LangGraph 到底有什么用?一文讲透 AI Agent 工作流
如果你已经会写一个简单 Agent,下一步真正难的不是“再多调一个工具”,而是让它稳定完成复杂任务:前一步的结果怎么保存?下一步该谁执行?什么时候继续,什么时候结束?如果中途需要返工,流程又该回到哪里?
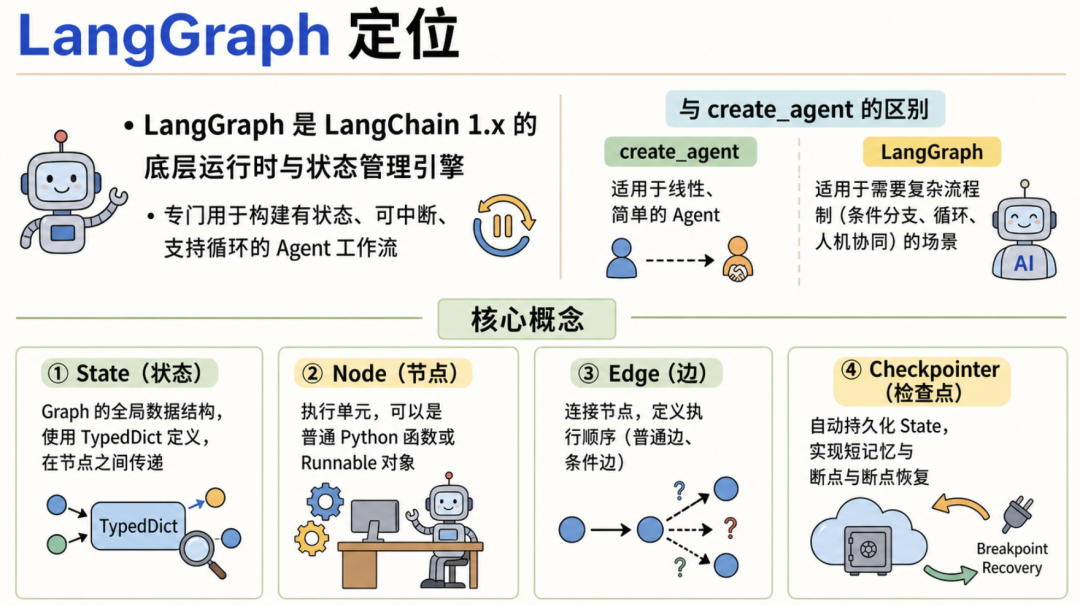
LangGraph 解决的就是这个问题。它不是一个让模型变聪明的魔法工具,而是一个用来组织 Agent 工作流的框架。它把复杂任务拆成一个个节点,用状态保存上下文,用边控制执行路线,再用检查点让流程可以恢复。
读完这篇文章,你至少能搞清楚三件事:
第一,Graph、State、Node、Edge、Checkpointer 分别是什么;
第二,为什么条件边和检查点对 Agent 很重要;
第三,多个 Agent 协作时,为什么监督者模式更适合流程清晰的任务。前面会用加法器把概念讲简单,后面再过渡到多 Agent 协作案例。
一、先安装 LangGraph
开始之前,先安装 LangGraph:pip install langgraph
如果后面要做联网搜索和大模型调用,还会用到 Tavily、LangChain、模型服务等依赖。但理解 LangGraph 的核心概念,不需要一开始就把所有工具都接上。我们先从最小例子开始。
二、用一个加法器理解 Graph 的基本结构
LangGraph 里的 Graph,可以先理解为一张“流程图”。这张图里有三件最重要的东西:
State:流程中一直传递的数据。
Node:真正执行任务的函数或 Agent。
Edge:节点之间的连线,决定执行顺序。
先看一个简单加法器。它的目标很朴素:传入一个新数字,把它加入 numbers 列表,再计算 total。这个例子不复杂,但非常适合用来理解 LangGraph 的基本结构。
from typing import TypedDict
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.constants import END
from langgraph.graph import StateGraph
#定义状态类
#total 表示所有的字段都是可选的,可以不用全部初始化
class AdderState(TypedDict,total=False):
numbers: list
total: int
new_number: int
def add_number(state: AdderState) -> AdderState:
new_number = state.get("new_number",0)
numbers = state.get("numbers", [])
numbers.append(new_number)
total = sum(numbers)
#更新状态信息
return {"numbers": numbers, "total": total}
#创建一个 状态图 构造器
builder = StateGraph(AdderState)
#添加节点
builder.add_node("add",add_number)
#设置入门点
builder.set_entry_point("add")
#添加边:执行完 add -》 结束
builder.add_edge("add",END)
#编译 状态图 graph
graph = builder.compile()
#初始化 状态
initial_state = {"numbers": [], "total": 0, "new_number": 5}
result = graph.invoke(initial_state)
print(f"结果:{result}")运行结果: 结果:{'numbers': [5], 'total': 5, 'new_number': 5}
这段代码虽然简单,但已经把 LangGraph 的基本工作方式讲清楚了。
首先,`AdderState` 定义了整个流程会用到哪些数据。这里有数字列表 `numbers`、总和 `total`,以及本次新增的数字 `new_number`。
其次,`add_number` 是一个节点函数。它接收 state,读取里面的数据,完成计算,再返回新的字段。LangGraph 会把返回结果合并回原来的状态里。
最后,`builder.add_edge("add", END)` 表示执行完 add 节点之后,流程结束。
所以,Graph 并不是一个神秘概念。它就是把“数据怎么传、函数怎么跑、下一步去哪里”这三件事组织起来。
三、为什么需要条件边?因为真实流程不总是直线
上面的加法器只执行一次,流程很简单:开始 → add → 结束。
但真实任务经常不是这样。比如我们希望不断加 1,直到 total 达到 10 才停止。这时候流程就需要循环。
接下来把例子稍微升级:让加法器不断加 1,直到 total 达到 10 才停止。这个例子用来说明条件边为什么重要。
# 带循环的 Graph
def add_one(state: AdderState) -> AdderState:
numbers = state.get("numbers", [])
numbers.append(1)
total = sum(numbers)
#更新状态信息
return {"numbers": numbers, "total": total}
builder2 = StateGraph(AdderState)
builder2.add_node("add",add_one)
builder2.set_entry_point("add")
#条件边
def should_continue(state:AdderState) ->str:
if state["total"] <10:
return "add"
else:
return "end"
#设置 条件分支
#add 源节点的名称
#should_continue 条件判断的函数
#"end":END 条件判断后 执行的 节点
builder2.add_conditional_edges("add",should_continue,{
"add":"add",
"end":END
})
graph2 = builder2.compile()
result2 = graph2.invoke({"numbers": [], "total": 0})
print(f"结果:{result2}")运行结果:结果:{'numbers': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1], 'total': 10}
这里的关键是 `add_conditional_edges`。
普通边只告诉 Graph:“执行完这个节点,固定去下一个节点。”
条件边则告诉 Graph:“执行完这个节点以后,先看一下当前 state,再决定下一步去哪里。”
这个能力非常重要。因为 Agent 工作流里经常会出现这种判断:资料够不够?文章写完了吗?审阅通过了吗?如果不通过,要不要回到写作节点?
