【二值量化】Network Sketching: Exploiting Binary Structure in Deep CNNs 构建二值权重
网络素描:在深度卷积神经网络中利用二元结构
Abstract
具有深度架构的卷积神经网络(CNN)极大地推动了计算机视觉任务的最先进技术水平。然而,深度网络通常资源密集,因此在移动设备上部署困难。近年来,具有二值权重的 CNN 因其显著的效率优势引起了广泛关注,但在实际应用中,此类模型的准确性往往不尽如人意。在本文中,我们提出“网络素描”(network sketching)这一新技术,用于构建二值权重 CNN,旨在实现更准确的推理并在实际应用中取得更好的权衡效果。我们的基本思想是直接在预训练的滤波器组中利用二值结构,并通过张量扩张生成二值权重模型。整个过程可视为一种由粗到细的模型近似方法,类似于铅笔素描中先勾勒轮廓、后添加阴影的步骤。为了进一步加速生成的模型(即“素描”),我们还提出了一种二值张量卷积的关联实现方式。实验结果表明,在对 ImageNet 大规模分类任务中,经过适当处理的 AlexNet(或 ResNet)的素描模型在性能上大幅优于现有的二值权重模型,而用于存储网络参数的内存开销仅略有增加。
1. Introduction
近年来,研究者设计了具有二值权重的卷积神经网络(CNN)以解决这一问题。通过将连接权重限制为仅两个可能的值(通常为 +1 和 −1),研究人员试图消除网络推理过程中所需的浮点乘法运算(FMULs),因为这些操作被认为是计算成本最高的。此外,由于实值权重被转换为二值形式,这类网络在存储参数时所占空间大幅减少,从而显著降低了内存占用和能耗 [8]。已有多种方法被提出用于训练此类网络 [1, 2, 22]。然而,这些方法在大容量数据集(如 ImageNet)上所得模型的准确率尚不理想 [22]。更为严峻的是,简单地扩大网络宽度并不能保证准确率的提升 [14],因此,目前尚不清楚如何在这类方法中在模型精度与预期准确率之间取得平衡。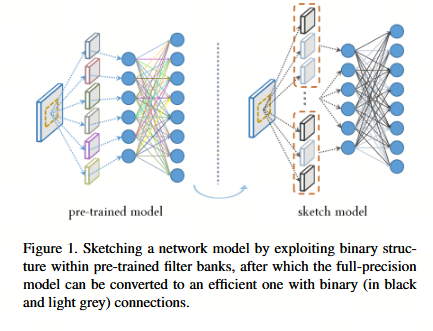
在本文中,我们提出网络素描(network sketching)作为一种追求二值权重卷积神经网络(CNNs)的新途径,其中二值结构被应用于预训练模型,而非从头开始训练。为了探索生成最先进模型的可能性,我们提出了两种具有理论依据的算法,使得能够通过调节素描的精度来实现更准确的推理。此外,为了进一步提升生成模型(即素描)的效率,我们还提出了一种算法,以关联方式实现二值张量卷积,从而同样减少了所需的浮点加减运算(FADDs)数量。实验结果表明,我们的方法在AlexNet和ResNet上都表现得极其出色。也就是说,仅需增加少量的FLOPs和内存占用,生成的素描便在性能上大幅超越了现有的二值权重AlexNet和ResNet,在ImageNet数据集上达到了接近最先进的识别准确率。
3. Network Sketching
一般而言,卷积层和全连接层是深度 CNN 中最耗资源的组件。幸运的是,两者均被认为是过度参数化的 [4, 30]。在本节中,我们阐述本方法的动机,并以卷积层为例介绍其实现细节。全连接层可采用类似的方式进行处理。
假设卷积层 L 的可学习权重可排列并表示为 {W(i) : 0 ≤ i < n},其中 n 表示目标特征图的数量,而 W(i) ∈ Rc×w×h 是其第 i 个滤波器的权重张量。存储所有这些权重需要 32 × c × w × h × n 比特的内存,而卷积的直接实现则需要 s × c × w × h × n 次浮点乘加运算(FMULs,伴随相同数量的浮点加法运算 FADDs),其中 s 表示目标特征图的空间尺寸。
