入门LangChain:让大模型从「懂」到「能」
LangChain 核心概念解析
LangChain 是一个开源框架,旨在将大语言模型(LLM)与外部数据源、工具和系统集成,解决传统大模型在私有数据访问、实时操作和上下文记忆等方面的局限性。其核心价值在于将静态的模型转化为动态的“智能体”,能够自主决策并执行任务。
关键能力与组件
数据感知与自主性
- 数据感知:通过检索增强生成(RAG)技术连接数据库、文档或API,使模型能够访问私有或实时数据。
- 自主性:借助Agent和Tools组件,模型可调用外部工具(如搜索引擎、计算器或API)完成任务,实现从“回答”到“行动”的升级。
六大核心组件
- Model I/O:标准化不同LLM的调用接口,支持无缝切换模型(如GPT-4与Claude)。
- Retrieval:从私有数据源检索相关信息,解决模型无法访问内部数据的问题。
- Agents:基于ReAct模式(思考→行动→观察→循环)自主决策,动态选择工具完成任务。
- Tools:扩展模型能力,例如调用Wolfram Alpha进行数学计算或访问天气API。
- Memory:维护对话历史,实现多轮上下文记忆。
- Chains:将多个组件串联为工作流(如“检索→生成→验证”)。
分层架构设计
核心层(langchain-core)
定义基础接口和抽象类,确保组件兼容性。例如,所有工具需实现Tool基类的run()方法。
集成层(Community Integrations)
提供与第三方服务的适配器,如OpenAI、HuggingFace或自定义API的封装。
应用层(langchain)
预构建高阶组件(如LLMChain),支持快速开发聊天机器人或问答系统。
编排层(langgraph)
管理复杂工作流,适用于多Agent协作或长周期任务(如自动化客服工单处理)。
环境搭建
1.python环境要求
LangChain需要Python 3.8或更高版本。
2.创建虚拟环境
为避免包冲突和依赖问题,建议使用虚拟环境工具(如conda或venv)隔离开发环境。
使用Conda
# 创建名为langchain-env的虚拟环境,指定Python版本
conda create -n langchain-env python=3.8.12
# 激活虚拟环境
conda activate langchain-env3.安装LangChain及相关依赖
逐个安装核心包
pip install langchain langchain-community langchain-core langchain-openai
pip install python-dotenv chromadb tiktoken4.获取API密钥(免费模型)
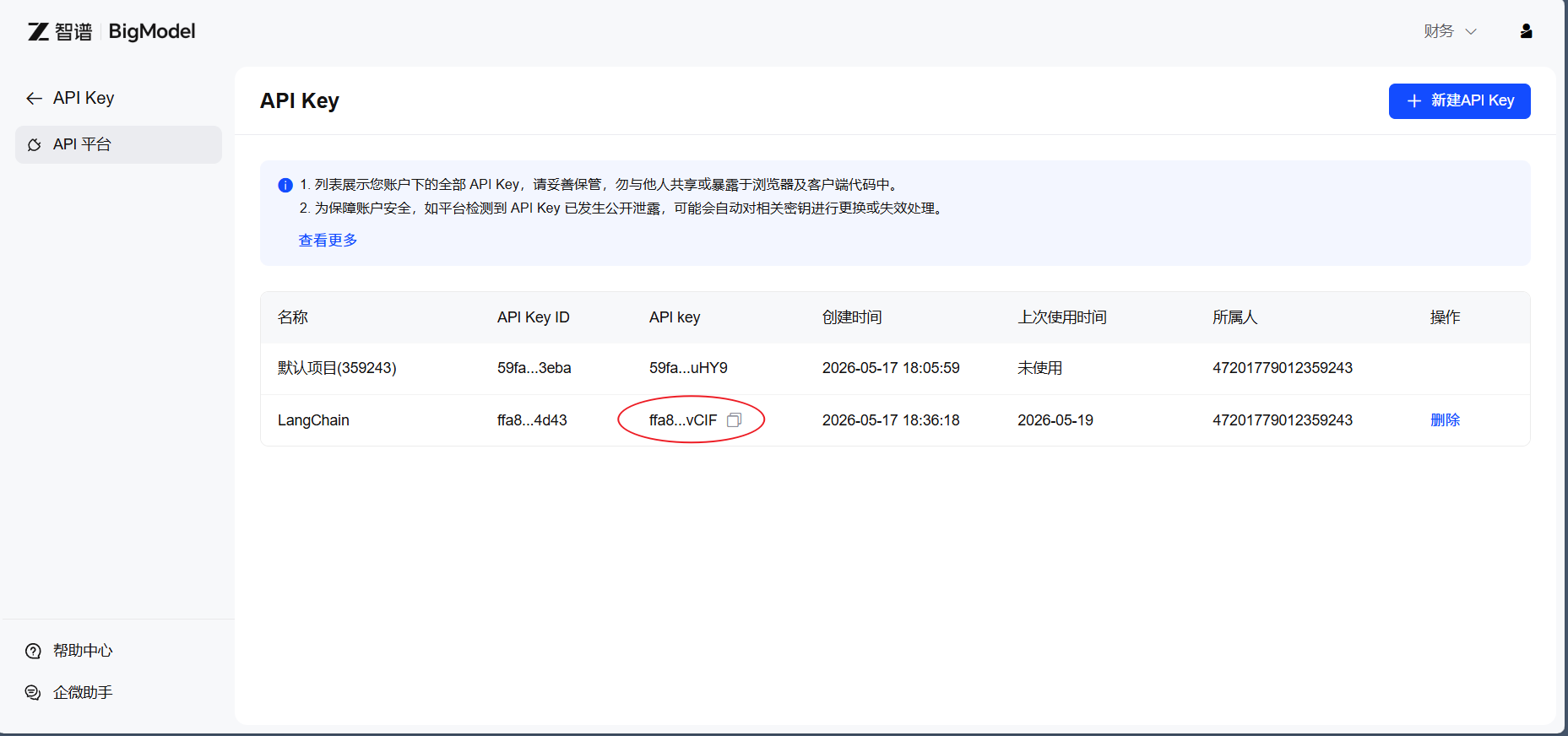
推荐使用智谱AI的GLM-4-Flash模型(免费且响应快):
- 访问智谱AI开放平台
- 注册账号并完成实名认证
- 进入"控制台" → “API密钥”
- 点击"创建新的API密钥"
- 复制生成的API Key
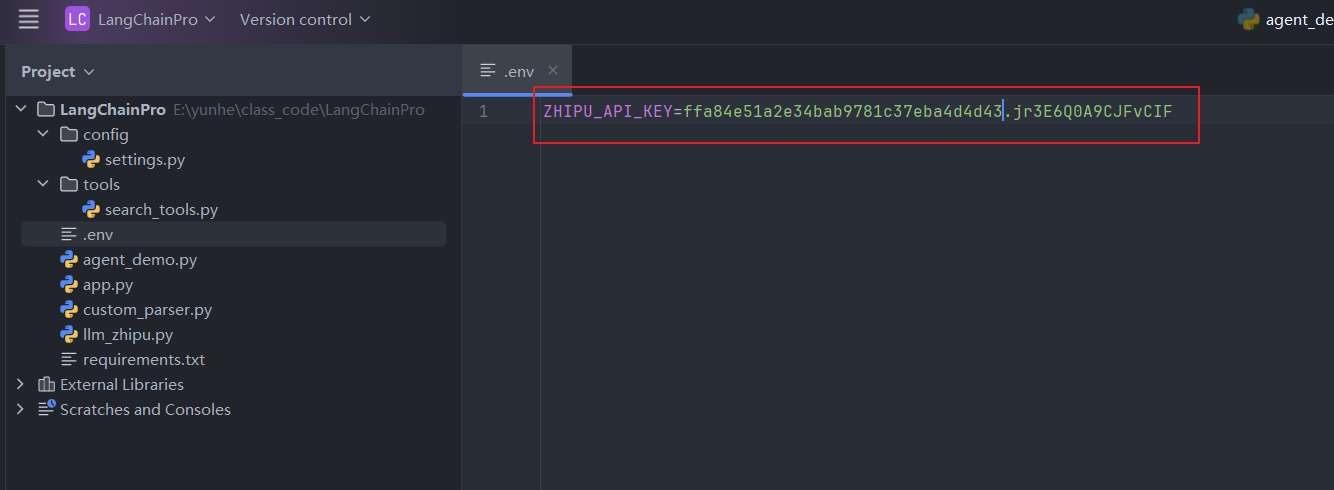
5.配置环境变量
在项目根目录创建.env文件,将复制的API Key 放在这里
实战入门:从基础运用到知识库问答
1.创建第一个LangChain应用
1.创建配置模块文件
在config/settings.py文件中集中管理所有配置参数:
import os
from dotenv import load_dotenv
from typing import Optional
# 加载环境变量
load_dotenv()
# 智谱AI配置
ZHIPU_API_KEY = os.getenv("ZHIPU_API_KEY")
ZHIPU_API_BASE = "https://open.bigmodel.cn/api/paas/v4"
# 模型配置
MODEL_NAME = "glm-4-flash"
MODEL_TEMPERATURE = 0.7
MODEL_MAX_TOKENS = 2048
# 搜索配置
SEARCH_RESULT_LIMIT = int(os.getenv("SEARCH_RESULT_LIMIT", 5))
SEARCH_TIMEOUT = int(os.getenv("SEARCH_TIMEOUT", 30))
# 应用配置
DEBUG = os.getenv("DEBUG", "False").lower() == "true"
LOG_LEVEL = os.getenv("LOG_LEVEL", "INFO")
# 记忆配置
MEMORY_WINDOW_SIZE = 10
def validate_config():
"""验证配置是否完整"""
if not ZHIPU_API_KEY:
raise ValueError("ZHIPU_API_KEY 环境变量未设置")
return True
2.创建自定义LLM包装器
在llm_zhipu.py文件中封装智谱AI接口:
import os
import logging
from typing import Any, Dict, List, Optional
from langchain.schema import BaseMessage, HumanMessage, AIMessage, SystemMessage
from langchain.llms.base import LLM
