基于助睿数智 Uniplore 的学生考勤行为聚类分析:从 K-Means 建模到考勤群体画像标签回写
摘要
本文基于上一实验构建完成的学生考勤主题标签表 student_attendance_stats,进一步使用助睿数智(Uniplore)在线实验平台完成学生考勤行为的聚类分析与画像标签扩展。
实验以迟到次数、早退次数、请假次数、没穿校服次数等考勤行为指标为核心特征,借助 AI Studio 中的 K-Means 聚类算法对学生进行自动分群,并通过助睿 BI 平台对聚类结果进行可视化分析,最终将机器生成的聚类簇解释为“自律模范型”“轻微波动型”“纪律高危型”三类考勤群体。
最后,本文通过助睿 ETL 将聚类簇编号与群体分类标签回写至原学生考勤主题标签表,实现从“考勤统计标签”到“考勤画像扩展标签”的完整闭环。
该实验能够帮助初学者理解零代码平台下的数据建模、可视化解释和标签回写流程,也为校园学生精细化管理、行为干预和数据化决策提供了实践参考。
一、为什么要做学生考勤聚类分析?
在上一实验中,我们已经通过助睿 ETL 平台完成了学生考勤主题标签表的构建。该表中已经包含学生的基础信息、考勤次数统计结果以及部分画像维度字段,例如:
- 学生 ID
- 班级 ID
- 年级
- 是否住校
- 校区类型
- 迟到次数
- 早退次数
- 请假次数
- 没穿校服次数
但是,仅仅有这些统计字段还不够。
例如,某个学生迟到 10 次,另一个学生请假 8 次,还有一个学生迟到、早退、校服违规都比较多。
如果只看单个字段,很难快速判断这些学生到底属于哪类考勤群体。
所以本次实验的目标,就是在已有考勤主题标签表的基础上,使用 K-Means 聚类算法 自动识别不同类型的考勤群体。
最终我们希望得到的不只是冷冰冰的聚类编号 C1、C2、C3,而是能够转化为更容易理解的学生画像标签,例如:
- 自律模范型
- 轻微波动型
- 纪律高危型
这样一来,学生考勤数据就不再只是统计结果,而是可以进一步转化为管理视角下的行为画像。
二、实验平台与数据基础
本次实验使用的是 助睿数智(Uniplore)在线实验平台。
助睿数智是一站式数据科学平台,覆盖从数据接入、ETL 处理、机器学习建模到可视化展示的完整链路,适用于数据分析教学、机器学习实验以及企业级数据加工场景。
本次实验主要使用到三个模块:
| 模块 | 作用 |
|---|---|
| 数据集成平台(助睿 ETL) | 用于表结构扩展、字段映射、结果回写 |
| 人工智能平台(AI Studio) | 用于 K-Means 聚类建模 |
| 助睿 BI 数据可视化平台 | 用于聚类结果分析与群体画像解释 |
实验平台地址:
产品官网地址:
本次实验的前置数据表是上一实验输出的(具体可参考上次实验:助睿数智 Uniplore 的学生用户画像实验实战:考勤主题标签构建全流程讲解https://blog.csdn.net/2301_81340819/article/details/160994964):
student_attendance_stats这张表已经是一个相对干净、标准化的学生考勤主题标签表,可以直接作为聚类建模的数据来源。
三、实验目标
本次实验主要完成以下几个目标:
第一,基于学生考勤主题标签表,提取迟到、早退、请假、校服违规等核心考勤行为指标。
第二,使用 AI Studio 中的 K-Means 聚类算法,将学生自动划分为不同考勤行为群体。
第三,借助助睿 BI 平台制作散点图和仪表盘,对聚类簇编号进行业务解释。
第四,将聚类簇编号映射为可读性更强的中文考勤群体标签。
第五,通过助睿 ETL 将聚类结果回写到原始学生考勤主题标签表中,完成考勤主题扩展标签构建。
整个实验流程可以概括为:
考勤标签表 → K-Means 聚类 → BI 可视化解释 → 聚类标签映射 → ETL 回写结果表
实验总体流程图

四、实验数据说明
本次实验使用上一实验生成的学生考勤主题标签表 student_attendance_stats。
该表既包含学生基础属性字段,也包含已经统计好的考勤行为指标字段。
主要字段如下:
| 字段名 | 字段说明 | 类型 |
|---|---|---|
| id | 自增主键 | 连续整数 |
| student_id | 学生 ID | 连续整数 |
| student_name | 学生姓名 | 文本 |
| class_id | 班级 ID | 连续整数 |
| class_name | 班级名称 | 文本 |
| grade | 年级 | 分类 |
| gender | 性别 | 二分类 |
| birth_date | 出生日期 | 日期 / 文本 |
| political_status | 政治面貌 | 分类 |
| is_boarder | 是否住校 | 二分类 |
| campus_type | 校区类型 | 分类 |
| late_count | 迟到次数 | 连续整数 |
| early_leave_count | 早退次数 | 连续整数 |
| leave_count | 请假次数 | 连续整数 |
| uniform_violate_count | 没穿校服次数 | 连续整数 |
| create_time | 统计入库时间 | 日期时间 |
五、为什么选择 K-Means 聚类?
