对比多个文档解析工具的核心能力与使用场景
文档解析赛道再添猛将。MinerU 2.5-Pro正式上线SaaS端,以1.2B参数在OmniDocBench v1.6评测集上跑出95.69分,登顶文档解析SOTA。新版本解锁Office全格式原生解析(Word/PPT/Excel无需转换),并支持印刷体/手写体公式精准输出LaTeX、复杂表格结构还原、跨页内容自动拼接等能力。这标志着:文档解析正从“能用”向“全能、高精度、生产级”快速演进。
然而,面对MinerU、TextIn、PaddleOCR等众多工具,开发者该如何选择?本文将从核心能力、性能数据、适用场景三个维度,为您系统对比主流文档解析工具,助您找到最适合业务需求的“解析底座”。
一、语义概念
文档解析是指将非结构化或半结构化的文档(如PDF、扫描件、图片、Office文件等)转化为大模型或计算机可理解的结构化数据(如Markdown、JSON、XML)的过程。它不仅仅是OCR文字识别,还包括:
● 版面分析:识别标题、段落、表格、图片、页眉页脚等区域
● 阅读顺序还原:按人类阅读逻辑重组多栏、跨页内容
● 表格解析:提取合并单元格、跨页表格、无线表格的结构与内容
● 公式识别:将印刷体/手写体公式转为LaTeX或MathML
● 层级重建:根据标题缩进、编号自动构建文档树 它是RAG、知识库、文档智能体的“第一步”,也是决定上层应用效果的关键瓶颈。
二、企业应用现状 根据我们与多家法律科技、金融、制造企业的调研,当前企业普遍面临三个断层:
|
断层类型 |
具体表现 |
企业痛点 |
|
格式断层 |
30%企业合同以PDF/扫描件形式存在 |
不支持原生PDF的工具导致客户流失 |
|
性能断层 |
开源方案单文件解析OK,批量并发崩溃 |
日处理量不足千页,响应时间从ms级飙升至15s+ |
|
精度断层 |
开源模型标称95%+准确率 |
表格错位、条款层级丢失导致AI审查漏判 |
一个典型案例:某法律科技企业自研OCR方案,成本高、周期长,且准确率不足。接入生产级解析底座后,解析准确率提升至99%以上,数据处理效率提升近5倍,原本数月的数据清洗工作缩短至几周,项目整体进度提前了3个月。
三、主流文档解析工具核心能力对比 基于公开资料,我们对三款代表性工具进行对比(数据截至2026年5月):
工具一:MinerU 2.5-Pro(开源 + SaaS)
|
能力维度 |
具体表现 |
适用场景 |
|
支持格式 |
✅ PDF、Word、PPT、Excel、图片✅ Office全格式原生解析(无需转换) |
学术论文、技术文档、办公文档 |
|
解析精度 |
⭐ OmniDocBench v1.6: 95.69分(SOTA)✅ 印刷体/手写体公式 → LaTeX✅ 跨页表格自动合并✅ 带背景干扰、空白单元格、嵌入公式/图片的复杂表格 |
科研、教育、出版 |
|
特殊能力 |
✅ 手写体文字、竖排/垂直文字提取✅ 跨页段落自动拼接✅ 一定程度的图片理解能力 |
古籍数字化、历史档案 |
|
部署方式 |
✅ 开源(本地部署)✅ SaaS(网页端/客户端/API) |
个人开发者、学术研究、企业轻量使用 |
|
性能数据 |
1.2B参数,轻量高效 |
资源受限环境 |
一句话总结:学术场景王者,轻量参数+SOTA精度,适合论文、公式、表格密集的文档。
工具二:TextIn xParse(生产级商业方案)
|
能力维度 |
具体表现 |
适用场景 |
|
支持格式 |
✅ PDF、Word、Excel、PPT、扫描件、图片等10余种格式✅ 无需预处理,原生PDF直接读 |
企业合同、财报、发票、报关单 |
|
解析精度 |
⭐ 表格识别准确率突破99%✅ 合并单元格、跨页表格、无线表格、密集少线表格✅ 自研文档树引擎,基于语义自动预测标题层级 |
金融、法律、供应链 |
|
性能数据 |
✅ 单文档P99 ≤ 1.5秒✅ 高并发架构,百份文件同时上传无衰减✅ 99.9%可用性SLA |
企业级批量处理 |
|
结构化输出 |
✅ Markdown / JSON✅ 条款、金额、日期、各方主体已对齐✅ 解析结果可溯源到原文档坐标 |
RAG、知识库、自动化审核 |
