Realtime-VLA V2——如何让vla运行的更快:从让π0实时抓取下落的钢笔到让 VLA 运行得更快、更平滑且更精确
前言
今天在朋友圈刷到一则新闻,称《开普勒机器人被A股公司收购,前任CEO已离职创业》
我仔细看了全文,还是多有感慨
- 其实对双足,3-5家今年可继续卷跳舞 跑步 打拳及比赛/陪练(乒乓球/网球/羽毛球等)
而3-5家之外的双足,得另寻他路,比如展厅讲解及接待
至于双足落地工厂的话,不好说,毕竟按照我们过去一年平均一月去3个工厂的经验,这一两年 双足在工厂还难以大规模智能落地,得先靠机械臂和轮式
————
且之前说,让工厂从自动化升级到智能化,然我司做深了会发现,先不要急着代替已经成熟十年的自动化,而是让智能化先做好补充,做纯工业自动化做不了的事情 - 追求资本认可不应该成为创业者的唯一或第一追求,社会认可 行业认可 客户认可 › 资本认可
有前者,必有后者,有后者 不一定有前者
真正推动社会生产力进步,才不枉今好时代
大规模批量卖机器 确实性感,利润高 可复制 赚钱多,这没有问题
但我个人还是觉得:让一台台机器人真正在工厂里跑起来,更sexy、更有价值
毕竟如果不持续月月跑起来、用起来,只是图一时新鲜,那一万台机器人就是一万个废铁,对社会有啥用呢
总之,现在各种吹的太多了,务实更好
正因为以上种种,使得我对基于机械臂和轮式的paper,比去年更关注了,比如本文介绍的Realtime-VLA
第一部分 以实时速度运行VLA
在本第一部分中,作者展示了如何仅使用一块消费级GPU,以 30Hz 的帧率和最高 480Hz 的轨迹频率运行 π0 级别的多视角 VLA。这使得此前被认为大型 VLA 模型无法实现的动态、实时任务成为可能
为此,作者提出了一系列策略,用于消除模型推理中的各种开销。真实环境实验表明,采用作者策略“Running VLAs at Real-time Speed”的 π0 策略在抓取下落钢笔任务中达到了100% 的成功率
基于上述结果,作者进一步提出了一个用于实时机器人控制的 VLA 全流式推理框架
1.1 引言与π0 级别模型预备知识
1.1.1 引言
基于学习的机器人控制算法正日益盛行,尤其是拥有数十亿参数的VLA 模型[2, 3, 16, 18]。尽管它们具有令人印象深刻的泛化能力,这些模型仍面临时延问题。许多现实世界任务,如抓取移动物体,往往需要快速反应时间
