MySQL的执行流程
目录
执行全流程:客户端 -> 连接器 -> 查询缓存 -> 分析器 -> 优化器 -> 执行器 -> 存储引擎 ->返回结果
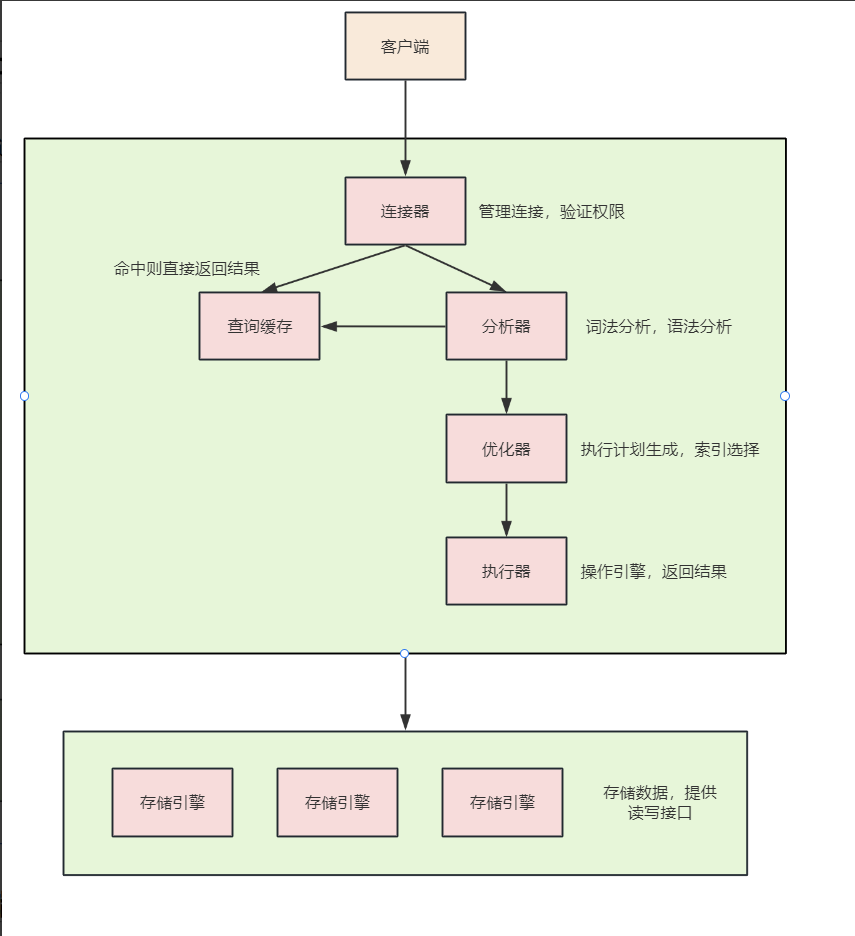
接下来是执行流程的详解
一、MySQL的执行流程详解
(1)客户端
用户或者程序通过MySQL客户端发送select语句,向MySQL服务端发起连接和查询请求
(2)客户端 -> 连接器
连接器是客户端通过协议与服务端建立连接,并且实现身份验证,权限校验,维持会话状态的连接
- 连接条件:通过 TCP/IP、Socket 或 Named Pipe 协议等
- 身份验证:连接器校验客户端提供的用户名、密码是否合法;若开启了 SSL,还会进行加密证书校验
- 权限校验:验证当前用户是否有执行该select语句所需的权限
- 连接维护:维护连接的会话状态,长连接会被连接器保存在连接池中复用,避免频繁创建销毁连接的开销
(3)连接器 -> 查询缓存(流程结束方式一)
连接器将校验过后的SQL语句作为key,去查询缓存中匹配是否有相同查询的结果集,查询缓存需要命中缓存结果,避免重复查询
命中条件:
- SQL 语句必须与缓存中的语句完全一致
- 目标表的数据未被修改
命中后 —— MySQL会将缓存结果返回给客户端,结束后续流程
未命中 —— 则传递给分析器,继续执行流程
(4)查询缓存 -> 分析器(流程结束方式二)
分析器对传递来的SQL语句进行词法分析,语法分析,成功则生成语法树
- 词法分析:将 SQL 语句拆分为一个个 “token”(词法单元),比如关键字(
SELECT、FROM、WHERE)、标识符(表名、列名)、运算符、常量等- 语法分析:根据 MySQL 的 SQL 语法规则,对 token 序列进行校验,判断语句是否符合语法规范,生成抽象语法树
- 校验:关键字顺序是否正确、表名列名是否存在、运算符使用是否合法、函数调用是否正确等
- 错误处理:如果语法错误,会直接返回 “SQL syntax error” 错误,终止执行流程
(5)分析器 -> 优化器
优化器根据分析器生成的语法树,生成最优的语句执行方式
- 逻辑优化:
- 等价变换:简化表达式、合并子查询 / 视图、消除冗余条件
- 外连接转内连接:如果外连接的条件可以过滤掉 NULL 值,会自动转为内连接,提升执行效率
- 谓词下推:将过滤条件尽可能下推到数据读取阶段,减少中间数据的传输量
- 物理优化:
- 索引选择:根据目标表的索引情况、统计信息,决定使用哪个索引,避免全表扫描
- 连接顺序优化:对于多表连接查询,选择最优的表连接顺序,减少中间结果集的大小
- 算法选择:为连接、排序、分组等操作选择最优的算法
结果:优化器最终会生成一份执行计划
(6)优化器 -> 执行器
执行器根据优化器的执行计划,进行二次的权限校验,调用存储引擎的接口,执行过滤查询,将处理后的结果按照select子句的列顺序组装,返回给客户端
