Harness 多模型/Agent 路由与评测策略文档
Harness 多模型/Agent 路由与评测策略文档
一、策略设计总则
1.1 核心目标
围绕 Harness 8 个任务阶段,实现「模型/Agent 最优匹配」,在保证任务质量的前提下,平衡执行效率、成本控制与结果可靠性;通过持续评测与数据积累,让路由策略实现自迭代,同时解决多模型矛盾/背书场景的决策难题,支撑复杂任务全流程顺畅推进。
核心原则
- 阶段适配:模型/Agent 选型与当前阶段的核心需求强绑定(如推理复杂度、上下文长度、操作类型);
- 动态调优:基于任务反馈、模型表现数据,自动调整路由策略,实现“能降级则降级、需升级则升级”;
- 成本可控:优先使用低成本、快速模型完成基础任务,仅在必要时升级强推理模型;
- 结果可验:所有模型/Agent 输出均需经过校验,明确“可采纳”标准,杜绝无效输出;
- 可追溯:完整记录模型调用、输出结果、评测数据,为策略迭代和问题排查提供支撑。
涉及模型/Agent 能力梳理
二、分阶段模型/Agent 路由策略(核心)
结合 8 个任务阶段的核心需求,明确每个阶段的「默认模型/Agent」「升级条件」「降级条件」,实现动态路由,平衡质量、效率与成本。
2.1 各阶段路由详情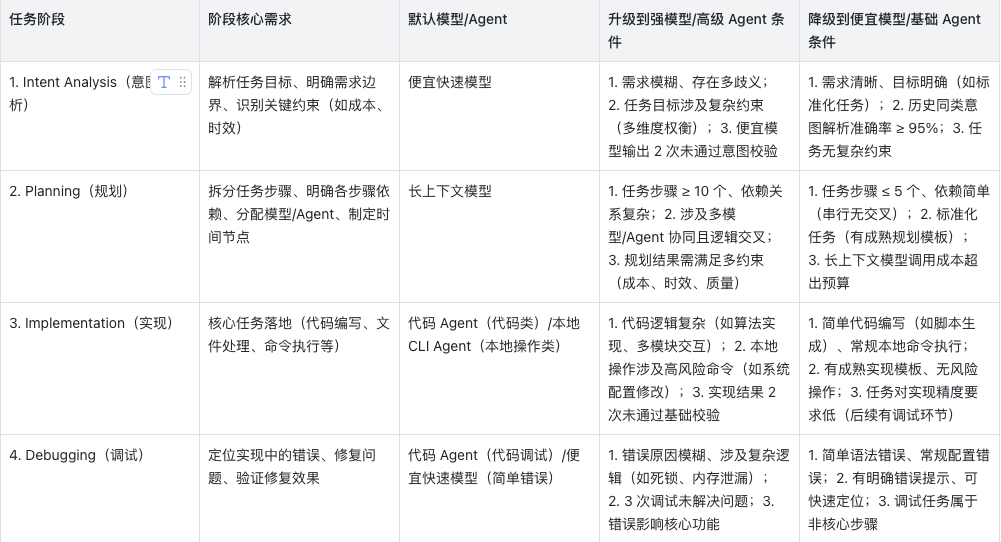
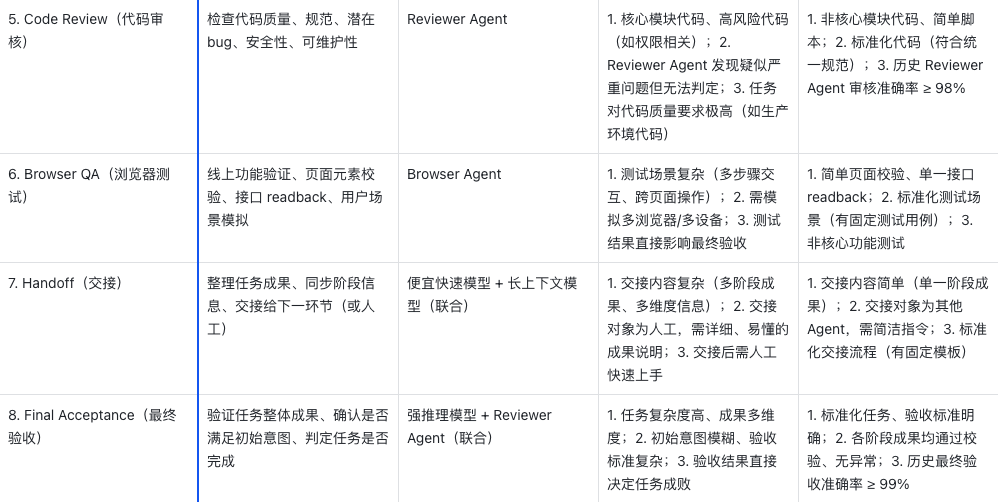
2.2 路由触发机制
- 默认触发:进入对应任务阶段后,自动调用「默认模型/Agent」,无需人工干预;
- 升级触发:满足该阶段「升级条件」时,由 Supervisor 自动终止当前模型/Agent 调用,切换为强模型/高级 Agent,记录升级原因和时间;
- 降级触发:满足该阶段「降级条件」时,由 Supervisor 自动切换为便宜模型/基础 Agent,若已调用强模型,可终止当前调用(节省成本),记录降级原因和时间;
- 人工干预:特殊场景下(如模型输出异常、任务紧急调整),人工可手动调整模型/Agent,操作记录留存至日志。
三、模型输出可采纳判定标准
为避免无效输出、错误输出进入下一环节,明确所有模型/Agent 输出的「可采纳标准」,由 Supervisor 或对应校验 Agent 执行判定,未通过则触发重试、模型升级或人工介入。
3.1 通用可采纳标准(所有模型/Agent 均需满足) - 相关性:输出内容与当前阶段任务目标高度相关,无无关信息、无偏离主题;
- 完整性:覆盖当前阶段核心需求,无关键信息缺失(如规划步骤无遗漏、代码无语法错误);
- 一致性:输出内容内部无逻辑矛盾,与前序阶段成果、任务意图无冲突;
- 可验证:输出结果可通过后续步骤、工具或 Agent 校验(如代码可编译、QA 可验证)。
3.2 各模型/Agent 专属可采纳标准 - 强推理模型/便宜快速模型:输出逻辑清晰、结论明确,无歧义;复杂推理需附带简要推理过程,便于校验;
- 长上下文模型:上下文关联准确,能复用前序阶段信息,无上下文脱节、信息混淆;
