深度工程判断力 × Claude Code:老法师怎么用全链路 AI 原生开发把 5 人 2 个月的交付,1 个人 30 天做完
去年,如果一家公司说:“我们 80% 的代码是 AI 写的。”
你大概会点点头,心里想:行,PPT 先收一下,投资人已经在路上了。
但今天再听到这句话,反应变了:才 80%?为什么还有 20% 的代码值得人去写?
2026 年 2 月,Anthropic CPO Mike Krieger 说:「Claude 是 Claude 写的,Claude Code 也是 Claude 写的,我们大部分产品 100% 都是 AI 写的代码。」我不太相信有多少业务的复杂度能超过 Anthropic,所以我用 30 天给自己交了一份答案,深刻理解那 20% 还在让人写的代码,不是 AI 写不了,是没有能力让 AI 写。
目录
一、30 天关键事实,三分钟看完
二、为什么"独立交付"在 2026 年重新成立
三、栈决策清单:第一性原理 + 多年踩坑反向工程
四、流程纪律:让 AI 不返工的四件铁器
五、那些没说出来的代价:30 天里我踩过的 4 个坑
六、写在最后:深度判断力 + 30 天 = 新型 CTO 杠杆
一、30 天关键事实,三分钟看完

37 个活跃日,5 个关键节点,每个节点背后是真实的工程决策和踩坑代价。数字先摆出来,下面所有判断都建立在这上面。
| 维度 | 数值 |
|---|---|
| 起点 | 2026-03-16(首次 commit:Initial commit: AIFlowLearn 平台 MVP 文档) |
| 30 天节点 | 2026-04-15 |
| GitHub 满 30 天发布内测 | 2026-04-17 |
| 首 30 天 commits | 880 个 / 27 个活跃日 |
| 截至 2026-04-25 总 commits | 1,540 个 / 37 个活跃日 |
| 单日峰值 | 137 commits(2026-04-15,多为 superpowers 7 阶段流水线下的小步独立 commit) |
| 后端代码(NestJS 11 + Prisma 5) | 476 个 .ts 文件 / 55,884 行 |
| 前端代码(Next.js 14 + React 18) | 207 个文件 / 38,054 行 |
| 验收测试(harness) | 100 个 spec / 17,201 行 |
| 总规模 | ~1000 源文件 / ~12.1 万行 LOC |
| Memory 沉淀 | 56 张 sticky knowledge cards |
| LLM 年成本基线 | ¥202/年 + 99% 可用性(GLM + DeepSeek fallback) |
| 已上线核心能力 | 注册登录(GitHub OAuth + 手机号)、Stripe 支付、技能包学习、AI 教练流式对话、概念图谱、终端沙箱、CTO 雷达 |
我列这张表只想说一件事:这不是 demo,这是真实产品。
带支付、带 OAuth、带验收测试、能跑生产、能算账,全都不少。
下面讲的所有工程决策,都跑在这个生产环境上。