由于许多卷积模型被认为存在信息冗余,因此有可能为其寻找低精度且紧凑的等效形式,以提升效率。基于这一考虑,我们通过采用分治策略,探索在 L 中利用二进制结构。我们首先用某些二进制基的线性张量来近似预训练的滤波器,然后将相同的基张量进行分组,以追求最大的网络效率。
3.1. 滤波器近似
如上所述,我们的第一个目标是寻找权值 W 的二进制展开,使其能够良好地近似 W(如图 2 所示),即 W≈⟨B,a⟩=∑j=0m−1ajBjW ≈ ⟨B, a⟩ = ∑_{j=0}^{m-1} a_j B_jW≈⟨B,a⟩=j=0∑m−1ajBj,其中 B∈+1,−1c×w×h×mB ∈ {+1, −1}^{c×w×h×m}B∈+1,−1c×w×h×m 和 a∈Rma ∈ R^ma∈Rm 分别是 m 个二进制张量 B0,...,Bm−1{B_0, ..., B_{m-1}}B0,...,Bm−1 和相同数量的尺度因子 a0,...,am−1{a_0, ..., a_{m-1}}a0,...,am−1 的拼接。在此,我们研究在固定 m 的情况下对 B 和 a 的合适选择。第 3.1.1 节和第 3.1.2 节分别提出了两种具有理论依据的算法。
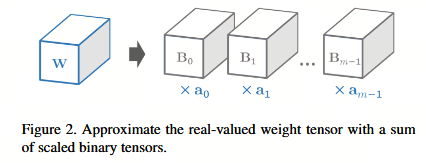
3.1.1 直接近似法
为了便于理解,我们首先介绍直接近似算法。一般而言,为了在展开后保持模型精度,应最小化重构误差(亦称近似误差、舍入误差)e2:=∥W−⟨B,a∥∥2e_2 := \|W - \langle B, a \|\|_2e2:=∥W−⟨B,a∥∥2。然而,作为一个具体的决策问题,直接最小化 e2e_2e2 似乎是 NP-hard 的,因此求解该问题可能非常耗时 [3]。为了在合理时间内完成计算,我们提出了一种启发式算法:在该算法中,BjB_jBj 和 aja_jaj 被依次学习,且每一次都根据 e2e_2e2 最小化准则将它们选为当前最优解。即,
Bj,aj=argminB∈B,a∈R∥W^j−aB∥2,(1) B_j, a_j = \arg \min_{B \in \mathcal{B}, a \in \mathbb{R}} \left\| \hat{W}_j - aB \right\|^2, \quad (1) Bj,aj=argB∈B,a∈Rmin W^j−aB 2,(1)
其中 B:={+1,−1}c×w×h\mathcal{B} := \{+1, -1\}^{c \times w \times h}B:={+1,−1}c×w×h,范数运算符 ∥⋅∥\|\cdot\|∥⋅∥ 对于任意三维张量 XXX 定义为 ∥X∥:=⟨X,X⟩1/2\|X\| := \langle X, X \rangle^{1/2}∥X∥:=⟨X,X⟩1/2,而 W^j\hat{W}_jW^j 表示合并所有此前生成的张量后的近似残差。特别地,若 j=0j = 0j=0,则 W^j=W\hat{W}_j = WW^j=W;若 j≥1j \ge 1j≥1,则
W^j=W−∑k=0j−1akBk(2) \hat{W}_j = W - \sum_{k=0}^{j-1} a_k B_k \quad (2) W^j=W−k=0∑j−1akBk(2)
容易通过导数计算得知,公式 (1) 等价于
Bj=sgn(W^j)且aj=⟨Bj,W^j⟩t(3) B_j = \text{sgn}(\hat{W}_j) \quad \text{且} \quad a_j = \frac{\langle B_j, \hat{W}_j \rangle}{t} \quad (3) Bj=sgn(W^j)且aj=t⟨Bj,W^j⟩(3)
