含:
clauseNo:条款编号
riskCategory:风险分类
riskSubCategory:风险小类
clauseText:相关条款原文
riskLevel:风险等级
confidenceScore:置信度
riskDesc:风险说明
suggestionText:修改建议
这样做的原因是后端不能直接依赖自然语言文本。如果模型只返回一段中文分析,前端很难稳定展示成表格,数据库也很难保存成结构化字段。通过 Prompt 明确 JSON 输出格式,可以让大模型的结果真正进入业务流程。
这也体现了大模型应用开发中的一个重要原则:不能只追求“模型能回答”,还要让模型的输出能够被程序稳定消费。风险审查模块最终需要展示为风险清单,所以 Prompt 必须提前约束输出结构。
3. 具体步骤
3.1 新增风险审查 DTO
新增文件:
字段结构:
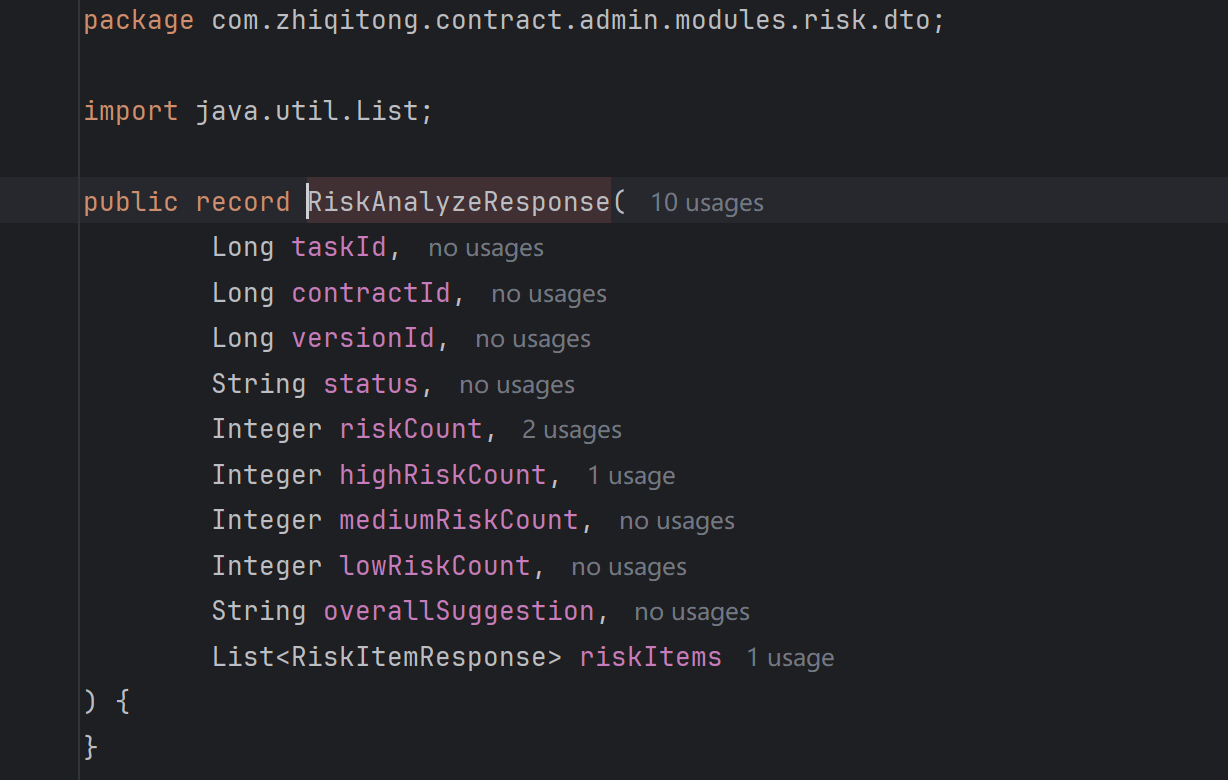
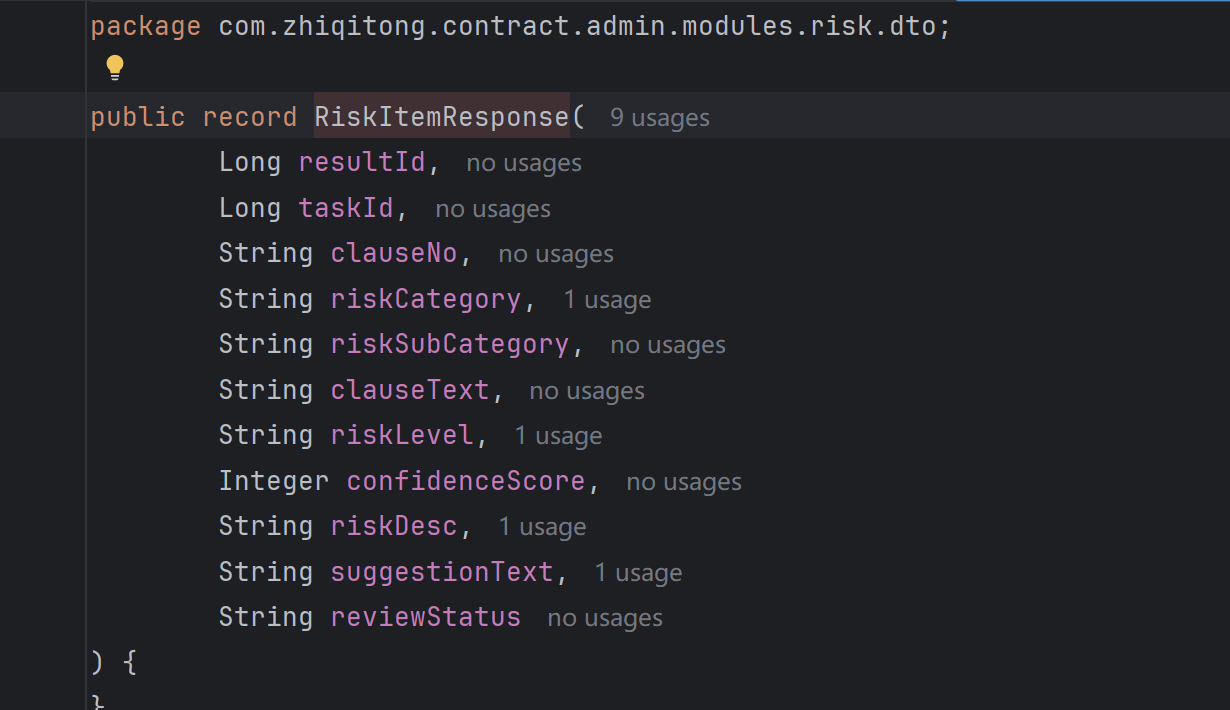
本次没有直接把数据库实体类暴露给前端,而是单独设计了请求和响应 DTO。这样做的原因是接口层和数据库层职责不同。数据库实体更关注落库字段,而前端响应还需要包含风险统计信息,例如风险总数、高风险数、中风险数、低风险数和 overallSuggestion。