|
集成方式 |
✅ 标准API + Python/Java SDK✅ MCP Server(一次开发,所有大模型自动适配)✅ 已上架Coze、Dify、HiAgent插件 |
法律科技厂商、系统集成商 |
|
部署方式 |
✅ SaaS API✅ 私有化部署(数据不出域) |
金融、政务等高敏感行业 |
一句话总结:企业级生产标杆,专为“批量、稳定、可溯源”设计,适合对可靠性有严苛要求的商业场景。
工具三:PaddleOCR(开源社区方案)
|
能力维度 |
具体表现 |
适用场景 |
|
核心定位 |
开源OCR工具,文档解析为其中一项能力 |
通用OCR、文档智能体入口 |
|
支持格式 |
图片、扫描件、PDF(通过社区贡献) |
发票、截图、会议白板 |
|
集成生态 |
✅ 集成至ClawMaster(可视化管理工具)✅ 与LangChain、OpenClaw、PowerMem打通 |
快速搭建文档智能体原型 |
|
部署方式 |
✅ 开源本地部署✅ 星河社区API |
开发者、研究者 |
一句话总结:开源社区生态王者,适合“OCR+Agent”快速原型验证,但企业级批量稳定需二次开发。
四、产品简介
TextIn xParse是合合信息旗下AI基础设施产品,核心使命:把任何非结构化文档,变成大模型真正“看得懂”的结构化数据。其差异化能力包括:
● 全格式覆盖:10余种格式、数百种专业文档类型,无需预处理
● 合同专项优化:自研文档树引擎,表格识别准确率99%+,条款层级精准还原
● 企业级性能:单文档≤1.5秒,高并发+99.9% SLA,支撑规模化交付
● 开发者友好:MCP Server、Coze/Dify插件、私有化部署,1小时跑通

五、核心能力点呈现能力一:格式支持广度——谁更“开箱即用”?
|
工具 |
|
Word |
PPT |
扫描件 |
手写体 |
公式 |
|
MinerU 2.5-Pro |
✅ |
✅原生 |
✅原生 |
✅ |
✅ |
✅ (LaTeX) |
|
TextIn xParse |
✅ |
✅ |
✅ |
✅ |
✅ |
✅ |
|
PaddleOCR |
✅* |
❌ |
❌ |
✅ |
有限 |
❌ |
*PaddleOCR需通过社区贡献或集成方案支持PDF
选择建议:Office文档密集→MinerU/TextIn;仅图片扫描件→PaddleOCR足够。
能力二:解析精度——谁更“可靠”?
|
测试维度 |
MinerU 2.5-Pro |
TextIn xParse |
PaddleOCR |
|
综合得分 |
95.69 (OmniDocBench) |
未公开benchmark(合同表格99%+) |
通用OCR场景95%+ |
|
表格解析 |
✅ 复杂表格、跨页合并 |
✅ 突破99%,含无线表格/密集少线表 |
基础表格 |
|
版面还原 |
✅ 标题层级、阅读顺序 |
✅ 文档树引擎,语义预测层级 |
基础版面分析 |
|
公式识别 |
✅ 印刷+手写→LaTeX |
✅ |
❌ |
|
输出结构化 |
Markdown/JSON |
Markdown/JSON(字段对齐+坐标溯源) |
文本为主 |
关键洞察:
● 学术/公式场景:MinerU的LaTeX输出无可替代
● 企业合同/表格场景:TextIn的99%+准确率+坐标溯源更可靠
● 通用OCR:PaddleOCR足够,但需接受5%左右的错误率
能力三:性能与规模化——谁能支撑“生产环境”?
|
性能指标 |
MinerU 2.5-Pro |
TextIn xParse |
PaddleOCR(自研封装) |
|
单文档响应 |
依赖部署环境 |
P99 ≤ 1.5秒 |
依赖封装质量 |
|
并发能力 |
开源方案需自建 |
高并发架构,百份文件无衰减 |
需二次开发 |
|
可用性SLA |
无(开源) |
99.9% |
无 |
|
批量处理案例 |
未知 |
日处理量提升5倍(客户实测) |
需自研运维 |
真实案例:某法律科技客户原方案日处理扫描文档不足千页,接入TextIn后日处理量提升5倍,知识库构建周期从数月缩短至数周。
能力四:集成与生态——谁更“开发者友好”?