然而,VLA 模型的一次前向传播通常需要数百毫秒,阻碍了人们对动态机器人所期望的快速反应。而运行时间少于 33 毫秒(约 1/30 秒)是实现实时操作的转折点——这意味着每秒 30 帧的 RGB 视频流的所有帧都能被完全处理
即使达到了 34 ms,在连续运行过程中作者也必须时不时丢弃一些帧。如果需要检测的事件恰好发生在被丢弃的那一帧上,那么整体延迟就会增加整整一个帧周期
在本文中,作者作出了一个关键观察:VLAs 实际上完全可以在单张消费级 RTX 4090 GPU 上实现实时运行。经过作者的优化,在输入两个视角的情况下,推理延迟仅为 27.3 毫秒,比 openpi[2] 项目提供的“官方”推理速度显著更快(见表 1)
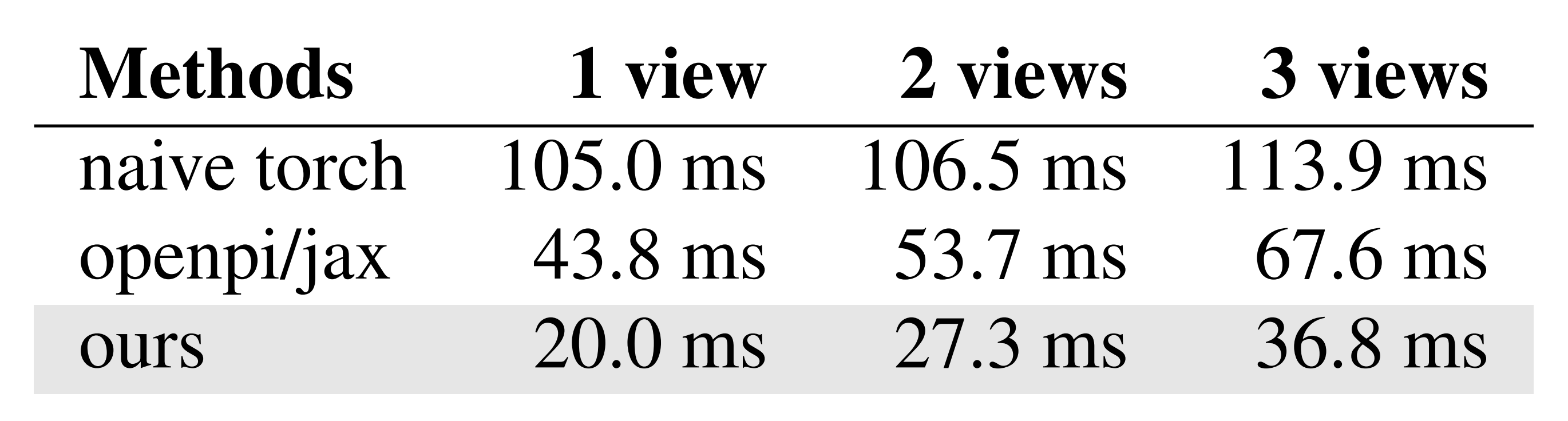
这一性能提升主要得益于作者对推理流水线的工程优化
- 首先,采用 CUDA 图(CUDA graph)方法消除了所有 CPU 开销
- 随后,对计算图进行变换,以减少总 MAC 计算量或减少 kernel 启动次数
在此之后,作者对各个 kernel 内部的内存和张量操作进行了重新编排,以更好地利用并行性。通过以上所有策略,作者成功将推理时间推进到30 FPS 及以上,满足了实时控制的需求
为了验证作者实时策略的有效性,他们在真实环境中设计了一个简单的概念验证实验。如图1 所示,制作了两个竖直对齐的夹爪来夹持一支记号笔

当上方的第一个夹爪松开笔后,第二个夹爪需要在合适的时间抓住这支笔。通过自动化规则收集了数百条抓取数据。通过训练π0 模型来控制夹爪去抓取从更高且存在扰动位置落下的笔。这样的任务具有非常严格的时间约束。在模型推理过程中,由于推理时间得到了极大优化,π0 模型在该任务上达到了100 % 的成功率
这一结果促使作者重新思考应当如何将 VLA 应用于实时机器人系统
- 目前,机器人控制系统主要由三层构成,不同的算法在其中以分层控制频率的形式运行。通常认为,VLA 位于中层控制这一层次
更高频率的控制(即力控制或力矩控制)则被认为由其他算法来处理 - 然而,作者发现VLA 本身就包含了不同层级的输入与输出频率。作者直接将 VLA 的结构映射为一个完整的控制算法,并将该模式称为全流式推理(Full StreamingInference)模式
系统能够以最高 480 Hz 的频率生成控制信号,已触及实时力控制的门槛
1.1.2 π0模型的预备知识