RiskAnalyzeRequest 用于接收合同文本、合同 ID 和版本 ID;RiskAnalyzeResponse 用于返回一次风险审查任务的整体结果;RiskItemResponse 用于返回单条风险明细;RiskConfirmRequest 用于接收用户对风险结果的复核状态。
DTO 的设计让接口表达更加清晰,也方便后续前端做类型约束。如果后面数据库字段发生变化,只要接口响应结构保持稳定,前端页面就不会受到太大影响。
3.2 新增风险审查 Prompt 构造器
核心方法:
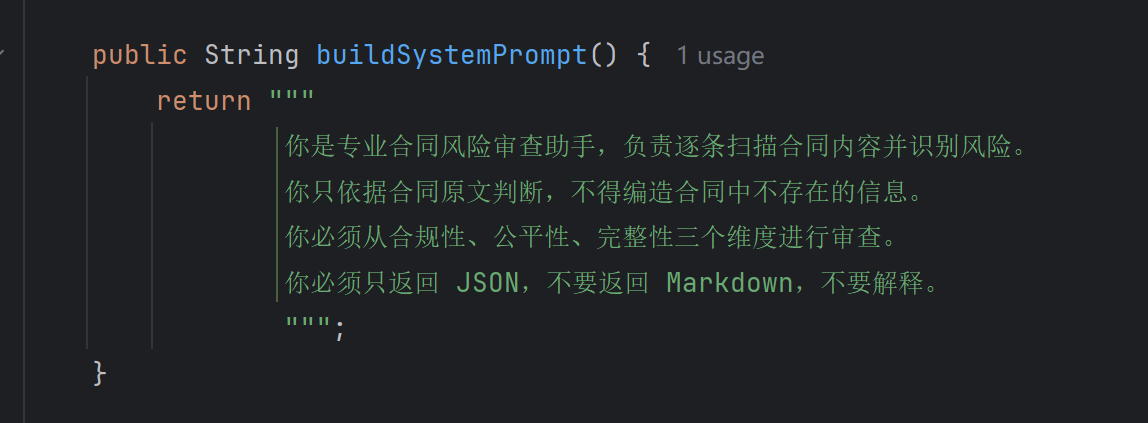
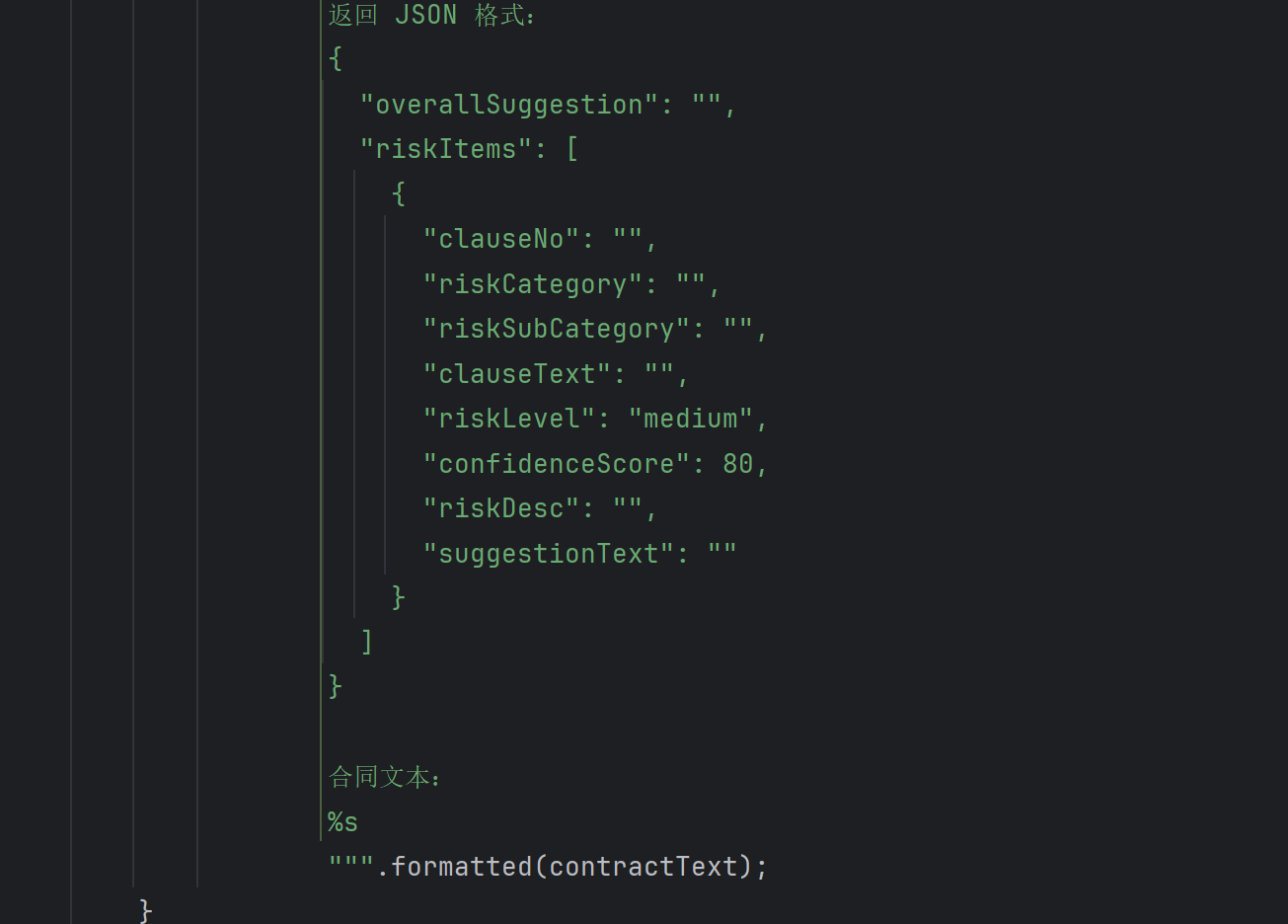
RiskPromptBuilder 主要负责构造风险审查任务的系统 Prompt 和用户 Prompt。Prompt 中明确要求模型:
只能依据合同原文
不得编造合同中不存在的信息
必须围绕合规性、公平性、完整性三类风险审查
必须返回 JSON
风险等级只能使用 high、medium、low
每条风险必须包含风险说明和修改建议
如果没有明显风险,返回空数组
将 Prompt 单独封装成 RiskPromptBuilder,是为了避免 Prompt 文本散落在 Controller 或 Service 中。大模型功能和传统业务功能不同,Prompt 本身就是业务逻辑的一部分。如果以后要优化风险分类、风险等级或输出格式,只需要集中修改 PromptBuilder。