二、为什么"独立交付"在 2026 年重新成立
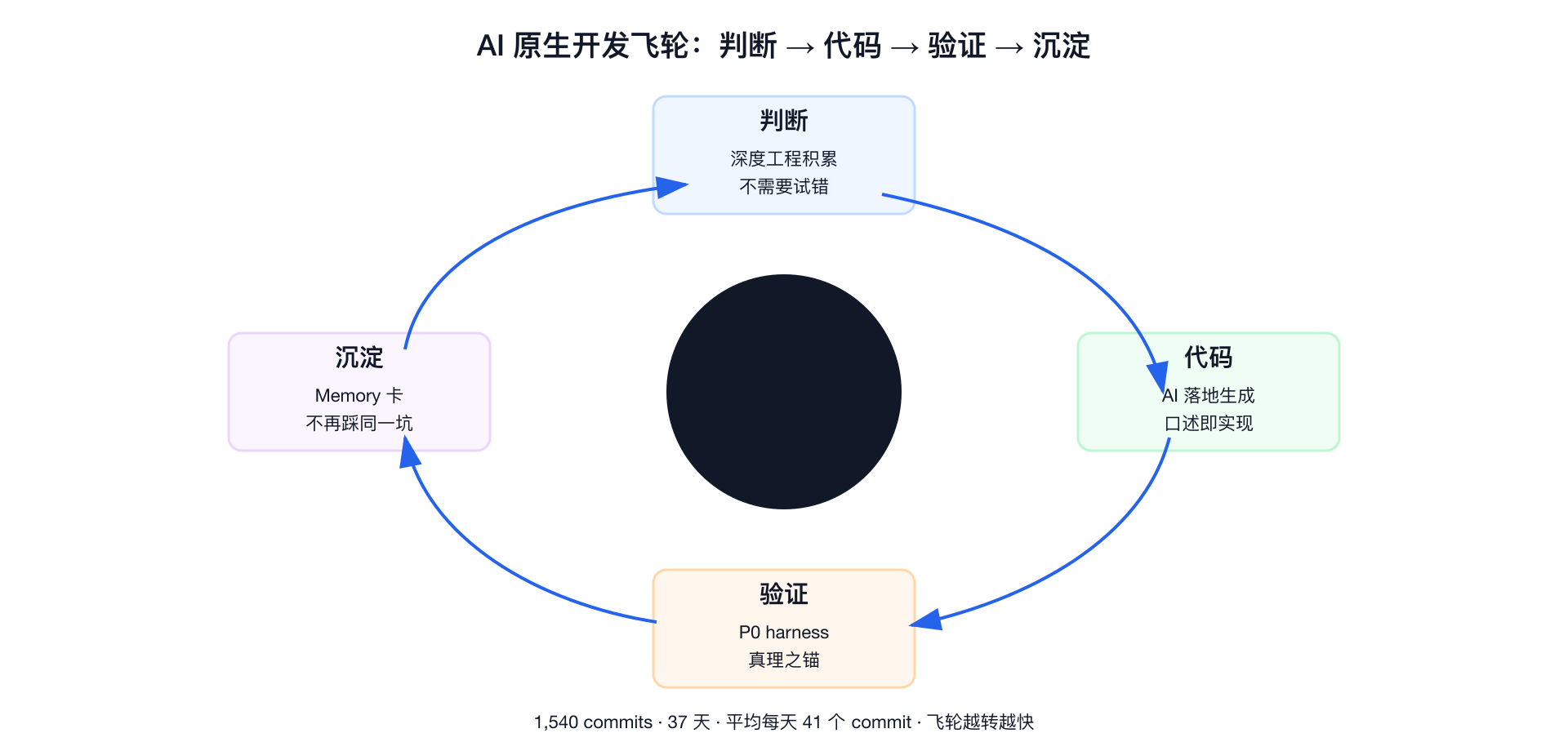
这个飞轮说明了一件事:深度工程积累是放大器的乘数,AI 把判断力折算成了生产速度。
我做了多年的技术管理。我亲手带过百人团队。我清楚一个有支付、有沙箱、有 OAuth、有 i18n、有 RAG 的 AI 学习产品,正常组织里要多少人——产品 1、前端 1、后端 2、QA 1、运维 1,至少 5 个人,跑 2 个月才到内测。
我用了 30 天,1 个人,跑到内测。
5 人 × 2 个月 = 10 人月;1 人 × 1 个月 = 1 人月。10 倍战斗力,不是比喻,是算术。
这不是因为我超人,是因为世界变了。
DORA 2025 报告:AI 在软件工程中的成功,较少取决于工具的复杂性,而更多取决于周围组织系统的强度。AI 是组织能力的放大器,不是替代品。 ——Google Cloud DORA 研究团队,
dora.dev/research/2025
把"放大器"这三个字读三遍。
它的隐含命题是:如果一个人本身就是组织能力的稀缺极值,AI 就把这个人放大成一支舰队。
这正是 深度工程积累 的位置。
我再把行业数据摆一下:
- DORA 2025:约 90% 的开发者在工作中使用某种形式的 AI 辅助。(infoq.com/news/2026/03/ai-dora-report)
- Shopify (BVP):通过建立 LLM 代理网关标准化底层基础设施(而非工具),实现了约 20% 的生产力提升。(bvp.com/atlas/inside-shopifys-ai-first-engineering-playbook)
- 一人独角兽:Midjourney 以约 11 名全职员工创造了超过 2 亿美元的年营收(每位员工约 1800 万美元);Pieter Levels 单人运营着 ARR 达 300 万美元的产品组合;2026 年初新创企业中 36.3% 为单人创办。(nxcode.io)
- AI 原生小团队:最有效的 AI 原生工程团队规模通常很小,3-4 人。(eng-leadership.com)
我把这四句话翻译成 CTO 的人话:
在 AI 原生开发模式下,判断力是新的稀缺品,编码不是。 组织过去用人海堆判断力,现在 1 个人就能堆得过去 7 个人——前提是这 1 个人本身有"过去 7 个人"那么多判断力。
我做了 深度工程积累,这就是我的"过去 7 个人"。
三、栈决策清单:第一性原理 + 多年踩坑反向工程
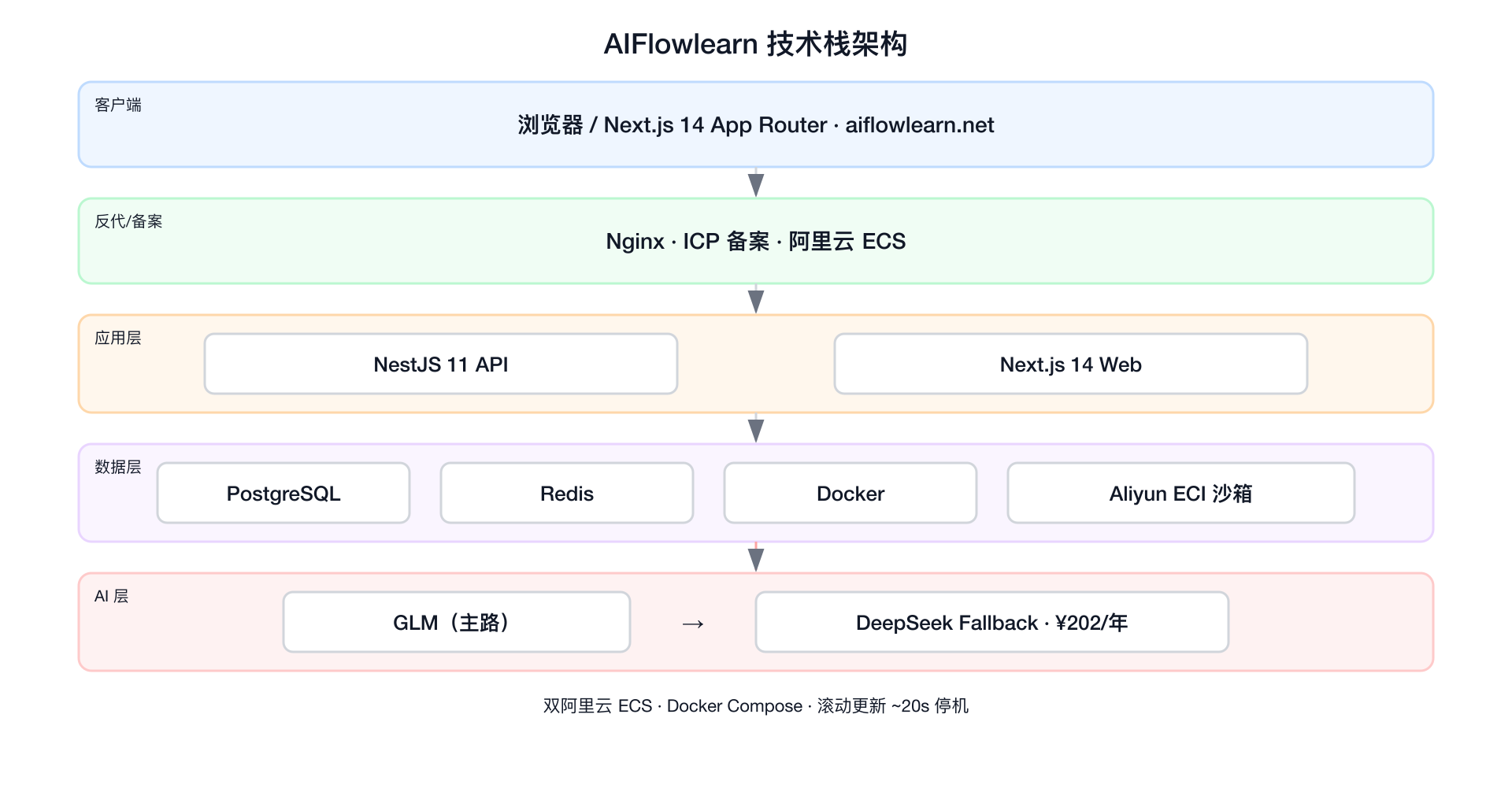
五层架构,每个选型不是"哪个流行选哪个",是"我踩过哪些坑所以这次必须选什么"。
我把 30 天里所有重要的栈决策摊出来。每一条不是"哪个流行就选哪个",而是"我踩过哪些坑、所以这次必须选什么"。
1. 后端:NestJS 11,不是 Express,不是 Fastify
决策:NestJS 11.0.1。
理由:
- AI 写代码最容易出格的就是模块边界——文件乱放、循环依赖、service 越权调 controller。