从这个加法器开始,我们已经能看到 LangGraph 的核心优势:它不是只能执行一条直线,而是可以根据状态做分支和循环。
四、Checkpointer:让流程有记忆,可以接着跑
理解了条件边之后,再看 Checkpointer,也就是检查点。
如果说 State 是当前流程的数据,那么 Checkpointer 就是把这些数据保存下来的机制。它可以让同一个会话在下一次调用时恢复之前的状态。
这里使用 `InMemorySaver` 做一个最小示例:
#检查点
builder3 = StateGraph(AdderState)
builder3.add_node("add",add_number)
builder3.set_entry_point("add")
builder3.add_edge("add",END)
checkpointer = InMemorySaver()
graph3 = builder3.compile(checkpointer=checkpointer)
config={
"configurable":{"thread_id":"session_123"}
}
result3 = graph3.invoke({"numbers": [], "total": 0, "new_number": 3}, config=config)
print(f"第一次执行结果:{result3}")
result4 = graph3.invoke({"new_number": 5}, config=config)
print(f"第二次执行结果:{result4}")这里的重点是 `thread_id`。
第一次执行结果:{'numbers': [3], 'total': 3, 'new_number': 3}
第二次执行结果:{'numbers': [3, 5], 'total': 8, 'new_number': 5}
第一次调用时,我们传入 3,状态里会记录 numbers 和 total。第二次调用时,我们只传入 `new_number: 4`,但因为使用的是同一个 `thread_id`,LangGraph 可以恢复之前的状态,再继续计算。
这就像给工作流加了“记忆”。
在简单加法器里,它只是记住了之前加过的数字。但放到真实 Agent 系统里,它可以记住用户需求、历史消息、搜索结果、文章草稿、审阅意见和最终结果。
这也是 LangGraph 很适合复杂 Agent 应用的原因:任务可以中断,可以继续,可以围绕同一个会话逐步推进。
五、为什么需要多个 Agent?
理解了 State、Node、Edge、Checkpointer 之后,我们再看多 Agent 就顺很多。
一个典型的复杂场景是研究写作类任务。它不是简单生成一段文字,而是包含资料获取、信息整理、结构组织、内容生成、质量检查和修改反馈等多个环节。
如果把这些环节都交给同一个 Agent,它当然可以尝试完成。但任务越复杂,单个 Agent 越容易混乱:它既要找资料,又要组织内容,还要做审阅,最后还要自己判断下一步。
如果这些事情都交给一个 Agent,它当然也能尝试完成。但问题是,任务越复杂,单个 Agent 越容易混乱。它既要搜索,又要写作,还要审阅,还要决定下一步做什么。
多个 Agent 的意义就在这里:让每个 Agent 专注于一个领域或工具集。研究 Agent 负责资料,写作 Agent 负责表达,审阅 Agent 负责质量检查,协调者负责调度流程。
这样做有三个好处。
第一,专业性更强。每个 Agent 的系统提示词可以更聚焦。
第二,可维护性更好。哪个环节出问题,就改哪个节点。
第三,更容易扩展。后面要加数据分析 Agent、代码 Agent、翻译 Agent,都可以作为新节点接进来。
不过,多个 Agent 也带来新问题:它们应该怎么协作?
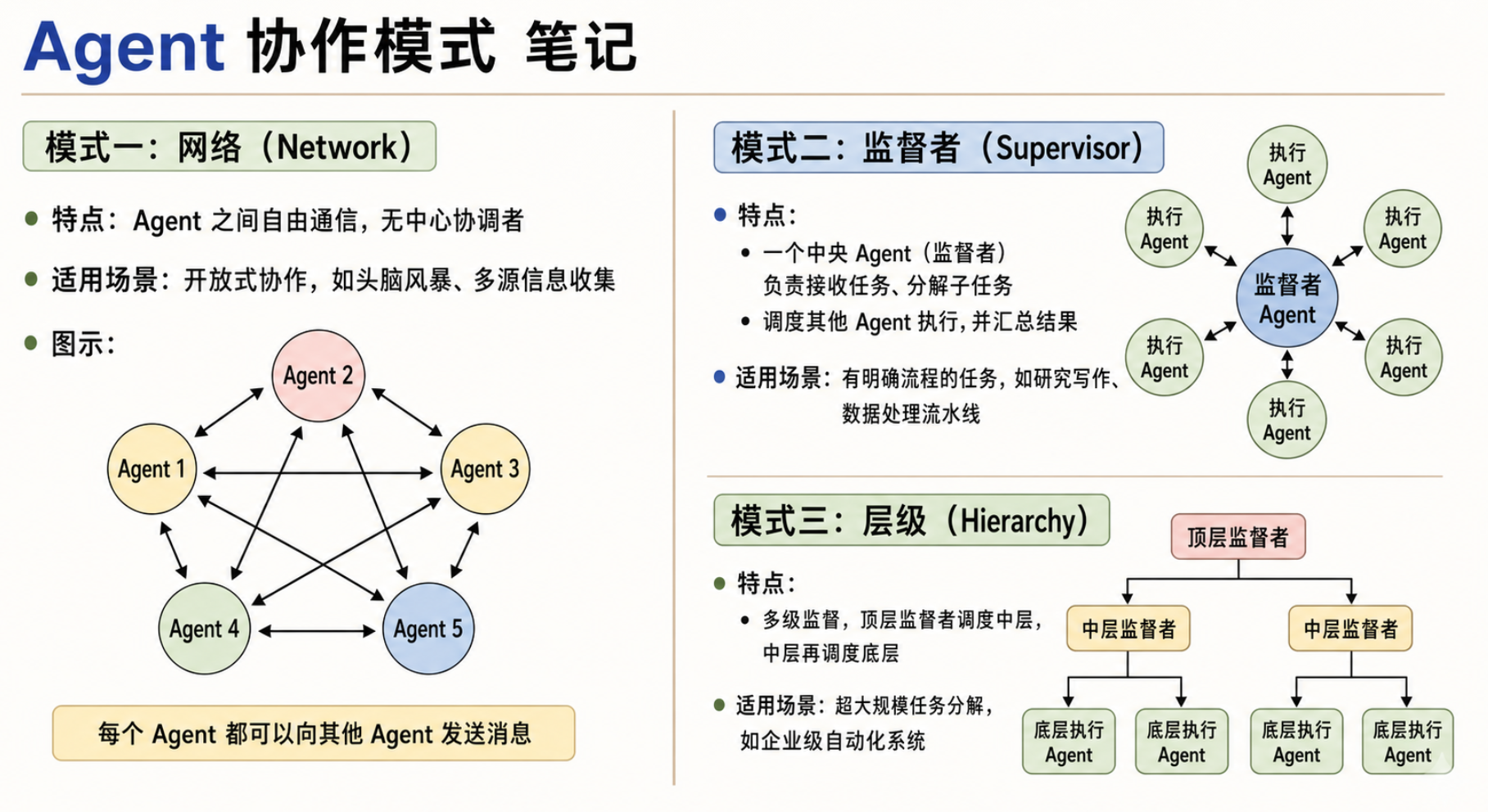
六、三种 Agent 协作模式
多 Agent 协作常见有三种模式:网络模式、监督者模式和层级模式。理解这三种模式,才能知道什么时候该让 Agent 自由沟通,什么时候该让一个 Supervisor 统一调度。
1. 网络模式:Agent 之间自由通信
网络模式里,Agent 之间可以自由发送消息,没有中心协调者。
这种模式适合开放式协作,比如头脑风暴、多源信息收集、观点碰撞。它的优点是灵活,每个 Agent 都可以直接和其他 Agent 交流。
但它也有明显缺点:协调成本高。因为没有一个统一调度者,任务很容易出现重复、冲突或者方向不一致。
所以,网络模式更适合开放探索,不太适合流程明确的任务。
2. 监督者模式:一个中央 Agent 负责调度
监督者模式里,有一个中央 Agent,也就是 Supervisor。
Supervisor 负责接收任务、拆解任务、分配任务,并汇总结果。其他 Agent 是执行者,按照 Supervisor 的安排完成各自工作。
这个模式非常适合有明确流程的任务,比如研究写作、数据处理流水线、报告生成。它的优点是流程清晰、可控性强。
当然,它也有一个潜在问题:Supervisor 可能成为瓶颈。因为所有调度都要经过它,所以 Supervisor 的判断质量会直接影响整个系统。
3. 层级模式:多级监督者逐层分发
层级模式可以理解为监督者模式的扩展。
顶层监督者负责总目标,中层监督者负责模块拆解,底层 Agent 负责具体执行。它适合超大规模任务,比如企业级自动化系统。
它的优势是可扩展性强,但实现更复杂。对于刚开始搭建多 Agent 系统的人来说,通常不建议一上来就做层级模式。
综合来看,监督者模式最适合从入门走向实战:它既能体现多 Agent 分工,又不会让系统一开始就变得过于复杂。
七、用 LangGraph 实现监督者 Agent
下面看一个监督者 + 两个工作 Agent 的例子:一个搜索 Agent,一个总结 Agent。这个例子可以帮助我们理解 Supervisor 如何做任务分发。
整体结构是这样的:
用户输入任务后,先进入 supervisor 节点。supervisor 根据用户消息判断任务类型。如果用户说“搜索”“查找”“信息”“数据”,就走搜索 Agent;如果用户说“总结”“概括”“归纳”,就走总结 Agent。