算法 1:直接近似算法
- 输入: WWW:预训练的权重张量;mmm:所需的二进制基的基数。
- 输出: {Bj,aj:0≤j<m}\{B_j, a_j : 0 \le j < m\}{Bj,aj:0≤j<m}:一组二进制基及一系列缩放因子。
- 步骤:
- 初始化 j←0j \leftarrow 0j←0 且 W^j←W\hat{W}_j \leftarrow WW^j←W。
- 重复以下过程:
a. 通过公式 (3) 计算 BjB_jBj 和 aja_jaj。
b. 计算 W^j+1=W^j−ajBj\hat{W}_{j+1} = \hat{W}_j - a_j B_jW^j+1=W^j−ajBj 并更新 j←j+1j \leftarrow j + 1j←j+1。 - 直到 jjj 达到最大数量 mmm 为止。
在此情境下,函数 sgn(⋅)\text{sgn}(\cdot)sgn(⋅) 计算输入张量的逐元素符号,且 t=c×w×ht = c \times w \times ht=c×w×h。上述算法总结于算法 1 中。该算法被视为启发式(或贪婪)算法,因为每次选择 BjB_jBj 使其成为当前最优解,而不管其是否会排除后续更好的近似可能性。
此外,通过一些简单的推导可得如下理论结果。
定理 1: 对于任意 m≥0m \ge 0m≥0,算法 1 实现的满足重构误差 e2e_2e2 满足:
e2≤∥W∥2(1−1t)m.(4) e_2 \le \|W\|^2 \left(1 - \frac{1}{t}\right)^m. \quad (4) e2≤∥W∥2(1−t1)m.(4)
证明: 由于 Bj=sgn(W^j)B_j = \text{sgn}(\hat{W}_j)Bj=sgn(W^j),我们可以得出,
⟨Bj,W^j⟩=∑l∣w^j(l)∣≥∥W^j∥,(5) \langle B_j, \hat{W}_j \rangle = \sum_l |\hat{w}_j^{(l)}| \ge \|\hat{W}_j\|, \quad (5) ⟨Bj,W^j⟩=l∑∣w^j(l)∣≥∥W^j∥,(5)
其中 w^j\hat{w}_jw^j 是 W^j\hat{W}_jW^j 的一个元素,上标 (l)(l)(l) 表示其索引。由公式 (2) 和 (5),我们有
∥W^j+1∥2=∥W^j∥2−aj⟨Bj,W^j⟩=∥W^j∥2(1−⟨Bj,W^j⟩2t∥W^j∥2)≤∥W^j∥2(1−1t).(6) \begin{aligned} \|\hat{W}_{j+1}\|^2 &= \|\hat{W}_j\|^2 - a_j \langle B_j, \hat{W}_j \rangle \\ &= \|\hat{W}_j\|^2 \left( 1 - \frac{\langle B_j, \hat{W}_j \rangle^2}{t \|\hat{W}_j\|^2} \right) \\ &\le \|\hat{W}_j\|^2 \left(1 - \frac{1}{t}\right). \quad (6) \end{aligned} ∥W^j+1∥2=∥W^j∥2−aj⟨Bj,W^j⟩=∥W^j∥2(1−t∥W^j∥2⟨Bj,W^j⟩2)≤∥W^j∥2(1−t1).(6)
通过对 jjj 从 000 到 m−1m-1m−1 应用公式 (6),即可得到该结果。
3.1.2 带 refinements 的近似方法