from zhipuai import ZhipuAI
# 配置日志
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
class ZhipuAILLM(LLM):
"""包装器"""
model_name: str = "glm-4-flash"
temperature: float = 0.7
max_tokens: int = 2048
api_key: str = ""
class Config:
"""Pydantic配置"""
arbitrary_types_allowed = True
extra = "ignore"
def __init__(self, **data: Any):
super().__init__(**data)
@property
def _llm_type(self) -> str:
return "zhipuai"
def _call(self, prompt: str, stop: Optional[List[str]] = None, **kwargs: Any) -> str:
"""调用智谱AI API"""
# 获取API密钥
api_key = self.api_key or os.getenv("ZHIPU_API_KEY")
if not api_key:
error_msg = "ZHIPU_API_KEY环境变量未设置"
logger.error(error_msg)
return error_msg
try:
client = ZhipuAI(api_key=api_key)
logger.info(f"调用智谱AI API,模型: {self.model_name}, 输入长度: {len(prompt)}")
response = client.chat.completions.create(
model=self.model_name,
messages=[{"role": "user", "content": prompt}],
temperature=self.temperature,
max_tokens=self.max_tokens,
)
result = response.choices[0].message.content
logger.info(f" API调用成功,输出长度: {len(result)}")
return result
except Exception as e:
error_msg = f" API调用失败: {str(e)}"
logger.error(error_msg)
return error_msg
def _convert_message_to_dict(self, message: BaseMessage) -> Dict[str, Any]:
"""转换消息"""
if isinstance(message, HumanMessage):
return {"role": "user", "content": message.content}
elif isinstance(message, AIMessage):
return {"role": "assistant", "content": message.content}
elif isinstance(message, SystemMessage):
return {"role": "system", "content": message.content}
else:
return {"role": "user", "content": str(message.content)}
class ZhipuAIChatLLM(ZhipuAILLM):
"""智谱AI LLM"""
def generate_chat(self, messages: List[BaseMessage], **kwargs: Any) -> str:
"""生成聊天响应"""
# 获取API密钥
api_key = self.api_key or os.getenv("ZHIPU_API_KEY")
if not api_key:
error_msg = "ZHIPU_API_KEY环境变量未设置"
logger.error(error_msg)
return error_msg
try:
# 每次调用都创建新的客户端
client = ZhipuAI(api_key=api_key)
formatted_messages = [self._convert_message_to_dict(msg) for msg in messages]
logger.info(f"消息数量: {len(formatted_messages)}")
response = client.chat.completions.create(
model=self.model_name,
messages=formatted_messages,
temperature=self.temperature,
max_tokens=self.max_tokens,
)
result = response.choices[0].message.content
logger.info(f"API调用成功,输出长度: {len(result)}")
return result
except Exception as e:
error_msg = f"出错: {str(e)}"