这就是监督者模式在 LangGraph 里的落地方式。
class MultiAgentState(TypedDict):
messages: List
current_agent: Optional[str]
task_type: Optional[str]这个 State 保存了消息列表、当前 Agent 和任务类型。对于多 Agent 系统来说,`messages` 很关键,因为它承载了用户输入和各个 Agent 的输出。
搜索 Agent 的职责是使用 Tavily 查询信息,并把搜索结果追加到 messages 中:
def search_agent(state: MultiAgentState):
messages = state["messages"]
# 最后一条用户的消息
last_message = messages[-1] if messages else None
search_query=""
if isinstance(last_message,HumanMessage):
search_query=last_message.content
try:
search_results = tavily.search(query=search_query, search_depth="basic")
results=[]
for result in search_results.get("results", [])[:3]:
title = result.get("title", "")
snippet = result.get("snippet", "")
results.append(f"-{title} : {snippet}")
if results:
response = "搜索结果:\n"+"\n".join(results)
else:
response = "搜索结果: 未找到相关的信息"
except Exception as e:
response = f"搜索结果:搜索失败,错误信息 {str(e)}"
return {
"messages": messages+[AIMessage(content=response,name="search_agent")],
"current_agent": "search_agent"
}总结 Agent 的职责则是读取历史消息,把用户问题和搜索结果组织起来,再调用模型生成总结。
真正决定路线的是 supervisor:
# 监督者
def supervisor(state: MultiAgentState):
messages = state["messages"]
last_message = messages[-1] if messages else None
if isinstance(last_message,HumanMessage):
content = last_message.content.lower()
if any(keyword in content for keyword in ["搜索","查找","信息","数据"]):
next_node="search"
elif any(keyword in content for keyword in ["总结","概括","归纳"]):
next_node="summary"
else:
next_node="search"
else:
next_node="search"
return {"next":next_node}这段代码看起来不复杂,但它体现了监督者模式的核心:工作节点只负责执行,Supervisor 负责判断下一步。
然后用条件边把 supervisor 的判断接到不同节点:
builder.add_conditional_edges(
"supervisor",
lambda state: state.get("next","search"),
{
"search":"search",
"summary":"summary"
}
)
builder.add_edge("search",END)
builder.add_edge("summary",END)到这里,一个简单的监督者多 Agent 系统就完成了。
完整代码:
import os
from typing import TypedDict, List, Optional
from langchain_core.messages import HumanMessage, AIMessage
from langchain_openai import ChatOpenAI
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.constants import END
from langgraph.graph import StateGraph
from tavily import TavilyClient
if not os.getenv("DASHSCOPE_API_KEY"):
raise ValueError("请先配置DASHSCOPE_API_KEY")
tavily = TavilyClient(api_key='tvly-dev-381111111111111111111111111111111111X')
model = ChatOpenAI(
model="qwen3.5-plus",
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
temperature=0.3
)
class MultiAgentState(TypedDict):
messages: List
current_agent: Optional[str]
task_type: Optional[str]
def search_agent(state: MultiAgentState):
messages = state["messages"]
# 最后一条用户的消息
last_message = messages[-1] if messages else None
search_query=""
