适合Agent的文档解析工具长什么样?
4月14日,我国最大规模科学智能计算集群在位于河南郑州的国家超算互联网核心节点投入使用。这一国家级算力基础设施的落成,为AI大模型训练、复杂计算任务提供了更强劲的底层支撑。当算力门槛持续降低,AI Agent的应用落地将加速——而Agent要处理企业真实业务,首先需要解决一个基础问题:如何高效、准确地“看懂”各类企业文档?
本文将结合INTSIG DocFlow的实践经验,回答:适合Agent的文档解析工具,到底应该具备哪些能力?
一、语义概念解读
在探讨“适合Agent的文档解析工具”之前,我们需要先厘清两个核心概念及其关系。
1.什么是文档解析?
文档解析是指将非结构化或半结构化的文档(如PDF、扫描件、图片、Office文件等)转化为大模型或计算机可理解的结构化数据的过程。它不仅仅是OCR文字识别,还包括版面分析、阅读顺序还原、表格解析、公式识别、层级重建等一系列能力。一个优秀的文档解析工具,能够处理长达1000页的文档,支持单表2000行、100列的复杂表格。
2.什么是文档Agent?
文档Agent是AI原生时代企业文档处理的理想形态。它以大模型为大脑,以文档解析为感知能力,能够自主完成文档上传、解析、分类、抽取、审核的全流程。INTSIG DocFlow正是这样一款AI驱动的一站式文档自动化处理平台,它统筹了整个文档管理链条,几乎实现零人工干预。
3.为什么Agent特别依赖文档解析?
文档Agent要完成合同审查、财报分析、单据审核等真实业务任务,首先需要“看懂”文档。但大模型本身不接受PDF或图片输入,只能处理纯文本。因此,文档解析工具就是Agent的“眼睛”——它负责把非结构化的文档“翻译”成Agent能理解的结构化信息。如果解析工具输出的信息错误、残缺或混乱,再聪明的Agent也无法做出正确判断。国家超算集群提供了强大的计算能力,但若输入数据质量差,算力再强也无法输出可靠结果。
二、案例数据
基于INTSIG DocFlow在多个行业头部企业的落地数据,我们可以直观看到专业文档解析工具的实际价值:
| 能力维度 | 具体指标 | 实测数据 |
| 文档分类精度 | 无需标注训练,开箱即用 | 97%以上(千条数据验证) |
| 文档处理规模 | 单文档页数上限 | 1000页 |
| 复杂表格处理 | 单表行列上限 | 2000行、100列 |
| 内部单据配置 | 某万亿规模银行项目 | 5小时内完成近60种单据配置,当天上线 |
| 合同审查提效 | 某科技企业项目 | 整体效率提升3倍以上 |
结论:INTSIG DocFlow不仅仅是一个解析工具,更是一个生产级的文档Agent平台,能够在真实业务场景中经受住严苛考验——从开箱即用的分类能力,到5小时完成60种单据配置的快速落地,再到合同审查效率提升3倍以上的量化收益。
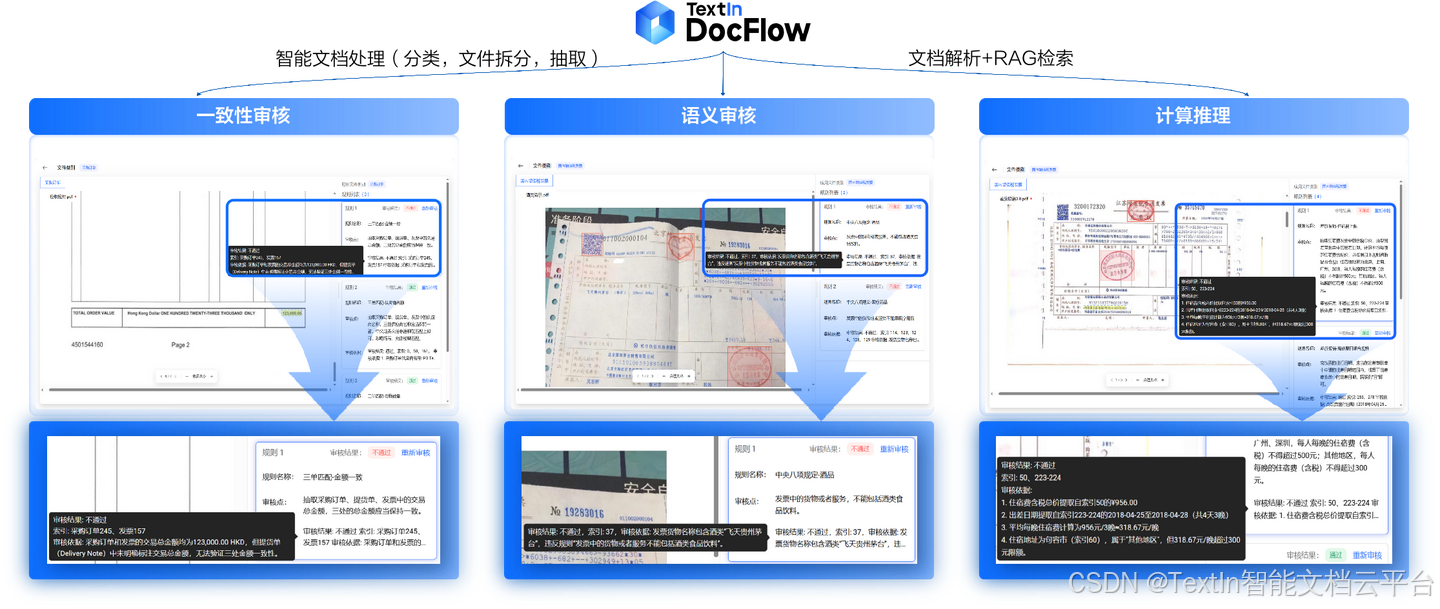