- 权限二次校验:执行器会再次校验当前用户是否有访问目标表 / 列的权限
- 调用存储引擎接口:根据执行计划,向存储引擎发起数据读取请求
- 执行过滤与计算:对存储引擎返回的数据,执行
WHERE条件过滤、GROUP BY分组、ORDER BY排序、聚合函数计算等操作- 结果集组装:将处理后的结果集按
SELECT子句的列顺序组装,准备返回给客户端
(7)执行器 -> 存储引擎
存储引擎是为执行器提供数据读写接口的,负责数据的持久化存储、索引维护、事务管理,然后将读取到的数据返回到执行器
- 数据读取:
- 根据执行器的请求,从磁盘中读取数据行
- 如果使用索引,会通过索引快速定位到目标数据,避免全表扫描
- 事务处理:InnoDB 支持事务,读取数据时会处理事务隔离级别
- 数据返回:将读取到的数据行返回给执行器,供后续过滤、计算使用
(8)执行器 -> 返回结果(正常流程结束)
执行器将组装好的结果集,通过连接器返回给客户端,客户端接收并展示结果
一次 SELECT 查询流程正式结束
(9)举例说明
下面是一条 SELECT * FROM user WHERE id = 100; 语句的完整执行过程叙述:
- 客户端发起请求:应用程序通过 JDBC 向 MySQL 服务端发送上述查询语句。
- 连接器处理:客户端与 MySQL 建立 TCP 连接,连接器校验用户名密码和 user 表的查询权限,连接建立成功。
- 查询缓存检查:MySQL 检查查询缓存中是否存在与该语句完全一致的结果,若不存在则进入分析器阶段。
- 分析器解析:词法分析将语句拆分为 SELECT、*、FROM、user、WHERE、id、=、100 等 token;语法分析验证语句符合 SQL 规范,生成抽象语法树,确认 user 表和 id 列存在,无语法错误。
- 优化器优化:优化器分析执行计划,发现 id 列有主键索引,选择使用主键索引快速定位数据,生成最优执行计划:通过主键索引查找 id=100 的行,直接返回结果。
- 执行器执行:执行器接收执行计划,再次校验权限后,调用 InnoDB 存储引擎的读取接口,请求 id=100 的数据行。
- 存储引擎读取数据:InnoDB 先在 Buffer Pool 中查找该数据页,若命中则直接读取;若未命中则从磁盘读取数据页到内存,再通过主键索引定位到目标行,将数据返回给执行器。
- 结果返回:执行器将数据组装为结果集,通过连接器返回给客户端,客户端接收并展示结果,查询流程结束
二、三次插入操作的事务模型
我们把三次
INSERT操作包裹在同一个事务中:BEGIN; INSERT INTO table VALUES (...); -- 第1条 INSERT INTO table VALUES (...); -- 第2条(执行失败) INSERT INTO table VALUES (...); -- 第3条 COMMIT;两种执行结果:
- 异常场景(失败): 执行到第 2 条
