Spring AI 可视化编排实战:构建 LangGraph 风格的 YAML DSL 工作流引擎
场景
Spring AI 多工具链式调用(Tool Chain)极简实战:
https://blog.csdn.net/BADAO_LIUMANG_QIZHI/article/details/161226567
在前面的系列文章中,我们逐步构建了基于 Spring AI + Ollama 的 RAG 智能体,
并实现了多工具调用(Tool Chain),让模型能够自主组合天气查询和翻译等工具。
然而,简单的工具注册方式将“决策权”完全交给了大模型,对于需要精确控制执行步骤、条件分支、循环重试、并行处理的复杂场景,
我们更希望用一种声明式、可读性强、便于维护的方式定义智能体的行为。
LangGraph 是 LangChain 生态中用于构建有状态、多步骤 Agent 的框架,它用有向图(Graph)来描述工作流:
节点代表操作,边代表转移,支持条件分支、循环、并行等高级控制流。
受此启发,本文将基于 Spring AI 1.1.2 和 Ollama,在不依赖任何外部流程引擎的前提下,
从零构建一个轻量级的 YAML DSL 工作流引擎。
通过编写一个 YAML 文件,你就能定义出复杂的工作流,引擎将解析并执行它。
这种方式即保留了 Spring AI 的强大能力,又获得了 LangGraph 式的可视化编排体验。
一、核心概念
| 概念 | 说明 |
|---|---|
| 状态图 (StateGraph / Workflow) | 由节点和有向边组成的执行单元,描述任务从开始到结束的完整路径。 |
| 节点 (Node) | 工作流中的一个操作步骤。可以是工具调用(tool)、LLM 推理(llm)、条件判断、循环控制等。 |
| 边 (Edge) | 连接两个节点的有向线段,定义执行顺序。 |
| 条件边 (Conditional Edge) | 根据上下文变量的值动态选择下一个节点(本文通过 while 节点内的条件判断体现)。 |
| 循环节点 (While) | 重复执行一组子节点,直到条件不再满足或达到最大迭代次数。 |
| 并行节点 (Parallel) | 同时启动多个独立分支,等待全部完成后合并结果,继续后续流程。 |
| 上下文 (Context) | 一个贯穿整个工作流的 Map,节点间通过它共享数据。每个节点的输出会被保存到上下文中,供后续节点通过 ${节点id.output} 表达式引用。 |
| DSL (领域特定语言) | 这里指我们设计的 YAML 配置语法,专门用于描述工作流的结构。 |
LangGraph 风格的核心思想
LangGraph 用图来建模 Agent,其特点包括:
节点即函数:每个节点是一个可执行的单元(如调用工具、调用 LLM)。
状态即上下文:图执行过程中,一个共享的状态对象在节点间传递并更新。
边可带条件:可以定义 “如果…则…” 的分支,实现动态路由。
支持循环与并行:节点可以包含子图(body),形成 while 循环;多个分支可并发执行。
配置与逻辑分离:将工作流结构从业务代码中剥离,只需修改 YAML 即可调整 Agent 的行为。
我们的轻量级引擎正是遵循这些原则,通过 YAML 定义图结构,Java 代码解析并执行。
注:
博客:
https://blog.csdn.net/badao_liumang_qizhi
实现
pom.xml
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.3.3</version>
</parent>
<groupId>com.example</groupId>
<artifactId>spring-ai-ollama-tool-chain-langGraph</artifactId>
<version>1.0</version>
<properties>
<java.version>17</java.version>
<spring-ai.version>1.1.2</spring-ai.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- Spring AI Ollama 核心 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-ollama</artifactId>
<version>${spring-ai.version}</version>
</dependency>
</dependencies>application.yml
server:
port: 886
spring:
ai:
ollama:
base-url: http://localhost:11434
chat:
model: qwen2.5:7b-instruct
options:
temperature: 0.7
num-ctx: 4096 # 上下文窗口大小
logging:
level:
org.springframework.ai.chat.client: DEBUG # 查看工具调用详情
工具类定义
天气工具类:
package com.badao.ai.tools;
import org.springframework.ai.tool.annotation.Tool;
import org.springframework.ai.tool.annotation.ToolParam;
import org.springframework.stereotype.Component;
@Component
public class WeatherTool {
@Tool(name = "get_weather", description = "查询指定城市的实时天气")
public String getWeather(@ToolParam(description = "城市名称") String city) {