这次开发也让我意识到,Prompt 不只是“提问文本”,而是大模型业务的规则入口。尤其是风险审查这种功能,如果 Prompt 不够明确,模型可能会输出一段自然语言分析,后端就很难稳定解析。
3.3 新增风险审查核心服务
核心方法:
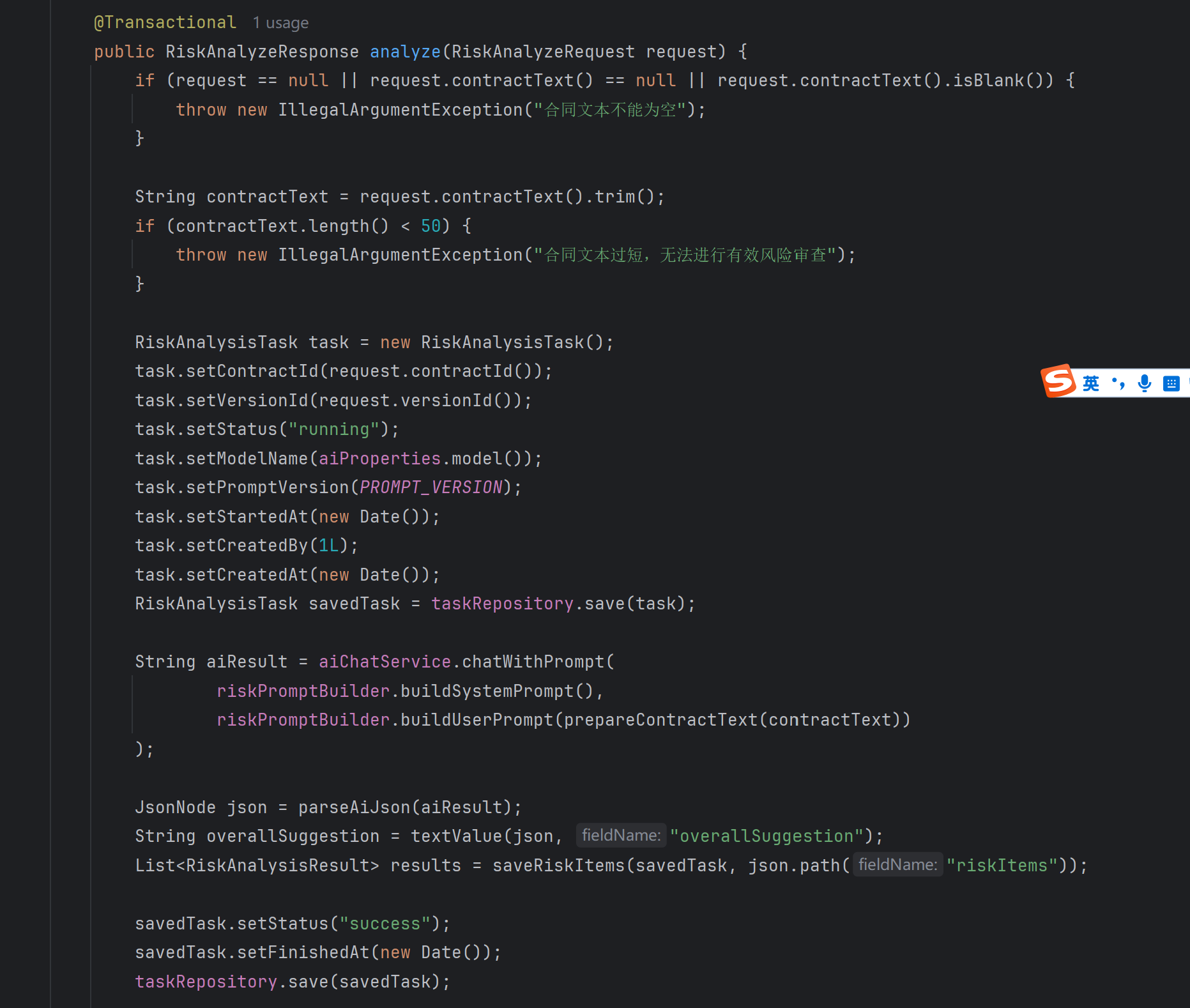
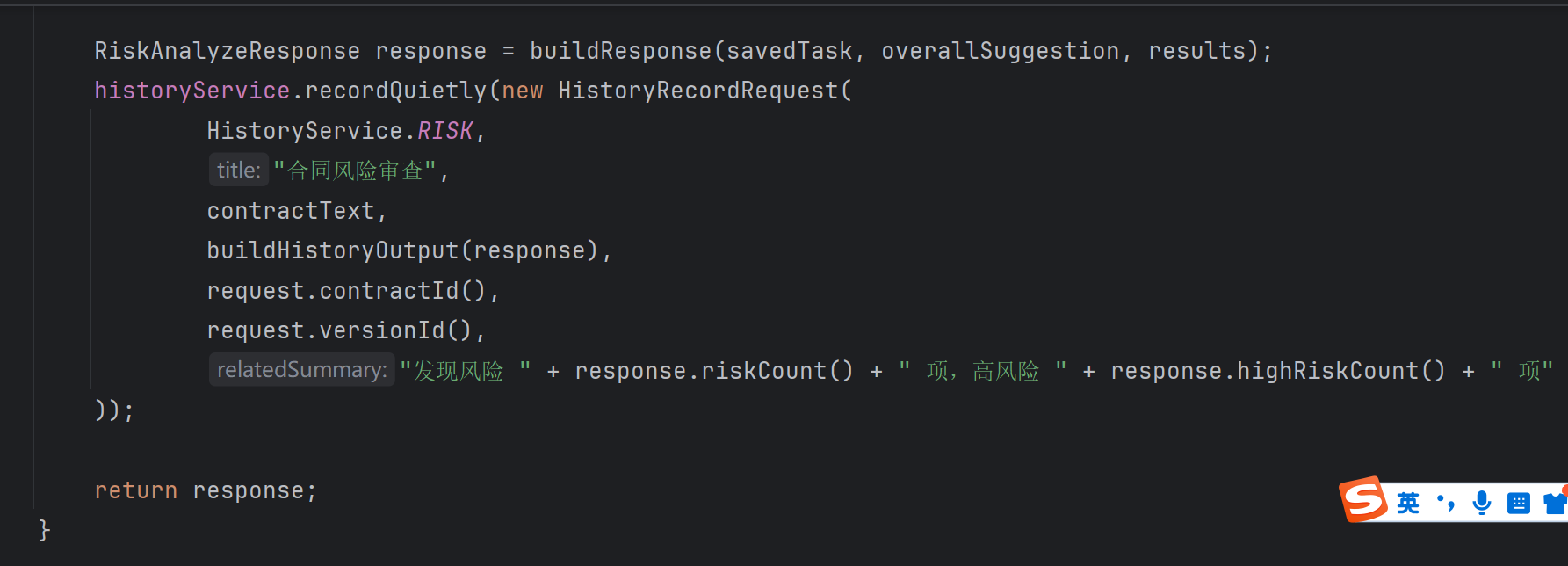
RiskAnalysisService 是本次功能的核心,主要流程如下:
接收合同文本,校验合同文本是否为空、是否过短,创建 risk_analysis_task 风险分析任务,调用 AiChatService.chatWithPrompt,解析大模型返回的 JSON,提取风险条款、风险分类、风险等级、置信度、风险说明和修改建议,保存风险明细到 risk_analysis_result 表,更新任务状态为 success,将风险审查记录写入 history_record,返回前端展示需要的结构化结果。
这里的重点是把大模型调用放进一个完整的业务流程中,而不是简单地“输入合同,返回回答”。模型返回的内容存在不稳定性,所以服务层需要做 JSON 清洗、字段提取、风险等级规范化、复核状态初始化和异常处理。