从定理 1 可以看出,通过利用直接近似算法,重构误差 e2e_2e2 以与 1/t1/t1/t 成正比的速率指数级衰减。也就是说,给定一个尺寸较小(即 ttt 较小)的张量 WWW,算法 1 仅使用少量二元张量即可实现相当不错的近似效果。然而,当 ttt 相对较大时,重构误差下降缓慢,即使使用大量二元张量,近似效果也可能令人不满意。在本节中,我们提出对直接近似算法进行 refine(细化/精炼),以获得更好的重构性能。
算法 2 带细化的近似方法:
输入: WWW:预训练权重张量,mmm:二元基所需的基数(数量)。
输出: {Bj,aj:0≤j<m}\{B_j, a_j : 0 \le j < m\}{Bj,aj:0≤j<m}:一组二元基及一系列缩放因子。
初始化 j←0j \leftarrow 0j←0 且 W^j←W\hat{W}_j \leftarrow WW^j←W。
重复执行:
通过公式 (3) 和 (7) 计算 BjB_jBj 和 aja_jaj。
更新 j←j+1j \leftarrow j + 1j←j+1 并通过公式 (2) 计算 W^j\hat{W}_jW^j。
直到 jjj 达到其最大数量 mmm。
考虑到在算法 1 中,BjB_jBj 和 aja_jaj 是在固定对方的情况下被选择以最小化 e2e_2e2 的。然而,在大多数情况下,BBB 和 aaa 是否是整体最优的是值得怀疑的。如果不是,为了获得更好的近似效果,我们可能需要至少对其中一个进行 refine。出于计算简单性的考虑,我们转向 BBB 固定的特定情况。也就是说,假设直接近似已经产生了 B^\hat{B}B^ 和 a^\hat{a}a^,我们在此寻找另一个缩放向量 aaa,满足 ∥W−⟨B^,a⟩∥2≤∥W−⟨B^,a^⟩∥2\|W - \langle \hat{B}, a \rangle\|_2 \le \|W - \langle \hat{B}, \hat{a} \rangle\|_2∥W−⟨B^,a⟩∥2≤∥W−⟨B^,a^⟩∥2。为了实现这一点,我们遵循最小二乘回归法并得到:
aj=(BjTBj)−1BjT⋅vec(W),(7) a_j = (B_j^T B_j)^{-1} B_j^T \cdot \text{vec}(W), \quad (7) aj=(BjTBj)−1BjT⋅vec(W),(7)
其中,算子 vec(⋅)\text{vec}(\cdot)vec(⋅) 获取一个列向量,其元素取自输入张量,而 BjB_jBj 由 [vec(B0),...,vec(Bj)][\text{vec}(B_0), ..., \text{vec}(B_j)][vec(B0),...,vec(Bj)] 构成。
上述带有缩放因子细化的算法总结在算法 2 中。直观地说,细化操作赋予了我们的方法一种类似记忆的特性,而以下定理确保了与算法 1 相比,它收敛速度更快。
定理 2。 对于任意 m≥0m \ge 0m≥0,算法 2 实现的重构误差 e2e_2e2 满足:
e2≤∥W∥22∏j=0m−1(1−1t−λ(j,t)),(8) e_2 \le \|W\|_2^2 \prod_{j=0}^{m-1} \left( 1 - \frac{1}{t - \lambda(j, t)} \right), \quad (8) e2≤∥W∥22j=0∏m−1(1−t−λ(j,t)1),(8)
其中 λ(j,t)≥0\lambda(j, t) \ge 0λ(j,t)≥0,对于 0≤j≤m−10 \le j \le m - 10≤j≤m−1。