System.out.println("调用了天气工具");
// 模拟天气数据
return String.format("%s当前天气:晴,温度22℃,湿度45%%。", city);
}
}翻译工具类:
package com.badao.ai.tools;
import org.springframework.ai.tool.annotation.Tool;
import org.springframework.ai.tool.annotation.ToolParam;
import org.springframework.stereotype.Component;
@Component
public class TranslateTool {
@Tool(name = "translate_to_english", description = "将中文文本翻译成英文")
public String translate(@ToolParam(description = "待翻译的中文文本") String text) {
System.out.println("调用了翻译工具");
// 模拟翻译,实际可接入翻译API
return "Translated: " + text + " (This is the English version.)";
}
}工具注册配置
package com.badao.ai.config;
import com.badao.ai.tools.WeatherTool;
import com.badao.ai.tools.TranslateTool;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.HashMap;
import java.util.Map;
import java.util.function.Function;
@Configuration
public class ToolConfig {
@Bean
public ChatClient chatClient(ChatModel chatModel) {
return ChatClient.builder(chatModel).build();
}
/**
* 构建工具名 -> 函数实现的映射,WorkflowEngine 直接使用
*/
@Bean
public Map<String, Function<String, String>> toolRegistry(WeatherTool weatherTool,
TranslateTool translateTool) {
Map<String, Function<String, String>> registry = new HashMap<>();
registry.put("get_weather", city -> weatherTool.getWeather(city));
registry.put("translate_to_english", text -> translateTool.translate(text));
return registry;
}
}我们将工具包装为 Function<String, String> 并存入 Map,供引擎按名称查找。
工作流定义模型(WorkflowDefinition)
使用 Java 类映射 YAML 结构,支持各种节点类型。
package com.badao.ai.workflow;
import java.util.List;
public class WorkflowDefinition {
private String name;
private String start;
private List<Node> nodes;
private List<Edge> edges;
// getters & setters
public String getName() { return name; }
public void setName(String name) { this.name = name; }
public String getStart() { return start; }
public void setStart(String start) { this.start = start; }
public List<Node> getNodes() { return nodes; }
public void setNodes(List<Node> nodes) { this.nodes = nodes; }
public List<Edge> getEdges() { return edges; }
public void setEdges(List<Edge> edges) { this.edges = edges; }
// ========== Node ==========
public static class Node {
private String id;
private String type;
private String tool;
private String input;
private String prompt;
private String condition;
private int maxIterations = 5;
private List<Node> body;
private List<ParallelBranch> branches; // 改为 ParallelBranch 列表
// getters & setters(请确保所有字段都有)
public String getId() { return id; }
public void setId(String id) { this.id = id; }
public String getType() { return type; }
public void setType(String type) { this.type = type; }