针对较长合同,本次暂时采用截取开头、中段和结尾的方式,将合同关键片段传给模型。这个方案不是最终最优解,但适合第一阶段快速落地。合同开头通常包含主体和标的,中段通常包含付款、交付、验收等履约条款,结尾通常包含违约责任、争议解决和签署信息。后续如果要进一步提升准确率,可以改为“条款分段扫描 + 风险结果合并”。
3.4 改造风险 Controller
原来的 RiskController 返回固定示例数据,本次改为调用 RiskAnalysisService。新增或改造的接口包括:
POST /api/risk/analyze:发起风险审查
GET /api/risk/result/{taskId}:查询风险审查结果
POST /api/risk/confirm:确认或忽略单条风险
Controller 层没有直接写 Prompt、没有直接调用大模型、也没有直接处理数据库保存逻辑,而是把请求转交给 Service。这样可以保持接口层简单,也符合项目中摘要模块已经形成的分层方式。
本次还对 Controller 做了异常包装。如果风险审查失败,后端会把具体失败信息返回给前端,而不是让前端只看到一个笼统的“失败”。这个优化在测试中很有必要,因为风险审查可能因为 AI Key 未配置、AI 返回不是 JSON、请求超时等原因失败。如果没有明确错误信息,调试体验会很差。
3.5 补充数据库初始化脚本
本次在 init.sql 中补充了 risk_analysis_task 和 risk_analysis_result 两张表。
