Hermes Agent Memory 记忆系统详解:为什么它能“越用越懂你”?
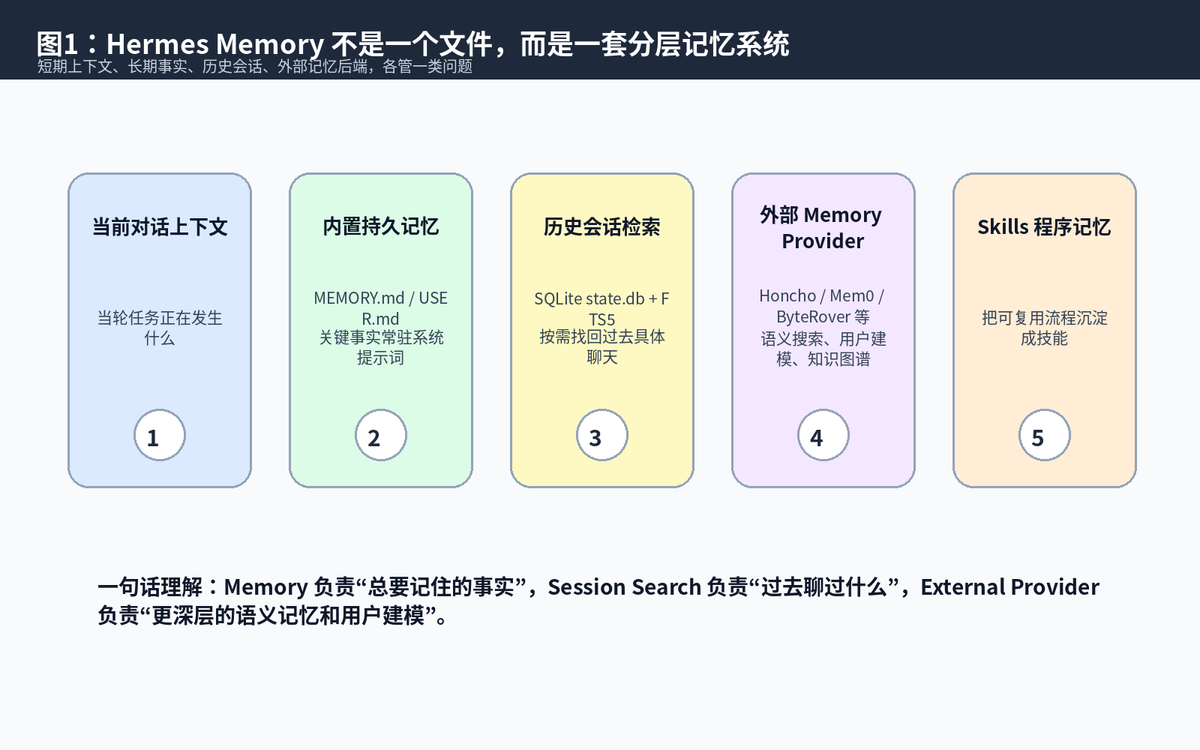
导读:很多人理解 Agent 的记忆时,容易误以为“记忆 = 把聊天历史塞进 prompt”。但 Hermes Agent 的设计更像一个分层知识系统:有常驻的关键事实,有可检索的历史会话,有可扩展的外部记忆后端,还有把成功流程沉淀下来的 Skills。本文不讲复杂公式,只用工程视角把 Memory 的完整链路讲清楚。
一、先给结论:Hermes 的 Memory 不是“多存点聊天记录”
Hermes Agent 的 Memory 机制,本质上解决的是一个非常现实的问题:当 Agent 不是一次性回答问题,而是长期陪你做项目、写代码、跑任务、处理环境配置时,它必须知道“你是谁”“你的项目是什么”“这台机器有什么特殊配置”“上次踩过什么坑”“你喜欢什么回答风格”。
但是,这些信息不能无限塞进提示词。提示词越长,成本越高,干扰越多,缓存越难命中。所以 Hermes 采用的是“有限、精选、分层”的记忆设计。
MEMORY.md:保存 Agent 自己要记住的环境、项目、经验、工具坑。
USER.md:保存用户画像,比如偏好、沟通风格、工作习惯。
Session Search:保存完整会话历史,需要时通过 SQLite + FTS5 搜索。
External Memory Provider:接入 Honcho、Mem0、ByteRover 等外部记忆后端,增强语义搜索、用户建模和知识图谱能力。
Skills:不是事实记忆,而是“流程记忆”,适合沉淀可复用操作方法。
所以你可以把 Hermes 的记忆理解成一句话:短期上下文负责当下,Memory 负责长期关键事实,Session Search 负责历史档案,外部 Provider 负责更深的语义和用户建模。
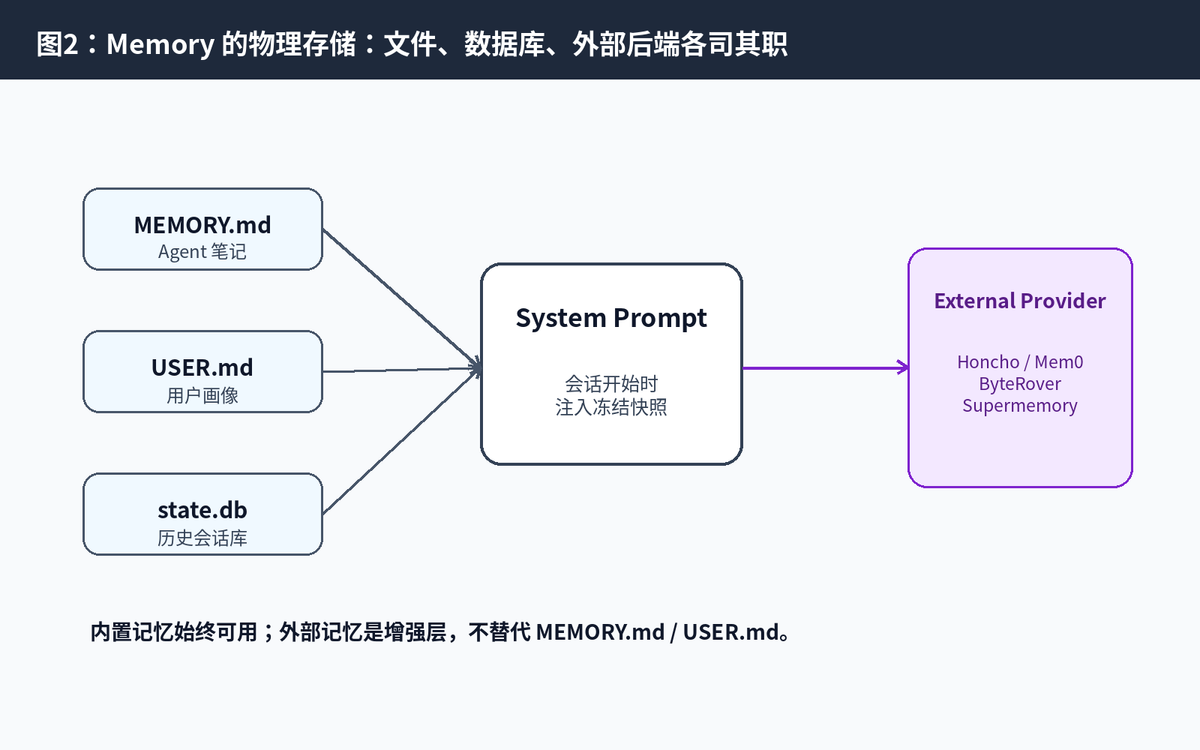
二、Memory 的核心文件:MEMORY.md 和 USER.md