本次实验的建模目标是根据学生考勤行为的相似性进行自动分群。
这类问题本质上属于 无监督学习 场景,因为我们事先并没有给每个学生标注“好学生”“风险学生”这样的类别标签。
K-Means 聚类适合本实验,主要有三个原因。
1. 特征维度清晰
本次聚类主要使用 4 个核心行为指标:
late_count:迟到次数early_leave_count:早退次数leave_count:请假次数uniform_violate_count:没穿校服次数
这些字段都直接反映学生考勤行为,业务含义清晰,不需要复杂特征工程。
2. 数据类型适配
这 4 个字段都是次数类连续变量,适合输入 K-Means 模型。
相比文本字段、类别字段,这类数值字段更适合通过距离度量计算学生之间的行为相似性。
3. 聚类结果可解释
K-Means 输出的簇编号虽然本身只是 C1、C2、C3,但我们可以通过后续可视化分析观察每个簇在迟到、请假、校服违规等指标上的表现,从而为它们赋予业务含义。
例如:
- 异常次数都很低 → 自律模范型
- 偶发异常 → 轻微波动型
- 多项异常明显偏高 → 纪律高危型
六、AI Studio 聚类建模实操
接下来进入助睿数智平台的 AI Studio 进行聚类建模。
6.1 新建 AI 工作流
首先点击左侧菜单中的 人工智能,进入 AI Studio 平台。
在人工智能模块中,点击:
+ → 新建工作流创建一个新的建模工作流。
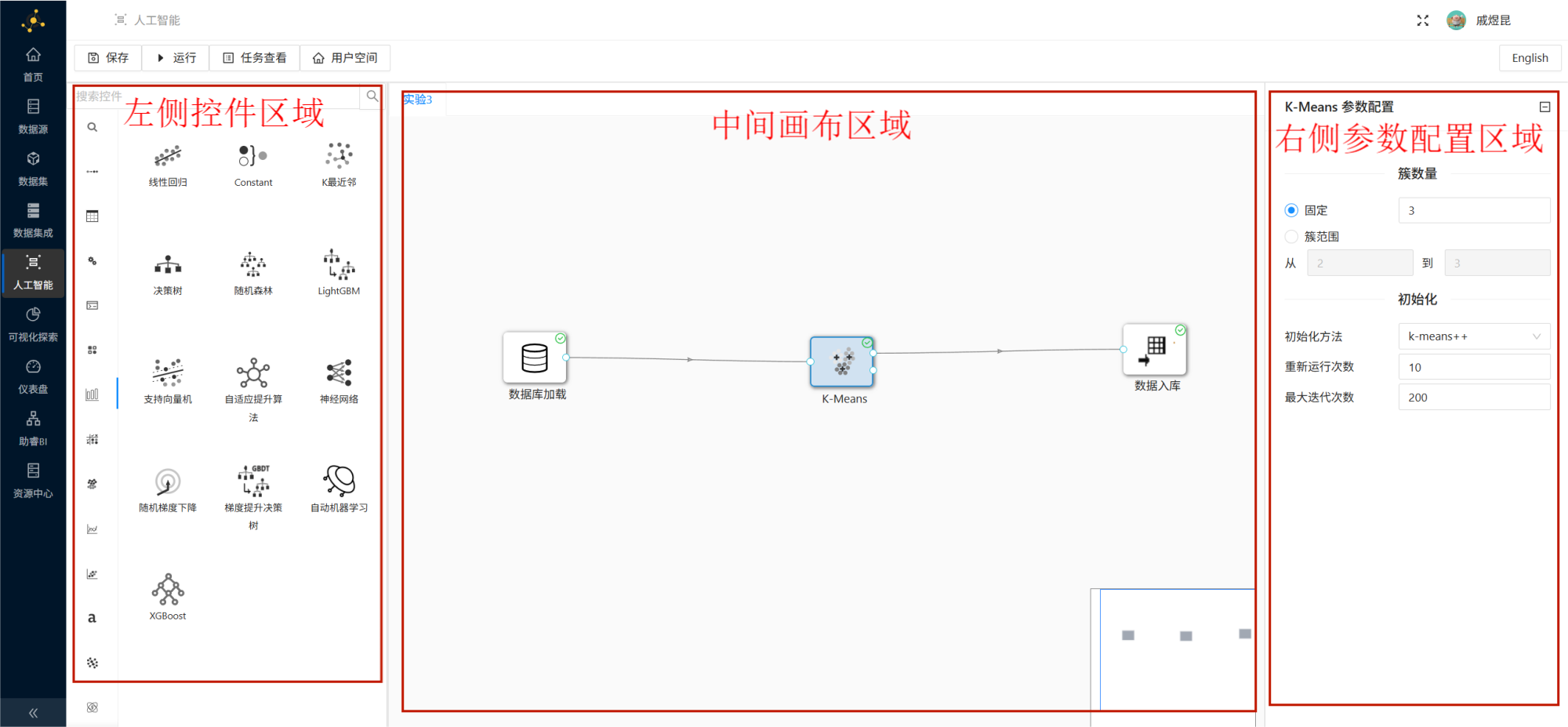
AI Studio 的工作区主要由三部分组成:
- 左侧控件列表
- 中间画布
- 右侧参数配置区域
后续的数据加载、模型训练和结果输出都会通过拖拽控件完成。