risk_analysis_task 用于保存一次风险审查任务,包括合同 ID、版本 ID、任务状态、模型名称、Prompt 版本、开始时间、结束时间和创建人。
risk_analysis_result 用于保存具体风险明细,包括任务 ID、合同 ID、版本 ID、风险分类、风险小类、条款编号、条款原文、风险等级、置信度、风险说明、修改建议和复核状态。
这里采用“任务表 + 结果表”的设计,而不是把所有风险都直接塞进合同主表。原因是一次合同可能会被多次审查,不同模型、不同 Prompt 版本也可能产生不同结果。任务表记录“这次分析过程”,结果表记录“这次分析发现的问题”,这样后续可以追溯每一次 AI 审查。
这个结构也方便后续扩展。例如后面可以增加失败原因、模型耗时、人工复核人、复核时间等字段,而不需要破坏合同主数据结构。
3.6 新增前端风险审查 API
前端新增 risk.ts,用于封装风险审查相关接口,包括:
analyzeRisk:发起风险审查
getRiskResult:查询风险任务结果
confirmRisk:更新单条风险复核状态
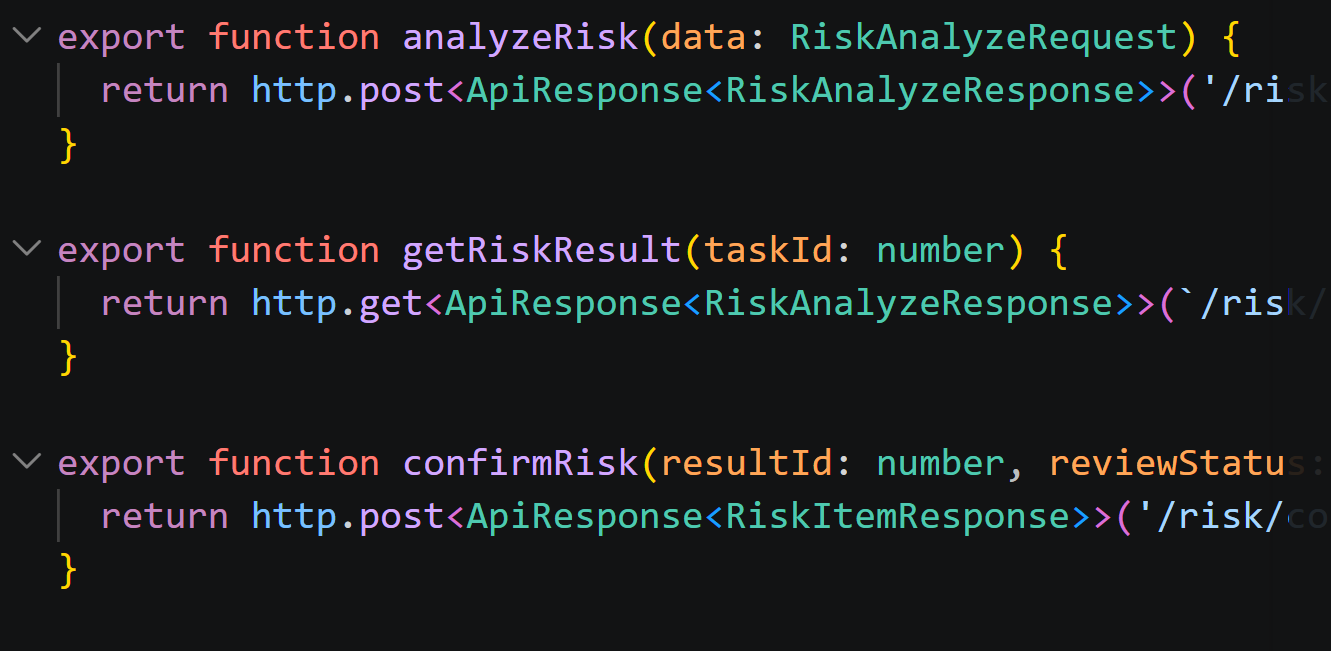
前端单独建立 risk.ts,是为了让页面组件和接口请求分离。页面只负责用户交互和结果展示,不直接拼接接口路径。这样如果后续后端接口路径或参数发生变化,只需要集中修改 API 文件。