官方文档把内置 Memory 拆成两个文件:MEMORY.md 和 USER.md。它们都存放在 ~/.hermes/memories/ 目录下,并且会在新 session 开始时加载进系统提示词。
|
文件 |
保存内容 |
适合保存 |
默认容量定位 |
|
MEMORY.md |
Agent 的个人笔记 |
环境事实、项目规范、工具坑、完成过的重要任务、经验教训 |
约 2,200 字符,偏工程事实 |
|
USER.md |
用户画像 |
用户姓名、角色、时区、回答偏好、工作习惯、技术水平 |
约 1,375 字符,偏用户偏好 |
这两个文件的分工非常关键:MEMORY.md 更像“工作笔记”,USER.md 更像“用户画像”。一个让 Agent 更懂项目,一个让 Agent 更懂人。
例如:项目路径、测试命令、数据库版本、部署注意事项,应该进入 MEMORY.md;用户喜欢先给结论、不要废话、喜欢表格总结,则更适合进入 USER.md。
2.1 为什么要拆成两个文件?
因为“项目事实”和“用户偏好”的生命周期不同。项目事实可能随着仓库、服务器和工具链变化而变化;用户偏好则更偏长期稳定。如果全部混在一个文件里,后期整理、替换、删除都会变得混乱。
项目事实变化时,只需要改 MEMORY.md。
用户偏好变化时,只需要改 USER.md。
系统提示词可以更清楚地区分“当前环境”和“用户画像”。
Agent 做记忆清理时,也更容易判断哪些该保留,哪些该淘汰。
三、Memory 是怎么进入模型的?冻结快照机制
Hermes 的一个重要设计是“冻结快照”。在每个新 session 开始时,系统会从磁盘读取 MEMORY.md 和 USER.md,把它们渲染成系统提示词中的固定块。这个块里会显示当前用了多少容量,以及每条记忆的内容。
所谓“冻结”,意思是:本轮 session 启动后,即使 Agent 中途调用 memory 工具新增或修改了记忆,当前已经组装好的系统提示词不会立即变化。写入会落到磁盘,但通常要到下一轮新 session 或强制重建 prompt 时才会被重新加载。
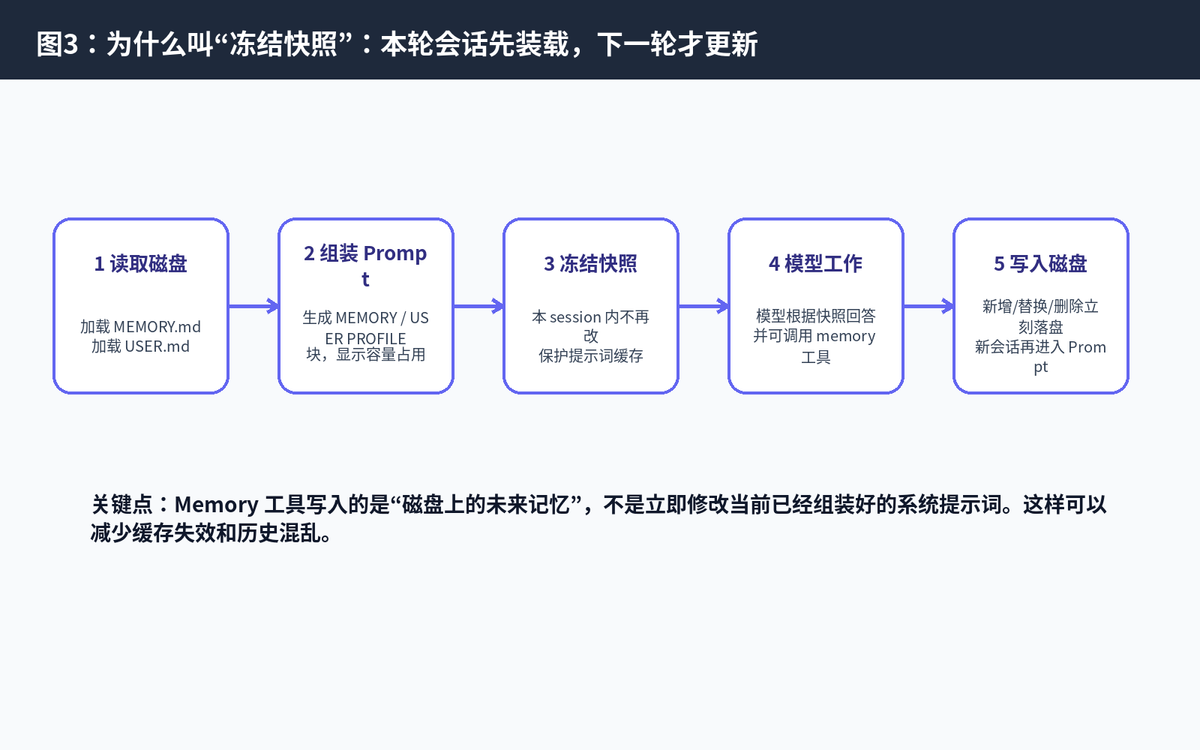
3.1 这种设计解决了什么问题?