- NestJS 的依赖注入 + 模块树是强约束。我在
CLAUDE.md里写一句"按 NestJS 模块边界放代码",Claude Code 就不会再乱建 utils。 - 多年工程实践踩过的坑:Express 项目到了 50 个文件以上,没有强约束就开始结构腐烂。AI 加速这种腐烂的速度比人快 10 倍。
结果:55,884 行后端代码,现在还能让任何一个 Claude Code 会话5 分钟内找到任何模块的位置。
2. 前端:Next.js 14 App Router
决策:Next.js 14.2.35 + React 18。
理由:
- App Router 的目录结构本身就是一份"AI 友好的契约"——
app/[locale]/(main)/learn/[id]/page.tsx这种路径,AI 一眼就知道是什么页面、什么参数、什么 layout。 - next-intl 让国际化从一开始就是一等公民,省掉了未来重构的路径。
- 多年工程实践踩过的坑:Pages Router 时代的
_app.tsx是状态地狱,AI 一改全栈崩。App Router 把"全局状态"和"页面状态"分开了。
结果:38,054 行前端代码,AI 改任何一个页面只读它自己那一棵子树。
3. 数据:Prisma 5 + migrate dev 是铁律
决策:Prisma 5.22.0。
理由:
- Schema-first 让 AI 不会"编字段名"——schema 在哪,类型就在哪,TypeScript 编译期就把错误兜住。
migrate dev是唯一允许的模式变更命令。- 多年工程实践踩过的坑:项目越大,"裸 SQL 改表"造的事故越严重。
铁律(写进 CLAUDE.md 第一节):
❌ npx prisma db push(会重建表,丢失数据)
❌ npx prisma db push --force-reset(清空数据库)
❌ npx prisma migrate reset(重置所有迁移)
✅ 开发:npx prisma migrate dev --name <描述>
✅ 生产:npx prisma migrate deploy
为什么这么强硬?因为我已经踩过一次(见第五章),代价是生产数据全丢。
4. 沙箱:isolated-vm + dockerode + 阿里云 ECI
决策:三层隔离。
理由:
- AI 学习产品的本质是让用户跑代码。让用户跑代码的本质是给一个不可信代码一个可控的执行环境。
- 第一层
isolated-vm:Node 同进程的 V8 隔离,跑 JS 表达式级别的判题脚本(毫秒级)。 - 第二层
dockerode:起一次性容器,跑 Python/Bash 这种需要文件系统的实战题。 - 第三层 阿里云 ECI(Elastic Container Instance):跑课程 RAG 索引这类"长任务 + 大内存"工作负载,按秒计费。
- 多年工程实践踩过的坑:自建 K8s 给学习产品做沙箱是纯纯的工程债。ECI 这种 serverless 容器,按秒计费,挂掉也只挂自己。