INSERT时发生错误(如约束冲突、主键重复、异常中断)。 根据事务的原子性,MySQL 会触发回滚(ROLLBACK): 即使第 1 条已经成功写入,也会被撤销,相当于三次操作什么都没发生,数据库恢复到事务开始前的状态- 正常场景(成功): 三次
INSERT全部执行成功,没有任何异常。 此时事务会执行提交(COMMIT):所有修改永久生效,数据库状态被更新
核心结论:原子性的本质
事务的原子性,就是保证操作的 “要么全做,要么全不做”,不允许出现 “部分成功、部分失败” 的中间状态。 三次插入被当作一个不可分割的整体,要么全部成功提交,要么全部失败回滚
三、两阶段提交
为什么需要这个流程
两阶段提交协议:为了保证 Redo Log 和 Binlog 数据一致性,常用于分布式事务中
MySQL 事务提交时,需要同时写两个日志:
- Redo Log:InnoDB 的事务日志,用于崩溃恢复,保证数据不丢失
- Binlog:Server 层的二进制日志,用于主从复制、数据备份
这两个日志的顺序出现问题,会导致数据不一致:
- Redo Log 写成功,Binlog 写失败,崩溃后用 Redo Log 恢复的数据,和 Binlog 里记录的数据对不上
- Binlog 写成功,Redo Log 没写完,崩溃后 Binlog 记录了修改,但 Redo Log 没有,恢复时数据丢失
所以 MySQL 用两阶段提交,保证这两个日志的写入要么都成功,要么都失败
MySQL 内部两阶段提交的完整流程
角色定义:
- 事务管理器(TM,协调者):整个事务的协调中心,负责发起准备、收集结果、最终决定提交 / 回滚
- 资源管理器(RM,参与者):实际执行事务的节点,比如两个独立的数据库 A 和 B,它们分别执行本地事务
阶段一:准备阶段
- 事务管理器向所有资源管理器(A 和 B)发送
prepare请求- 每个资源管理器收到请求后,执行本地事务操作(如三次插入),并将操作结果写入本地日志(如 redo log),但不真正提交
- 每个资源管理器向事务管理器返回执行状态:
success(准备成功)或failure(准备失败)
阶段二:提交 / 回滚阶段
- 情况 1:所有返回都是
success事务管理器向所有资源管理器发送commit指令。 资源管理器收到指令后,正式提交本地事务,释放锁资源,事务完成- 情况 2:任意一个返回
failure事务管理器向所有资源管理器发送rollback指令。 所有资源管理器执行回滚操作,撤销之前的修改,恢复到事务开始前的状态
两阶段提交的缺陷:
- 单点故障问题 事务管理器是整个流程的中心,如果它在阶段二宕机,资源管理器会一直等待,无法完成提交或回滚,导致资源(如锁)被长期占用,影响系统可用性
- 数据不一致问题 如果事务管理器发送
commit指令后,部分节点(如 A)收到并提交成功,而另一部分节点(如 B)因为网络故障没收到指令,就会出现 “部分提交、部分未提交” 的状态,导致分布式数据不一致

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)