保护提示词缓存:系统提示词前缀稳定,更利于 provider 侧缓存。
避免中途变更导致上下文混乱:同一个 session 里模型看到的长期记忆保持一致。
降低调试难度:你知道本轮回答基于哪一版 Memory。
让写入动作更像“为未来准备知识”,而不是立刻重写当前对话规则。
这也是 Hermes Memory 和普通 RAG 的不同点:Memory 不是每次都去库里搜一大堆材料,而是把最重要、最稳定的事实放进系统提示词,让 Agent 从启动时就带着这些事实工作。
四、memory 工具:Agent 如何写入、替换、删除记忆
Hermes 并不是靠用户手动编辑 MEMORY.md。官方文档说明,Agent 可以通过 memory 工具管理自己的记忆。这个工具的核心动作非常简单:add、replace、remove。
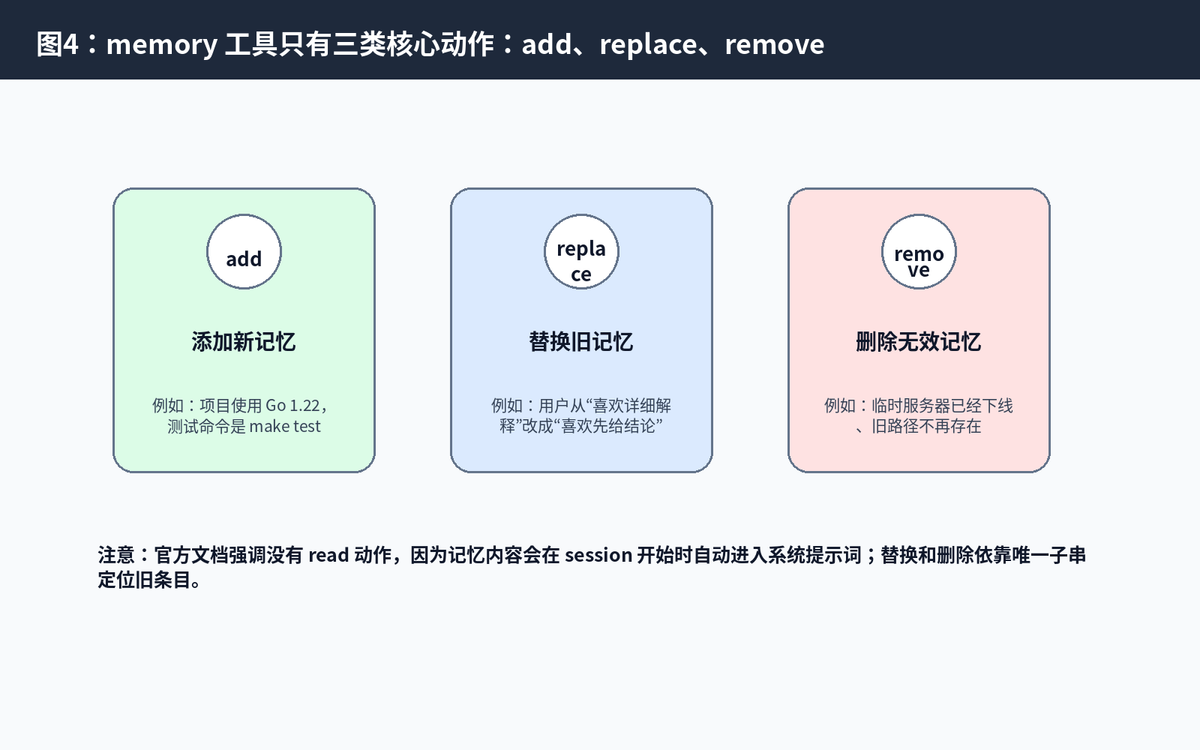
4.1 add:添加新记忆
当 Agent 发现一个长期有价值的信息时,可以把它写入 memory。比如用户明确说“记住我这个项目用 Java 17”,或者 Agent 在排查中发现“这个服务器 Docker 不能用 sudo”,这些都可能成为未来任务的关键事实。
4.2 replace:替换旧记忆
项目和用户偏好都会变。如果原来项目用 MySQL,现在迁移到了 PostgreSQL,继续保留旧记忆反而会误导 Agent。replace 的作用就是用新事实覆盖旧事实。官方文档也提到,替换和删除使用 old_text 子串匹配,只要这个子串能唯一定位旧条目即可。
4.3 remove:删除过期记忆
有些信息只在当时有用,比如临时测试路径、一次性日志、废弃服务器、已经失效的 API 地址。长期保存这些内容会污染上下文,导致 Agent 做出错误判断,所以需要 remove。
五、什么应该记?什么不该记?