证明: 为简化符号表示,让我们进一步记 wj:=vec(Wj)w_j := \text{vec}(W_j)wj:=vec(Wj) 和 bj+1:=vec(Bj+1)b_{j+1} := \text{vec}(B_{j+1})bj+1:=vec(Bj+1),则我们可以通过分块矩阵乘法和逆运算得到:
(Bj+1TBj+1)−1=[Φ+ΦψψTΦ/r−Φψ/r−ψTΦ/r1/r],(9) (B_{j+1}^T B_{j+1})^{-1} = \begin{bmatrix} \Phi + \Phi \psi \psi^T \Phi / r & -\Phi \psi / r \\ -\psi^T \Phi / r & 1 / r \end{bmatrix}, \quad (9) (Bj+1TBj+1)−1=[Φ+ΦψψTΦ/r−ψTΦ/r−Φψ/r1/r],(9)
其中 Φ=(BjTBj)−1\Phi = (B_j^T B_j)^{-1}Φ=(BjTBj)−1,ψ=BjTbj+1\psi = B_j^T b_{j+1}ψ=BjTbj+1,且 r=bj+1Tbj+1−ψTΦψr = b_{j+1}^T b_{j+1} - \psi^T \Phi \psir=bj+1Tbj+1−ψTΦψ。因此,对于 j=0,...,m−1j = 0, ..., m - 1j=0,...,m−1,我们有以下方程:
wj+1=(I−Λ(bj+1bj+1T)bj+1TΛbj+1)wj,(10) w_{j+1} = \left( I - \frac{\Lambda (b_{j+1} b_{j+1}^T)}{b_{j+1}^T \Lambda b_{j+1}} \right) w_j, \quad (10) wj+1=(I−bj+1TΛbj+1Λ(bj+1bj+1T))wj,(10)
这里定义 Λ:=I−BjΦBjT\Lambda := I - B_j \Phi B_j^TΛ:=I−BjΦBjT。众所周知,给定半正定矩阵 XXX 和 YYY,有 tr(XY)≤tr(X)tr(Y)\text{tr}(XY) \le \text{tr}(X)\text{tr}(Y)tr(XY)≤tr(X)tr(Y)。于是,公式 (10) 给出:
∥W^j+1∥22≤∥W^j∥22−wjT(bj+1bj+1T)Λ(bj+1bj+1T)wj(bj+1TΛbj+1)2=∥W^j∥22−wjT(bj+1bj+1T)wjbj+1TΛbj+1=∥W^j∥22(1−⟨Bj,W^j⟩2bj+1TΛbj+1∥W^j∥22). \begin{aligned} \|\hat{W}_{j+1}\|_2^2 &\le \|\hat{W}_j\|_2^2 - \frac{w_j^T (b_{j+1} b_{j+1}^T) \Lambda (b_{j+1} b_{j+1}^T) w_j}{(b_{j+1}^T \Lambda b_{j+1})^2} \\ &= \|\hat{W}_j\|_2^2 - \frac{w_j^T (b_{j+1} b_{j+1}^T) w_j}{b_{j+1}^T \Lambda b_{j+1}} \\ &= \|\hat{W}_j\|_2^2 \left( 1 - \frac{\langle B_j, \hat{W}_j \rangle^2}{b_{j+1}^T \Lambda b_{j+1} \|\hat{W}_j\|_2^2} \right). \end{aligned} ∥W^j+1∥22≤∥W^j∥22−(bj+1TΛbj+1)2wjT(bj+1bj+1T)Λ(bj+1bj+1T)wj=∥W^j∥22−bj+1TΛbj+1wjT(bj+1bj+1T)wj=∥W^j∥22(1−bj+1TΛbj+1∥W^j∥22⟨Bj,W^j⟩2).