- 代码 Agent:代码可编译通过、无语法错误;符合预设代码规范;核心逻辑能实现预期功能;
- Browser Agent:操作步骤可复现;能准确获取目标页面/接口数据;测试结果与预期一致(无漏测、误判);
- Reviewer Agent:审核意见具体、有依据(如指出具体代码行问题);无遗漏严重问题;审核标准与预设一致;
- 本地 CLI Agent:命令执行成功(无报错);操作结果符合预期(如文件修改正确、命令输出正常);无权限异常。
3.3 判定流程与处理逻辑
补充说明:重试次数默认不超过 3 次,每次重试间隔 5-10s;升级模型后仍未通过,立即触发人工介入,避免无效消耗。
四、评测体系设计(benchmark/replay/golden task)
建立完善的评测体系,通过「基准测试、回放测试、黄金任务测试」,持续评估模型/Agent 表现,为路由策略优化提供数据支撑,确保策略的科学性和有效性。
4.1 Benchmark(基准测试):建立性能基线
4.1.1 基准指标设计
围绕「质量、效率、成本」三大核心维度,设计可量化的基准指标,覆盖所有模型/Agent 和任务阶段: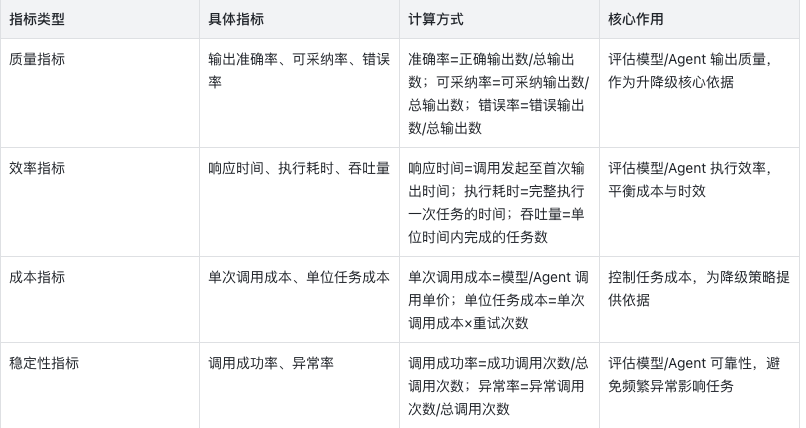
4.1.2 基准测试执行
- 初始化基准:在系统上线初期,对所有模型/Agent 进行全阶段基准测试,记录各指标 baseline(基线值);
- 定期复测:每周执行一次基准测试,每月执行一次全量基准复测,更新指标数据,对比基线值,识别模型表现变化;
- 异常触发:当某模型/Agent 指标出现大幅波动(如准确率下降 ≥ 10%、异常率上升 ≥ 15%),立即触发紧急基准测试,排查原因。
4.2 Replay(回放测试):复现真实场景
基于历史真实任务数据,进行回放测试,模拟实际运行场景,评估模型/Agent 在真实任务中的表现,避免基准测试与实际场景脱节。
4.2.1 回放数据采集 - 采集范围:历史完成的任务(成功/失败)、模型调用记录、输出结果、校验记录、人工干预记录;
- 数据筛选:优先筛选高频任务、复杂任务、曾出现异常的任务,确保回放场景的代表性;
- 数据脱敏:对敏感信息(如核心代码、隐私数据)进行脱敏处理,确保数据安全。
4.2.2 回放测试执行 - 自动回放:每周自动回放 100-200 条历史任务数据,使用当前路由策略调用模型/Agent,记录表现指标;
- 对比分析:将回放测试结果与历史真实结果对比,评估路由策略的优化效果(如可采纳率提升、成本降低);
- 问题定位:若回放测试中出现模型输出异常、路由错误,定位原因(如模型版本更新、策略参数不合理),及时优化。
4.3 Golden Task(黄金任务):标准化校验
设计一批标准化的“黄金任务”,覆盖 8 个任务阶段、不同复杂度场景,作为模型/Agent 表现的“标准校验工具”,确保评测的一致性。
4.3.1 黄金任务设计原则 - 覆盖性:每个任务阶段设计 5-10 个黄金任务,涵盖简单、中等、复杂三种复杂度;
- 标准化:每个黄金任务有明确的输入、预期输出、验收标准,无歧义;
- 稳定性:黄金任务不频繁修改,仅在任务流程、模型能力升级时更新;