警惕:ECI 的内存单位是 GiB 不是 MB。我曾经把 512 当成 MB 写进 SDK,启动了一个 512 GiB / 64 vCPU 的巨型实例,账单当场爆炸(详见第五章)。
5. LLM 路由:GLM + DeepSeek fallback,年 ¥202
决策:自研 PromptRunner + 多模型分层。
理由:
- 学习产品的 LLM 调用峰值在"AI 教练流式对话"和"内容生成"两个点上,年估算 14M input + 7M output tokens。
- 实测对照价格表:
| 模型 | Input ($/M) | Output ($/M) | 中国区可用 |
|---|---|---|---|
| GLM-4.7(智谱直连付费) | ¥10 (~$1.4) | ¥15 (~$2.1) | ✅ 必须 |
| DeepSeek-Chat(OpenRouter) | $0.14 | $0.28 | ✅ 中国原生 |
| Gemini 2.5 Flash | $0.075 | $0.30 | ⚠️ 部分时段 |
| GPT-4o-mini | $0.15 | $0.60 | ❌ 中国 block |
| Claude Haiku 4.5 | $0.80 | $4.00 | ⚠️ 不稳定 |
- 终选:GLM 主路 + DeepSeek fallback,年成本 ¥202 + 可用性 99%+。
- 关键洞察:按 input 单价 DeepSeek 比 GLM 便宜约 10 倍($0.14/M vs ~$1.4/M),output 也约 7–8 倍——做 fallback 不仅没增成本,反而拉低了均价。
深度工程判断:在中国做生产产品,可用性永远比省钱重要。但当便宜的 fallback 还顺带让你更可靠时,没有理由不做。
6. 部署:Docker + 阿里云 ECS + nginx 备案反代
决策:双服务器架构。
理由:
- 前端反代 + 备案:阿里云 ECS(备案节点)跑 nginx,唯一对外域名 aiflowlearn.net。
- 后端应用:阿里云 ECS(应用节点)跑 Docker(API + Web + DB + Redis)。
- 部署用滚动发布脚本:rsync 增量同步源码 → SSH 远程滚动构建+切换(停机 ~20 秒)。
- 多年工程实践踩过的坑:Cloudflare Tunnel 在中国是技术债,不能依赖;境外/境内双栈都是慢性死亡。全 ICP 备案 + 阿里云一条路走到底,简单到不会出错。
我曾经用过 Cloudflare Tunnel + 海外域名 aiflearn.com,最后全废掉了。这种"放弃了什么"也算是 深度工程判断力里最重要的一类决策——知道什么时候止损。
四、流程纪律:让 AI 不返工的四件铁器
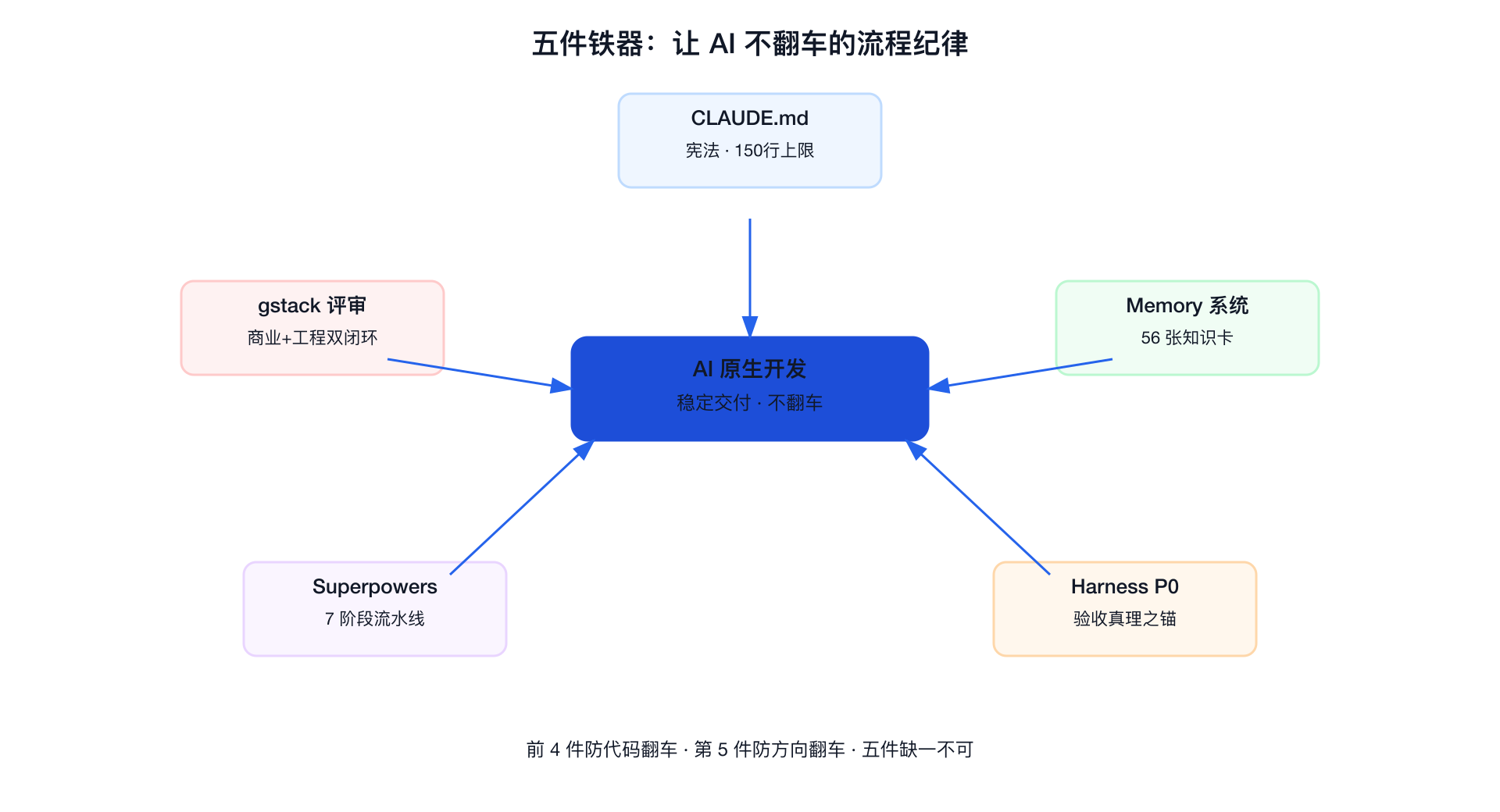
前 4 件铁器防代码层面翻车,第 5 件防方向层面翻车。技术栈选完了不算完,AI 时代真正的护城河,是流程纪律。
我把过去 30 天里"让 AI 开发不翻车"的五件铁器列出来。这部分对中小团队 CTO 最有借鉴价值。
铁器 1:CLAUDE.md(项目宪法,150 行硬上限)