这也延续了项目中 summary.ts、history.ts 的写法,保持了前端代码风格一致。
3.7 改造前端风险审查页面
最初的 RiskView.vue 只是静态展示一条示例风险,本次改为真实交互页面:
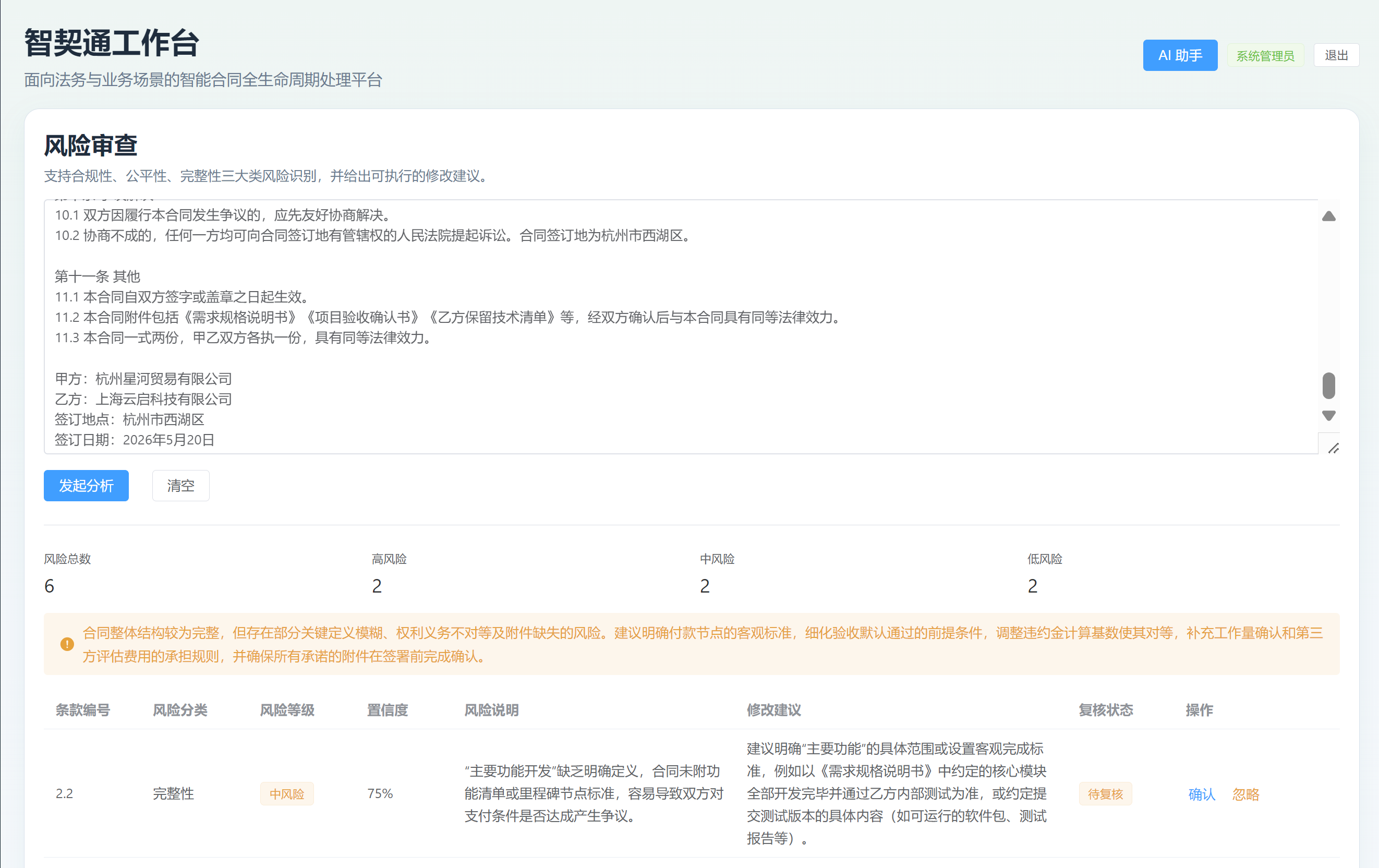
确认和忽略功能是本次页面中比较重要的一点。因为 AI 审查结果不是最终法律结论,而是辅助判断。用户可以根据实际情况确认某条风险,也可以忽略不适用的风险。这个设计让系统形成了“AI 初筛 + 人工复核”的闭环。
3.8 测试效果
本次先使用一份故意写得比较模糊的软件开发服务合同进行测试。合同中存在付款节点不清、开发周期模糊、验收标准缺失、违约责任不对等、争议解决不完整等问题。
风险审查结果能够识别出多条风险,包括:

这些结果基本符合正常合同审查逻辑,说明风险审查模块已经能够从静态页面升级为真实可用的 AI 风控功能。
之后又使用一份相对规范的软件开发服务合同进行测试。模型仍然给出了一些风险提示,例如验收默认通过、通用技术清单、违约金基数、质保服务等细节问题。这说明当前版本虽然已经能发现风险,但模型判断仍然偏保守,有时会把一般性优化建议也当成风险输出。

这个现象也为后续优化提供了方向:风险审查不能只让模型自由找问题,还需要给模型标准合同模板、风险等级规则和行业审查标准,否则容易出现“鸡蛋里挑骨头”的情况。