- 可量化:验收标准可量化(如代码编译通过率 100%、QA 测试通过率 100%),便于自动评测。
4.3.2 黄金任务应用 - 模型准入:新模型/Agent 接入 Harness 时,需通过对应阶段的黄金任务测试,指标达标方可接入;
- 日常校验:每日执行一次黄金任务测试,快速检测模型/Agent 表现是否稳定;
- 策略优化:通过黄金任务测试结果,对比不同模型/Agent 在同一任务中的表现,优化路由策略(如调整默认模型、升降级条件)。
五、模型表现记录与路由策略自迭代机制
建立“记录-分析-优化-迭代”的闭环,完整记录模型表现数据,通过数据分析识别问题,自动优化路由策略,实现策略随时间持续改进。
5.1 模型表现记录规范
5.1.1 记录内容(全量可追溯) - 基础信息:任务 ID、任务阶段、调用的模型/Agent 类型、调用时间、结束时间;
- 输入输出:模型/Agent 的输入参数、输出结果、可采纳判定结果、校验记录;
- 性能指标:响应时间、执行耗时、调用成本、准确率、可采纳率、异常信息;
- 路由信息:是否触发升级/降级、升级/降级原因、人工干预记录;
- 关联数据:与该模型/Agent 相关的前序/后续步骤成果、黄金任务测试结果、回放测试结果。
5.1.2 记录存储与检索 - 存储介质:采用“MySQL + ElasticSearch”联合存储,MySQL 存储结构化数据(如指标、基础信息),ElasticSearch 存储非结构化数据(如输出结果、日志);
- 检索维度:支持按任务 ID、任务阶段、模型/Agent 类型、时间范围、性能指标检索,便于数据分析;
- 数据留存:历史数据留存 1 年,核心数据(如黄金任务、异常记录)永久留存,用于长期策略优化。
5.2 路由策略自迭代机制
基于模型表现记录、评测数据,由 Supervisor 自动触发策略优化,每月进行一次全量迭代,紧急异常时触发临时迭代。
5.2.1 迭代分析维度 - 模型表现分析:识别各模型/Agent 在不同阶段、不同复杂度任务中的优势/劣势(如某便宜模型在简单意图分析中准确率达 98%,可扩大其使用场景);
- 升降级逻辑分析:统计升级/降级触发的频率、原因,优化升降级条件(如某阶段升级强模型后准确率提升不明显,可调整升级阈值);
- 成本效率分析:对比不同模型/Agent 的“成本-质量”比,优先选择性价比高的模型(如便宜模型准确率仅比强模型低 2%,但成本低 80%,可调整默认模型);
- 异常分析:统计模型异常、输出不可采纳的高频场景,优化路由策略(如某模型在复杂规划中异常率高,可直接将复杂规划的默认模型升级为强模型)。
5.2.2 迭代执行流程
5.2.3 人工兜底优化
每月迭代后,人工审核优化效果,针对自动迭代无法解决的问题(如多模型矛盾场景、复杂任务路由不合理),手动调整策略;每季度进行一次全量策略复盘,结合业务场景变化,优化模型选型和路由逻辑。
六、多模型矛盾/背书场景的 Supervisor 决策策略