AI Studio 新建工作流页面
6.2 使用数据库加载控件读取数据
在控件列表中搜索:
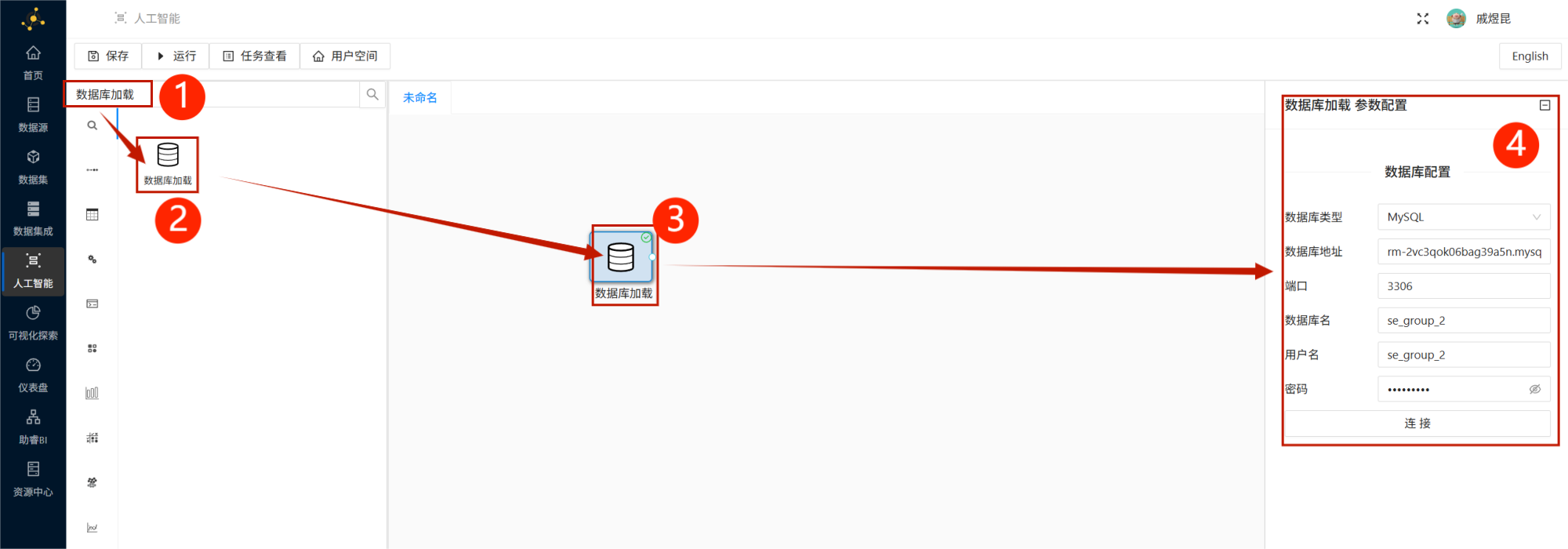
数据库加载将该控件拖拽到画布中。
双击数据库加载控件,在右侧配置窗口中填写团队私有数据库连接信息,然后点击连接。
连接成功后,在数据表列表中选择:
student_attendance_stats选择后,平台会自动加载该表的字段信息。
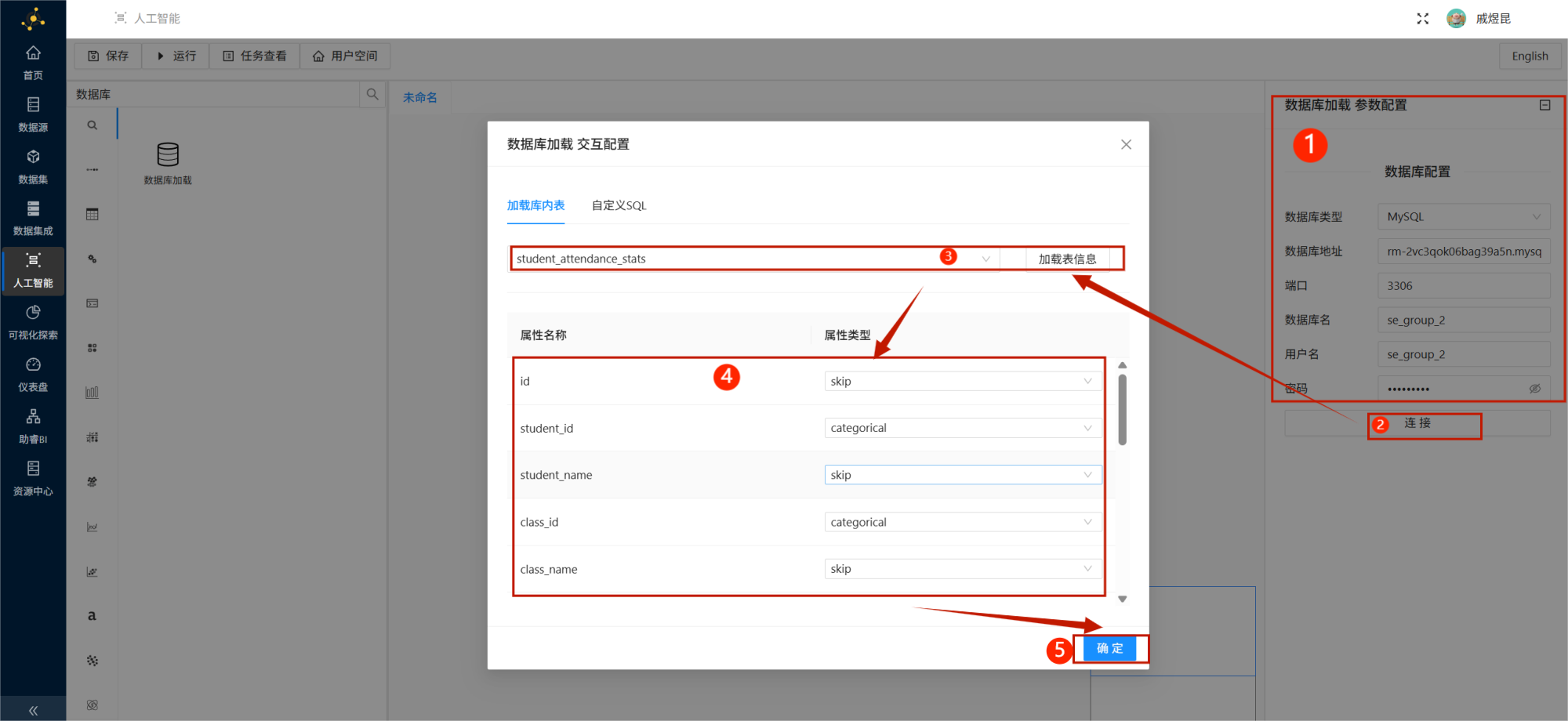
本次实验并不需要所有字段参与建模。
为了保证模型聚焦考勤行为本身,我们只保留以下字段:
student_idclass_idlate_countearly_leave_countleave_countuniform_violate_count
其余字段设置为 skip。
字段属性类型建议设置如下:
| 字段名 | 属性类型 |
|---|---|
| id | skip |
| student_id | categorical |
| student_name | skip |
| class_id | categorical |
| class_name | skip |
| grade | skip |
| gender | skip |
| birth_date | skip |
| political_status | skip |
| is_boarder | skip |
| campus_type | skip |
| late_count | numeric |
| early_leave_count | numeric |
| leave_count | numeric |
