调用深度求索实现多语言翻译
1.作者介绍
魏博腾,男,西安工程大学电子信息学院,2025级研究生
研究方向:图像生成
电子邮件:463301578@qq.com
程锡贵,男,西安工程大学电子信息学院,2025级研究生,张宏伟人工智能题组
研究方向:机器视觉与人工智能
电子邮件:15327178796@163.com
2.关于理论方面的知识介绍(DeepSeek-V4模型底层架构)
2.1 模型整体定位与极高能效比
DeepSeek-V4 是新一代超大规模混合专家 (MoE) 语言模型。其核心优势在于用极低的算力成本,实现了极高的智力水平和原生 100 万 Token 的超长文本处理能力。该模型总参数量高达 1.6T(万亿),但得益于先进的细粒度路由机制,单次推理仅激活 49B(十亿)参数。在百万级上下文场景下,其单 Token 推理计算量仅为前代的 27%,KV 缓存占用仅为 10%。
2.2 底层架构的三大核心物理重构
DeepSeek 并没有沿用传统的 Transformer 架构,而是对其最核心的三个模块进行了革命性的物理重构:
DeepSeekMoE (细粒度混合专家): 替代了传统的全连接层(FFN)。它将庞大的网络切分成数千个微型专家,并设置了一个常驻的“共享专家”处理通用语法常识。这实现了计算量与参数量的彻底解绑,实现了智能分诊式的极其省电的高效推理。
MTP (多 Token 并联预测): 打破了传统模型“单向串行输出”的物理瓶颈。在顶层搭建了多个并联输出头,在预测当前词的同时,并行预测后续的多个词,成倍提升了生成速度与逻辑连贯性。
无辅助损失的负载均衡: 摒弃了传统模型会损害“智商”的惩罚函数,采用纯调度的算法让所有专家满负荷工作,实现了“既要负载均衡,又不损害模型性能”。
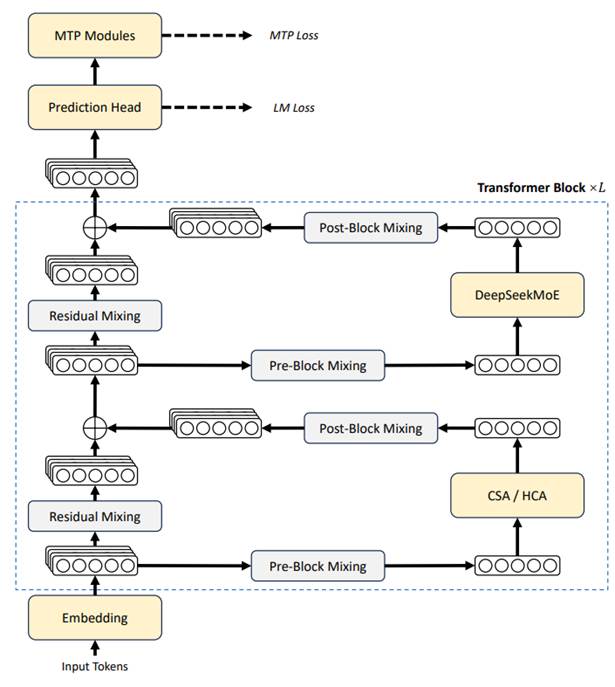
DeepSeek-V4整体框架
2.3 长文本处理核心:混合压缩注意力机制
面对长文本容易导致的显存溢出(OOM)问题,DeepSeek-V4 采用了两种混合注意力机制交替叠加,其本质类似于计算机视觉中的特征降维与池化提取:
CSA(压缩稀疏注意力): 负责“微观细节的精准检索”。它通过词级压缩器将冗长的历史信息压缩成潜在记忆块。查询时,利用“闪电索引器”从海量记忆中只挑出最相关的 Top-k 个片段,保留了对高频细节的精准匹配。
HCA(重度压缩注意力): 负责“宏观语境的全局感知”。它采用极大的压缩率将大量信息浓缩成精简的向量,不再进行稀疏检索,而是让浓缩向量全部参与计算,保证模型不会偏离全文的大方向。
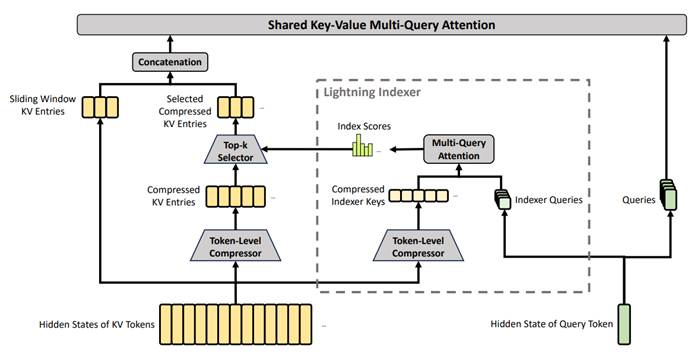 CSA机制结构图
CSA机制结构图
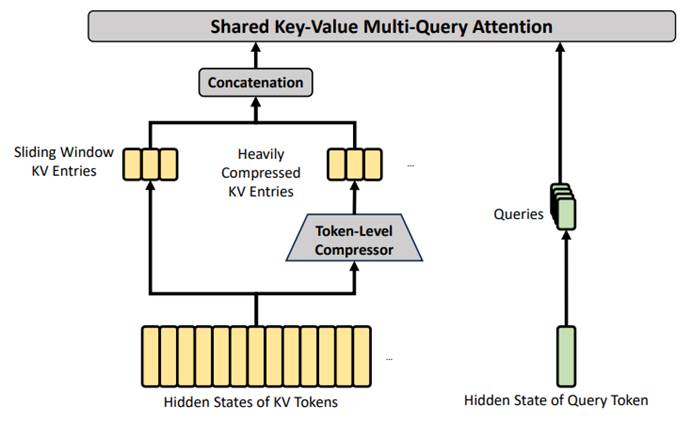
HCA机制结构图
2.4 API key获取
进入deep seek的api开放平台(https://platform.deepseek.com/usage)
点击左侧菜单栏的API keys
进入后点击创建API key
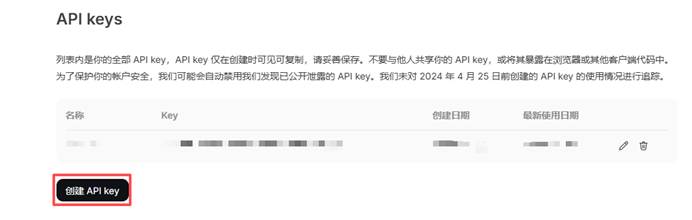
输入名称后完成API key的创建,注意复制保存创建好的API key,如果此时没保存好将无法再复制API key,需要重新创建。

3.关于实验过程的介绍,完整实验代码,测试结果
3.1 实验环境准备与数据集介绍