当多个模型/Agent 针对同一任务输出(或同一环节)出现「矛盾」(输出不一致)或「背书」(输出一致)时,Supervisor 需基于证据、模型表现、任务优先级,做出科学决策,确保任务推进的正确性。
6.1 多模型背书场景(输出一致):优先采纳,谨慎校验
背书定义
2 个及以上不同类型/不同等级的模型/Agent,针对同一任务输出(或同一校验点),给出一致的结果(如 Reviewer Agent 与强推理模型均认为代码无问题)。
决策策略
- 基础原则:优先采纳背书结果,减少人工干预,提升效率;
- 校验要求:若背书模型包含强推理模型/Reviewer Agent,可简化校验流程(仅执行核心校验);若仅为便宜模型/基础 Agent 背书,需执行完整校验,避免“集体出错”;
- 特殊处理:若背书结果与前序阶段成果、任务意图有轻微偏差,触发简单重试;若偏差较大,即使背书一致,也需人工介入核查。
6.2 多模型矛盾场景(输出不一致):分层决策,证据优先
矛盾定义
2 个及以上不同类型/不同等级的模型/Agent,针对同一任务输出(或同一校验点),给出相互冲突的结果(如代码 Agent 认为代码无错,Reviewer Agent 认为存在严重 bug)。
决策优先级(从高到低)
- 第一步:基于证据校验矛盾结果
- 第二步:结合模型表现数据决策
- 若强推理模型与便宜模型矛盾,且强推理模型表现更优(准确率 ≥ 95%),优先采纳强推理模型;若便宜模型表现接近(准确率 ≥ 93%),且成本更低,可触发人工复核后决定;
- 若同类型模型矛盾(如两个代码 Agent),优先采纳历史表现更优、调用成功率更高的模型;
- 若 Agent 与模型矛盾(如 Browser Agent 测试通过,强推理模型认为测试不完整),优先采纳 Agent 输出(Agent 更贴近实际操作,证据更直观)。
- 第三步:结合任务优先级决策
- 高优先级任务(如生产部署、核心功能开发):优先采纳强推理模型/Reviewer Agent 输出,触发人工复核,确保结果正确;
- 普通优先级任务:优先采纳成本低、效率高的模型输出,后续通过调试、QA 环节验证;
- 低优先级任务:可随机采纳一个结果,后续若发现错误,触发重试和模型升级。
- 第四步:人工介入兜底
6.3 决策记录与优化
所有多模型矛盾/背书场景的决策过程、结果、依据,均需完整记录至日志;每月迭代时,分析矛盾/背书高频场景,优化路由策略(如调整模型选型、增加校验环节),减少矛盾场景的出现。
七、总结
本策略围绕 Harness 8 个任务阶段,实现了多模型/Agent 的精准路由、动态升降级,通过明确的输出可采纳标准、完善的评测体系,确保任务质量与成本平衡;同时建立了策略自迭代机制和多模型决策规则,解决了复杂场景下的模型选型与决策难题。
策略落地后,可通过持续的评测数据积累、策略迭代,逐步提升模型调用的性价比和任务执行的可靠性,支撑 Harness 长期稳定运行,适配复杂工程任务的全流程需求。后续可结合实际业务场景,进一步优化模型表现指标、升降级条件和决策规则,提升策略的灵活性和适配性。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)