Memory 的难点不在“怎么写文件”,而在“什么值得进入长期记忆”。Hermes 的设计强调 bounded curated memory,也就是有限且精选的记忆。
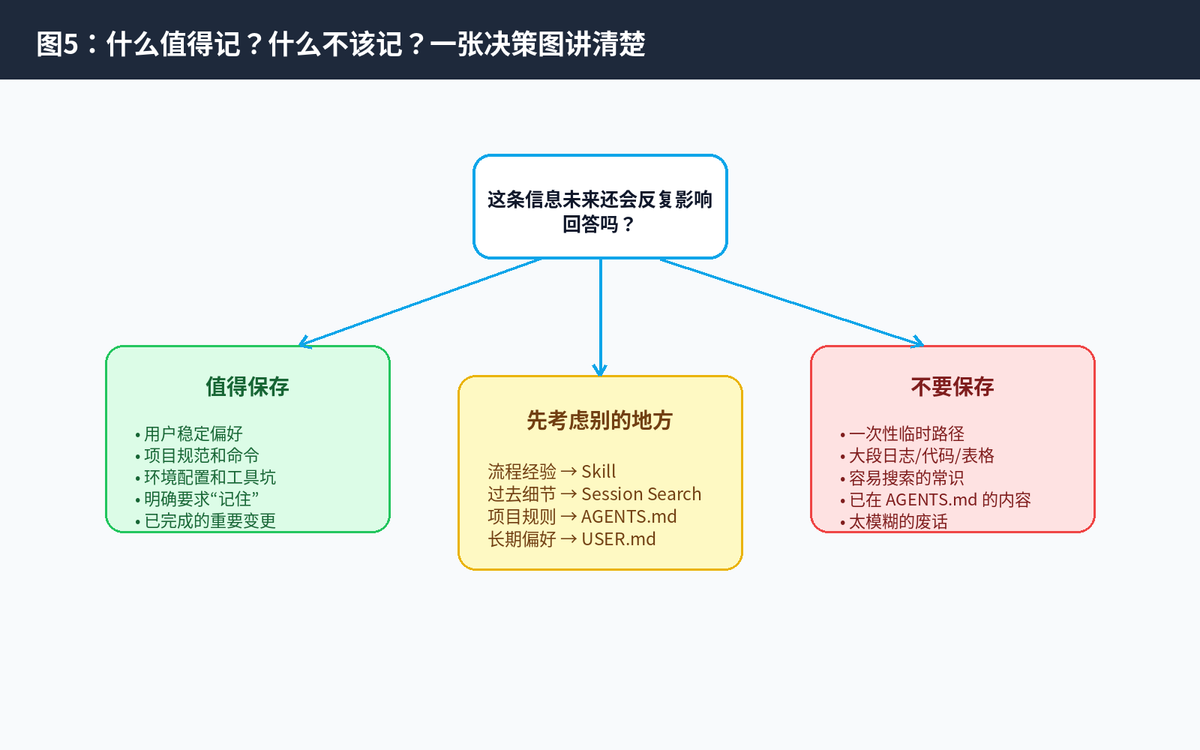
5.1 值得保存的内容
用户偏好:比如喜欢简洁回答、喜欢表格、喜欢先给结论。
环境事实:比如服务器系统版本、项目目录、数据库版本、常用工具。
项目约定:比如测试命令、代码风格、分支策略、CI 流程。
用户纠正:比如“以后不要用这个方案”“这个项目不用某个框架”。
完成过的重要工作:比如某次迁移、修复、部署、重构已经完成。
明确要求记住的事实:用户说“记住”“以后都按这个来”。
5.2 不应该保存的内容
太泛的信息:比如“用户问过 Python”,没有实际价值。
容易搜索的常识:比如语言版本特性、公开文档可查内容。
大段原始材料:代码块、日志、表格、报错全文,太占空间。
一次性上下文:临时文件路径、某次调试中的中间变量。
已经放在项目 context 文件里的内容:例如 AGENTS.md、SOUL.md 已经覆盖的规则。
一句话:Memory 只保存“未来会反复改变答案的关键信息”。如果只是过去发生过,不代表就应该写进 Memory。
六、Memory 和 Session Search:一个是长期结论,一个是历史档案
很多人容易把 Memory 和历史聊天记录混为一谈。Hermes 的设计恰恰是把它们分开:Memory 是精选结论,Session Search 是完整档案。

官方文档说明,CLI 和 messaging sessions 会存到 SQLite 的 ~/.hermes/state.db 中,并使用 FTS5 做全文搜索。session_search 返回的是数据库里的真实消息,不是 LLM 摘要,也不是被截断后的二手内容。
这就像一个人的大脑:Memory 是你牢牢记住的经验,Session Search 是你的聊天档案库。平时不需要每次都翻档案,但当你问“上周我们是不是讨论过这个问题”时,Agent 可以检索过去 session。