if isinstance(last_message,HumanMessage):
search_query=last_message.content
try:
search_results = tavily.search(query=search_query, search_depth="basic")
results=[]
for result in search_results.get("results", [])[:3]:
title = result.get("title", "")
snippet = result.get("snippet", "")
results.append(f"-{title} : {snippet}")
if results:
response = "搜索结果:\n"+"\n".join(results)
else:
response = "搜索结果: 未找到相关的信息"
except Exception as e:
response = f"搜索结果:搜索失败,错误信息 {str(e)}"
return {
"messages": messages+[AIMessage(content=response,name="search_agent")],
"current_agent": "search_agent"
}
# 总结
def summarize_agent(state: MultiAgentState):
messages = state["messages"]
content_to_summarize = ""
for message in messages:
if isinstance(message,HumanMessage):
content_to_summarize+=f"用户:{message.content}\n"
elif isinstance(message,AIMessage):
content_to_summarize+=f"搜索结果:{message.content}\n"
try:
summary_prompt=f"请总结一下内容\n\n {content_to_summarize} \n\n 总结:"
summary_response = model.invoke(summary_prompt)
response = f"总结:{summary_response.content}"
except Exception as e:
response = f"总结:总结失败 错误信息 {str(e)}"
return {
"messages": messages+[AIMessage(content=response,name="summarize_agent")],
"current_agent": "summarize_agent"
}
# 监督者
def supervisor(state: MultiAgentState):
messages = state["messages"]
last_message = messages[-1] if messages else None
if isinstance(last_message,HumanMessage):
content = last_message.content.lower()
if any(keyword in content for keyword in ["搜索","查找","信息","数据"]):
next_node="search"
elif any(keyword in content for keyword in ["总结","概括","归纳"]):
next_node="summary"
else:
next_node="search"
else:
next_node="search"
return {"next":next_node}
builder = StateGraph(MultiAgentState)
builder.add_node("supervisor",supervisor)
builder.add_node("search",search_agent)
builder.add_node("summary",summarize_agent)
builder.set_entry_point("supervisor")
builder.add_conditional_edges(
"supervisor",
lambda state: state.get("next","search"),
{
"search":"search",
"summary":"summary"
}
)
builder.add_edge("search",END)
builder.add_edge("summary",END)
checkpointer = InMemorySaver()
graph = builder.compile(checkpointer=checkpointer)
def test_multi_agent_system():
config = {
"configurable": {"thread_id": "session_123"}
}
result = graph.invoke({"messages": [HumanMessage(content="请搜索2024年奥运会举办的时间和中国代表团的表现")]},
config=config)
print("最后一条消息",result["messages"][-1].content)
result2 = graph.invoke({"messages": [HumanMessage(content="请总结一下2024年奥运会举办的时间和中国代表团的表现")]},
config=config)
print("最后一条消息",result2["messages"][-1].content)
if __name__ == "__main__":
test_multi_agent_system()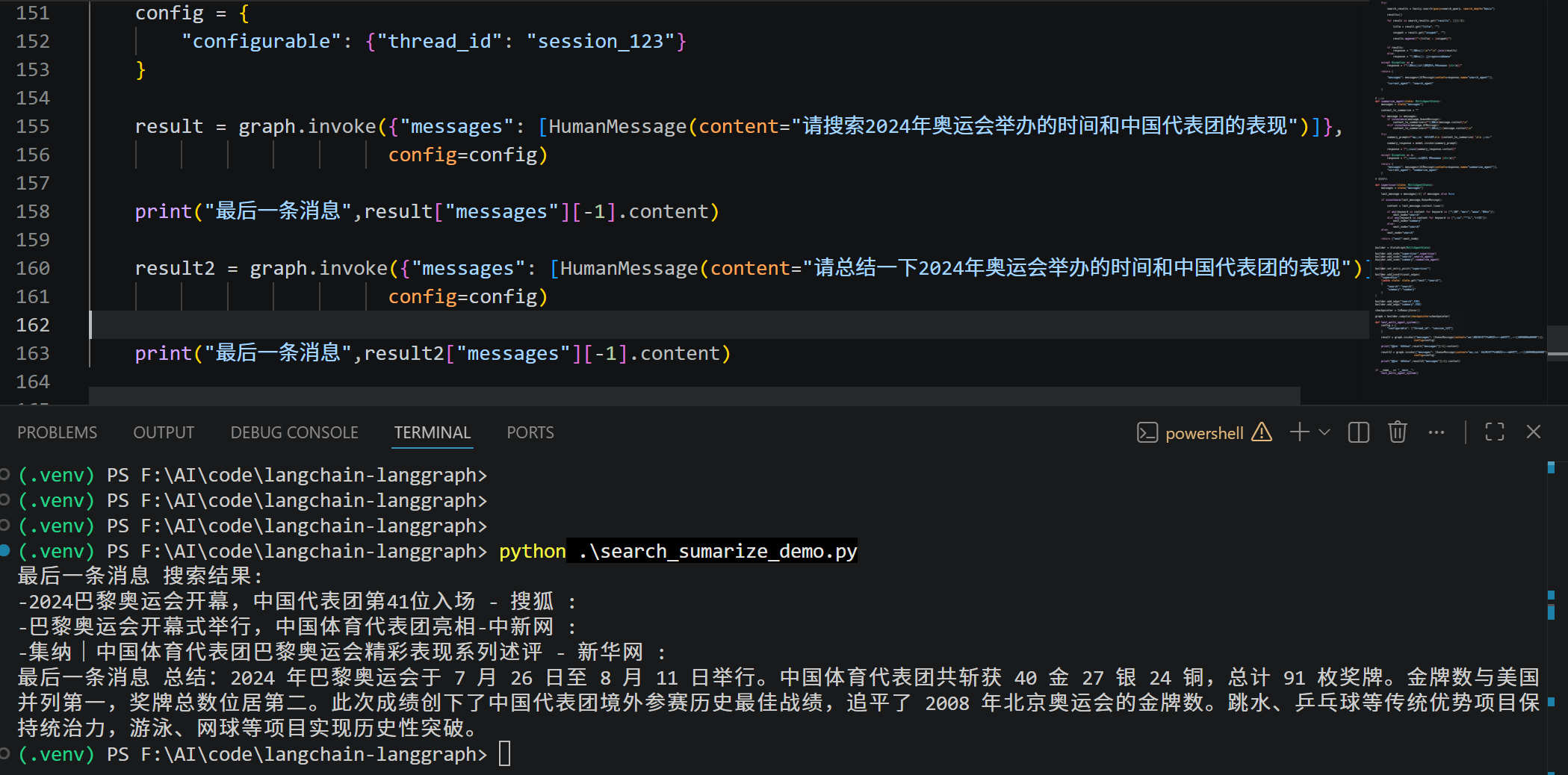
八、架构上应该怎么理解监督者、工作节点和状态?