显然,由此可得:
∥W^j+1∥22≤∥W^j∥22(1−1/(t−λ(j,t))),(11) \|\hat{W}_{j+1}\|_2^2 \le \|\hat{W}_j\|_2^2 (1 - 1/(t - \lambda(j, t))), \quad (11) ∥W^j+1∥22≤∥W^j∥22(1−1/(t−λ(j,t))),(11)
其中 λ(j,t):=bj+1T(I−Λ)bj+1\lambda(j, t) := b_{j+1}^T (I - \Lambda) b_{j+1}λ(j,t):=bj+1T(I−Λ)bj+1。由于 λ(j,t)\lambda(j, t)λ(j,t) 代表 bj+1b_{j+1}bj+1 的正交投影的平方欧几里得范数,不难证明 λ(j,t)≥0\lambda(j, t) \ge 0λ(j,t)≥0,从而得出上述结果。
3.2. 几何解释
在对预训练滤波器进行扩展之后,我们可以将相同的二值张量进行分组,从而进一步节省内存占用。在本文中,我们将整个技术命名为网络草绘(network sketching),并将生成的二值权重模型直接称为草绘(sketch)。接下来,我们将从几何角度对草绘过程进行解释。
首先,我们需要认识到,公式(1)本质上是在寻找由一组 t 维二值向量张成的线性子空间,以最小化该子空间与 vec(W) 之间的欧几里得距离。从概念上讲,该问题中存在两个需要确定的变量。算法 1 和算法 2 均采用启发式方法求解此问题,并且第 j 个二值向量始终通过最小化其自身与当前近似残差之间的距离来估计。二者之间的区别在于:算法 2 利用了其前 j−1 次估计的线性张成空间以获得更好的近似效果,而算法 1 则未利用这一点。
现在我们仔细考察定理 2。与定理 1 中的公式(4)相比,公式(8)的主要区别在于 λ(j, t) 的存在。显然,只要对于任意 j ∈ [0, m−1] 都有 λ(j, t) > 0 成立,算法 2 的收敛速度就会快于算法 1。
从几何角度来看,如果我们将 Bj(BjTBj)−1BjTB_j (B_j^T B_j)^{-1} B_j^TBj(BjTBj)−1BjT 视为向 Sj:=span(b0,...,bj)S_j := span(b_0, ..., b_j)Sj:=span(b0,...,bj) 的正交投影矩阵,那么 λ(j, t) 等于某个向量投影的欧几里得范数的平方。因此,λ(j, t) = 0 当且仅当向量 bj+1b_{j+1}bj+1 与 SjS_jSj 正交,换句话说,bj+1b_{j+1}bj+1 与集合 b0,...,bj{b_0, ..., b_j}b0,...,bj 中的每个元素都正交。这种情况发生的概率极低,且仅在 t∈2k:k∈Nt ∈ {2^k : k ∈ N}t∈2k:k∈N 的条件下才可能出现。因此,在实际应用中,算法 2 很可能优于算法 1。
4. 加速草图模型
利用算法1或算法2,可以方便地获得L上的一组mn个二元张量,这意味着可学习权重的存储需求降低为原来的32t/(32m+tm)倍。在应用模型时,所需的浮点乘法运算(FMULs)数量也显著减少,降低为原来的(t/m)倍。草图方法可能带来的唯一副作用是浮点加法运算(FADDs)数量的某些增加,因为它给计算单元带来了额外的负担。 在本节中,我们尝试改进这一缺陷,并引入一种进一步加速二元权重网络的算法。我们从一个观察出发:尽管所需的浮点加法运算数量随m单调增长,但对于给定的L输入,被加数和加数的固有数量始终保持固定。也就是说,在二元张量卷积的直接实现中存在重复的浮点加法运算。令X ∈ Rc×w×h表示输入子特征图,图3给出了示意图。
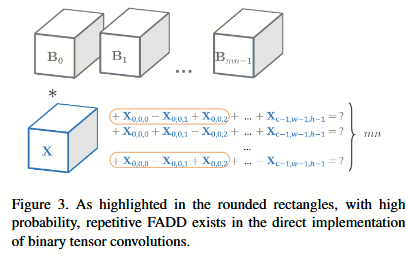
4.1. 关联性实现