π0[2] 是一种在通用机器人操作任务上表现优异的VLA策略。通过在机器人数据和多模态数据上进行混合训练,以实现开放世界泛化能力[3]。从模型架构的角度来看,它主要包括两个部分:视觉-语言模型(VLM)和动作专家(AE)
- VLMbackbone 以 PaliGemma [1] 进行初始化
PaliGemma 是一个具有 30 亿参数的多模态模型
它由一个具有 4 亿参数的视觉编码器 SigLIP [22] 和一个具有 26 亿参数的大型语言模型(LLM)Gemma [19] 组成
PaliGemma 的表示通过大规模网页数据预训练获得,为下文 AE 部分的并行动作解码提供了强有力的先验 - AE 通过混合专家MoE架构与 VLM 骨干网络相耦合 [15]
AE 的网络是在Gemma 的基础上缩小宽度和 MLP 维度得到的,总参数量为 3 亿。AE 通过 flow matching[12] 建模,用于生成分段动作的预测结果
多视角图像和任务prompt 被路由到更大的 VLM 主干网络,而状态和动作噪声则被路由到 AE
1.2 消除开销
如原论文所述,接下来,作者将展示一个逐步构建推理程序的过程
- 作者的起点是一个普通的 PyTorch nn.Module实现,它严格按照模型结构直接编写。测得的运行时间在 100 毫秒以上,距离作者的目标相去甚远
- 首先做的几步优化,聚焦于一些“易得红利”:
一方面通过消除 CPU 开销(对应图 2 中的“+cuda graph”项)显著加速计算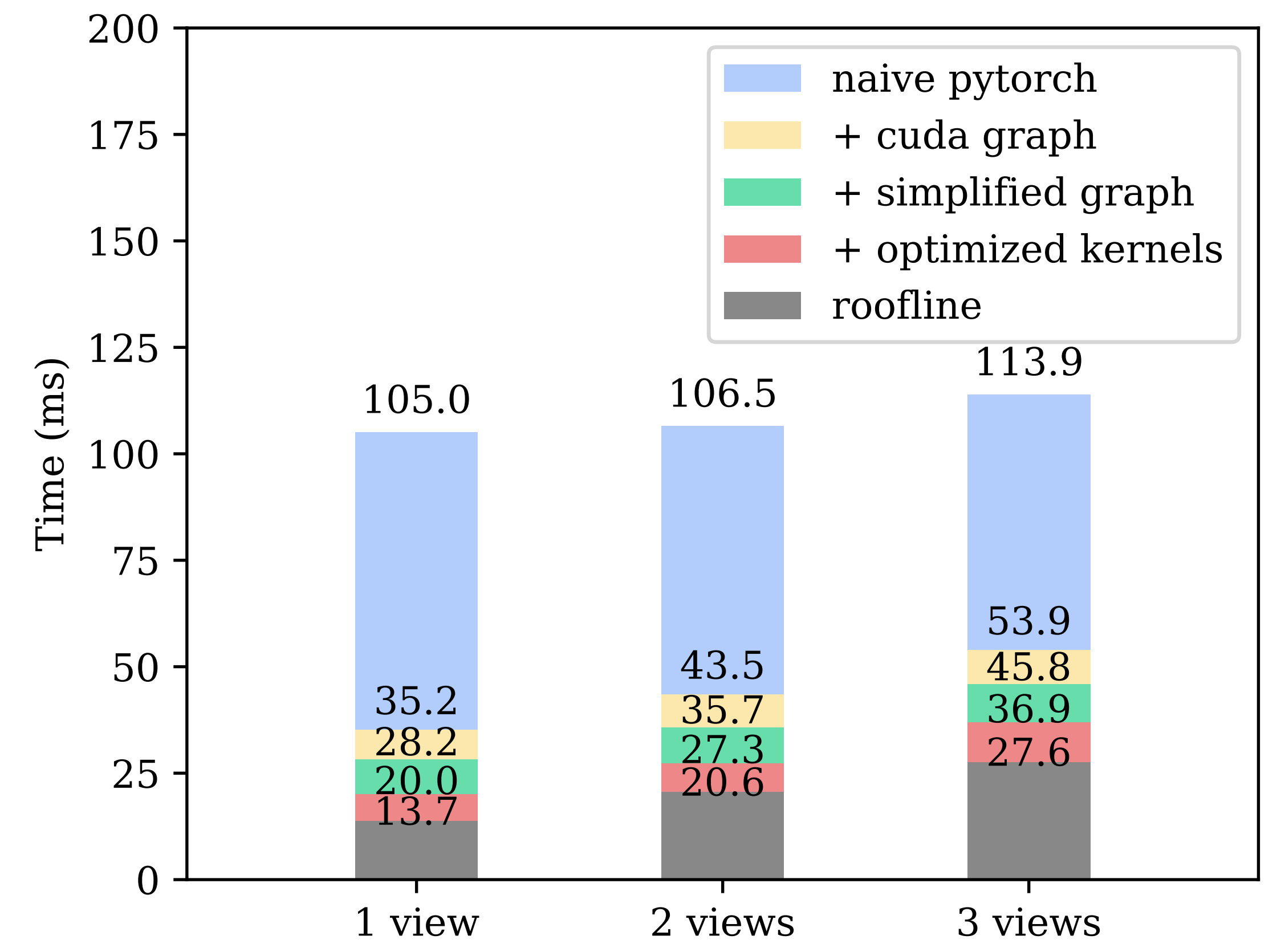
另一方面通过去除冗余计算(对应图 2中的“+simplified graph”项)来进一步提速
1.2.1 消除 CPU 开销
目前,神经网络推理通常由 Python 代码驱动,用来启动底层的 CUDA 内核。然而,当内核数量很大时,Python 部分会带来显著的开销。在 π0模型中,估计每一步推理需要启动的内核总数超过一千个,这使得 CPU 开销问题变得十分紧迫
目前已有多种预先编译(Ahead-Of-Time, AOT)或即时编译(Just-In-Time, JIT)技术可供选择
然而,作者发现最简单且最有效的方法是使用 CUDA 图(CUDA graph)机制。在CUDA图中,作者可以记录模型推理期间启动的内核流,然后重新执行这些操作
- 在回放阶段,这些 kernel 完全由 GPU 和驱动程序发起与执行,从而消除所有 Python 执行开销