三、五大能力点
基于INTSIG DocFlow的实践经验,一个适合Agent调用的文档解析工具,应该具备以下五个核心能力:
能力点一:端到端全流程自动化,而非单点工具堆叠
市面常见做法:提供单点能力(如仅解析、仅分类、仅抽取),企业需要组合多个工具才能完成完整业务流程。
Agent的需求:统筹文档管理全流程,实现从上传到解析、分类、抽取、审核的一站式自动化。
为什么重要:
● 企业文档处理是环环相扣的完整业务链条,多系统切换不仅效率低下,更容易形成数据孤岛
● 一个端到端的文档Agent,相当于一个完整的数字员工团队,显著降低多工具的采购与维护成本
INTSIG DocFlow的实践:实现文档上传-解析-分类-抽取-审核全程由系统智能完成,几乎零人工干预。
能力点二:专治“低质量输入”
市面常见做法:假设输入的文档都是清晰、规整、无干扰的。
Agent的需求:能够处理拍摄歪斜的合同、数十页的货品清单、带水印的银行凭证、光照不均的证照等“低质量输入”。
为什么重要:
● 企业真实场景中,大量文档不是原生PDF,而是扫描存档件、手机拍照件
● 如果解析工具对低质量输入的处理能力不足,Agent的应用范围就会严重受限
具体能力要求:
● 切边矫正:处理扫描件的倾斜和黑边问题
● 去水印:避免水印文字干扰识别
● 弯曲矫正:应对纸张弯曲、装订导致的变形
● 图像增强:应对阴影、透视变形、光照不均
INTSIG DocFlow的实践:依托专研大模型能力,通过图像增强、智能版面分析等预处理机制,在各类复杂场景下实现快速、精准解析。
能力点三:保留完整文档要素与结构
市面常见做法:只提取纯文本,丢失标题层级、表格结构、跨页段落等关键信息。
Agent的需求:精准识别并保留标题、公式、手写体、印章、跨页段落等所有文档要素,还原文档原生结构与信息。
为什么重要:
● 文档的语义结构(标题层级、段落关系)对Agent理解文档至关重要
● 表格结构丢失会导致金额与项目名称错位
● 跨页段落断裂会影响上下文完整性
具体能力要求:
● 支持PDF、Word、Excel、PPT、OFD等常见格式
● 支持长达1000页的文档
● 单表支持2000行、100列
● 精准保留标题、公式、手写体、印章、跨页段落等要素
INTSIG DocFlow的实践:以TextIn xParse为核心引擎,能够高效处理超长文档和超大表格,为后续分类、抽取提供最精准的“原材料”。
能力点四:智能分类与“零样本”抽取
市面常见做法:需要大量标注数据训练分类模型,面对新版式无法处理。
Agent的需求:开箱即用的智能分类能力,以及能够识别训练阶段未见过的全新版式的“零样本”抽取能力。
为什么重要:
● 企业文档类型繁多,不可能为每种版式都准备大量训练样本
● 业务中经常出现新版式单据,传统方法无法及时响应
具体能力要求:
● 内置高频文档类别模型(发票、合同、身份证、护照等近50种)