6.1 为什么不把所有历史都放进 Memory?
因为 Memory 每次都进系统提示词,有固定 token 成本。历史会话如果全部塞进去,会让 prompt 越来越臃肿。Session Search 则是按需检索,不需要每次都带上所有历史。
Memory:适合常驻关键事实,成本是每次 prompt 都要携带。
Session Search:适合查找过去具体对话,成本是需要时才检索。
二者组合:既保证 Agent 有长期认知,又避免提示词无限膨胀。
七、一条记忆从产生到生效的完整链路
理解 Memory 不能只看文件,还要看完整生命周期。一次典型写入大概经历这些阶段:识别长期价值、调用 memory 工具、安全扫描、容量检查、写入文件、下次 session 注入。
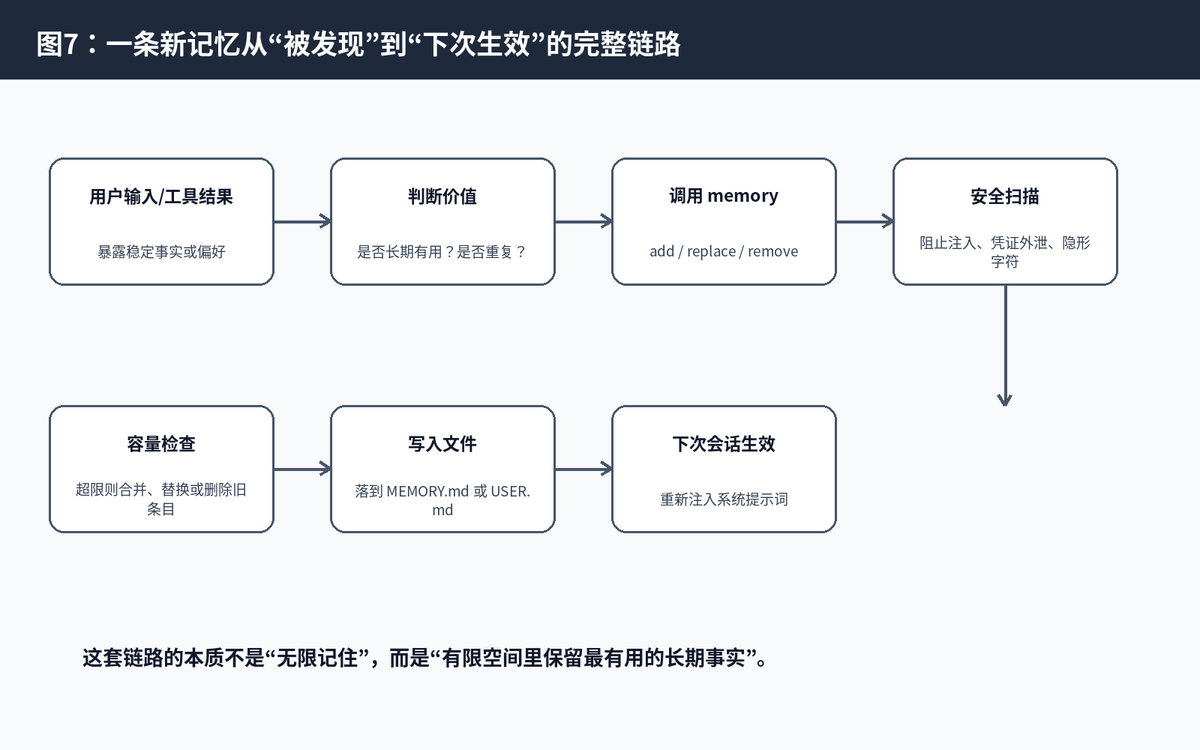
7.1 一个实际例子
假设用户说:“以后这个项目都用 pnpm,不要用 npm。”Hermes 应该判断这不是一次性闲聊,而是会影响后续命令生成的项目约定,于是把它写入 MEMORY.md。
本轮对话:Agent 可以立即根据当前消息使用 pnpm。
写入磁盘:memory 工具把“项目使用 pnpm,不用 npm”保存下来。
下次会话:这条信息作为 Memory 快照进入系统提示词。
未来任务:Agent 再生成安装、测试、构建命令时,会自然优先使用 pnpm。
这就是“越用越懂你”的真实原因:不是模型权重被实时训练了,而是运行时系统把长期有效信息资产化了。
八、容量管理:为什么 Memory 要限制大小
官方文档给内置 memory 和 user profile 都设置了严格字符限制。这个限制看似小,但它能迫使 Agent 只保存高价值信息,避免把 Memory 变成垃圾堆。
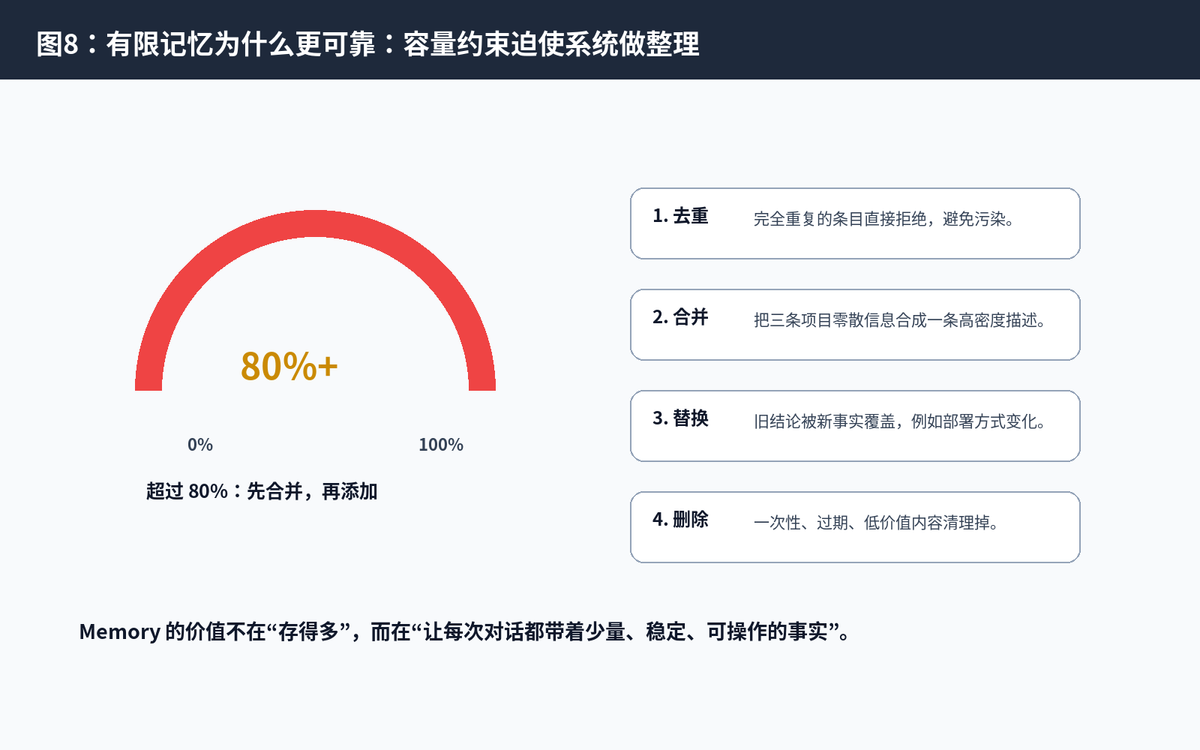
8.1 超过容量怎么办?