从架构上看,监督者模式可以拆成三块:左边是监督者节点,中间是工作节点,右边是状态定义。

左边是监督者节点。它负责理解用户需求,决定调用哪个工作节点。它不一定亲自做搜索、写作或分析,而是负责调度计划。
中间是工作节点,比如研究 Agent、写作 Agent、编码 Agent、数据分析 Agent。每个工作节点执行一个具体任务,并把结果写回状态。
右边是状态定义。它保存用户输入、历史消息、各工作节点的输出,以及最终结果。
这个结构对应到 LangGraph 里,就是:
State 保存全局数据。
Node 执行具体动作。
Edge 连接节点并定义流程。
Supervisor 通过条件边决定下一步。
所以,LangGraph 不是简单地“调用多个 Agent”,而是把多 Agent 的协作流程变成一张可以执行、可以判断、可以保存状态的图。
九、实战:搭建一个研究写作团队
再往前一步,可以搭建一个更完整的研究写作团队:研究员、写作者、审阅者和协调者共同完成一个任务。
这个例子比前面的搜索 + 总结更接近真实应用。
角色可以这样理解。
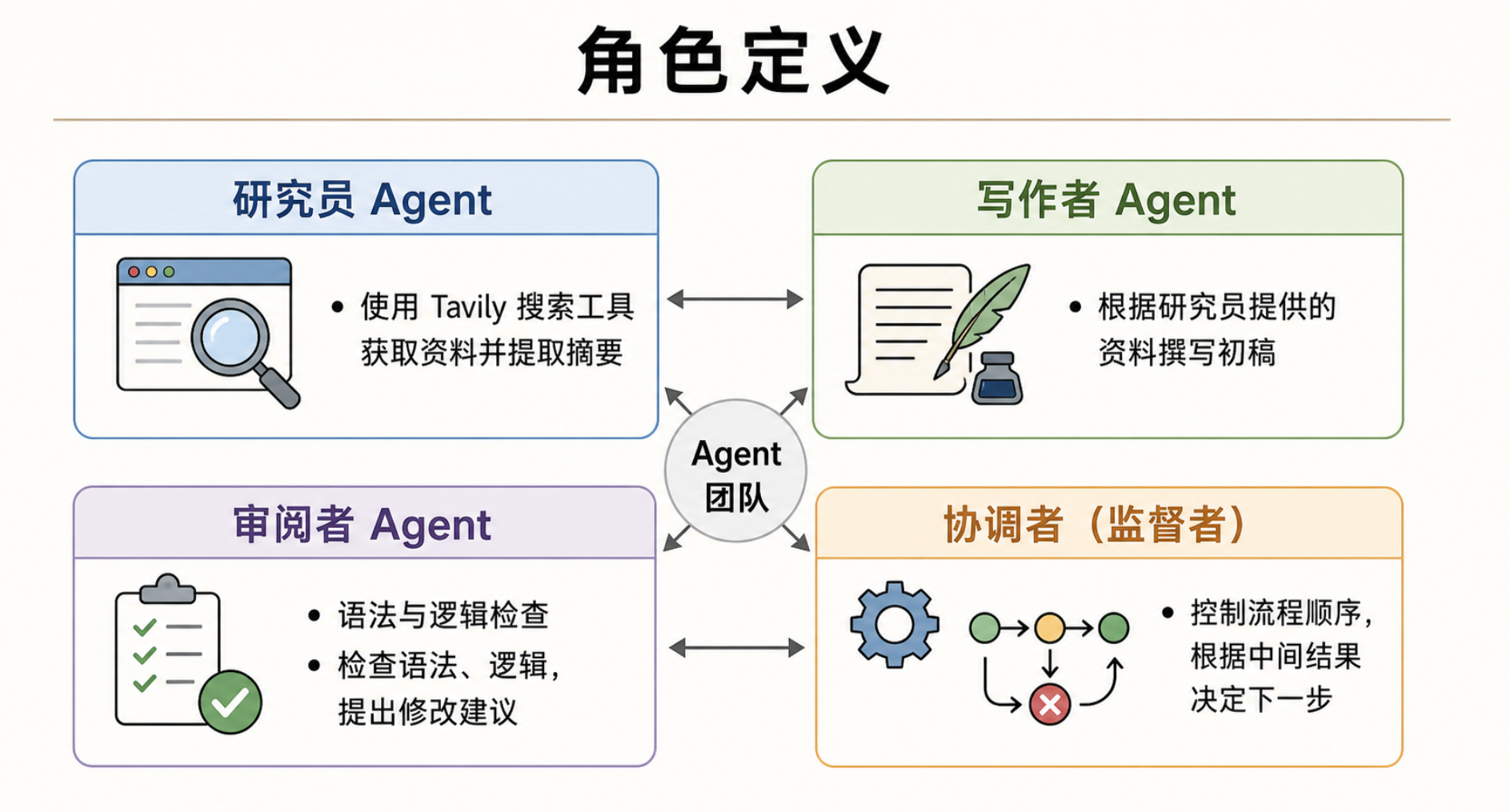
研究员 Agent:使用 Tavily 搜索工具获取资料,并提取摘要。
写作者 Agent:根据研究员提供的资料撰写初稿。
审阅者 Agent:检查文章语法、逻辑和风格,并提出修改建议。
协调者,也就是监督者:控制流程顺序,根据中间结果决定下一步。
这里的关键不是给 Agent 起不同名字,而是让每个角色都有明确职责。角色边界越清楚,整个工作流越容易维护。
研究员解决“资料从哪里来”。
写作者解决“如何把资料写成文章”。
审阅者解决“文章是否通顺、准确、有逻辑”。
协调者解决“下一步该谁来做”。
对应到代码里,State 可以这样定义:
class ResearchState(TypedDict, total=False):
# 研究主题
topic: str
#研究笔记
research_notes: Optional[str]
# 草稿
draft: Optional[str]
# 反馈建议
review_feedback: Optional[str]
# 最终文章
final_article: Optional[str]
#下一步操作
next_step: str这里的字段很清楚:`topic` 是研究主题,`research_notes` 是研究笔记,`draft` 是草稿,`review_feedback` 是审阅意见,`final_article` 是最终文章,`next_step` 用来告诉协调者下一步去哪里。
研究员节点执行完后,把资料写入 `research_notes`,并把下一步设置为 write:
def researcher_node(state: ResearchState) -> ResearchState:topic = state["topic"]response = researcher_agent.invoke({"messages": [("user", topic)]})notes = response["messages"][-1].contentreturn {"research_notes": notes, "next_step": "write"}
写作者节点读取研究笔记,生成草稿,然后把下一步设置为 review:
def writer_node(state: ResearchState) -> ResearchState:
notes = state["research_notes"]
response = writer_agent.invoke({"messages": [("user", f"根据以下资料撰写文字: \n{notes}")]})
draft = response["messages"][-1].content
return {"draft": draft, "next_step": "review"}审阅者节点读取草稿,生成反馈和最终文章:
def reviewer_node(state: ResearchState) -> ResearchState:
draft = state["draft"]