| uniform_violate_count | numeric |
| create_time | skip |
这里的核心思路是:
学生 ID 和班级 ID 用于保留身份信息,真正参与聚类的是 4 个考勤次数指标。
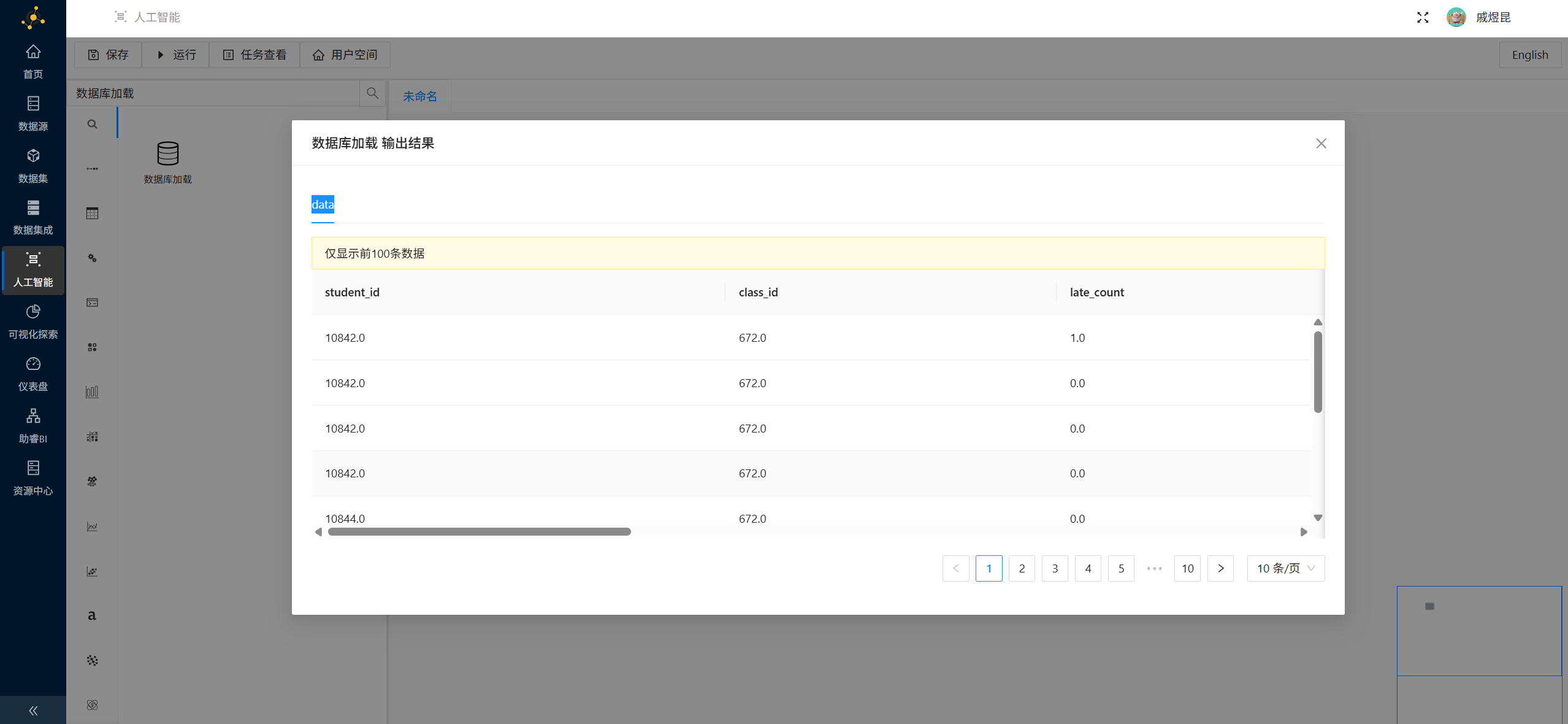
配置完成后,右键数据库加载控件,选择 运行该控件。
运行成功后可以右键查看输出结果,确认数据已经正常加载。
数据库加载配置界面1
数据库加载配置界面2
输出结果预览界面
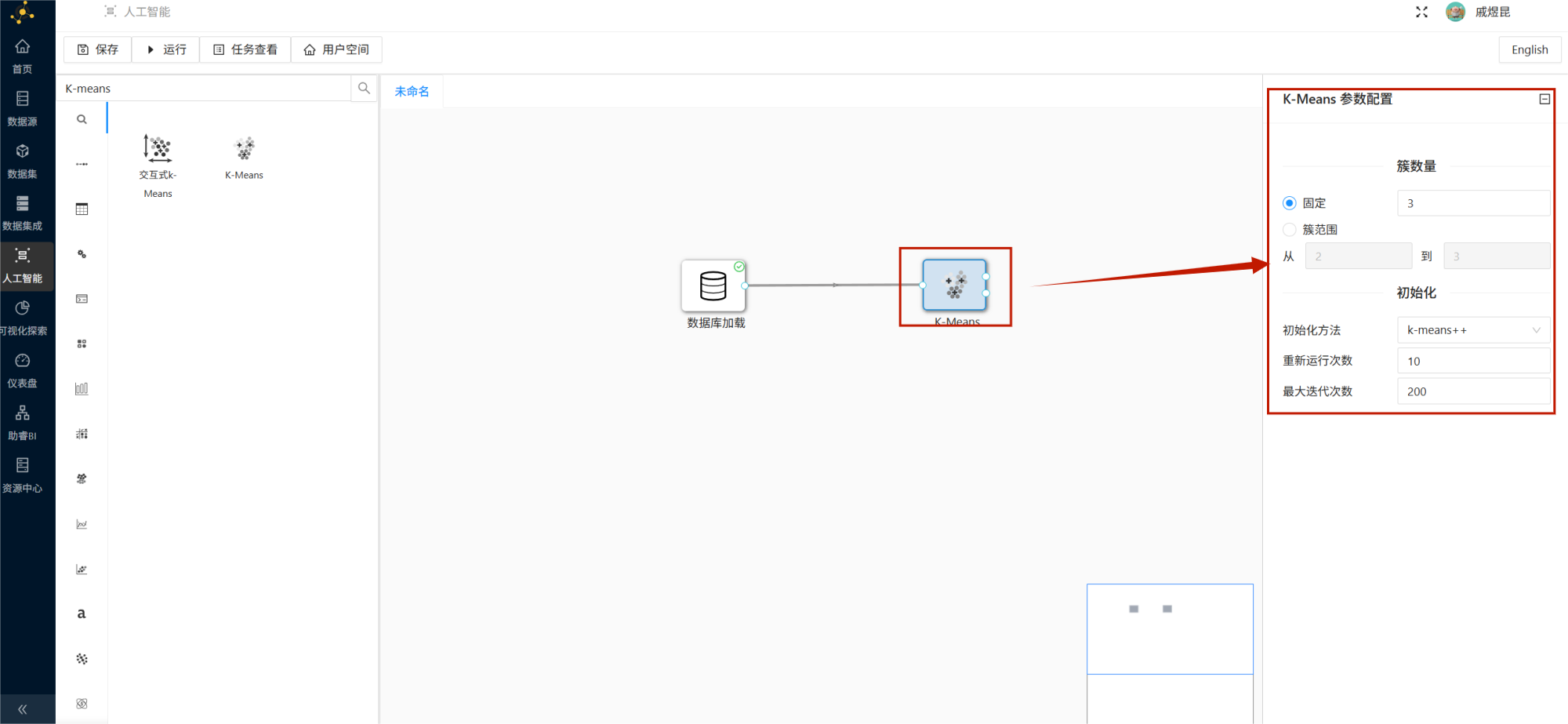
6.3 使用 K-Means 进行聚类建模
接下来在控件列表中搜索:
K-Means将 K-Means 组件拖拽到画布中,并将数据库加载控件连接到 K-Means 组件。
双击 K-Means 组件,设置聚类簇数量为:
3这里选择 3 类,是因为从学生考勤管理的业务角度来看,可以初步划分为:
- 表现较好的群体
- 偶发异常的群体
- 需要重点关注的群体
所以将簇数量固定为 3,便于后续解释和应用。
其他参数可以保持默认。
配置完成后,右键运行 K-Means 控件。
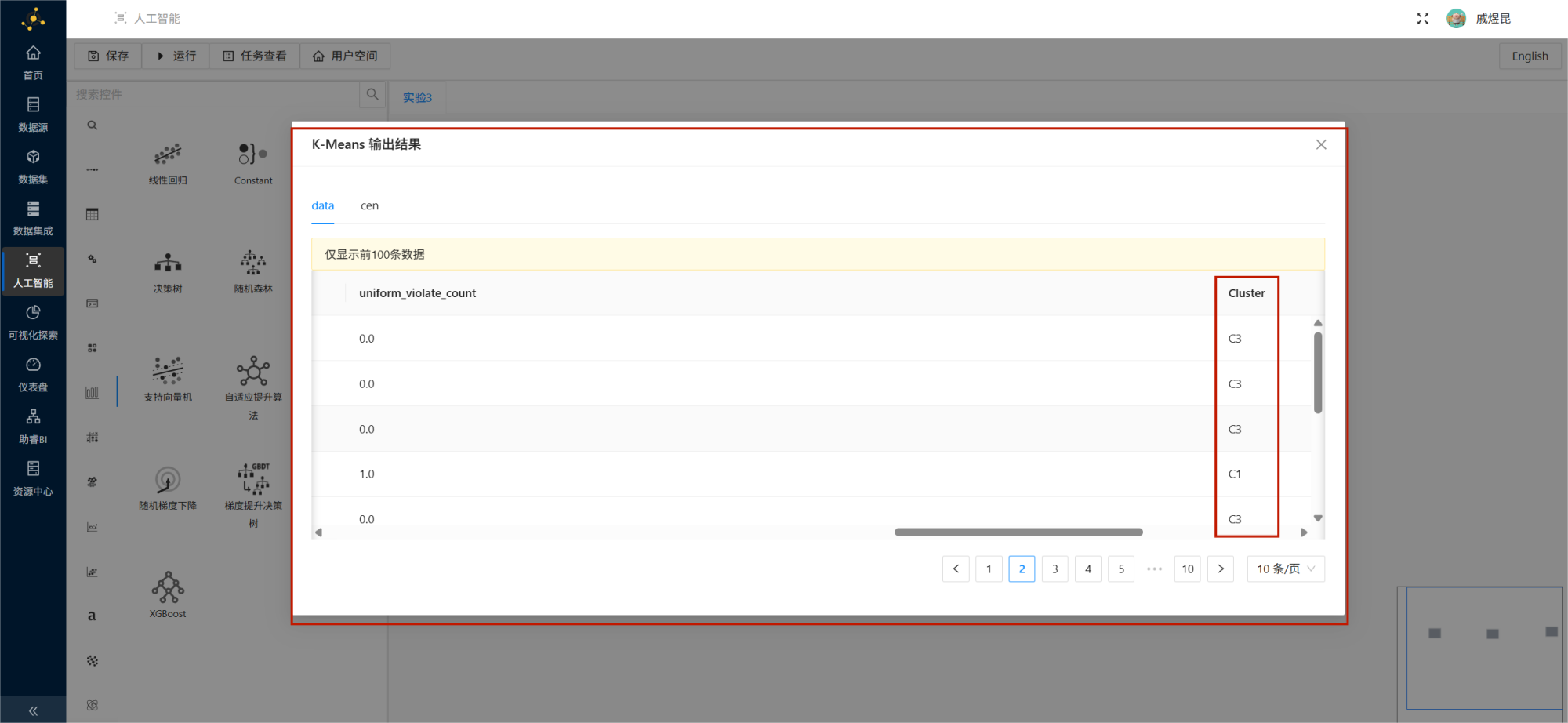
运行成功后查看输出结果,可以看到每个学生都被打上了对应的聚类簇编号,例如:
- C1
- C2
- C3
这一步完成后,说明平台已经根据学生的考勤行为特征完成了自动分群。
K-Means 参数配置
聚类输出结果,重点展示 Cluster 字段
6.4 将聚类结果保存到数据库
聚类完成后,需要将结果保存到数据库中,方便后续在 BI 平台中分析,也方便后续通过 ETL 回写到学生考勤主题标签表。
