【模型调优】手把手教你调优yolo
利用YOLOv8进行模型调优:以电视检测为例
引言
YOLO(You Only Look Once)系列模型在目标检测领域已经非常成熟,预训练模型种类繁多。然而,如何在低成本(主要是标注成本)的情况下获得一个客制化的模型,是模型调优所能解决的一个主要问题。本文将以一个具体例子——从YOLOv8s预训练模型中调优出一个专门检测电视的模型——来一步步展示模型调优的过程。
什么是模型调优?
模型调优(Model Tuning)是指通过调整机器学习模型的参数和结构,以提高其性能和准确性的过程。在目标检测任务中,调优可以帮助模型在特定类别上达到更高的精度(如AP值),同时减少不必要的计算开销。例如,YOLO模型默认支持多类别检测,但有时我们只需要检测单一类别,并要求该类别的检测效果最佳。
任务目标
- 目标:利用YOLOv8s预训练模型,通过调优获得一个只能检测电视(TV)的YOLO模型。
- 数据集:采用COCO 2017数据集。
第一步:下载和准备数据集
- 下载COCO 2017数据集:
- 从COCO官方网站下载2017年的训练集(train2017)、验证集(val2017)以及对应的标注文件(annotations_trainval2017)。
- 下载完成后解压,数据集目录结构如下:
coco/ ├── annotations/ │ ├── instances_train2017.json │ ├── instances_val2017.json ├── train2017/ │ ├── 000000000001.jpg │ ├── ... ├── val2017/ │ ├── 000000000139.jpg │ ├── ...
第二步:提取电视类别数据
由于我们只需要检测电视(TV)一个类别,因此需要从COCO数据集中提取包含电视的图像及其标注,并转换为YOLO所需的格式。
提取脚本
以下脚本使用pycocotools库提取电视类别数据,并保存为YOLO格式:
from pycocotools.coco import COCO
import os
import shutil
from tqdm import tqdm
# 配置路径
coco_path = "./coco" # COCO数据集根目录
save_path = "./tv_dataset" # 输出目录
classes_to_extract = ["tv"] # 目标类别
# 定义待处理的数据集类型
datasets = ["train2017", "val2017"]
for dataset in datasets:
# 创建输出子目录
dataset_save_path = os.path.join(save_path, dataset)
os.makedirs(os.path.join(dataset_save_path, "images"), exist_ok=True)
os.makedirs(os.path.join(dataset_save_path, "labels"), exist_ok=True)
# 加载对应数据集的标注文件
anno_file = os.path.join(coco_path, "annotations", f"instances_{dataset}.json")
coco = COCO(anno_file)
# 获取目标类别的ID和图像ID
cat_ids = coco.getCatIds(catNms=classes_to_extract)
img_ids = coco.getImgIds(catIds=cat_ids)
# 提取图片和标注
for img_id in tqdm(img_ids, desc=f"Processing {dataset}"):
img_info = coco.loadImgs(img_id)[0]
ann_ids = coco.getAnnIds(imgIds=img_id, catIds=cat_ids)
anns = coco.loadAnns(ann_ids)
# 复制图片到输出目录
src_img = os.path.join(coco_path, dataset, img_info["file_name"])
dst_img = os.path.join(dataset_save_path, "images", img_info["file_name"])
shutil.copy(src_img, dst_img)
# 生成YOLO格式的标签文件
label_file = os.path.join(dataset_save_path, "labels", os.path.splitext(img_info["file_name"])[0] + ".txt")
with open(label_file, 'w') as f:
for ann in anns:
# COCO bbox格式: [x, y, width, height] (绝对像素值)
x, y, w, h = ann["bbox"]
img_width = img_info["width"]
img_height = img_info["height"]
# 转换为YOLO格式: [x_center, y_center, width, height] (归一化到0~1)
x_center = (x + w / 2) / img_width
y_center = (y + h / 2) / img_height
norm_w = w / img_width
norm_h = h / img_height
# 类别ID重置为0(仅检测TV)
f.write(f"0 {x_center} {y_center} {norm_w} {norm_h}\n")
注意:请根据实际路径修改coco_path和save_path。
第三步:配置数据YAML文件
为YOLO模型准备一个YAML文件,指定数据集路径和类别信息。
tv_data.yaml
path: /path/to/tv_dataset # 数据集根目录
train: train2017/images # 训练集图像路径
val: val2017/images # 验证集图像路径
names:
0: TV # 类别名称
注意:将/path/to/tv_dataset替换为实际的tv_dataset目录路径。
第四步:使用Optuna进行超参数调优
Optuna是一个自动超参数优化工具,可以帮助我们找到最佳的训练超参数组合。关于Optuna的详细介绍,可参考这篇博客。
调优脚本
import optuna
from ultralytics import YOLO
# 定义超参数搜索空间
def objective(trial):
# 生成超参数建议值
lr0 = trial.suggest_float("lr0", 1e-4, 1e-2, log=True)
weight_decay = trial.suggest_float("weight_decay", 0.0001, 0.001)
momentum = trial.suggest_float("momentum", 0.9, 0.99)