CLAUDE.md 是项目根目录里的一份"宪法文档",每次 Claude Code 启动会自动读。
核心规则(精简版):
| 场景 | 规则 |
|---|---|
| API 路径 | 不含 /api/ 前缀(baseURL 已包含) |
| 字段命名 | 前后端必须一致 |
| AI 配置 | 使用环境变量(AI_API_KEY, AI_MODEL) |
| 数据库迁移 | 禁止 db push/reset,必须用 migrate dev |
| 开发流程 | 所有新功能和 Bug 修复必须使用 TDD |
| Chrome 测试 | ❌ 不得 pkill 用户 Chrome;✅ 用独立 --user-data-dir |
| 自主验证 | 开发完成后必须自行用 Chrome DevTools MCP 验证 |
铁律:CLAUDE.md 不得超过 150 行。每加一条规则,先删一条过时的。
为什么 150 行?因为再多 AI 就开始"读不进去",违反规则的概率上升。这个数字是我用 4 篇翻车的稿子换来的。
铁器 2:memory 系统(56 张 sticky knowledge cards)
Claude Code 自带一个 memory/ 目录。我把它当成**“我的二号大脑”**用。
每个 memory 文件是一张卡:
feedback_*—— 用户偏好(沟通用中文、不要复盘式反馈)project_*—— 项目状态(启动时间、长期愿景、模型路由)critical-*—— 不许再犯的事故(db push、ECI 单位)reference_*—— 外部资源指针(开源库本地路径)user_*—— 用户身份(深度工程积累、作者型产品)
到 2026-04-25,我有 56 张卡。每开一个新会话,Claude Code 自动加载 MEMORY.md 索引,相关卡片随用随读。
这件事的价值不在记多少,在"我已经踩过的坑不会再踩第二次"。
铁器 3:harness/p0-critical(验收测试 = AI 不能逃避的真理之锚)
harness/ 是一个独立的 E2E 测试框架,30 个 spec / 7,201 行。
跑一句 P0 验收脚本就能验证:
- 注册登录链路完整
- 支付链路 OK
- 概念图谱加载
- AI 教练能流式对话
- 终端沙箱能跑代码
铁律:编码后必须新增/修改对应 spec,确保 P0 全绿才能提交。
这是给 AI 的真理之锚——不管 Claude Code 改了什么,跑一遍 P0,错了就退回去。
铁器 4:Claude Code + 三模型分层 + superpowers skill
开发环境:Claude Code(Anthropic 官方 CLI)。不是在编辑器里用补全插件,是把 Claude Code 当成开发团队的核心成员:派任务、留 KPI、晚上还能接着干。
模型按任务分层,不是"哪个最强用哪个",是"这个场景需要什么样的推理/速度比":
| 模型 | 定位 | 典型场景 |
|---|---|---|
| Claude Opus 4.7 | 复杂推理 | 架构决策、P0 bug 根因分析、需求 spec review |