public String getTool() { return tool; }
public void setTool(String tool) { this.tool = tool; }
public String getInput() { return input; }
public void setInput(String input) { this.input = input; }
public String getPrompt() { return prompt; }
public void setPrompt(String prompt) { this.prompt = prompt; }
public String getCondition() { return condition; }
public void setCondition(String condition) { this.condition = condition; }
public int getMaxIterations() { return maxIterations; }
public void setMaxIterations(int maxIterations) { this.maxIterations = maxIterations; }
public List<Node> getBody() { return body; }
public void setBody(List<Node> body) { this.body = body; }
public List<ParallelBranch> getBranches() { return branches; }
public void setBranches(List<ParallelBranch> branches) { this.branches = branches; }
}
// ========== ParallelBranch ==========
public static class ParallelBranch {
private List<Node> nodes; // 分支内部的节点序列
public List<Node> getNodes() { return nodes; }
public void setNodes(List<Node> nodes) { this.nodes = nodes; }
}
// ========== Edge ==========
public static class Edge {
private String from;
private String to;
public String getFrom() { return from; }
public void setFrom(String from) { this.from = from; }
public String getTo() { return to; }
public void setTo(String to) { this.to = to; }
}
}工作流引擎(WorkflowEngine)
解析 YAML 并执行节点,处理工具调用、LLM 调用、while 循环、并行分支。
package com.badao.ai.workflow;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.stereotype.Component;
import org.yaml.snakeyaml.Yaml;
import java.io.InputStream;
import java.util.*;
import java.util.concurrent.CompletableFuture;
import java.util.function.Function;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
@Component
public class WorkflowEngine {
private final ChatClient chatClient;
private final Map<String, Function<String, String>> toolRegistry;
public WorkflowEngine(ChatClient chatClient,
Map<String, Function<String, String>> toolRegistry) {
this.chatClient = chatClient;
this.toolRegistry = toolRegistry;
}
// ---------- 工作流执行入口 ----------
public String execute(String workflowPath, Map<String, Object> initialContext) {
WorkflowDefinition wf = loadWorkflow(workflowPath);
Map<String, Object> context = new HashMap<>(initialContext);
context.put("_nodes", new HashMap<String, Object>());
String currentNode = wf.getStart();
while (currentNode != null && !currentNode.equals("end")) {
WorkflowDefinition.Node node = findNodeById(wf, currentNode);
if (node == null) break;
System.out.println("Executing node: " + node.getId());
