从零搭建 RAG 知识库:让大模型读懂你的私有数据(上篇)
·
👨 作者简介:大家好,我是唐璜Taro,全栈 领域创作者
✒️ 个人主页 :唐璜Taro
🚀 支持我:点赞👍+📝 评论 + ⭐️收藏
让大模型读懂你的私有数据
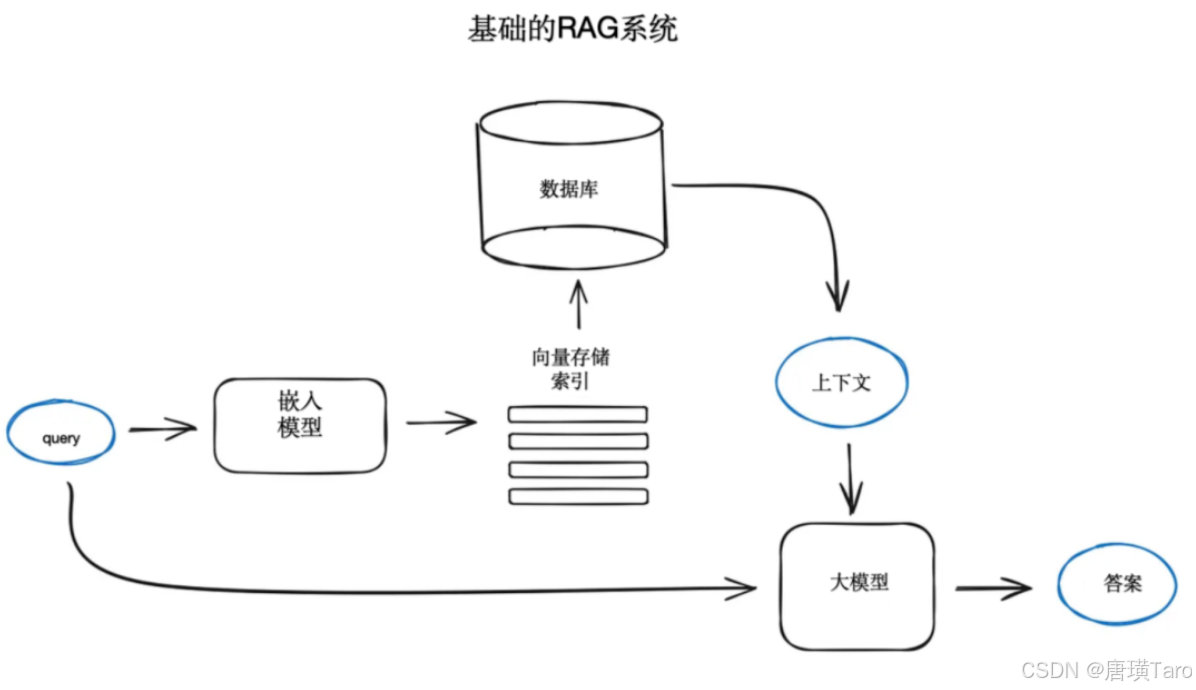
大模型很强大,但它不认识你的内部文档。RAG(Retrieval-Augmented Generation)就是解决这个问题的方案——先检索,再生成,让大模型基于你的数据精准回答。
一、什么是 RAG?
1.1 为什么需要 RAG?
直接用大模型的痛点:
- 知识截止日期:模型不知道训练数据之后发生的事
- 私有数据盲区:公司内部文档、个人笔记,模型从未见过
- 幻觉问题:不确定时会编造答案
1.2 RAG 的核心思想
传统方式: 用户提问 → 大模型 → 回答(可能瞎编)
RAG 方式: 用户提问 → 检索相关文档 → 文档 + 问题 → 大模型 → 回答(有据可依)
一句话:先找到相关资料,再让模型基于资料回答。
1.3 RAG vs 微调 vs 长上下文
| 方案 | 原理 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| RAG | 检索 + 生成 | 成本低、数据可实时更新、可溯源 | 依赖检索质量 | 企业知识库、客服系统 |
| 微调 | 用数据训练模型 | 模型内化知识,响应快 | 成本高、数据更新需重新训练 | 特定风格/格式生成 |
| 长上下文 | 把所有内容塞进 Prompt | 实现简单 | Token 费用高、有长度上限 | 短文档问答 |
二、整体架构
┌─────────────────────────────────────────────────────┐
│ 离线阶段(建库) │
│ │
│ 文档 → 文本提取 → 分块(Chunking) → 向量化(Embedding) │
│ ↓ │
│ 向量数据库存储 │
└─────────────────────────────────────────────────────┘
┌─────────────────────────────────────────────────────┐
│ 在线阶段(问答) │
│ │
│ 用户提问 → 问题向量化 → 向量检索(相似文档 Top-K) │
│ ↓ │
│ Prompt 模板(问题 + 检索结果) → 大模型 │
│ ↓ │
│ 生成回答 │
└─────────────────────────────────────────────────────┘
三、环境准备
3.1 技术栈选型
| 组件 | 选型 | 说明 |
|---|---|---|
| 编排框架 | LangChain | RAG 流程编排,生态成熟 |
| Embedding | BAAI/bge-small-zh-v1.5 | 开源中文模型,免费本地运行 |
| 向量数据库 | Chroma | 轻量级,零配置,适合学习 |
| 大模型 | DeepSeek | 便宜好用的国产模型 |
| Python | 3.10+ | 推荐用 Conda 管理环境 |
3.2 安装依赖
# 创建虚拟环境
conda create -n rag python=3.10 -y
conda activate rag
# 安装核心依赖
pip install langchain langchain-community langchain-openai
pip install sentence-transformers chromadb
pip install unstructured pypdf docx2txt # 文档解析
pip install tiktoken # Token 计算
3.3 准备 DeepSeek API Key
- 注册 DeepSeek 开放平台
- 创建 API Key
- 余额充值(几块钱够用很久)
后续:从零搭建 RAG 知识库:让大模型读懂你的私有数据(下篇)
学习路线建议
- 先跑通 — 用 LangChain + Chroma + DeepSeek 跑一个最小 demo
- 优化检索 — 试不同的 chunk_size、overlap、Top-K 值
- 混合检索 — 关键词检索(BM25)+ 向量检索结合,效果更好
- 进阶 — 多轮对话、引用来源标注、Rerank 重排序
文章总结:
先把最小 demo 跑通,再逐步优化分块策略、检索方式和 Prompt 模板。RAG 的效果 80% 取决于数据处理和检索质量,而不是模型本身。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 10
10 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)