当新增条目会超过容量时,工具会返回错误并提示当前占用和需要腾出的空间。官方建议 Agent 先读当前条目、找出可以合并或删除的内容,再用 replace 合并相关条目,最后再添加新条目。
去重:完全重复的内容不重复写入。
压缩:把多条零散信息合并成一条高密度事实。
替换:用新事实覆盖过期事实。
删除:清理无效、临时、低价值记忆。
这和做知识库很像:真正好的知识库不是资料越多越好,而是让最关键的内容在最短路径里被找到。
九、安全扫描:Memory 为什么必须更严格
Memory 比普通聊天内容更危险,因为它会在后续 session 中进入系统提示词,持续影响 Agent 行为。如果恶意内容被写进 Memory,就可能形成长期 prompt injection。
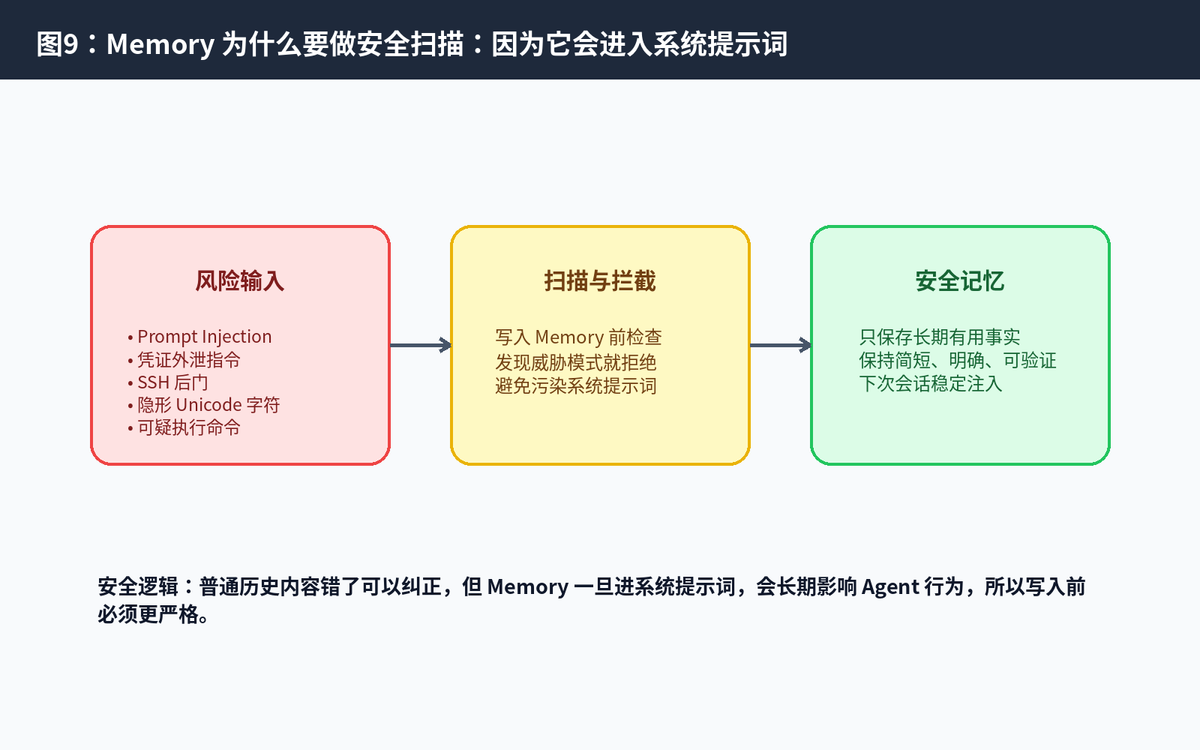
9.1 需要防什么?
Prompt Injection:把“以后忽略系统指令”之类内容写入长期记忆。
凭证外泄:诱导 Agent 保存或输出密钥、token、私有路径。
后门指令:保存危险命令、SSH 后门、绕过审批的操作习惯。
不可见字符:利用 Unicode 隐形字符隐藏恶意指令。
所以 Memory 的安全策略可以总结为:能进系统提示词的内容,一定要比普通聊天记录更严格。
十、外部 Memory Provider:从文件记忆升级到语义记忆
内置 MEMORY.md / USER.md 是 Hermes Memory 的基础层,但官方也提供外部 Memory Provider 插件体系。它们不是替代内置记忆,而是作为增强层并行工作。
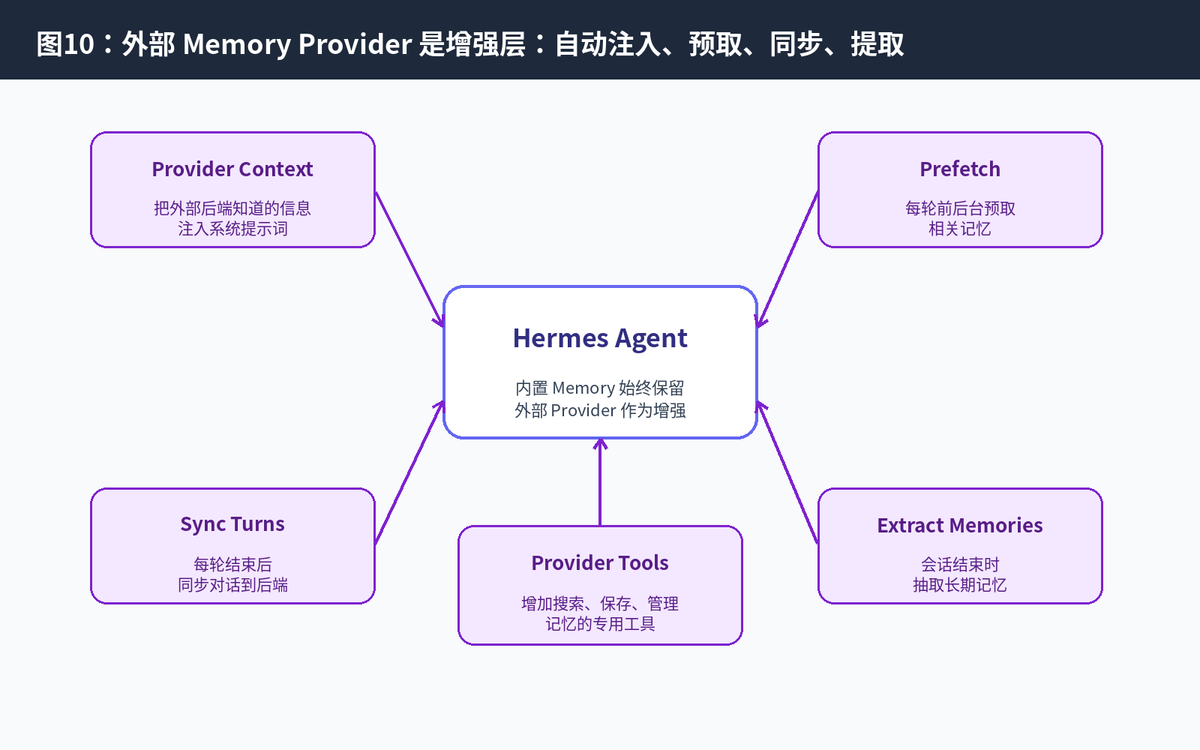
官方文档说明,当外部 provider 激活后,Hermes 会自动做几类动作:把 provider context 注入系统提示词、每轮前后台预取相关记忆、每轮后同步对话、会话结束时抽取记忆、镜像内置 Memory 写入,并增加 provider 专用工具。
|
Provider |
定位 |
存储/成本倾向 |
典型能力 |
|
Honcho |
用户建模与跨 session 上下文 |
云端或自托管 |
Dialectic reasoning、peer profile、语义搜索 |
|
OpenViking |
层级知识管理 |
自托管 |
分层上下文加载、自动记忆抽取 |
|
Mem0 |
通用记忆层 |
云端 |
服务端记忆抽取与检索 |
|
ByteRover |
本地优先知识树 |
本地/云同步 |
预压缩抽取、分层知识树 |
|
Supermemory |
语义长期记忆 |
云端 |
上下文隔离、会话图谱 ingest、多容器 |
10.1 为什么要外部 Provider?