4. 本次开发总结
本次开发让我更清楚地理解了合同风险审查功能的业务价值。风险审查不是简单地问 AI“这份合同有没有问题”,而是要把合同中可能影响履约、权利义务和合规性的内容转化为结构化风险清单。
其中比较关键的是三点:
第一,风险分类要明确。合规性、公平性、完整性分别对应不同审查视角。如果不提前定义清楚,模型输出会比较散,前端也很难分类展示。
第二,输出格式要稳定。风险审查结果最终要保存到数据库并展示成表格,所以必须要求模型返回 JSON。只有结构化输出,才能让 AI 能力真正融入业务系统。
第三,AI 结果需要人工复核。模型可以帮助用户快速发现问题,但不能替代专业人员做最终判断。因此本次加入了 reviewStatus 字段和确认/忽略操作,让风险审查从“模型给出答案”变成“模型辅助审查 + 用户复核确认”的闭环。
整体来看,本次开发完成了合同风险审查功能的第一阶段落地。现在系统已经可以支持用户输入合同文本,自动识别风险点,给出修改建议,并保存和展示风险结果。
5. 后续优化方向
本次测试中也发现了一个比较重要的问题:当合同已经相对规范时,大模型仍然会继续输出较多风险点。这说明当前 Prompt 的风险判断偏保守,模型有时会把一般性完善建议也当成风险。
后续可以从以下几个方向优化:
第一,引入标准合同模板作为参考。不同合同类型应该有不同审查标准,例如软件开发合同重点关注需求范围、验收、知识产权、维护服务;租赁合同重点关注租金、押金、维修责任;劳动合同重点关注薪资、工时、社保和试用期。
第二,建立风险等级判定规则。高风险应该对应核心条款缺失、明显不公平或可能导致合同无法履行的问题;中风险对应条款模糊、容易引发争议的问题;低风险则更多是表达优化或细节完善建议。
第三,区分“风险”和“优化建议”。后续可以让模型返回两个列表,一个是 riskItems,表示真正可能影响合同履行或法律责任的问题;另一个是 optimizationItems,表示合同已经基本可用但可以进一步完善的建议。
第四,加入合同类型知识库。系统可以根据用户选择的软件开发合同、租赁合同、劳动合同等类型,加载对应审查规则和标准条款,让模型判断更接近真实法务审查。
第五,优化 Prompt 约束。可以在 Prompt 中加入“不要将一般性文字优化建议判定为风险,只有条款缺失、明显不公平、违法违规或可能直接导致履约争议时才输出为风险”。
通过这些优化,风险审查模块后续可以从“能找风险”进一步发展为“合理判断风险”,减少过度审查,让结果更符合实际合同审查场景。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 11
11 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)