CUDA graph 方法需要确保从一次运行到下一次运行,所有 kernel 代码和缓冲区指针都是恒定不变的 - 在作者的 VLA 场景中,这一条件是可以满足的,因为底层的 transformer 块中不存在动态分支
如图 2 所示,这大约将推理速度提升了两倍,从而挤掉了朴素实现中推理开销的主要部分
1.2.2 图简化
// 待更
第二部分 Realtime-VLA V2:让 VLA 运行得更快、更平滑且更精确
1.1 引言与相关工作
1.1.1 引言
在真实世界的机器人任务中,循环时间至关重要。为了让基于 VLA 的机器人执行变得快速,人们在异步控制方法、自适应速度规划、训练数据优化以及高性能计算等方面做了大量工作
作者则尝试将这些要素整合起来,以评估在当前 VLA技术条件下,以探讨究竟能让机器人运动得多快
- 然第一个障碍来自机器人硬件本身
典型的机械臂虽然具备较高的关节最大转速,但无法承受突发的加速度或颠簸的运动
当作者对动作片段进行加速时,硬件系统本身就会开始变得不稳定,尤其是对于当前流行的、基于 QDD的轻量级机械臂而言,这类机械臂通常刚度较低,更容易出现问题 - 下一个概念上的难点来自模仿学习原理
当机器人通过人类操控的远程操作来记录示教数据时,其运动速度会被大幅降低
————
由于硬件限制以及控制反馈存在延迟,人类很难记录高速的示教轨迹
因此,必须进入比演示更快的策略执行领域,而这会在训练与推理之间造成环境动态上的不匹配 - 最后,作者必须在不牺牲一次性任务成功率的前提下实现加速,即最好是一次成功
如果机器人需要频繁重试某个动作,甚至整个任务,那么在失败恢复上花费的时间将会抵消在端到端任务吞吐量方面获得的性能提升
总之,作者希望采用一种方法,使机器人运行得又快、又平滑、又准确。获得平滑的轨迹是实现对硬件友好的高速执行的前提;保持轨迹的准确性则对任务成功至关重要

1.1.2 相关工作
首先,对于VLA
- VLA模型为机器人操作提供了一种强大的范式,它将视觉观测和语言指令映射到低层动作。具有代表性的工作包括 RT-1[4]、RT-2 [23]、PaLM-E [5]、ACT [22]、Octo[19]、OpenVLA [10] 和 Gr00t [2],这些模型实现了在不同任务和不同机体之间的强泛化能力
尽管语义推理方面已经取得了进展,这些系统通常继承了人类示教中缓慢的时间特性,从而在实际节拍时间上产生瓶颈 - 近期的工作,如 π[3] 和 VLASH [18],通过高频率动作生成和异步推理提高了效率