logger.error(error_msg)
return error_msg
3.创建基础对话版本
在app.py文件中演示基础的LLMChain + Memory使用:
import os
from dotenv import load_dotenv
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain.memory import ConversationBufferMemory
from llm_zhipu import ZhipuAIChatLLM
# 加载环境变量
load_dotenv()
# 初始化LLM
llm = ZhipuAIChatLLM()
# 创建对话模板
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个有帮助的AI助手"),
MessagesPlaceholder(variable_name="history"),
("human", "{input}")
])
# 创建记忆
memory = ConversationBufferMemory(memory_key="history", return_messages=True)
# 创建对话链
chain = prompt | llm
# 示例对话
def chat(input_text):
memory.load_memory_variables({})
response = chain.invoke({"input": input_text, "history": memory.chat_memory.messages})
memory.save_context({"input": input_text}, {"output": response})
return response
4.运行项目
确保已安装所有依赖项并设置好环境变量后,可以通过以下命令运行项目:
python app.py
典型应用场景:上下文感知对话
2. 进阶应用:构建你的第一个Agent
2.1 创建搜索工具
文件:tools/search_tools.py
作用:提供网络搜索能力
import requests
from langchain.tools import Tool
from typing import Optional, Dict, Any
import json
import time
import logging
from bs4 import BeautifulSoup
# 配置日志
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
class BaiduSearchTool:
"""百度搜索"""
def __init__(self):
self.base_url = "https://www.baidu.com/s"
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
}
def search(self, query: str, num_results: int = 5) -> str:
"""
使用百度网页搜索(带重试机制)
"""
for attempt in range(3):
try:
params = {
'wd': query,
'rn': num_results,
'ie': 'utf-8',
'oq': query
}
response = requests.get(
self.base_url,
params=params,
headers=self.headers,
timeout=30
)
if response.status_code == 200:
result = self._parse_baidu_results_robust(response.text, query, num_results)
if "未找到" not in result and "失败" not in result:
return result
else:
logger.warning(f"百度搜索结果为空,尝试第 {attempt + 1} 次重试")
else:
logger.warning(f"百度搜索HTTP错误 {response.status_code},尝试第 {attempt + 1} 次重试")
except Exception as e:
logger.warning(f"百度搜索异常 {str(e)},尝试第 {attempt + 1} 次重试")
if attempt < 2:
time.sleep(1)
return self._get_fallback_result(query)
def _parse_baidu_results_robust(self, html: str, query: str, num_results: int) -> str:
"""百度搜索结果解析"""
try:
soup = BeautifulSoup(html, 'html.parser')
results = []
# 尝试多种可能的百度搜索结果容器选择器
possible_selectors = [
'div.result',
'div.c-container',
'div[class*="result"]',
'div[class*="c-container"]',
'div.contentLeft',
]