response = reviewer_agent.invoke({"messages": [("user", f"请审阅以下文章:\n{draft}")]})
feedback = response["messages"][-1].content
final = draft if "严重问题" not in feedback else draft + "\n\n【修改建议】\n" + feedback
return {"review_feedback": feedback, "final_article": final, "next_step": "end"}协调者节点最简单,但很关键:它读取 `next_step`,告诉 Graph 下一步该走哪个节点。
def coordinator(state: ResearchState) -> ResearchState:
step = state.get("next_step", "research")
return {"next_step" : step}最后,把这些节点接起来:
builder = StateGraph(ResearchState)
builder.add_node("coordinator",coordinator)
builder.add_node("review",reviewer_node)
builder.add_node("write",writer_node)
builder.add_node("research",researcher_node)
builder.set_entry_point("coordinator")
builder.add_conditional_edges("coordinator",lambda s:s["next_step"],{
"research":"research",
"write":"write",
"review":"review",
"end":END
})
builder.add_edge("research","coordinator")
builder.add_edge("write","coordinator")
builder.add_edge("review","coordinator")这段代码体现了一个完整的监督者式工作流:
先由 coordinator 判断下一步。
如果是 research,就让研究员工作。
研究完成后回到 coordinator。
coordinator 再根据 next_step 调用写作者。
写作完成后再回到 coordinator。
最后进入审阅,审阅完成后结束。
这就是 LangGraph 在多 Agent 协作里的核心价值:它让每个角色专注自己的任务,同时让整个流程保持可控。
完整代码:
import os
from typing import TypedDict, Optional
from langchain.agents import create_agent
from langchain_core.tools import tool
from langchain_openai import ChatOpenAI
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.constants import END
from langgraph.graph import StateGraph
from tavily import TavilyClient
if not os.getenv("DASHSCOPE_API_KEY"):
raise Exception("请设置系统环境变量DASHSCOPE_API_KEY")
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_API_KEY"] = "lsv2_pt1111111111111111a9e35a2ac3b5d_eedec3ebfa"
os.environ["LANGCHAIN_PROJECT"] = "multi_agent_course"
# 初始化模型
model = ChatOpenAI(
model="qwen3.5-plus",
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