| Claude Sonnet 4.6 | 编码主力 | 日常功能开发、重构、代码 review |
| GLM 5.1 | 内容 + 控成本 | AI 教练对话、课程内容生成、中文场景 |
superpowers skill 核心七步:把"模型自由发挥"切成 7 个有检查点的阶段,每个新功能必须按序走:
/brainstorming → /writing-plans → /TDD →
/verification → /review → /ship → /land-and-deploy
这套流程看起来"重",但它解决了 AI 原生开发最大的问题——概率性翻车。模型不是不行,是没有约束它就会走捷径、跳步骤、编结果。superpowers 的每个 skill 就是一道检查门。
引用 OpenAI Codex 负责人的话:
AI 原生团队最擅长识别工作在哪里慢下来,并应用 AI 来消除这些瓶颈。这意味着质疑一切:规划、策略、功能/缺陷优先级、代码生成、代码审查。 ——Thibault Sottiaux,
eng-leadership.com
我的前 4 件铁器就是把这句话落地:CLAUDE.md 锁宪法、memory 锁经验、harness 锁真理、Claude Code + superpowers 锁流程。
铁器 5:gstack 全栈评审(让商业判断和工程判断同步经过对抗 review)
前四件铁器管的是"代码不出错",第五件铁器管的是"做的事情本身对不对"。
gstack 是一套嵌在 Claude Code 里的评审体系,我用了其中三个核心能力:
/office-hours(战略问诊):把真实问题搬进来——不是"我要做什么功能",是"在 0 付费用户的阶段,我是该继续打磨产品还是收窄画像押单一个 wedge?“。它逼你面对最难承认的事:我有 15 个注册用户,没有 1 个付费,这不是"早期”,这是"需求未验证"。这种诚实是商业判断的起点。
/plan-ceo-review(10x 校验):每个策略计划进来会被评分(第一轮 6/10,第二轮 7/10,反复改才到 8/10)。它会做两件事:提出你没想到的扩展方向(A/B/C/D/E/F 六个提案,逐个评 ACCEPT / DEFER / CONDITIONAL),以及把你没注意到的商业盲点打出来——比如主页的 2000+ 工程师 / NPS 72 / 4.8⭐ 全是占位数据,我在做 B 端 sales 演示前第三轮地面核查才发现,差点在 CTO 客户面前露底。
/plan-eng-review(工程审查):映射所有新增代码路径、每条路径的失败模式、测试覆盖缺口。我在做数字分身功能时,它发现了 2 个 P0 缺口:流式接口 prompt injection 裸奔(T6 Schema Hijack 已实测打穿)+ 多席位团队隔离零基建。这两条如果进了生产,B 端客户数据会互相可见。
工程价值在这里: 这套评审不是"做完了来检查",是"要做之前先过一遍"。发现缺口的成本在规划阶段是改文档,在代码阶段是改架构,在生产阶段是故障修复。这三个成本比是 1 : 10 : 100。
五、那些没说出来的代价:30 天里我踩过的 4 个坑