containers = []
for selector in possible_selectors:
containers.extend(soup.select(selector))
# 如果上述选择器都没找到,尝试查找包含标题和摘要的通用结构
if not containers:
# 查找所有包含链接和文本的容器
link_containers = soup.find_all(['div', 'table'], class_=lambda x: x and any(keyword in str(x) for keyword in ['result', 'c-', 'content']))
containers = link_containers
for i, container in enumerate(containers[:num_results]):
try:
# 多种标题提取策略
title = None
title_selectors = ['h3', 'h3 a', 'a[data-click]', '.t a', '.c-title a']
for selector in title_selectors:
title_elem = container.select_one(selector)
if title_elem:
title = title_elem.get_text().strip()
break
if not title:
# 尝试在容器内查找第一个链接
link_elem = container.find('a')
title = link_elem.get_text().strip() if link_elem else "无标题"
# 多种摘要提取策略
content = None
content_selectors = ['.c-abstract', '.c-span-last', '.c-gap', '.content-right_8Zs40']
for selector in content_selectors:
content_elem = container.select_one(selector)
if content_elem:
content = content_elem.get_text().strip()
break
if not content:
# 尝试查找包含描述文本的元素
desc_elements = container.find_all(['div', 'span'], class_=lambda x: x and any(keyword in str(x) for keyword in ['abstract', 'content', 'desc']))
if desc_elements:
content = desc_elements[0].get_text().strip()
else:
# 提取容器中除标题外的文本
if title_elem:
title_elem.extract()
content = container.get_text().strip()[:100] + "..." if container.get_text().strip() else "无内容摘要"
results.append(f"{i+1}. {title}\n {content}")
except Exception as e:
logger.debug(f"解析单个搜索结果时出错: {str(e)}")
continue
if results:
return f"百度搜索 '{query}' 的结果:\n" + "\n\n".join(results)
else:
return f"未找到关于 '{query}' 的搜索结果,请尝试其他关键词"
except Exception as e:
logger.error(f"解析百度搜索结果时出错: {str(e)}")
return f"解析百度搜索结果时出错: {str(e)}"
def _get_fallback_result(self, query: str) -> str:
"""备用搜索结果"""
return f"""搜索 '{query}' 的结果(网络搜索暂时不可用):
建议您:
1. 检查网络连接
2. 尝试使用更具体的关键词
3. 稍后重试
当前提供的信息基于模型训练数据,可能不是最新的。"""
class ReliableSearchTool:
"""搜索工具"""
def __init__(self):
self.baidu_tool = BaiduSearchTool()
def search(self, query: str, num_results: int = 5) -> str:
"""
使用百度搜索
"""
return self.baidu_tool.search(query, num_results)
def create_search_tools():
"""搜索工具集合"""
reliable_search = ReliableSearchTool()
tools = [
Tool(
name="web_search",
func=reliable_search.search,
description="使用网络搜索引擎获取最新信息。输入:搜索查询字符串"
),
Tool(
name="baidu_search",
func=reliable_search.search,
description="使用百度获取内容。输入:搜索查询字符串"