然而,这些方法侧重于策略生成,而非系统层面的约束,例如控制延迟、轨迹平滑性以及硬件动力学
相比之下,作者从系统层面加速VLA 的执行,将异步控制、轨迹整形和速度自适应整合在一起,从而实现可靠的超越示教速度运行
其次,对于模仿学习与执行加速
模仿学习受制于人类示范的速度和分布
- 先前的工作如DAgger[15] 和 ACT [22] 通过数据集聚合以及更强的策略表示来提升泛化能力和稳定性
- 近期研究的重点是实现“快于示范”的执行
基于数据层面的相关方法(包括 ESPADA [9] 和DemoSpeedup [7])通过调整示范轨迹来鼓励更快速的运动模式
策略与速度自适应方法,如SpeedAug [12]、SAIL [1] 和 RLT [21],则通过数据增强和在线微调联合优化速度与稳定性
相比之下,作者的方法利用由人类调制的 rollout 来学习细粒度的速度自适应,这种能力可以隐式地融入 VLA策略本身,或通过一个轻量级适配器实现,从而在无需更改架构的前提下,实现灵活、即插即用的速度调制
最后,对于系统级执行与控制
- 经典的轨迹优化方法包括CHOMP [14]、STOMP [8]、TrajOpt [16] 和 MPC [6]能够生成平滑且满足动力学可行性的运动轨迹
最新工作[13] 将基于学习的策略集成为参考轨迹,用于跟踪和进一步优化 - 然而,这些方法侧重于执行的精确性,而非可靠的高速运行
当将速度提升到超出演示级别时,包括控制延迟、感知—执行滞后以及轨迹平滑性在内的系统瓶颈会主导整体稳定性,但这些问题在很大程度上仍未得到解决
相比之下,作者将时间对齐、轨迹塑形以及闭环控制识别为实现可靠高速 VLA 执行的关键要素,并对这些组件进行联合优化,从而在真实世界环境中实现超出示范速度的稳定、平滑且精确的运行
1.2 系统的标定与识别
1.2.1 系统中的延迟
首先需要正确把握的是理解系统中的时间延迟。在VLA训练中,作者为模型提供了一个理想环境,在该环境中观察是即时的,动作也立即执行。从训练的角度来看,这是理想状态:否则模型会因信号不同步而困惑,并生成模糊的轨迹。然而,在真实世界的场景中,舞台上存在着多种时间错位的问题
当作者记录训练数据时,相机会为每一帧给出一个时间戳(报告的相机时间),该时间戳将被用来与关节位置读数对齐以形成训练对
然而
- 作者发现实际曝光可能发生在时间戳被记录之前
- 并且关节读数可能会被延迟
- 同时,图像将在声明的时间戳之后