为了避免冗余操作,我们首先提出一种在集合 LLL 上对多个卷积 X∗B0,…,X∗Bmn−1X * B_0, \dots, X * B_{mn-1}X∗B0,…,X∗Bmn−1 进行计算的关联性实现方法,其中充分利用了不同卷积之间的联系。具体来说,我们的策略是以分层且渐进的方式执行卷积。也就是说,每个卷积结果都作为后续计算的基准。假设第 j0j_0j0 个卷积已预先计算得出,并产生结果 X∗Bj0=sX * B_{j_0} = sX∗Bj0=s,则 XXX 与 Bj1B_{j_1}Bj1 的卷积可以通过以下公式推导得出:
X∗Bj1=s+(X∗(Bj0∘Bj1))×2,(12) X * B_{j_1} = s + (X * (B_{j_0} \circ B_{j_1})) \times 2, \quad (12) X∗Bj1=s+(X∗(Bj0∘Bj1))×2,(12)
或者 alternatively:
X∗Bj1=s−(X∗(¬Bj0∘Bj1))×2,(13) X * B_{j_1} = s - (X * (\neg B_{j_0} \circ B_{j_1})) \times 2, \quad (13) X∗Bj1=s−(X∗(¬Bj0∘Bj1))×2,(13)
其中 ¬\neg¬ 表示逐元素非运算,∘\circ∘ 表示逐元素运算符,其行为如表 1 所示。
表 1. 逐元素运算符 ∘\circ∘ 的真值表
| Bj1B_{j_1}Bj1 | Bj2B_{j_2}Bj2 | Bj1∘Bj2B_{j_1} \circ B_{j_2}Bj1∘Bj2 |
|---|---|---|
| +1 | -1 | -1 |
| +1 | +1 | 0 |
| -1 | -1 | 0 |
| -1 | +1 | +1 |
由于 Bj0∘Bj1B_{j_0} \circ B_{j_1}Bj0∘Bj1 在每个索引位置上产生三值输出,我们可以自然地将 X∗(Bj0∘Bj1)X * (B_{j_0} \circ B_{j_1})X∗(Bj0∘Bj1) 视为一系列 switch ... case ... 语句的迭代。通过这种方式,只需对 Bj0∘Bj1B_{j_0} \circ B_{j_1}Bj0∘Bj1 中对应于 ±1\pm 1±1 的 XXX 中的条目进行操作,从而获得加速效果。假设 Bj0B_{j_0}Bj0 与 Bj1B_{j_1}Bj1 的内积等于 rrr,则计算公式 (12) 和 (13) 分别仍需要 (t−r)/2+1(t - r)/2 + 1(t−r)/2+1 和 (t+r)/2+1(t + r)/2 + 1(t+r)/2+1 次浮点加法运算(FADDs)。显然,我们希望实数 r∈[−t,+t]r \in [-t, +t]r∈[−t,+t] 接近 ttt 或 −t-t−t 的某个值,以便减少 FADD 次数,从而在我们的实现中获得更快的卷积速度。特别地,如果 r≥0r \geq 0r≥0,为了获得更好的效率,选择公式 (12);否则,应选择公式 (13)。
4.2. 构建依赖树
我们的实现通过适当重新排列二进制张量,并以间接方式实现二进制张量卷积来工作。因此,除了公式 (12) 和 (13) 之外,还需要一棵依赖树来驱动整个流程。特别地,依赖关系是指某些二进制张量之间的链接关系,用于指定首先执行哪个卷积,以及随后执行哪些卷积。例如,采用深度优先搜索策略,图 4 中的树 TTT 显示了一棵依赖树,表明首先计算 X∗B1X * B_1X∗B1,然后从前一个结果推导 X∗B0X * B_0X∗B0,接着以 X∗B0X * B_0X∗B0 为基础计算 X∗B3X * B_3X∗B3,依此类推。通过遍历整棵树,所有 mnmnmn 个卷积将被渐进且高效地计算出来。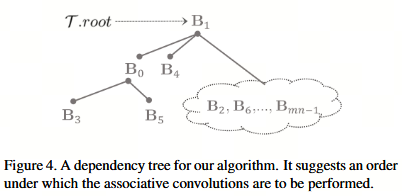