)
]
return tools
# 创建工具实例
search_tools = create_search_tools()
2.2 创建自定义输出解析器
文件:custom_parser.py
作用:处理Agent的输出格式
import re
import logging
from typing import Union
from langchain.agents import AgentOutputParser
from langchain.schema import AgentAction, AgentFinish
logger = logging.getLogger(__name__)
class CustomOutputParser(AgentOutputParser):
"""解析器,处理智谱AI的输出格式"""
def parse(self, text: str) -> Union[AgentAction, AgentFinish]:
logger.info(f"解析Agent输出: {text}")
# 检查是否包含Final Answer
if "Final Answer:" in text:
# 提取最终答案
final_answer_match = re.search(r"Final Answer:\s*(.*)", text, re.DOTALL)
if final_answer_match:
answer = final_answer_match.group(1).strip()
logger.info(f"提取到最终答案: {answer}")
return AgentFinish(
return_values={"output": answer},
log=text,
)
# 检查是否包含Action和Action Input
action_match = re.search(r"Action:\s*(.*?)\nAction Input:\s*(.*)", text, re.DOTALL)
if action_match:
action = action_match.group(1).strip()
action_input = action_match.group(2).strip().strip('"')
logger.info(f"提取到Action: {action}, Input: {action_input}")
return AgentAction(tool=action, tool_input=action_input, log=text)
# 如果无法解析,返回最终答案
logger.warning(f"无法解析Agent输出,直接返回文本: {text}")
return AgentFinish(
return_values={"output": text},
log=text,
)
2.3 创建Agent版本
文件:agent_demo.py
作用:演示完整的Agent + Tools使用
import os
import logging
from dotenv import load_dotenv
from langchain.agents import initialize_agent, AgentType
from langchain.memory import ConversationBufferWindowMemory
from langchain.prompts import MessagesPlaceholder
from langchain.schema import SystemMessage
from llm_zhipu import ZhipuAIChatLLM
from tools.search_tools import search_tools
from config.settings import validate_config
# 配置日志
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
# 加载环境变量并验证配置
load_dotenv()
try:
validate_config()
except Exception as e:
logger.error(f"配置验证失败: {e}")
raise
class HealthcareAgent:
def __init__(self):
# 使用智谱AI LLM
self.llm = ZhipuAIChatLLM(
model_name="glm-4-flash",
temperature=0.1, # 降低温度
max_tokens=2048,
api_key=os.getenv("ZHIPU_API_KEY")
)
# 创建记忆
self.memory = ConversationBufferWindowMemory(
memory_key="chat_history",
k=10,
return_messages=True
)
# 系统提示词
system_message = SystemMessage(content="""
你是一个专业的健康和生活方式助手,专门帮助用户分析健康风险并提供建议。
你的能力包括:
1. 搜索最新的健康信息和医学知识
2. 分析生活方式对健康的影响
3. 提供个性化的健康建议
4. 回答关于疾病预防和健康管理的问题
请遵循以下原则:
- 提供准确、科学的健康信息
- 对于严重的健康问题,建议用户咨询专业医生