被接收
如果所有组件都经过良好工程设计,所有这些时间延迟都可以被减小到最小值。但对于现成的相机和机器人,它们的延迟可能达到几十毫秒的量级
另一个更为显著的延迟来自机器人的自身动力学。当作者在循环同步位置(Cyclic SynchronousPosition,CSP)模式下控制机器人时,作者会在每一个控制周期向机器人发送一个目标位置
- 然而,机器人的实际位置会滞后于该目标位置。这种滞后部分是由通信延迟造成的,但主要原因来自机械臂自身的轨迹跟踪算法
- 作者观察到,许多轻量级机械臂在位置环中采用 PD 控制(甚至是 P 控制)以最大化稳定性,因此,其滞后量与 PD 控制器的增益成反比
这会在直线运动中产生一个常数时间的延迟(记为),并在停止或启动时表现为指数衰减
上述术语之间的关系在图2 中进行了总结
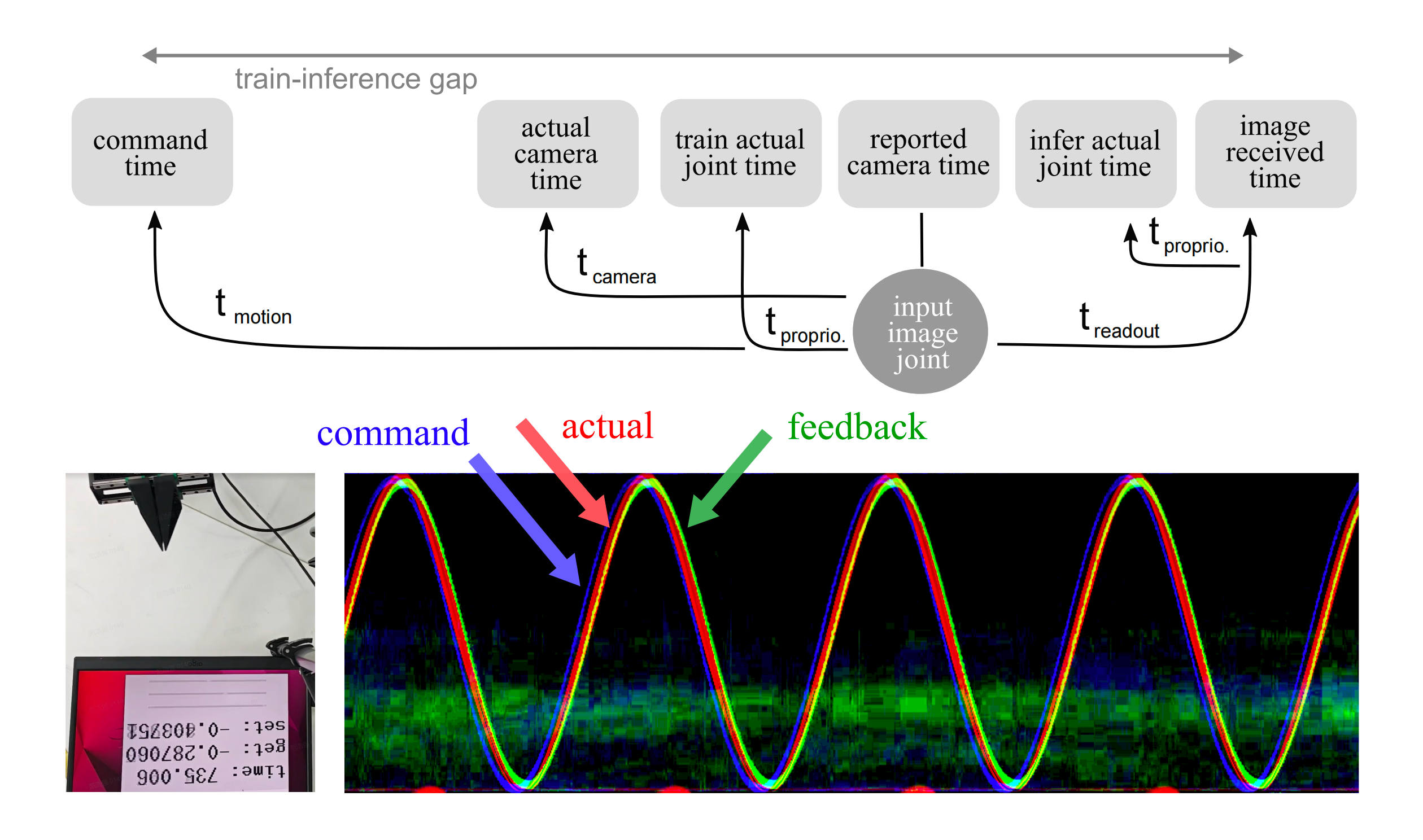
作者可以看到,相比于一种 “在看到图像时生成下一时刻动作” 的理想化模型,在真实世界中总存在一个的间隔
1.2.2 标定与补偿
鉴于上述问题,作者现在需要设计一种方法来测量这些时间延迟,以便后续对其进行处理
- 最简单的是
- 对于
,作者设置了一条由系统时钟驱动的LED 灯带,通过比较捕获的内容与相机所标注的时间戳来测量延迟。这些是在相机标定中已经被广泛采用的方法
- 对于与机器人相关的延迟,当作者没有配备高精度测量设备时,测量会更加困难
不过,作者宣称,他们找到了一种在精度上相当可行的实用方法来对这些延迟进行解析。其装置如图 2 左下部分所示
作者让机器人在摄像头前以正弦模式来回摆动
然后,作者在屏幕上显示三个轨迹条,用于表示当前时间相对于正弦周期的相位、机器人报告的实际位置以及作者发送给机器人的指令目标位置
整个设置由一台高帧率相机进行录制(许多手机都支持最高120fps),然后作者从每一帧中提取包含滑轨条和机械臂末端区域的那一行图像,用以构成一个时间-位置图
一个示例如图 2 右下部分所示,其中作者利用图像的三个通道来表示三种被测运动
使用图像数据的优势在于,可以根据像素值进行相位估计,从而达到亚帧级的时间精度。作者宣称,根据作者的实验,作者可以将 、
的标定精度提升到 5 毫秒以内。需要注意的是,必须考虑屏幕显示延迟。这可以通过对比系统时间进度条测得的延迟(该延迟包含屏幕延迟和相机延迟)以及通过 LED测量得到的延迟(该延迟仅包含相机延迟)来完成