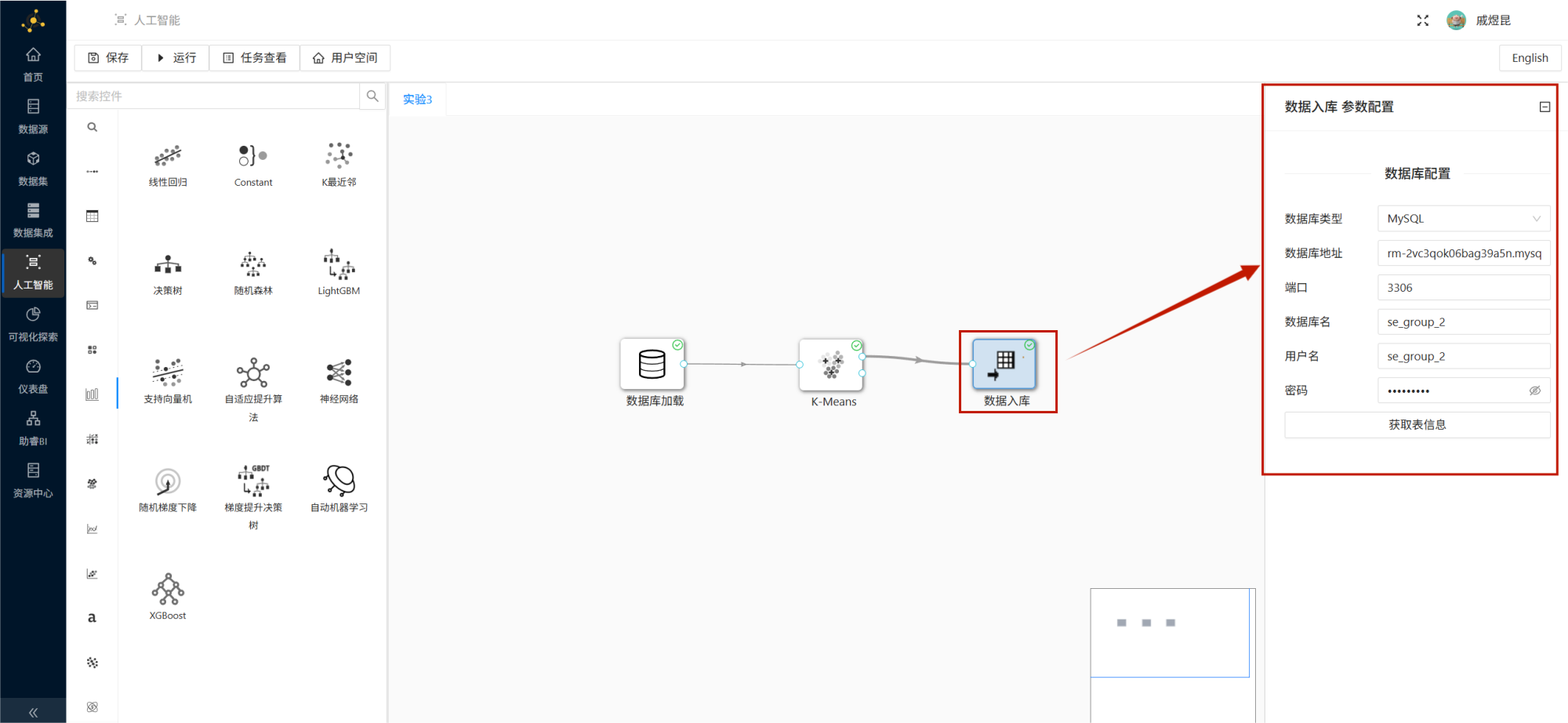
在画布中拖入:
数据入库将 K-Means 组件连接到数据入库组件。
双击数据入库组件,填写团队私有数据库连接信息,然后点击 获取表信息。
在弹出的窗口中选择:
新建数据表表名称设置为:
student_cluster配置完成后运行整个工作流。
如果所有控件都运行成功,说明 K-Means 聚类结果已经保存到数据库表 student_cluster 中。
聚类结果入库配置
七、使用助睿 BI 分析聚类簇含义
K-Means 输出的 C1、C2、C3 本身只是机器编号。
如果直接把这些编号交给业务人员使用,几乎没有解释价值。
所以我们需要通过助睿 BI 平台观察不同簇在各类考勤指标上的分布情况,然后为每个簇赋予清晰的业务含义。
7.1 创建 BI 数据源连接
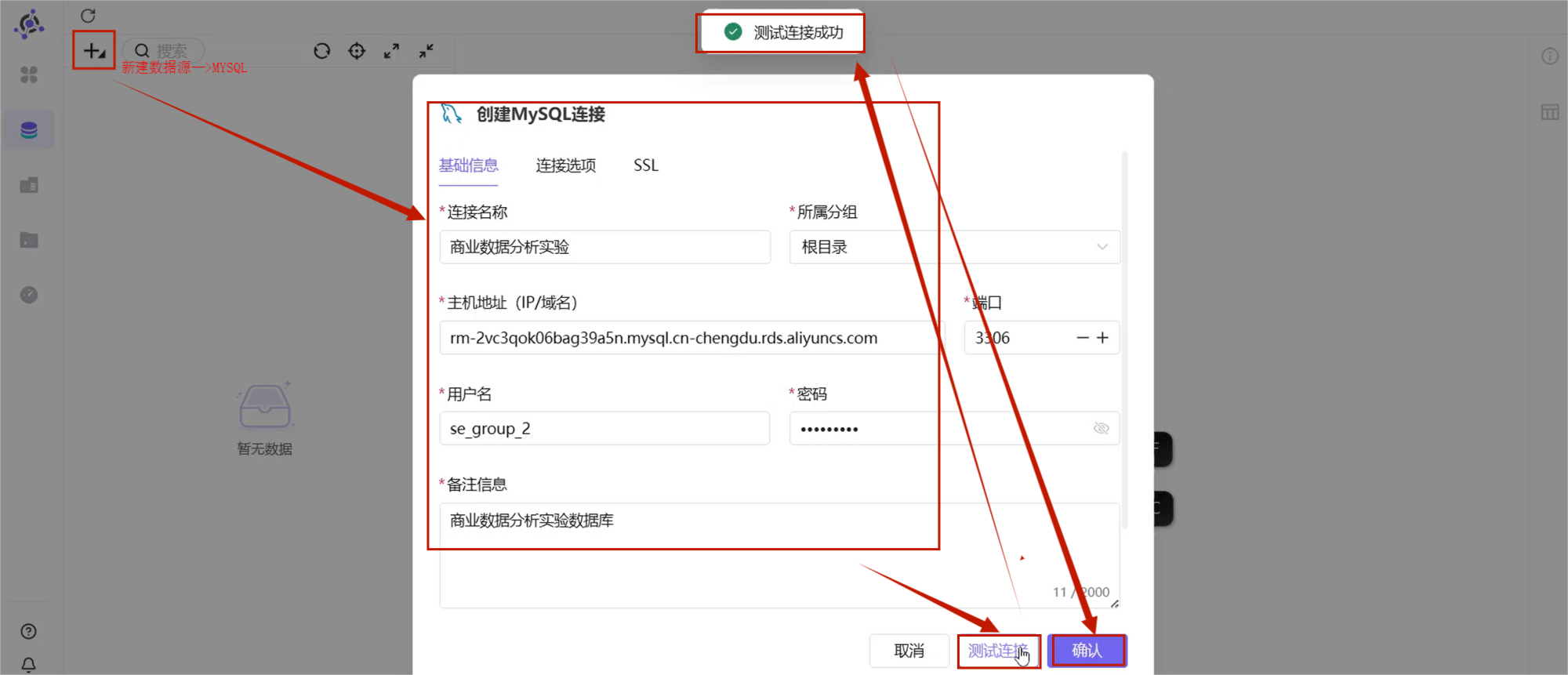
点击实验平台左侧菜单中的 助睿 BI,进入助睿 BI 平台。
进入后点击左侧菜单:
数据源然后点击:
+ → 新建连接 → MySQL在弹出的窗口中填写团队私有数据库连接信息。
点击 测试连接。
如果提示测试连接成功,就点击确认。
创建完成后,在数据库目录中可以看到本次实验用到的表,例如:
student_cluster也可以右键查看表数据,确认聚类结果已经正常写入。
助睿 BI 数据源连接
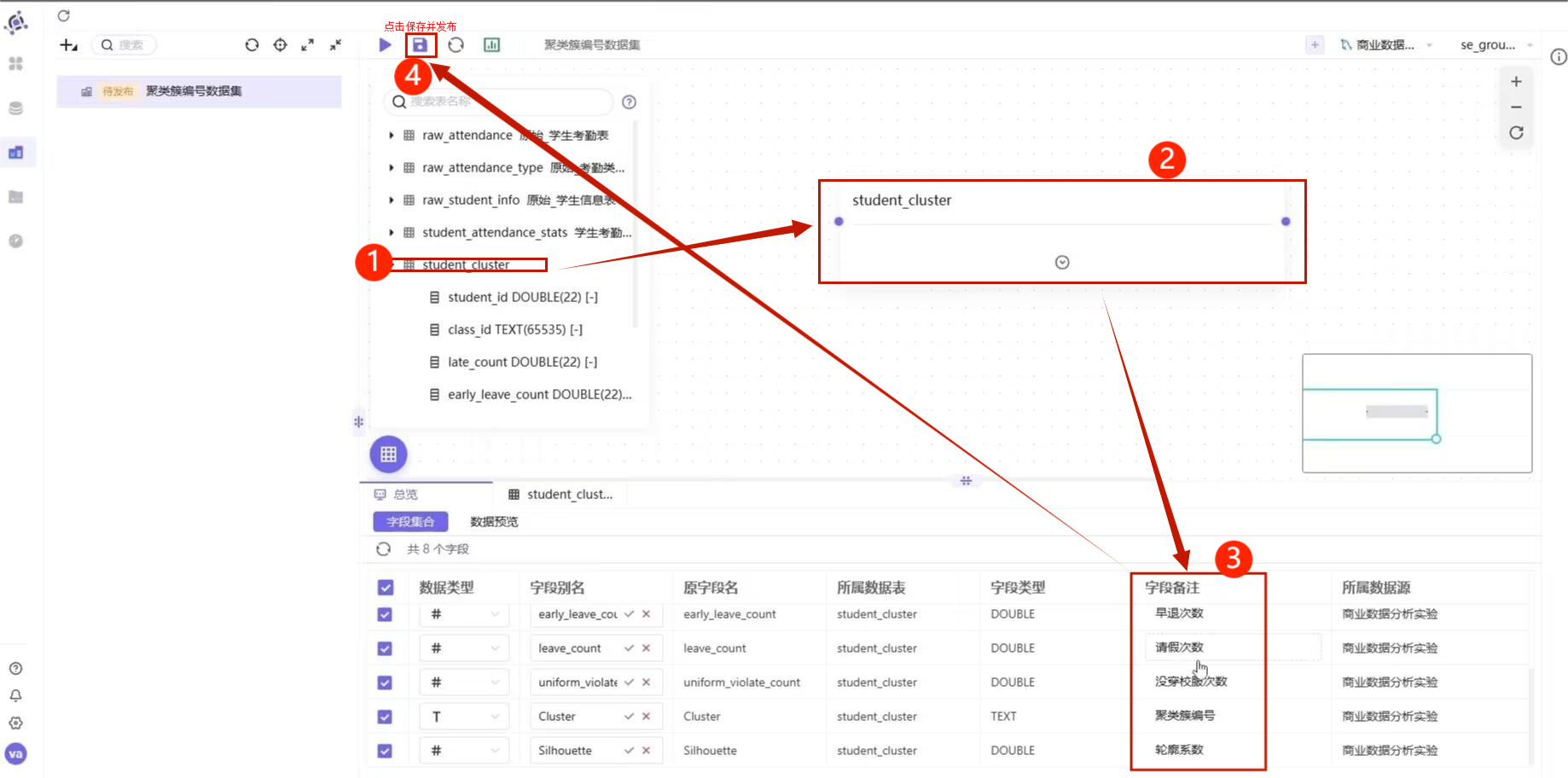
7.2 构建聚类结果数据集
数据源连接成功后,需要将 student_cluster 构建为 BI 数据集。
点击左侧菜单:
数据集然后点击:
+ → 新建数据集输入数据集名称,例如:
聚类簇编号数据集创建成功后进入数据集配置页面。
选择刚刚创建的数据库数据源,然后选择 student_cluster 所在目录。
将 student_cluster 表拖拽到画布中。
为了后续做图表更直观,需要把字段备注修改为中文。
字段备注可以参考下面配置:
| 原字段名 | 字段备注 |
|---|---|
| student_id | 学生ID |
| class_id | 班级ID |
| late_count | 迟到次数 |
| early_leave_count | 早退次数 |
| leave_count | 请假次数 |
| uniform_violate_count | 没穿校服次数 |
| Cluster | 聚类簇编号 |
| Silhouette | 轮廓系数 |
修改完成后,点击保存,并选择 保存并发布。
注意,只有发布后的数据集才能在工作表中引用。
BI 数据集字段备注配置
7.3 制作聚类散点图工作表
接下来进入工作表模块,创建用于分析聚类簇分布的散点图。
点击左侧菜单:
工作表为了方便管理,可以先创建一个分组,例如:
聚类簇对应的考勤画像群体分类分析然后在该分组下新建工作表。
第一个工作表可以命名为:
迟到早退次数的聚类簇分析进入工作表设计页面后,选择刚刚发布的:
聚类簇编号数据集图表类型选择:
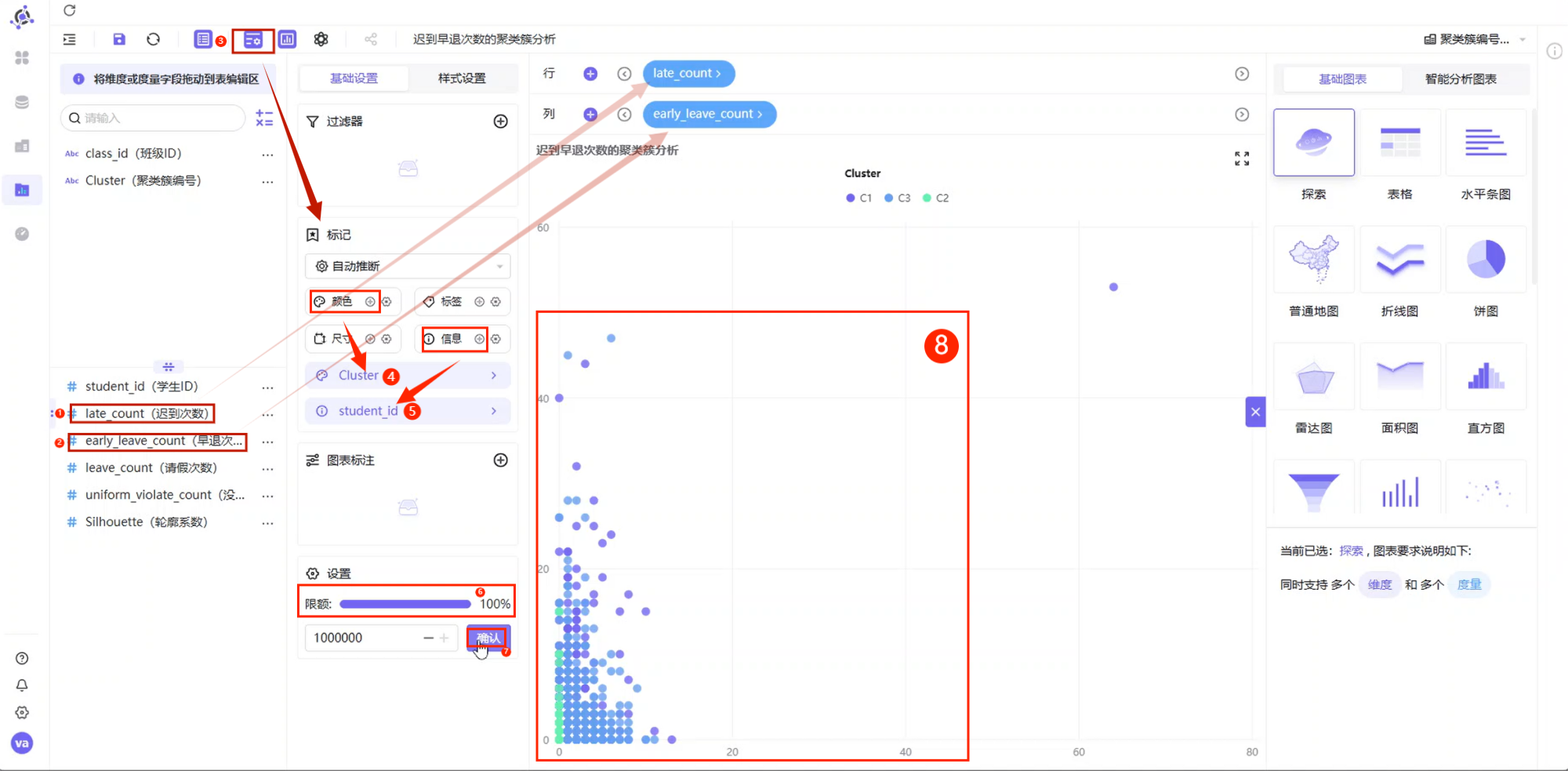
探索器然后进行字段拖拽:
- 将
late_count(迟到次数)拖拽到 X 轴 - 将
early_leave_count(早退次数)拖拽到 Y 轴 - 将
Cluster(聚类簇编号)添加到颜色区域 - 将