temperature=0.3
)
class ResearchState(TypedDict, total=False):
# 研究主题
topic: str
#研究笔记
research_notes: Optional[str]
# 草稿
draft: Optional[str]
# 反馈建议
review_feedback: Optional[str]
# 最终文章
final_article: Optional[str]
#下一步操作
next_step: str
tavily = TavilyClient(api_key='tvly-dev-3hY111111111111111111111111111se')
@tool
def search_web(query: str) ->str:
"""搜索互联网获取事实的信息,参数 query是 搜索关键词,当用户 需要最新的 新闻、天气、事件等时 使用此工具"""
try:
#调用 搜索工具,查询关键词,获取 最多 3条结果
result = tavily.search(query, max_results=3)
summaries = [item["content"] for item in result.get("results",[])]
return "\n".join(summaries) if summaries else "未找到相关的信息"
except Exception as e:
return f"搜索失败:{str(e)}"
researcher_agent = create_agent(model=model, tools=[search_web],
system_prompt="你是一个研究员。根据用户的主题,使用搜索工具收集资料,并整理成要点列表")
writer_agent = create_agent(model=model, tools=[],
system_prompt="你是一个专业的写作者。根据研究院提供的资料,撰写一篇结构清晰、语言流畅的文章")
reviewer_agent = create_agent(model=model, tools=[],
system_prompt="你是一个审阅编辑。检查文章的逻辑、语法、风格,提出修改建议")
def researcher_node(state: ResearchState) -> ResearchState:
topic = state["topic"]
response = researcher_agent.invoke({"messages": [("user", topic)]})
notes = response["messages"][-1].content
return {"research_notes": notes, "next_step": "write"}
def writer_node(state: ResearchState) -> ResearchState:
notes = state["research_notes"]
response = writer_agent.invoke({"messages": [("user", f"根据以下资料撰写文字: \n{notes}")]})
draft = response["messages"][-1].content
return {"draft": draft, "next_step": "review"}
def reviewer_node(state: ResearchState) -> ResearchState:
draft = state["draft"]
response = reviewer_agent.invoke({"messages": [("user", f"请审阅以下文章:\n{draft}")]})
feedback = response["messages"][-1].content
final = draft if "严重问题" not in feedback else draft + "\n\n【修改建议】\n" + feedback
return {"review_feedback": feedback, "final_article": final, "next_step": "end"}