事实上,我们的算法能够处理随机生成的树,但为了获得最优性能,仍需针对特定场景构建专用的依赖树 TTT。令 G=(V,E)G = (V, E)G=(V,E) 为一个无向加权图,其中 VVV 为顶点集,E∈Rmn×mnE \in \mathbb{R}^{mn \times mn}E∈Rmn×mn 为权重矩阵。VVV 中的每个元素代表一个单一的二阶张量,而 EEE 中的元素则用于度量所选两个张量之间的距离。
算法 3 关联式实现:
- 输入: {Bj:0≤j<mn}\{B_j : 0 \le j < mn\}{Bj:0≤j<mn}:二阶张量集合;XXX:输入子特征图;TTT:依赖树。
- 输出: {yj:0≤j<mn}\{y_j : 0 \le j < mn\}{yj:0≤j<mn}:卷积运算的结果。
获取 z=T.rootz = T.\text{root}z=T.root,并计算 yz.key=X∗Bz.keyy_{z.\text{key}} = X * B_{z.\text{key}}yz.key=X∗Bz.key。
通过 s←yz.keys \leftarrow y_{z.\text{key}}s←yz.key 初始化基线值。
重复
搜索 TTT 的下一个节点并更新 zzz 和 sss。
利用公式 (12) 或 (13) 计算 yz.keyy_{z.\text{key}}yz.key。
直到 搜索结束。
为与前一小节保持一致,此处定义距离函数如下:
d(Bj0,Bj1):=min(t+r2,t−r2),(14) d(B_{j_0}, B_{j_1}) := \min \left( \frac{t+r}{2}, \frac{t-r}{2} \right), \quad (14) d(Bj0,Bj1):=min(2t+r,2t−r),(14)
其中 r=⟨Bj0,Bj1⟩r = \langle B_{j_0}, B_{j_1} \rangler=⟨Bj0,Bj1⟩ 表示 Bj0B_{j_0}Bj0 和 Bj1B_{j_1}Bj1 的内积。显然,所定义的函数是定义在 {−1,+1}c×w×h\{-1, +1\}^{c \times w \times h}{−1,+1}c×w×h 上的度量函数,其取值范围限制在 [0,t][0, t][0,t]。回顾前一小节可知,我们期望 rrr 的值接近 ±t\pm t±t。因此,最优的依赖树应具备从根节点到其任意顶点的距离最短这一特性,故图 GGG 的最小生成树(MST)即为我们所求。
从这一视角出发,我们可以利用现成的算法来构建此类树。本文选择 Prim 算法 [21],原因之一是其时间复杂度关于边数 ∣E∣|E|∣E∣ 呈线性关系,即在 LLL 上的复杂度为 O(m2n2)O(m^2n^2)O(m2n2)。在获得 TTT 之后,便很容易实现我们的算法,整个过程总结于算法 3 中。需要注意的是,虽然全连接层执行的是向量-矩阵乘法,但可将其视为一系列张量卷积。因此,在二进制情况下,我们也可以借助算法 3 在全连接层实现加速。
6. 结论
在本文中,我们引入(network sketching)作为实现二进制权重卷积神经网络(CNN)的一种新颖技术。该技术相较于现有方法具有更高的灵活性,使研究人员和工程师能够调控所生成速写的精度,从而在模型效率与准确性之间获得更优的权衡。我们通过理论分析与实证分析验证了其有效性。此外,我们还提出了一种关联式实现方案,用于加速二进制张量卷积,进一步提升速写的执行速度。经过上述努力,我们成功生成了二进制权重的 AlexNet 和 ResNet 模型,能够在 ImageNet 分类任务上实现既高效又忠实(高保真)的推理。未来的工作将包括探索其他 CNN 架构的速写结果。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 0
0 0
0- 0



 已为社区贡献34条内容
已为社区贡献34条内容

所有评论(0)