student_id(学生ID)添加到信息区域
同时,将 student_id 设置为维度。
由于系统默认限额可能是 2000 条数据,为避免数据过多时显示不完整,建议将数据限额设置为 100%。
为了让不同聚类簇区分更明显,可以在颜色设置中选择对比度更强的主题。
完成后保存并发布工作表。
迟到早退聚类散点图
7.4 构建 6 组两两指标分析图
为了更全面地解释聚类结果,我们不能只看迟到和早退两个字段,还要分析四个考勤异常指标之间的组合关系。
因此可以继续创建以下 6 个工作表:
| 工作表名称 | X 轴 | Y 轴 |
|---|---|---|
| 迟到与早退次数的聚类簇分析 | 迟到次数 | 早退次数 |
| 迟到与请假次数的聚类簇分析 | 迟到次数 | 请假次数 |
| 迟到与没穿校服次数的聚类簇分析 | 迟到次数 | 没穿校服次数 |
| 早退与请假次数的聚类簇分析 | 早退次数 | 请假次数 |
| 早退与没穿校服次数的聚类簇分析 | 早退次数 | 没穿校服次数 |
| 请假与没穿校服次数的聚类簇分析 | 请假次数 | 没穿校服次数 |
每张图的颜色字段都使用:
Cluster(聚类簇编号)信息字段可以使用:
student_id(学生ID)这样可以通过多个二维视角观察不同聚类簇的行为差异。
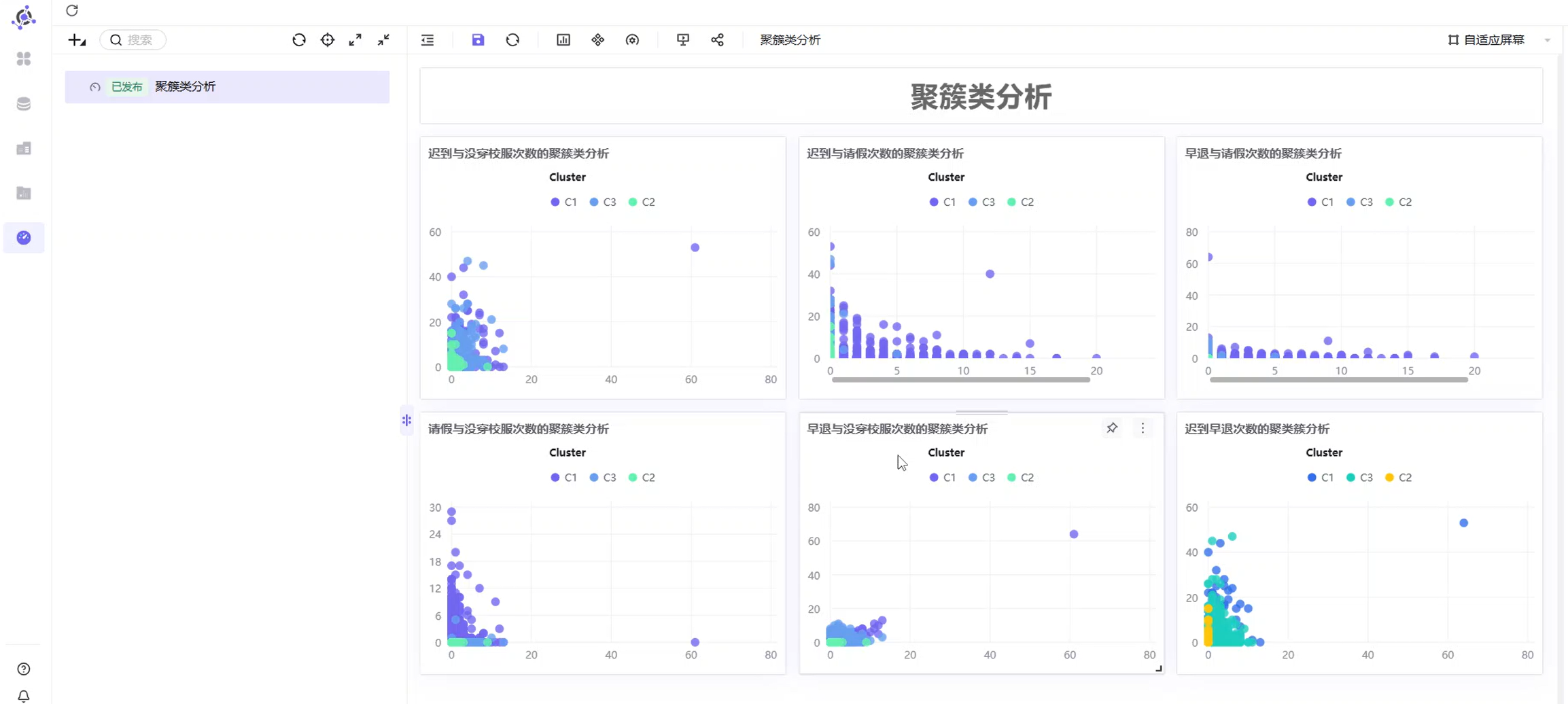
7.5 搭建聚类分析仪表盘
为了统一观察 6 个工作表,可以继续创建一个 BI 仪表盘。
点击左侧菜单:
仪表盘然后选择:
+ → 新建仪表盘仪表盘名称可以设置为:
聚类簇分析进入仪表盘设计页面后,先拖入一个文本组件,设置标题为:
聚类簇分析然后将前面制作好的 6 个工作表依次拖入仪表盘画布中。