本实验旨在构建一个可视化的 DeepSeek 多语言翻译评测平台。
准备与安装的软件包: 实验环境需要 Python 3.8+,并安装以下核心依赖库:pip install gradio pandas openai datasets。(各依赖库的版本无特殊要求,安装新版本即可),以下是作者相关依赖版本参考:
python==3.10.0
gradio==6.14.0
pandas==2.3.3
openai==2.36.0
datasets==4.8.5
实验使用的数据集(双轨评测标准):
OPUS-100(多领域日常文本): 涵盖开源多领域(电影字幕、IT 文档等)语料。本实验提取其测试集,以短句和口语为主,用于验证模型处理日常沟通的“接地气”程度。
FLORES-200(高质量长句): 由 Meta AI 发布的机器翻译评估“金标准”。语料源自维基百科并经专业人工精修,用于测试模型处理复杂从句、专业术语的“专业能力上限”。
3.2 完整实验代码
以下为本评测平台的完整核心代码,包含了网络环境防御、UI 宽度自适应以及规避安全封杀的底层架构重构:
import os
import random
import json
import pandas as pd
import gradio as gr
from openai import OpenAI
from datasets import load_dataset
# 1. 网络防御与环境配置
# 重要提醒:强制屏蔽本地代理拦截,解决网页端 502 Bad Gateway 报错
os.environ['no_proxy'] = 'localhost, 127.0.0.1, ::1'
# 强制设定 HuggingFace 走国内镜像,解决数据集拉取超时问题
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
# API 密钥配置 (实验用)
API_KEY = "sk-xxxxxxxxxxxxxxxxxxxx"
# 2. 语言与数据集路由字典配置
LANGUAGE_MAPPING = {
"简体中文": "Simplified Chinese", "英语": "English", "日语": "Japanese",
"韩语": "Korean", "法语": "French", "德语": "German"
}
LANG_CHOICES = list(LANGUAGE_MAPPING.keys())
FLORES_MAP = {"简体中文": "zho_Hans", "英语": "eng_Latn", "日语": "jpn_Jpan", "韩语": "kor_Hang", "法语": "fra_Latn", "德语": "deu_Latn"}
OPUS_MAP = {"简体中文": ("en-zh", "zh"), "英语": ("en", "en"), "日语": ("en-ja", "ja"), "韩语": ("en-ko", "ko"), "法语": ("en-fr", "fr"), "德语": ("de-en", "de")}
# 3. 数据集自动测评引擎核心逻辑
def run_dataset_test(dataset_name, target_lang_zh, num_samples, progress=gr.Progress()):
samples = []
progress(0, desc="正在通过国内镜像极速下载数据...")