hsv_h = trial.suggest_float("hsv_h", 0.0, 0.1) # 数据增强参数
# 加载模型
model = YOLO("yolov8s.yaml").load("yolov8s.pt")
# 训练配置
results = model.train(
data="tv_data.yaml",
epochs=50,
imgsz=640,
batch=16,
lr0=lr0,
weight_decay=weight_decay,
momentum=momentum,
hsv_h=hsv_h,
verbose=False,
project="optuna_tv_detection",
name=f"trial_{trial.number}"
)
# 获取验证集mAP作为优化目标
return results.results_dict["metrics/mAP50-95(B)"]
# 运行Optuna优化
study = optuna.create_study(direction="maximize")
study.optimize(objective, n_trials=30)
# 输出最佳参数
print("Best trial:")
trial = study.best_trial
print(f" mAP: {trial.value}")
print(" Params: ")
for key, value in trial.params.items():
print(f" {key}: {value}")
说明:
- Optuna会尝试30组超参数组合,选择mAP(mean Average Precision)最高的模型。
- 训练过程中,每组超参数的权重和结果会保存在
optuna_tv_detection目录下。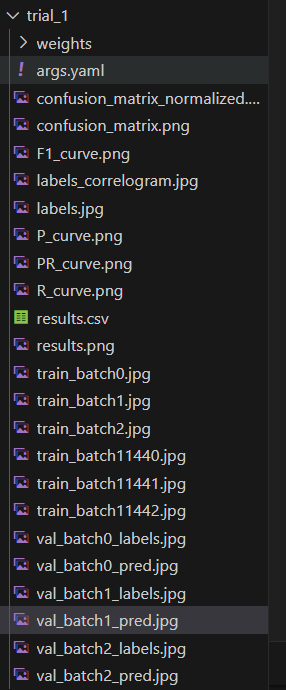
最终的输出log
Best trial:
mAP: 0.6687146125607054
Params:
lr0: 0.00474561659830347
weight_decay: 0.000457461385055744
momentum: 0.9853476457931238
hsv_h: 0.06618514221805666
注意:工业场景通常要求mAP≥0.7。若未达到要求,可增加训练轮数(epochs)或调整搜索空间。
第五步:模型推理
使用最佳模型权重进行图像和视频的推理测试。我们就直接拿第21次出的模型, 用于推理就可以啦,这里给一个测试的脚本用于导入你需要的数据,就能检测效果了
图像推理脚本
from ultralytics import YOLO
import cv2
import os
# 加载最佳模型
best_model = YOLO("/path/to/optuna_tv_detection/trial_21/weights/best.pt") # 替换为实际路径
def test_image(img_path):
# 进行预测
results = best_model.predict(
source=img_path,
imgsz=640,
conf=0.5,
iou=0.45,
show=True,
save=True,
project="optuna_test_results"
)
print(f"results: {results}")
# 加载原始图像
img = cv2.imread(img_path)
if img is None:
raise ValueError(f"无法加载图像: {img_path}")
# 获取检测框信息
boxes = results[0].boxes.data # [x1, y1, x2, y2, conf, class]
# 绘制检测框
for box in boxes:
x1, y1, x2, y2, conf, cls = box
x1, y1, x2, y2 = map(int, [x1, y1, x2, y2])
label = f"{int(cls)}: {conf:.2f}"
cv2.rectangle(img, (x1, y1), (x2, y2), (0, 255, 0), 2)
cv2.putText(img, label, (x1, y1 - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
# 保存绘制后的图像
save_path = os.path.join("optuna_test_results", os.path.basename(img_path))
cv2.imwrite(save_path, img)
print(f"保存带标注的图像到: {save_path}")
return boxes
# 测试示例
if __name__ == "__main__":
test_image("coco/val2017/000000000139.jpg")
视频推理脚本
from ultralytics import YOLO
import cv2
from matplotlib import pyplot as plt
# 加载最佳模型
best_model = YOLO("/path/to/optuna_tv_detection/trial_21/weights/best.pt") # 替换为实际路径
def test_video(video_path):
cap = cv2.VideoCapture(video_path)
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
results = best_model.predict(
source=frame,
imgsz=640,
stream=False
)
annotated_frame = results[0].plot()
frame_rgb = cv2.cvtColor(annotated_frame, cv2.COLOR_BGR2RGB)
plt.imshow(frame_rgb)
plt.pause(0.001)
plt.clf()
cap.release()
# 测试示例
if __name__ == "__main__":
test_video("tv_2_move.avi")
注意:将模型路径替换为实际的best.pt文件路径。
单帧图片推理效果如下:

总结
通过以上步骤,我们成功从YOLOv8s预训练模型中调优出一个专门检测电视的模型。利用COCO数据集提取电视类别数据,并结合Optuna进行超参数优化,最终获得了性能最佳的模型。这种方法无需额外标注数据,成本低且实用性强,适用于快速部署客制化目标检测模型的场景。其实最好的是自己想让模型适应什么场景,直接打标一些数据重新训练就可以了!本文只是简单的示例,调优还是有很多工作可以做的,比如冻结特征提取层,只调优部分模型的权重等等,以后可以和大家一一介绍。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 35
35 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)