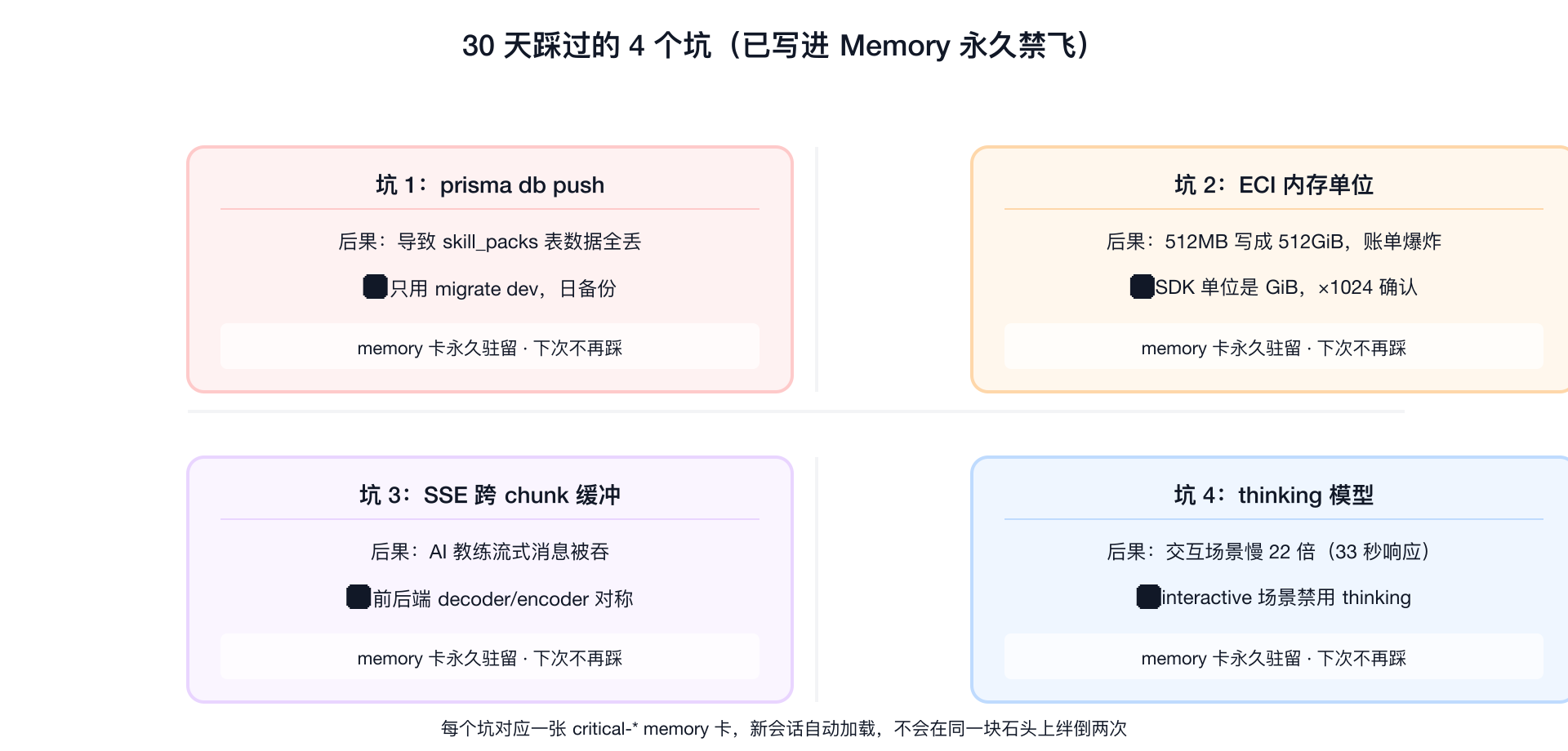
这 4 个坑让我明白:AI 加速的不只是开发,也加速了出错的速度。把教训写进 memory 卡,才是真正的护城河。
我说"30 天交付"听起来浪漫,但浪漫是因为我没说背后流过的血。下面这 4 个坑都已经写进 memory,永久禁飞。
坑 1:prisma db push 那一夜(生产数据全丢)
事故:2026-04-11,我用 npx prisma db push 同步 schema 变更。
结果:skill_packs 表被重建,所有数据丢失。
为什么:db push 不走迁移历史,它是"我看到 schema 和库不一样了,那就把库改成 schema 的样子"——它不在乎你库里的数据。
修复:
- 数据库备份脚本升级为强制每日备份。
- 写进
CLAUDE.md的 ❌ 列表(见前文)。 - memory 卡
critical-prisma-db-push-warning永久驻留。
新铁律:数据库重建(极少情况),必须先备份 + 用户明确同意 + 用 migrate dev。
坑 2:ECI 内存单位 ×1024(账单爆炸)
事故:阿里云 ECI 的 memory 字段单位是 GiB,我误以为是 MB,写代码时 ×1024。
结果:本来要起 512MB,结果起了 512 GiB / 64 vCPU 的巨型实例。账单当场爆炸。
修复:
- memory 卡
critical-eci-memory-unit-bug永久驻留。 - SDK 调用前必须打印实例规格 + 双人审。
判断升级:云厂商 SDK 的单位约定是"隐形地雷"。读 SDK 必须看 type 注释,不能凭印象。
坑 3:SSE 跨 chunk-boundary 缓冲(前后端非对称 = 生产 bug)
事故:AI 教练流式对话用 SSE。后端 chunk 跨边界切割时,前端没做缓冲拼接,导致部分 message 被吞。
根因:前后端的"边界处理"必须对称——后端按字符切,前端就得按字符拼;后端按 token 切,前端就得按 token 拼。
修复:
- 后端 SSE encoder 和前端 decoder 同源同协议。
- memory 卡
feedback_sse-buffer-symmetry永久驻留。
判断升级:任何"流式"协议都有对称性义务,改一边忘一边 = 生产 bug。
坑 4:thinking 模型用错地方(interactive 场景慢 22 倍)
事故:AI 教练对话场景接入了 qwen3.6-plus 的 thinking 模式(带显式 reasoning)。
结果:实测响应延迟从 1.5s 飙到 33 秒,慢了 22 倍。
根因:thinking 模型适合离线深度推理,不适合交互式实时回复。
修复:
interactive场景禁用 thinking 模型。- memory 卡
feedback_avoid-thinking-models-for-interactive永久驻留。
判断升级:模型选型必须按"使用场景"分档。不是"哪个最强用哪个",是"这个场景需要什么样的延迟/精度比"。
六、写在最后:深度判断力 × Claude Code = 老法师的新杠杆