try:
if "FLORES-200" in dataset_name:
lang_code = FLORES_MAP.get(target_lang_zh)
if target_lang_zh == "英语": return pd.DataFrame(), "测试无意义。"
# 核心重构:使用纯 Parquet 格式的第三方镜像,避开 HF 官方对 .py 脚本的安全封杀
ds_en = load_dataset("tomasmajercik/flores-parquet", "eng_Latn", split="validation")
ds_tgt = load_dataset("tomasmajercik/flores-parquet", lang_code, split="validation")
# 使用 random.sample 实现真正的每次随机抽取
total_rows = len(ds_en)
indices = random.sample(range(total_rows), min(num_samples, total_rows))
for idx in indices:
samples.append({"源语言(English)": ds_en[idx]["sentence"], "官方参考译文": ds_tgt[idx]["sentence"]})
elif "OPUS-100" in dataset_name:
config_name, lang_code = OPUS_MAP.get(target_lang_zh)
if target_lang_zh == "英语": return pd.DataFrame(), "测试无意义。"
ds = load_dataset("opus100", config_name, split="test")
ds = ds.shuffle(seed=random.randint(1, 100000)).select(range(min(num_samples, len(ds))))
for item in ds:
samples.append({"源语言(English)": item["translation"]["en"], "官方参考译文": item["translation"][lang_code]})
except Exception as e:
return pd.DataFrame(), f"❌ 数据集加载失败: {str(e)}"
# 4. 调用大模型 API 进行批量评测
client = OpenAI(api_key=API_KEY, base_url="https://api.deepseek.com")
target_lang_en = LANGUAGE_MAPPING.get(target_lang_zh, "English")
system_prompt = f"Translate the following text into {target_lang_en}. Return ONLY the translated text."
for i, item in enumerate(progress.tqdm(samples, desc="🚀 正在调用 DeepSeek 进行翻译...")):
try:
response = client.chat.completions.create(
model="deepseek-v4-pro",
messages=[{"role": "system", "content": system_prompt}, {"role": "user", "content": item["源语言(English)"]}],
temperature=0.3
)
item["DeepSeek 机器翻译"] = response.choices[0].message.content.strip()
except Exception as e:
item["DeepSeek 机器翻译"] = f"请求失败: {str(e)}"
return pd.DataFrame(samples), f"✅ 测试完成!共处理 {len(samples)} 条数据。"
# 5. 构建响应式前端界面
with gr.Blocks(title="DeepSeek 智能评测台") as app:
gr.Markdown("# 🌐 DeepSeek 智能多语言翻译评测台")
with gr.Tabs():
with gr.TabItem("📊 真实数据集直连评测"):
with gr.Row():
with gr.Column(scale=2):