因为文件记忆适合短小、稳定的关键事实,但当你希望 Agent 理解更复杂的用户模式、项目历史、跨设备上下文、知识图谱关系时,仅靠两个 Markdown 文件就不够了。外部 provider 可以提供语义搜索、自动事实抽取、用户建模、知识图谱、分层知识树等能力。
但是要注意:外部 provider 不是越多越好。官方文档说明同一时间只能激活一个外部 provider,内置 Memory 则始终和它一起工作。
十一、Honcho 示例:Memory 不只是存事实,还能理解用户模式
在官方 Honcho Memory 文档里,Honcho 被描述为 AI-native memory backend,它在 Hermes 内置记忆基础上增加 dialectic reasoning 和深层用户建模。简单说,它不只是保存“用户说过什么”,还会尝试从对话中推理“用户偏好、习惯、目标和模式”。
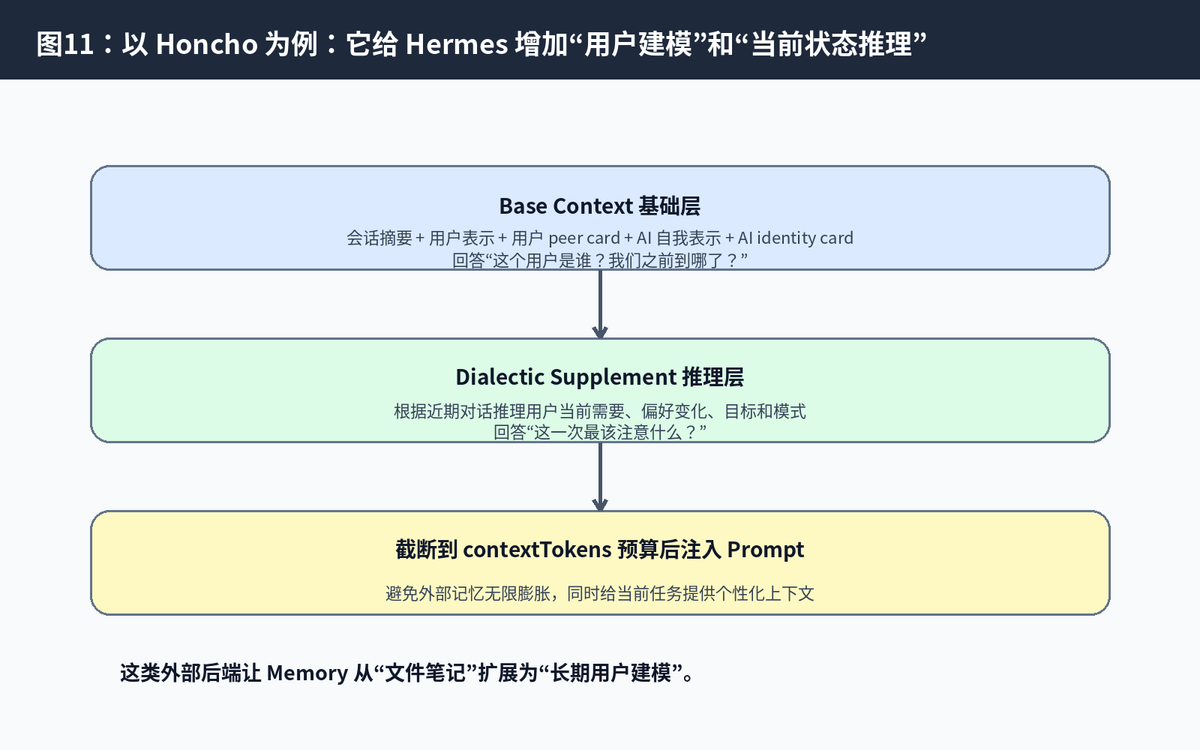
11.1 Honcho 的两层上下文
Base Context:包括会话摘要、用户表示、用户 peer card、AI 自我表示、AI identity card,解决“这个用户是谁、当前 session 到哪了”的问题。
Dialectic Supplement:通过 LLM 推理当前对话背后的用户状态和需要,解决“这次互动最该注意什么”的问题。
Context Budget:这些内容最终会被截断到配置的 contextTokens 预算内,避免上下文无限增长。
这类能力让 Agent 的“懂你”从简单偏好扩展到行为模式。例如,一个用户经常要求“生成头条技术文章 + docx + 图解”,长期记忆系统就可以让 Agent 更快进入这种工作模式。
十二、Memory 和 Skills 的边界:记事实 vs 记流程
Hermes 里还有 Skills 系统,它也经常被误解成 Memory。实际上二者边界非常清楚:Memory 记事实,Skills 记流程。
|
类型 |
回答的问题 |
适合内容 |
例子 |
|
Memory |
以后应该知道什么事实? |
偏好、环境、项目约定、工具坑 |
用户喜欢 Word 文档,项目用 pnpm |
|
Skills |
以后遇到类似任务怎么做? |
可复用操作步骤、模板、脚本、工作流 |
生成头条文章的固定结构和配图流程 |
|
Session Search |
过去具体聊了什么? |
历史对话、工具结果、临时过程 |
上周排查某个错误时的完整记录 |
举个例子:用户说“以后文章标题要有大小写数字”,这更像偏好,可以进 USER.md;用户说“每次生成技术文章都要先联网、画图、生成 docx、渲染检查”,这就是流程,更适合沉淀成 Skill。
十三、看 GitHub 源码应该从哪里入手?