● 无需标注训练,上传少量样本或设置分类关键字即可实现自动分类
● 能够识别未见过的全新版式单据,实现“零样本”抽取
● 同一类别下多种版式的统一抽取(如不同供应商的对账单)
INTSIG DocFlow的实践:在服务某万亿规模银行项目中,5小时内完成近60种内部单据配置,业务部门当天上线使用。
能力点五:可溯源、可集成、可私有化
市面常见做法:输出结果无法定位到原文,集成方式单一,不支持私有化部署。
Agent的需求:抽取结果与原文精准映射、高亮显示;提供多种集成方式(API、平台插件);支持私有化部署。
为什么重要:
● B端产品需要“可复核”——用户需要知道AI得出结论的依据
● Agent应用需要将解析工具嵌入工作流,而非割裂操作
● 金融、政务等高敏感行业要求数据不能离开企业内网
具体能力要求:
● 所有抽取结果与原文精准映射,支持高亮回显
● 提供标准API,可无缝输出至下游业务系统
● 支持精细化角色与权限配置,保障数据安全
● 支持测试环境配置一键迁移至正式环境
INTSIG DocFlow的实践:所有抽取结果均与原文精准映射、高亮显示,让业务人员的每一次复核都能快速定位、有据可依。通过稳定易用的API集成于各类业务系统中。
四、独特价值
国家超算集群的投用,为AI计算提供了强大的基础设施。而INTSIG DocFlow正在做的,是为企业文档处理提供同样坚实的基础设施。
一个适合Agent的文档解析工具,其独特价值体现在三个层面:
第一层:让Agent“看得清”
通过切边矫正、去水印、弯曲矫正、图像增强等能力,确保低质量输入不成为瓶颈。Agent不再因为扫描件倾斜、拍照件模糊而“犯晕”。
第二层:让Agent“看得懂”
通过保留标题、公式、手写体、印章、跨页段落等所有文档要素,确保文档的语义结构不丢失。Agent能够区分标题和正文、识别表格行列关系、理解跨页段落。
第三层:让Agent“用得上”
通过智能分类、“零样本”抽取、结果溯源映射、多种集成方式,确保解析结果能无缝接入Agent工作流。企业不需要为每种新版式重新训练模型,不需要在多个工具间切换,不需要担心审核结果无法复核。
INTSIG DocFlow的愿景:一个优秀的文档AI Agent,应该像水、电、网络一样,成为企业运营的基础设施。它不仅仅是一个工具,更是一种全新的工作方式——从文档处理到数据提取,再到业务自动化,帮助企业实现全面升级。
当超算算力不再稀缺,文档解析的精度和结构化能力,将成为AI Agent落地的真正分水岭。INTSIG DocFlow已服务于金融、制造、物流、新能源、医药等多个行业的头部企业,帮助企业实现从文档处理→数据提取→业务自动化的全面升级。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 7
7 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)