- 尊重用户隐私,不询问过于私密的信息
- 用友好、专业的方式与用户交流
当需要最新信息时,请使用搜索工具。
重要:对于简单的问题(如日期、时间等),请直接回答,不要过度使用搜索工具。
""")
try:
# 初始化Agent
self.agent = initialize_agent(
tools=search_tools,
llm=self.llm,
agent=AgentType.CONVERSATIONAL_REACT_DESCRIPTION, # 对话型Agent
verbose=True,
memory=self.memory,
agent_kwargs={
"system_message": system_message,
"memory_prompts": [MessagesPlaceholder(variable_name="chat_history")],
"input_variables": ["input", "chat_history", "agent_scratchpad"]
},
handle_parsing_errors=True,
max_iterations=3, # 限制最大迭代次数,避免无限循环
early_stopping_method="generate" # 提前停止
)
logger.info("HealthcareAgent初始化成功")
except Exception as e:
logger.error(f"HealthcareAgent初始化失败: {e}")
raise
def chat(self, user_input: str) -> str:
"""与Agent对话"""
try:
# 对于简单问题,直接使用LLM回答
simple_questions = ["今天的日期", "现在几点", "当前时间", "日期", "时间"]
if any(q in user_input for q in simple_questions):
logger.info("检测到简单问题,直接使用LLM回答")
from datetime import datetime
now = datetime.now()
if "日期" in user_input:
return f"今天是{now.strftime('%Y年%m月%d日')}"
elif "时间" in user_input or "几点" in user_input:
return f"现在是{now.strftime('%H点%M分')}"
response = self.agent.run(user_input)
return response
except Exception as e:
logger.error(f"Agent对话过程中出错: {e}")
return f"抱歉,处理您的请求时出现了错误: {str(e)}"
def main():
"""主函数 - 测试Agent"""
print("=" * 60)
print(" 健康与生活方式助手 Agent")
print("=" * 60)
print("注意:本助手提供的信息仅供参考,不能替代专业医疗建议")
print("输入 '退出' 或 'quit' 结束对话")
print("-" * 60)
try:
# 创建Agent实例
agent = HealthcareAgent()
while True:
try:
user_input = input("\n您: ").strip()
if user_input.lower() in ['退出', 'quit', 'exit']:
print("\n助手: 感谢使用!祝您健康!")
break
if not user_input:
continue
print("\n助手: ", end="", flush=True)
response = agent.chat(user_input)
print(response)
except KeyboardInterrupt:
print("\n\n助手: 对话已中断,再见!")
break
except Exception as e:
print(f"\n助手: 抱歉,出现了错误: {str(e)}")
except Exception as e:
print(f"初始化Agent失败: {e}")
print("请检查:")
print("1. ZHIPU_API_KEY环境变量是否正确设置")
print("2. 网络连接是否正常")
print("3. 依赖包是否正确安装")
if __name__ == "__main__":
main()
典型应用场景
Agent可结合工具链实现以下流程:
- 用户提问“北京今日天气”
- Agent调用搜索工具获取实时数据
- 模型整理结果并生成自然语言回复
技术趋势与展望
- 解耦与分层:类似Web开发的前后端分离,AI应用趋向模块化设计(模型、数据、逻辑分离)。
- 目标驱动开发:开发者通过定义目标(而非具体步骤)引导AI自主完成任务。
- 范式演进:LangChain提出的Agent、Tools等概念可能成为未来AI应用的标配,但具体实现会持续优化(如更高效的检索算法或轻量级Agent)。
通过LangChain,开发者能够构建从简单问答到复杂自动化流程的AI应用,推动大模型从“知识库”向“智能助手”转型。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)