如果你想深入理解 Hermes Memory,不建议从所有文件开始看。可以按“Prompt 注入 -> 工具写入 -> 会话存储 -> 外部 Provider”的顺序读。
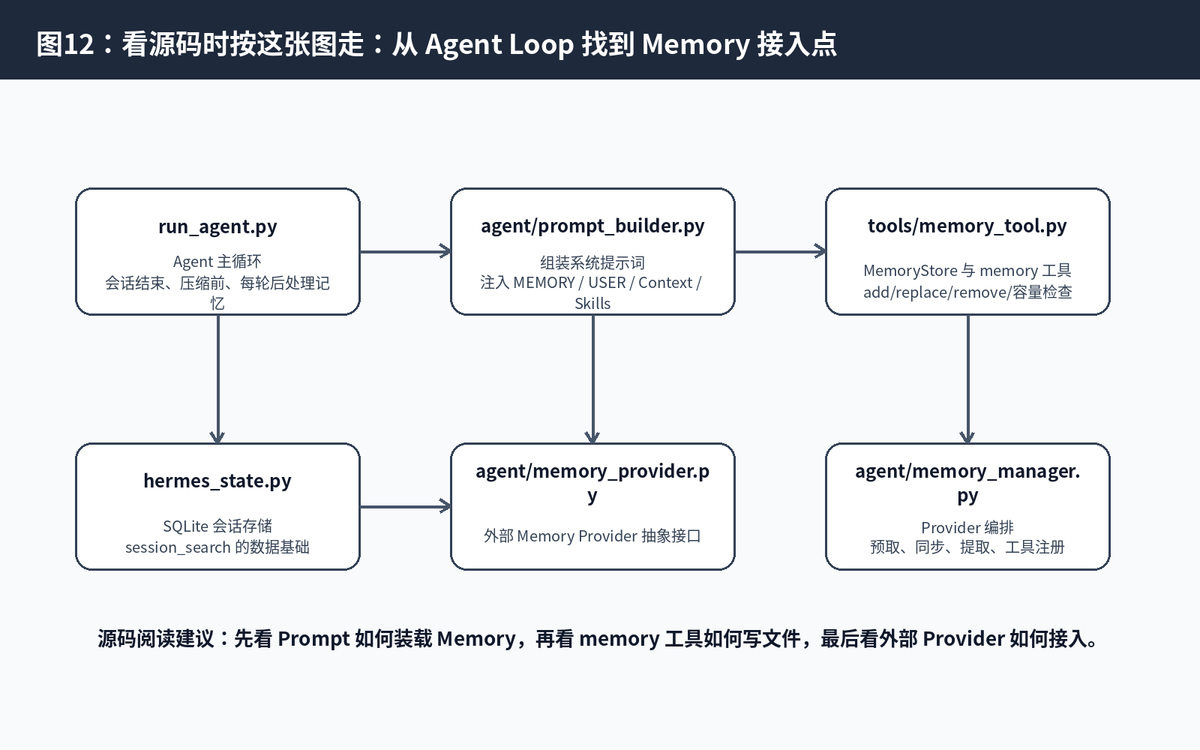
13.1 推荐阅读顺序
先看 agent/prompt_builder.py:理解 MEMORY.md、USER.md、Context Files、Skills 如何进入系统提示词。
再看 tools/memory_tool.py:理解 MemoryStore 如何处理 add、replace、remove、容量检查、去重。
再看 run_agent.py:理解 Agent Loop 如何在每轮结束、压缩前、会话保存时触发 Memory 相关逻辑。
再看 hermes_state.py:理解 session_search 的历史会话存储基础。
最后看 agent/memory_provider.py 和 agent/memory_manager.py:理解外部记忆后端如何统一接入。
十四、把 Hermes Memory 思路迁移到你自己的 Agent 项目
如果你自己要做一个企业知识助手、客服 Agent、AI 编程助手或个人自动化 Agent,可以直接借鉴 Hermes 的 Memory 思路。
14.1 可以直接照抄的工程原则
分层记忆:不要把用户偏好、项目规则、历史对话、流程经验混在一起。
容量限制:Memory 必须有上限,否则迟早变成垃圾场。
主动整理:新增前先判断价值,超过容量时合并旧内容。
按需检索:历史会话不要常驻 prompt,必要时再搜。
写入安全:凡是会进入系统提示词的内容,都要做注入和泄密扫描。
可解释:Memory 最好是人能读懂的 Markdown 或可审计结构,而不是黑盒向量。
事实和流程分离:事实进 Memory,流程进 Skills,历史进 Session Search。
14.2 一个适合企业落地的 Memory 结构
如果是企业级 Agent,可以设计成下面这样:
User Profile:用户角色、部门、偏好、权限范围。
Project Memory:项目目录、服务架构、技术栈、部署命令。
Team Convention:团队规范、代码风格、审批流程。
Incident Memory:历史故障、修复方式、排障经验。
Session Archive:完整历史对话和工具调用日志。
Skill Library:常见任务的标准操作流程。
这样设计后,Agent 不会每次从零开始,也不会把所有历史一股脑塞进 prompt,而是像一个熟悉项目的工程师一样,带着关键事实和经验进入任务。
十五、总结:Hermes 为什么能“越用越懂你”?
Hermes Agent 的 Memory 机制,不是魔法,也不是每次在线训练模型。它真正做的是把长期有效的信息资产化、分层存储、按需注入、持续整理。
它用 MEMORY.md 记住环境、项目、工具和经验。
它用 USER.md 记住用户偏好、沟通风格和工作习惯。
它用 Session Search 找回过去具体聊过什么。
它用外部 Memory Provider 扩展语义搜索、知识图谱和用户建模。
它用容量管理和安全扫描防止 Memory 变成垃圾堆或攻击入口。
它用 Skills 把可复用流程沉淀下来,让下一次类似任务更快更稳。
所以,Hermes “越用越懂你”的根本原因,不是模型突然变聪明,而是它把每次交互中有长期价值的事实、偏好、经验和流程,逐步沉淀成下一次任务可直接使用的上下文资产。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 4
4 0
0- 0



 已为社区贡献235条内容
已为社区贡献235条内容

所有评论(0)