currentNode = executeNode(node, context, wf);
}
// 找到工作流中最后一个非 end、非 start 的节点,并返回其输出
String lastOutput = null;
Map<String, Object> nodesOutput = (Map<String, Object>) context.get("_nodes");
if (nodesOutput != null) {
// 按边的顺序找到最后一个被执行的节点(或直接取最后一个节点的 id)
for (WorkflowDefinition.Edge edge : wf.getEdges()) {
if ("end".equals(edge.getTo())) {
lastOutput = nodesOutput.getOrDefault(edge.getFrom(), "").toString();
break;
}
}
}
return lastOutput != null ? lastOutput : "No output generated";
}
// ---------- 节点分发 ----------
private String executeNode(WorkflowDefinition.Node node, Map<String, Object> context,
WorkflowDefinition wf) {
switch (node.getType()) {
case "start":
return getNextNodeId(wf, node.getId());
case "tool":
return executeToolNode(node, context, wf);
case "llm":
return executeLlmNode(node, context, wf);
case "while":
return executeWhileNode(node, context, wf);
case "parallel":
return executeParallelNode(node, context, wf);
default:
return getNextNodeId(wf, node.getId());
}
}
// ---------- 工具节点 ----------
private String executeToolNode(WorkflowDefinition.Node node, Map<String, Object> context,
WorkflowDefinition wf) {
Function<String, String> tool = toolRegistry.get(node.getTool());
if (tool == null) throw new RuntimeException("Tool not found: " + node.getTool());
String resolvedInput = resolveExpression(node.getInput(), context);
String result = tool.apply(resolvedInput);
saveOutput(node.getId(), result, context);
return getNextNodeId(wf, node.getId());
}
// ---------- LLM 节点 ----------
private String executeLlmNode(WorkflowDefinition.Node node, Map<String, Object> context,
WorkflowDefinition wf) {
String resolvedPrompt = resolveExpression(node.getPrompt(), context);
String response = chatClient.prompt().user(resolvedPrompt).call().content();
saveOutput(node.getId(), response, context);
return getNextNodeId(wf, node.getId());
}
// ---------- While 循环 ----------
private String executeWhileNode(WorkflowDefinition.Node node, Map<String, Object> context,
WorkflowDefinition wf) {
int count = 0;
while (count < node.getMaxIterations()) {
// 先解析条件
String condition = resolveExpression(node.getCondition(), context);
// 条件不满足(null、空、false)则直接退出
if (condition == null || !"true".equalsIgnoreCase(condition)) {
break;
}
// 条件满足,执行循环体
for (WorkflowDefinition.Node bodyNode : node.getBody()) {
executeNode(bodyNode, context, wf);
}
count++;
}
return getNextNodeId(wf, node.getId());
}
// ---------- 并行节点 ----------
private String executeParallelNode(WorkflowDefinition.Node node, Map<String, Object> context,
WorkflowDefinition wf) {
List<CompletableFuture<Void>> futures = new ArrayList<>();