之后,作者在原论文中展示了在他们的机器人配置——DOS W1 系统——上获得的具体数据结果,该系统使用 RealSense D435 相机和 Airbot Play 机械臂

在测量了延迟之后,作者现在描述如何对其进行补偿
- 对于
- 然后作者使用该值从报告的关节位置的小型历史缓冲区中进行检索(考虑到
)
通过这种方式,以确保图像和关节读数在作为VLA 的输入时是对齐的 - 对于
作者将该参数放在模型轨迹的后处理阶段(下一节会详细说明),以预放大目标位置,使机器人能够紧密跟踪模型的输出
在图3中,作者展示了预放大(pre-amplification)的效果『机器人指令预放大的效果。需要增大机器人指令中变化量的幅度,使实际位置能够跟踪模型给出的目标』
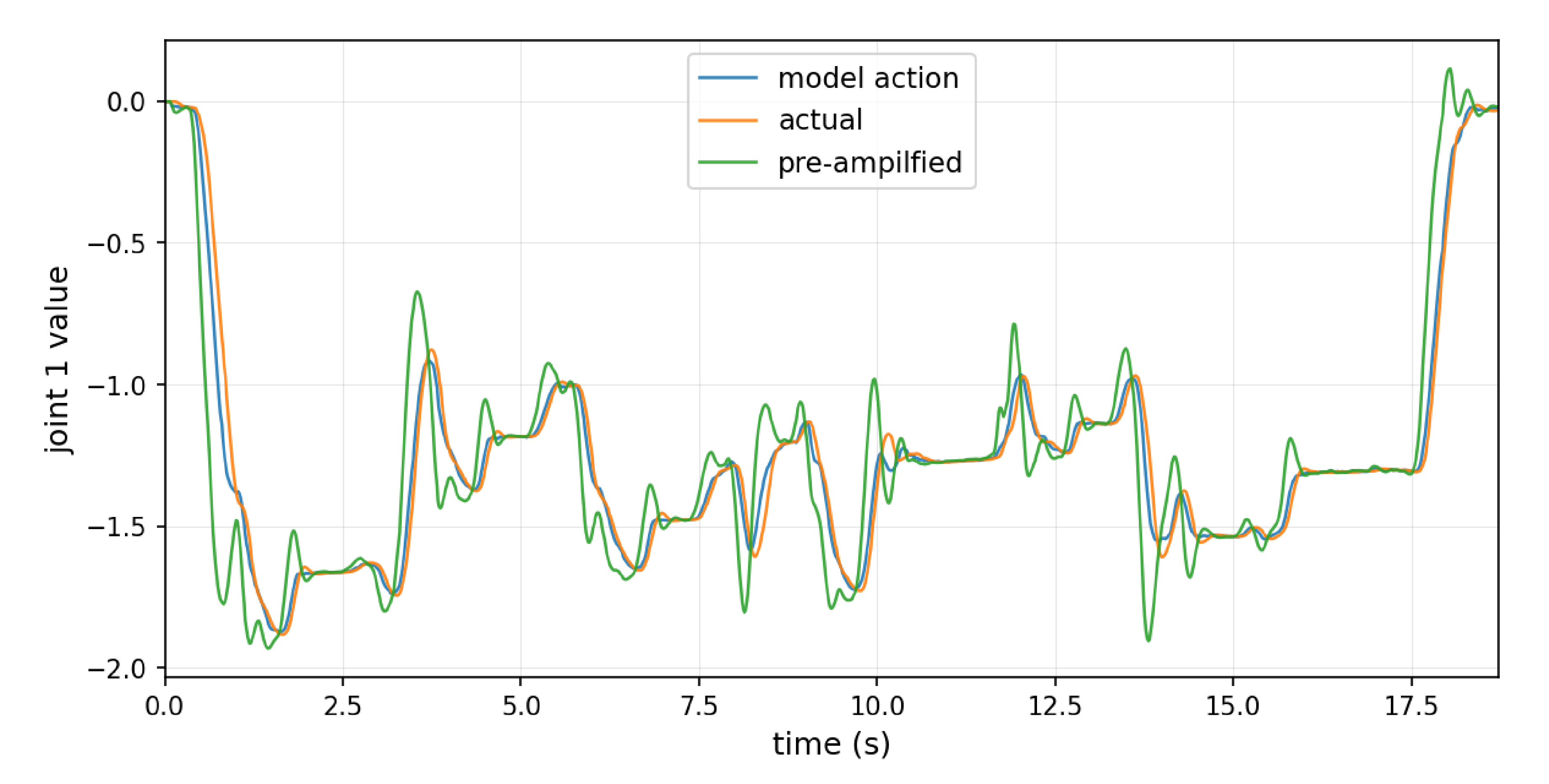
作者发送给机器人的目标位置指令比模型所期望的轨迹要剧烈得多。经过机器人的控制器之后,轨迹又回到了模型真正要求的路径上。这是将模型所看到的时间线与滞后的真实世界对齐的关键步骤
1.3 对 VLA 轨迹的后处理
核心思想是以对模型透明的方式对 VLA 的输出轨迹进行后处理。作者希望让模型“看到”的是其动作被完美执行的视图,从而无需重新训练模型,同时诸如 RTC 之类的异步技术依然适用。这样可以通过在时间上调整轨迹来完成——重新为各个时间步分配持续时间,使轨迹变得平滑,然后对平滑后的轨迹进行加速以达到最大速度
- 作者想强调的是,轨迹的平滑性是在高速执行中最为关键的因素。现实世界中跑得快的障碍并不是关节的最大速度,而是系统在高速运行时不能发生发散。控制信号中的抖动和振动会导致输入视觉画面不稳定,从而破坏 VLA 模型和关节硬件的稳定性
- 然而,如果能够使轨迹平滑,便可以最大限度地利用硬件能力,同时紧密跟踪轨迹中的目标位置
因此,作者实现了轨迹后处理——如图4所示的处理框架
作者假定采用客户端-服务器分离架构,其中 VLA 模型运行在另一台GPU 服务器上(服务器端),而机器人则连接到本地计算机或控制板(客户端)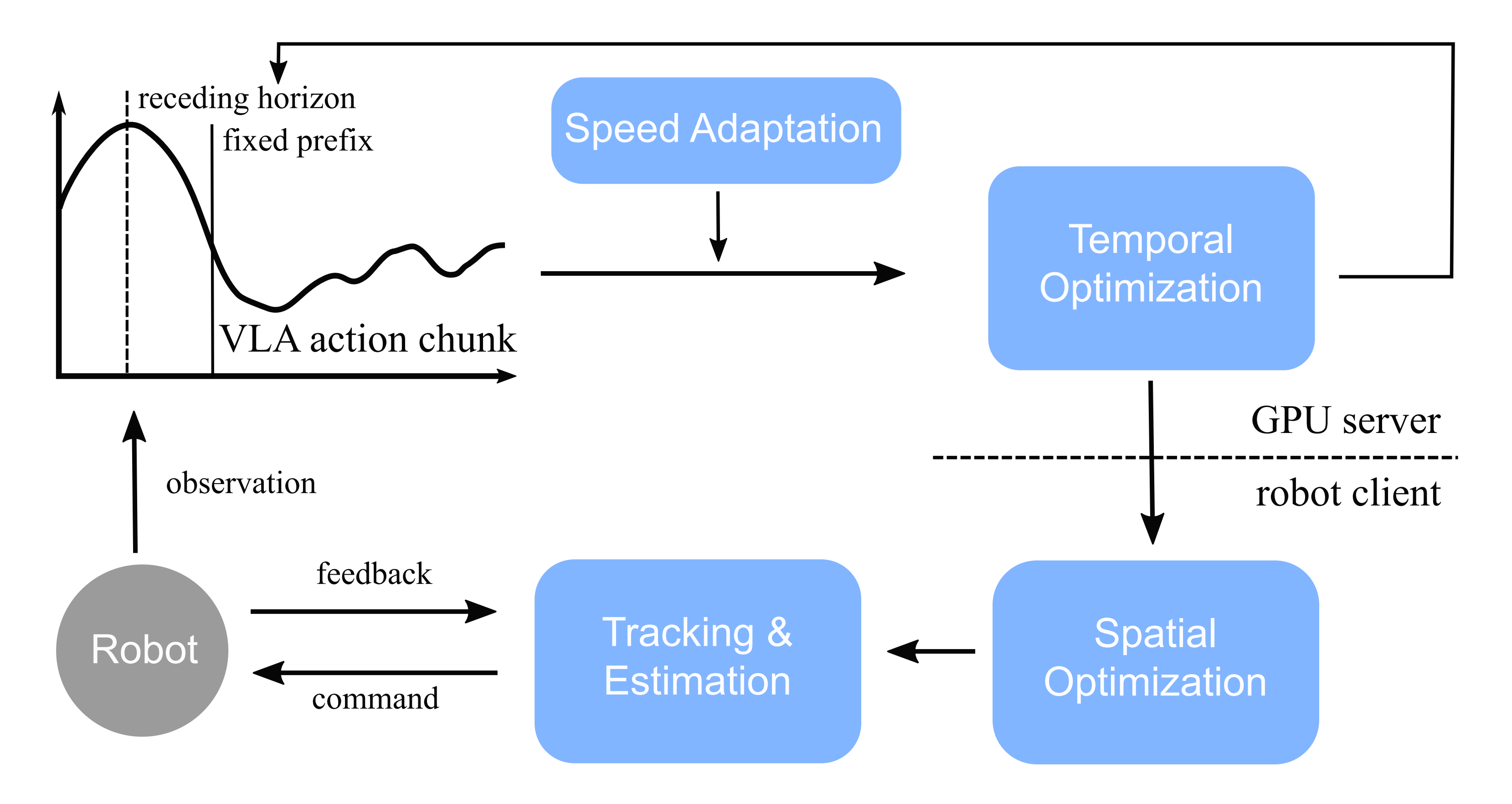
VLA 的轨迹首先由速度自适应模型进行调制,然后由时间优化模型进一步处理,并发送到客户端
之后,客户端在每一个执行时刻进行空间优化,随后通过控制与反馈对机器人的状态进行跟踪和估计
1.3.1 速度自适应与时间优化
第一阶段只对轨迹的时间剖面进行操作,而不改变 VLA 生成的路径形状。作者之所以做出这一限制,是因为:
- 不希望丢失 VLA 给出的航路点(way-points)的空间/位置精度
- 这种做法独立于实时分块的前缀匹配机制
从 VLA 模型的角度来看,时间调整仅仅改变了动作片段被“消耗”的速度,因此不会给视觉控制环路引入不一致性
在这个阶段,使用一个速度自适应模型(SpeedAdaptation Model)来决定每一步中块的运行速度(以缩放因子的形式表示)。将在后文章节中描述如何训练这样的模型。该模型应能够在保持成功率的前提下,将执行过程动态加速到极限
然而,不能依赖模型来保证平滑性。在实践中作者发现路径中包含一些短段落,在这些段落中某个关节会突然转动,从而产生很高的加速度峰值。故作者觉得需要在整个片段中分布加速度,而不改变平均速度
即作者在一个优化框架中实现这一点,因此称其为时间优化(Temporal Optimization)。具体来说,在步长持续时间的倒数上构建一个二次规划:
其中 和
定义为
表示由VLA 模型生成的路径点,
是通过转换速度自适应模型预测的速度缩放因子得到的。
,
,
,
,
都是可配置参数。相当于通过OSQP 求解该问题
通过这种方式,作者认为应当能够以合适的速度获取一个数据块,并且避免突然加速。然后将该轨迹通过网络发送到客户端
1.3.2 空间优化与跟踪
在这个阶段,作者将偏离仅在时间维度上进行规划的范式,局部地改变轨迹的位姿
此步骤的目标有两个
- 确保轨迹在实际硬件约束下是有效的
- 驱动机器人去跟踪该轨迹
这两个目标通过一个称之为空间优化(Spatial Optimization)的单一过程来实现,本质上它是一个控制算法
使用线性递归关系对机器人系统的滞后动态进行建模:
其中,为伺服周期,
为识别得到的响应时间常数。该模型刻画了在高速执行中最重要的主导效应:实际运动滞后于下达的指令,并对突发的指令变化产生衰减
总之,可以利用这一关系来补偿关节位置观测中的延迟:在最近一次接收到状态反馈的实际时间戳之后,记录指令的历史,并通过上述方程回放这些指令的效果。这样就得到了对当前状态的修正观测
最后,作者将根据当前状态、先前的指令
,
以及未来目标
来决定要发送的当前指令:
基于
// 待更

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 8
8 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)