|
集成方式 |
MinerU 2.5-Pro |
TextIn xParse |
PaddleOCR |
|
API |
✅ SaaS API |
✅ 标准REST API + SDK |
✅ 星河社区API |
|
开源框架 |
✅ 开源模型可本地部署 |
✅ MCP Server(一次开发适配所有大模型) |
✅ LangChain集成 |
|
低代码平台 |
❌ |
✅ Coze/Dify/HiAgent插件 |
✅ ClawMaster可视化工具 |
|
私有化部署 |
✅ 开源自行部署 |
✅ 企业级私有化(数据不出域) |
✅ 开源自行部署 |
六、应用场景:
不同工具的最佳战场场景一:
学术论文/科研文档解析
● 推荐工具:MinerU 2.5-Pro
● 理由:公式→LaTeX、跨页表格合并、手写体识别,完美适配arXiv、学术数据库
● 典型用户:研究生、科研机构、出版社
场景二:企业合同审查/法律科技产品
● 推荐工具:TextIn xParse
● 理由:99%+表格准确率、条款层级还原、坐标溯源、高并发稳定、私有化部署
● 典型用户:法律科技厂商、企业法务部、合同管理SaaS
● 客户案例:接入后数据处理效率提升5倍,项目整体进度提前3个月
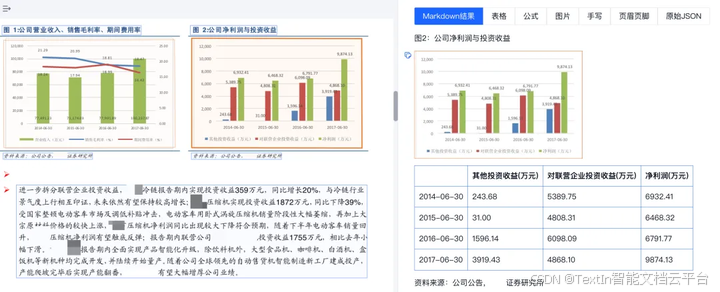
场景三:金融财报/供应链单据处理
● 推荐工具:TextIn xParse
● 理由:无线表格、密集少线表格、合并单元格识别突破99%,支持批量并发
● 典型用户:银行、保理公司、物流企业
场景四:通用OCR + 文档智能体原型验证
● 推荐工具:PaddleOCR + ClawMaster
● 理由:开源免费、10分钟跑通、与LangChain/OpenClaw深度集成,适合快速验证
● 典型用户:AI爱好者、创业团队、个人开发者
场景五:多语言/跨境贸易文档
● 推荐工具:TextIn xParse(支持50+种语言自动识别)
● 理由:中、英、德、日、法等多语言混排合同无需切换引擎
● 典型用户:跨国企业、报关行、外贸公司
七、总结
|
需求优先级 |
首选工具 |
次选方案 |
|
学术精度+公式识别 |
MinerU 2.5-Pro |
- |
|
企业级稳定+批量处理 |
TextIn xParse |
MinerU SaaS(轻量场景) |
|
开源免费+快速原型 |
PaddleOCR+ClawMaster |
MinerU开源版 |
|
数据安全+私有化部署 |
TextIn xParse(商业) |
MinerU开源版(自运维) |
|
低代码/零代码集成 |
TextIn xParse(插件) |
MinerU SaaS |
最后建议:如果您的业务处于PoC阶段,团队有充裕的研发资源愿意投入解析层优化,可以选择开源方案。
但如果您的产品已经进入或计划进入规模化商业交付阶段,一个生产级解析底座(如TextIn xParse)的价值在于:让研发团队从修解析bug中解放出来,专注打磨真正的产品差异化——无论是合同审查逻辑、用户体验,还是行业垂直模型。
正如AI合同审查领域的一个共识:“当所有厂商都能调用GPT-4、DeepSeek-R1时,产品的核心竞争力早已不是‘AI大脑’,而是‘数字手眼’——文档解析的完整性、准确性、流畅性。这是看不见,但客户感知最直接的分水岭。”

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 10
10 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)