for (WorkflowDefinition.ParallelBranch branch : node.getBranches()) {
List<WorkflowDefinition.Node> branchNodes = branch.getNodes(); // 获取分支内的节点列表
CompletableFuture<Void> future = CompletableFuture.runAsync(() -> {
Map<String, Object> branchContext = new HashMap<>(context);
for (WorkflowDefinition.Node branchNode : branchNodes) {
executeNode(branchNode, branchContext, wf);
}
synchronized (context) {
context.putAll(branchContext);
}
});
futures.add(future);
}
CompletableFuture.allOf(futures.toArray(new CompletableFuture[0])).join();
return getNextNodeId(wf, node.getId());
}
// ---------- 辅助方法 ----------
private WorkflowDefinition.Node findNodeById(WorkflowDefinition wf, String id) {
return wf.getNodes().stream().filter(n -> n.getId().equals(id)).findFirst().orElse(null);
}
private String getNextNodeId(WorkflowDefinition wf, String currentId) {
return wf.getEdges().stream()
.filter(e -> e.getFrom().equals(currentId))
.map(WorkflowDefinition.Edge::getTo)
.findFirst().orElse("end");
}
private void saveOutput(String nodeId, String output, Map<String, Object> context) {
((Map<String, Object>) context.get("_nodes")).put(nodeId, output);
context.put(nodeId + ".output", output);
}
private String resolveExpression(String expr, Map<String, Object> context) {
if (expr == null) return null;
Pattern pattern = Pattern.compile("\\$\\{(.+?)\\}");
Matcher matcher = pattern.matcher(expr);
StringBuffer sb = new StringBuffer();
while (matcher.find()) {
String var = matcher.group(1);
Object value = context.get(var);
if (value == null) {
Map<String, Object> nodes = (Map<String, Object>) context.get("_nodes");
if (nodes != null) value = nodes.get(var);
}
matcher.appendReplacement(sb, value != null ? value.toString() : "");
}
matcher.appendTail(sb);
return sb.toString();
}
private WorkflowDefinition loadWorkflow(String path) {
Yaml yaml = new Yaml();
InputStream in = getClass().getResourceAsStream(path);
return yaml.loadAs(in, WorkflowDefinition.class);
}
}服务层
package com.badao.ai.service;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.stereotype.Service;
@Service
public class AgentService {
private final ChatClient chatClient;
public AgentService(ChatClient chatClient) {
this.chatClient = chatClient;
}
public String ask(String question) {
return chatClient.prompt()
.user(question+ "(请先用天气工具,再用翻译工具)")
.call()
.content();
}
}控制器
package com.badao.ai.controller;
import com.badao.ai.service.AgentService;
import com.badao.ai.workflow.WorkflowEngine;
import org.springframework.web.bind.annotation.*;
import java.util.HashMap;
import java.util.Map;