回到最开始那个问题:老法师的深度工程判断力,在 AI 原生开发模式下,到底能折算成多少生产力?
我把这条等式拆开:
深度工程判断力让我跳过了 90% 的选型试错——
- 我不需要试 5 个后端框架才发现 NestJS 适合大规模代码生成。
- 我不需要踩 3 次 ORM 的坑才知道 Prisma migrate dev 必须是铁律。
- 我不需要被云厂商 SDK 单位坑两次才学会读 type 注释。
- 我不需要写两个 SSE 实现才知道前后端必须对称。
AI 原生开发让我跳过了 90% 的编码反复——
- 1,540 commits / 27 个活跃日 = 平均每天 57 个 commit。
- 这不是"AI 帮我写代码",这是"我口述判断、AI 落地代码、harness 验证真理、memory 锁定经验"——一个完整的判断 → 代码 → 验证 → 沉淀闭环。
引用 Shopify 工程副总裁 Farhan Thawar 的护栏:
工程师必须理解其工作层级之下 2-3 层的系统,使用 AI 来加速学习而非替代它。 ——
bvp.com/atlas/inside-shopifys-ai-first-engineering-playbook
我把这句话翻译成 CTO 的版本:
AI 加速的是落地,不是判断。判断不能外包。
给中小团队技术管理者 的 5 条建议
如果你是一个 10-30 人团队的 CTO,正在思考怎么把"AI 原生开发"落地,我这 30 天换来的 5 条建议:
-
先写 CLAUDE.md,再写代码。 150 行宪法。每加一条,删一条。这是你团队的"AI 集体潜意识"。
-
memory 不是日记,是 sticky knowledge. 只记"再犯一次会致命"的事。
feedback_/critical-/project_三类前缀分清楚。 -
harness/p0 是真理之锚,不是装饰。 不写 P0 的功能不算交付。AI 改完跑一遍,这是你睡得着觉的唯一理由。
-
栈选择优先"AI 友好"而不是"性能极致"。 NestJS 的 DI 比 Fastify 的 throughput 重要 10 倍——因为前者帮 AI 不出错,后者只是优化已经出错的代码。
-
深度工程判断力是放大器的乘数。 别想着"换一个工具就行"。AI 是放大器——它把你的判断力放大成生产力,也把你的判断错误放大成事故。该补判断力补判断力,该买经验买经验,AI 治不了你不思考。
下一篇:编码阶段模型切换——我怎么把 Claude Code 的 token 消耗降了 50%。四阶段 token 分布表 + "写代码不需要最强推理,只需要最合适的模型"核心洞察。关注「新点智流学社」不错过。
关于作者:木子霖 @ AI智流学社,架构师 / CTO / AI 原生构建者,正用 AI Native 的方式构建学练一体成长引擎,欢迎您基于他打造你的个人成长引擎。
如果这篇文章对你有用,欢迎转发给身边的朋友——我相信不只我一个人在思考"工程积累 + 30 天交付"这个等式。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)