def coordinator(state: ResearchState) -> ResearchState:
step = state.get("next_step", "research")
return {"next_step" : step}
builder = StateGraph(ResearchState)
builder.add_node("coordinator",coordinator)
builder.add_node("review",reviewer_node)
builder.add_node("write",writer_node)
builder.add_node("research",researcher_node)
builder.set_entry_point("coordinator")
builder.add_conditional_edges("coordinator",lambda s:s["next_step"],{
"research":"research",
"write":"write",
"review":"review",
"end":END
})
builder.add_edge("research","coordinator")
builder.add_edge("write","coordinator")
builder.add_edge("review","coordinator")
checkpointer = InMemorySaver()
graph = builder.compile(checkpointer=checkpointer)
def test_search_writing_team():
config = {
"configurable":{
"thread_id":"session_001"
}
}
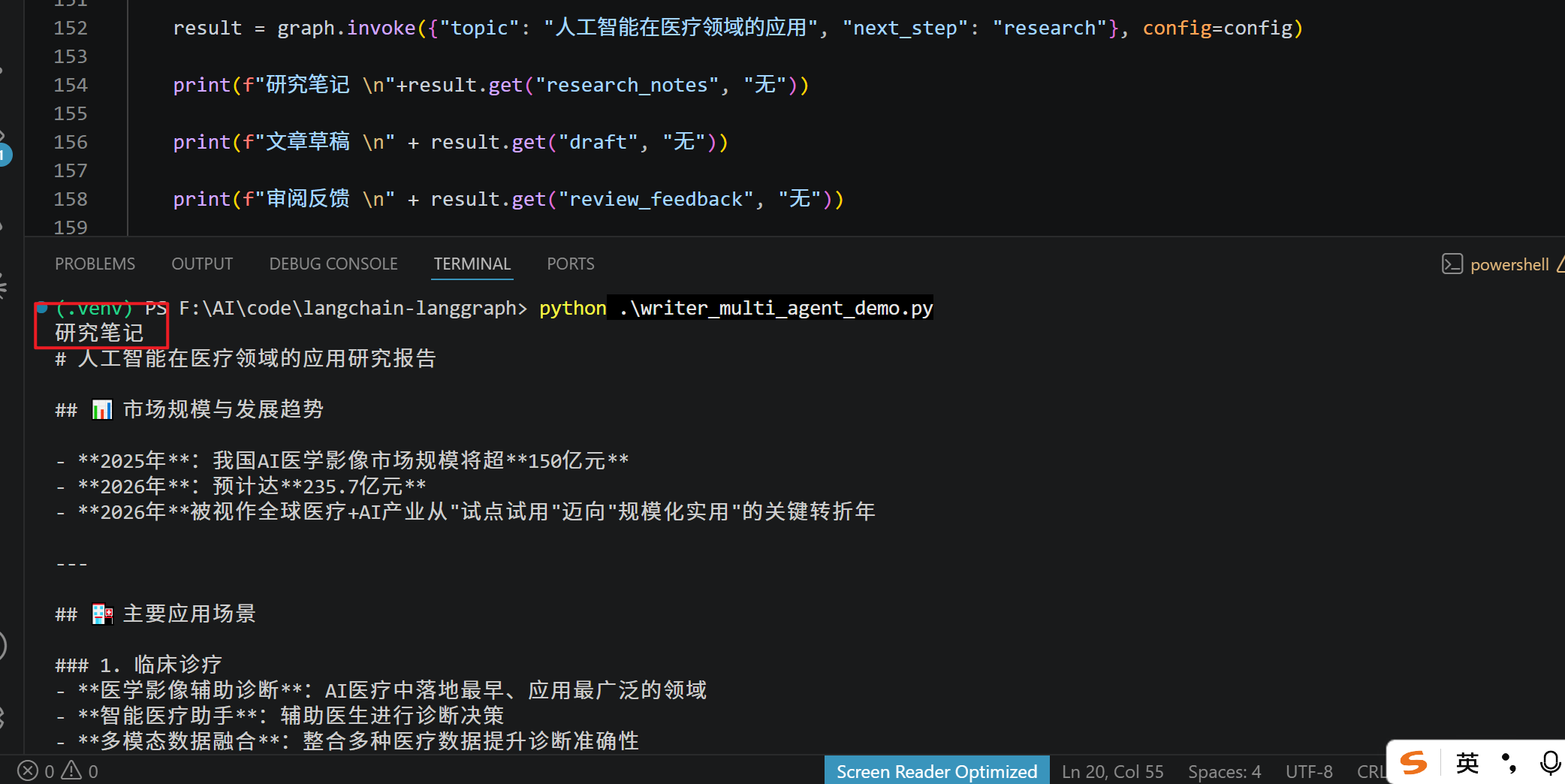
result = graph.invoke({"topic": "人工智能在医疗领域的应用", "next_step": "research"}, config=config)
print(f"研究笔记 \n"+result.get("research_notes", "无"))
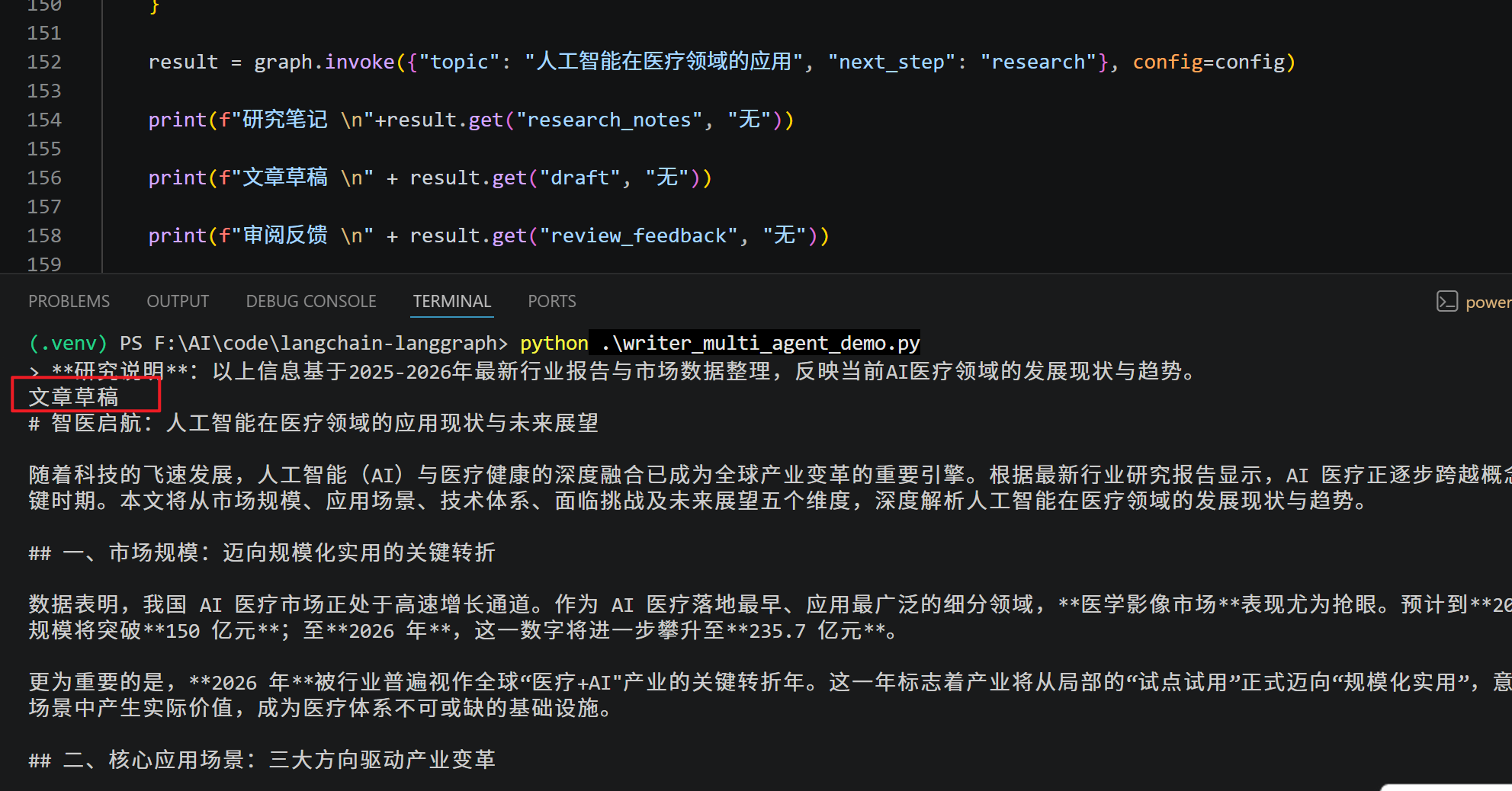
print(f"文章草稿 \n" + result.get("draft", "无"))
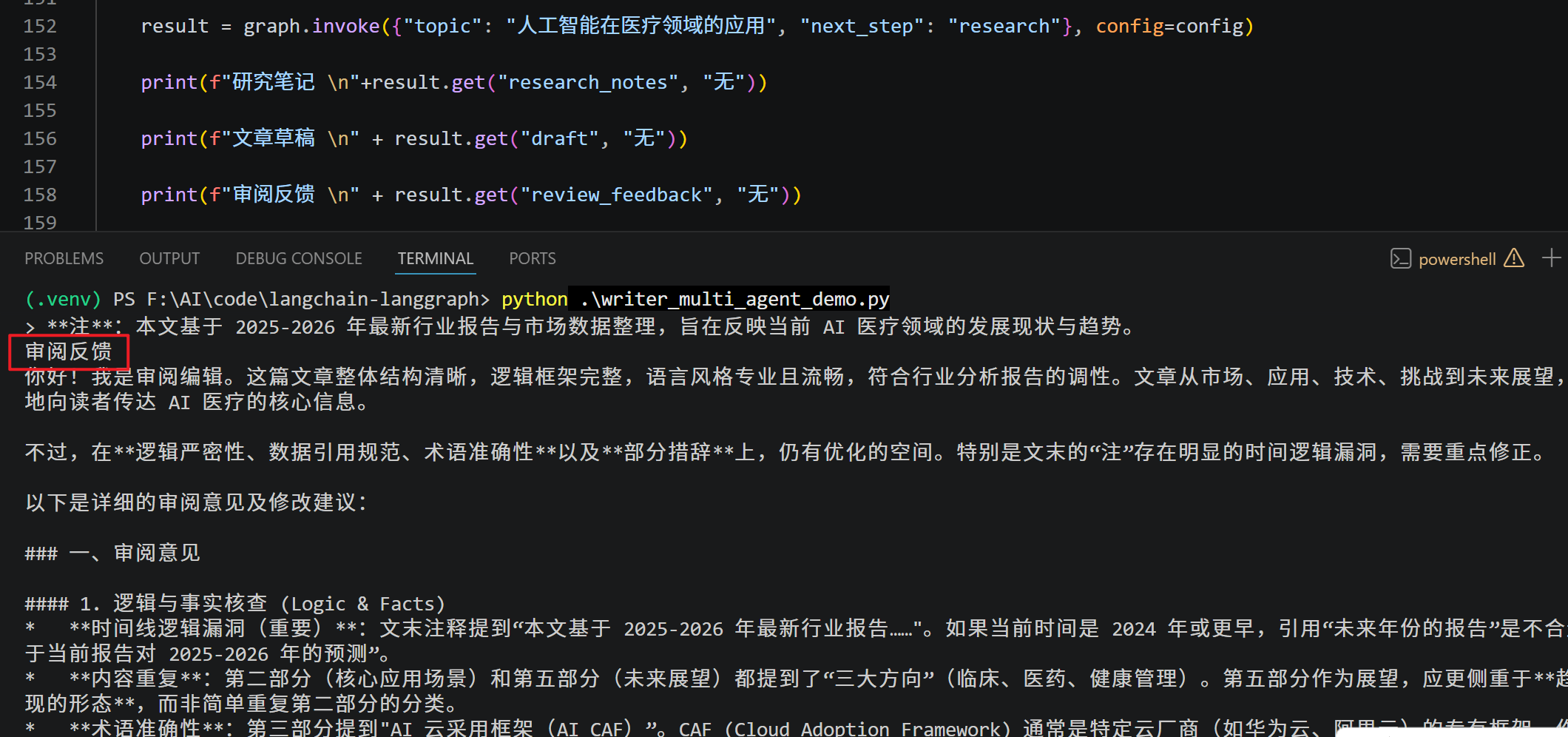
print(f"审阅反馈 \n" + result.get("review_feedback", "无"))
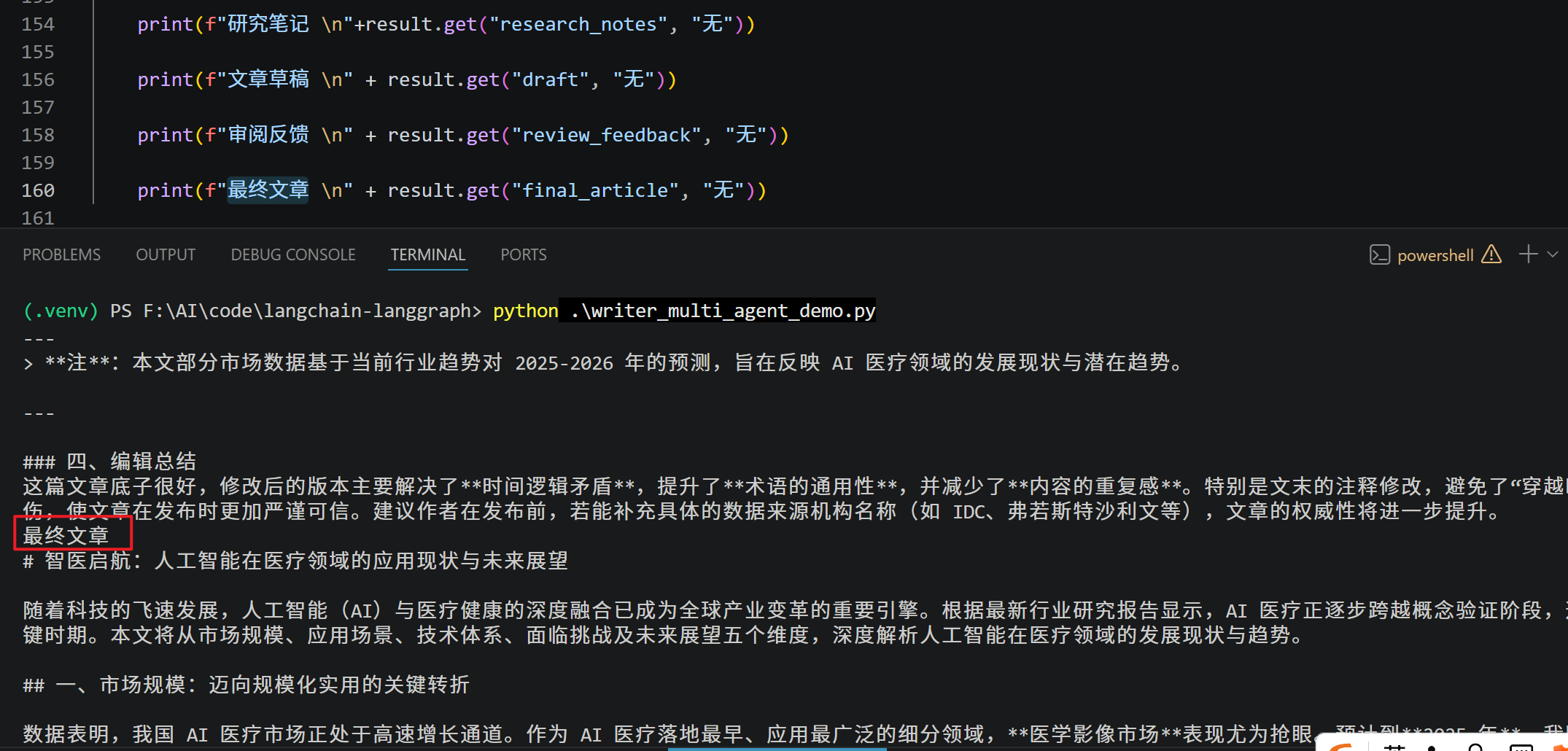
print(f"最终文章 \n" + result.get("final_article", "无"))
if __name__ == "__main__":
test_search_writing_team()运行结果:
结尾:LangGraph 不是让 Agent 更聪明,而是让流程更可靠
回顾一下,本文其实不是在讲一个单独 API,而是在讲一种构建复杂 Agent 应用的方式。
当任务很简单时,一个 Agent 就够了。比如问一个问题、调用一个工具、返回一个答案。
但当任务变成多步骤、多角色、多轮推进时,就需要 LangGraph 这样的框架来管理流程。
它通过 State 保存上下文,通过 Node 拆分任务,通过 Edge 控制流向,通过 Checkpointer 保存进度。再结合监督者模式,就可以把研究、写作、审阅、总结、搜索这些不同 Agent 组织成一个可维护的系统。
最后可以用一句话记住 LangGraph:它不是更聪明的 Agent,而是让多个 Agent 按照清晰流程协作的工作流框架。
如果你理解了这条主线,再回头看加法器、条件边、检查点和研究写作团队代码,就不会觉得它们是零散示例。它们其实是一条逐步升级的路线:先理解图,再理解状态,再理解分支和恢复,最后把这些能力用到多 Agent 协作里。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)