@RestController
@RequestMapping("/api")
public class AgentController {
private final AgentService agentService;
private final WorkflowEngine engine;
public AgentController(AgentService agentService, WorkflowEngine engine) {
this.agentService = agentService;
this.engine = engine;
}
@PostMapping("/agent")
public String ask(@RequestBody String question) {
return agentService.ask(question);
}
@PostMapping("/workflow")
public String runWorkflow(@RequestBody Map<String, String> input) {
Map<String, Object> context = new HashMap<>(input);
return engine.execute("/workflows/weather_agent.yaml", context);
}
}YAML 工作流定义文件
放置于 src/main/resources/workflows/weather_agent.yaml。
name: "weather_agent"
start: "start_node"
nodes:
- id: "start_node"
type: "start"
- id: "get_weather"
type: "tool"
tool: "get_weather"
input: "${city}"
- id: "check_need_translate"
type: "while"
condition: "${need_english}"
maxIterations: 1
body:
- id: "translate"
type: "tool"
tool: "translate_to_english"
input: "${get_weather.output}"
- id: "parallel_llm"
type: "parallel"
branches:
- nodes: # 分支1
- id: "summary"
type: "llm"
prompt: "总结:${get_weather.output}"
- nodes: # 分支2
- id: "advice"
type: "llm"
prompt: "给点建议:${get_weather.output}"
- id: "final"
type: "llm"
prompt: >
请严格按照以下要求输出,不要添加任何多余的文字、解释或建议:
1. 用一句话描述天气:${get_weather.output}
2. 如果下面的英文翻译不为空,请完整地输出它:
${translate.output}
edges:
- from: "start_node"
to: "get_weather"
- from: "get_weather"
to: "check_need_translate"
- from: "check_need_translate"
to: "parallel_llm"
- from: "parallel_llm"
to: "final"
- from: "final"
to: "end"运行与测试
传递不翻译:
{"city":"青岛", "need_english":"false"}
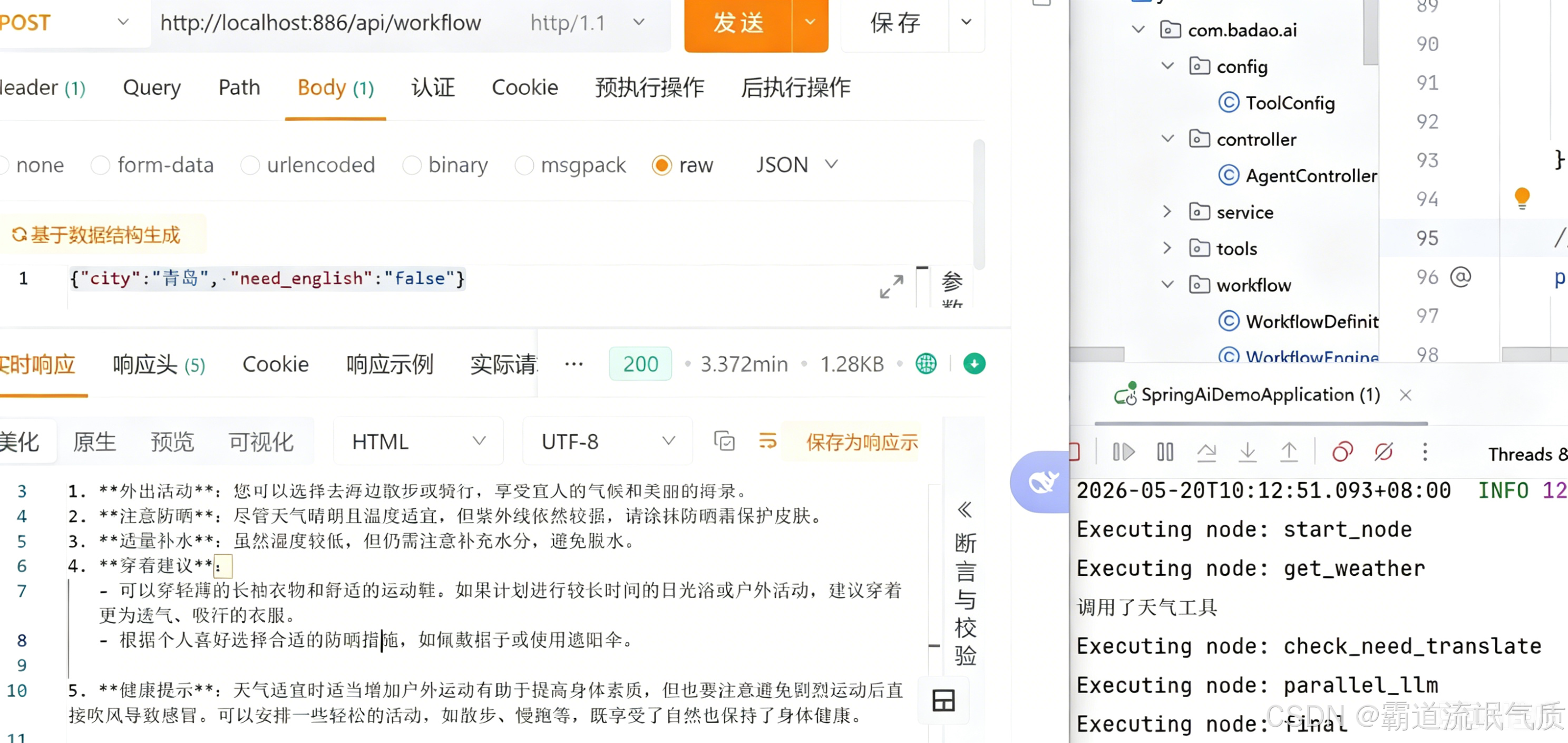
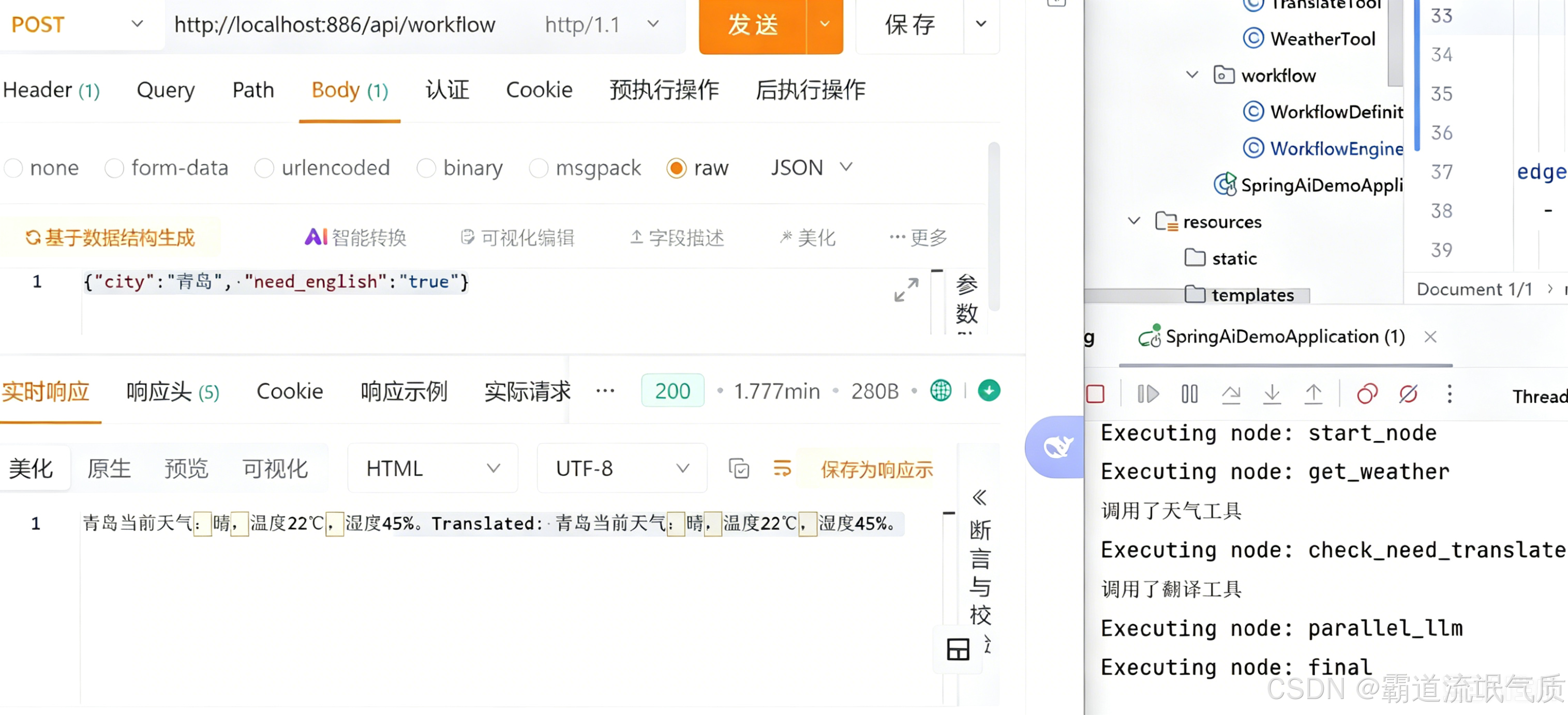
编排要翻译,改为true
1、图结构设计
我们的 DSL 用 节点列表 + 边列表 描述有向图。节点包含 type 字段来区分不同行为;
边仅定义 from 和 to,不含条件——条件逻辑被封装在 while 节点内部。
这种简化使 YAML 更清晰,同时保留了图的灵活性。
2、上下文传递与表达式解析
表达式 ${xxx.output} 和 ${variable} 在运行时动态解析,从上下文 Map 中取值。
这类似于 LangGraph 的 state 概念,节点间通过共享状态通信。
引擎在保存节点输出时,既存入了 _nodes 映射,也存入了 节点id.output 键,便于后续节点引用。
3、控制流实现
顺序执行:
通过 edges 自然描述。
While 循环:
由 executeWhileNode 实现,先评估条件(condition 表达式),条件为真时执行 body 中的子节点序列,
重复直至条件为假或达到 maxIterations。
并行分支:
使用 CompletableFuture.runAsync() 并发执行各分支,分支内的节点顺序执行;
所有分支完成后通过 allOf().join() 同步,然后将结果合并回主上下文。
注意并发写同一键可能造成覆盖,实际项目中可增加聚合策略。
4、YAML 设计考量
使用驼峰命名(如 maxIterations),与 Java 字段一致,避免 SnakeYAML 映射失败。
并行分支使用 ParallelBranch 包装,因为 SnakeYAML 无法直接将 List<List<Node>> 解析为强类型对象(会变成 List<LinkedHashMap>),
我们在开发中就遇到了该问题。
节点类型用字符串枚举,便于扩展(如添加 http 类型、switch 类型等)。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 30
30 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)