dataset_choice = gr.Radio(choices=["OPUS-100 (多领域日常文本)", "FLORES-200 (高质量长句)"], value="OPUS-100 (多领域日常文本)", label="1. 选择评测基准")
with gr.Column(scale=1):
target_lang_ds = gr.Dropdown(choices=LANG_CHOICES, value="简体中文", label="2. 选择目标语言")
with gr.Column(scale=2):
sample_size = gr.Slider(minimum=1, maximum=50, value=5, step=1, label="3. 抽取样本数量")
with gr.Column(scale=1):
ds_translate_btn = gr.Button("⬇️ 一键拉取并评测", variant="primary")
ds_status = gr.Textbox(label="执行状态", interactive=False)
with gr.Row():
# 强制列宽均为33%,完美触发长文本自动换行以方便对比
result_table = gr.Dataframe(headers=["源语言(English)", "官方参考译文", "DeepSeek 机器翻译"], wrap=True, column_widths=["33%", "33%", "33%"])
ds_translate_btn.click(fn=run_dataset_test, inputs=[dataset_choice, target_lang_ds, sample_size], outputs=[result_table, ds_status])
if __name__ == "__main__":
app.launch(server_name="127.0.0.1", server_port=7860, share=False)3.3 测试结果展示
通过上述代码成功搭建本地 Web 应用界面。进行多语言评测时,页面可自动实现三列等宽分布与自动换行,直观展示出 DeepSeek 在翻译长难句时优异的逻辑把控与词汇准确度。
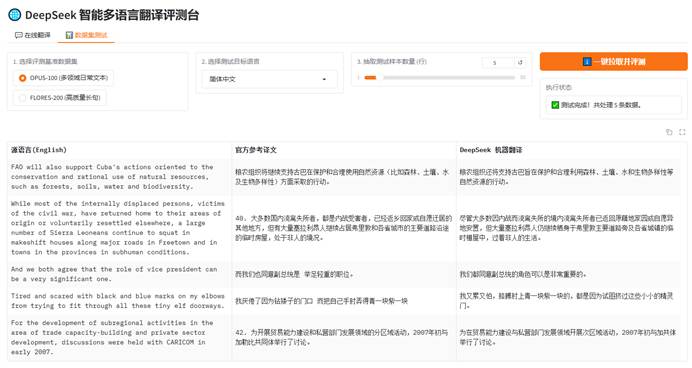
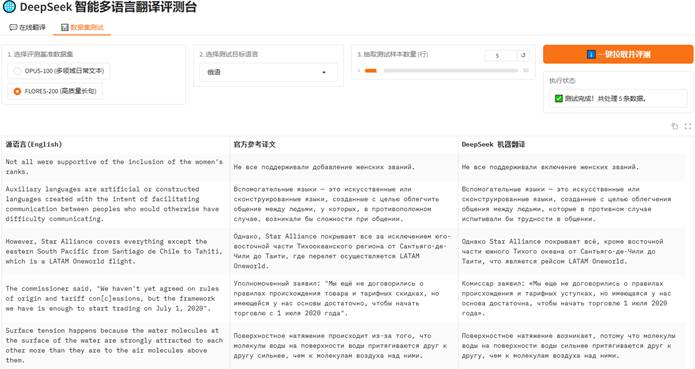
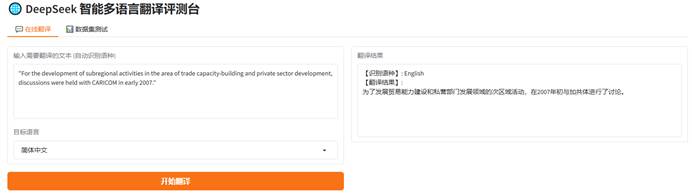
3.4 实验问题记录与深入分析
在本次实验开发中,遭遇了非常典型的问题,经过原理排查均已妥善解决:
本地代理与框架路由冲突:
现象: 开启网络代理时,Gradio 界面报错 502 Bad Gateway。
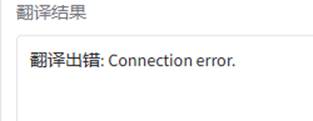
分析: 代理软件自动拦截了发往本地 127.0.0.1 的内部测试流量。
解决: 在代码顶端写入 os.environ['no_proxy'] = 'localhost, 127.0.0.1, ::1',建立网络自适应保护机制,强制本地流量直连。
底层库安全策略封杀:
现象: 拉取 FLORES-200 数据集时抛出严重错误:Dataset scripts are no longer supported。

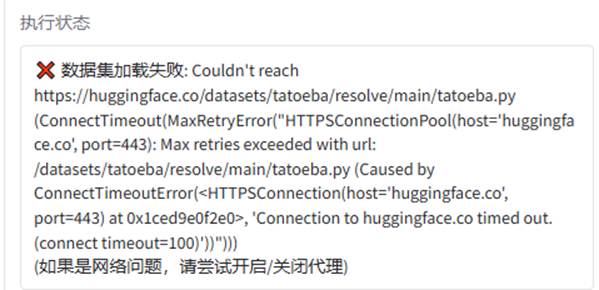
分析: Hugging Face 最新的 datasets 库为了防范恶意远程代码执行攻击,物理封杀了所有基于 Python 脚本 (.py) 的数据集加载方式,而官方旧数据源仍在使用废弃格式。
解决: 摒弃危险旧脚本,在代码层面将数据源重构指向纯 Parquet 数据格式的第三方安全镜像。这不仅完美绕过了安全限制,还大幅提升了二维表数据的拉取速度。
4.参考链接
(1)DeepSeek-V4 Technical Report (Hugging Face 官网发布): https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro
(2)Meta AI FLORES-200 评估基准白皮书: https://github.com/facebookresearch/flores
(3)Hugging Face Datasets 官方文档及安全更新说明: https://huggingface.co/docs/datasets/
(4)OPUS-100 多语言平行语料库: https://opus.nlpl.eu/opus-100.php

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)