可以采用 2 行 3 列的布局,方便横向比较不同指标组合下的聚类分布。
调整好大小和位置后,点击保存并发布仪表盘。
聚类分析仪表盘
八、聚类群体画像解读
通过 6 组两两指标散点图,可以观察不同聚类簇在考勤行为指标上的分布特征。
K-Means 只负责给出机器编号,但真正有价值的是我们根据图表把这些编号解释成业务含义。
结合图表分布,可以将三类聚类簇解释为以下三类学生群体。
8.1 C1:自律模范型
C1 群体在迟到、早退、请假、没穿校服等指标上整体都处于低频区间。
这类学生的考勤行为相对稳定,异常次数少,纪律意识较强,是校园考勤管理中的正面典型。
可以将 C1 解释为:
自律模范型8.2 C2:轻微波动型
C2 群体整体也集中在低频区间,但相比 C1,分布略微分散。
这类学生可能存在少量偶发的请假或校服违规情况,但迟到和早退次数整体仍然较低。
可以将 C2 解释为:
轻微波动型这类学生通常不属于重点风险对象,但适合通过日常提醒进行管理。
8.3 C3:纪律高危型
C3 群体表现出明显的离群特征。
在迟到次数与其他指标的组合图中,可以看到该类学生存在高频迟到现象,并且可能伴随早退、请假或校服违规等多维度异常行为。
这类学生的考勤问题更突出,是后续校园管理中需要重点关注和干预的对象。
可以将 C3 解释为:
纪律高危型九、最终聚类群体映射结果
根据 BI 可视化分析结果,可以得到聚类簇与群体分类之间的映射关系。
| 聚类簇编号 | 群体分类名称 | 核心特征 |
|---|---|---|
| C1 | 自律模范型 | 全维度异常次数较低,出勤表现稳定,纪律意识强 |
| C2 | 轻微波动型 | 整体纪律可控,存在偶发请假或校服违规 |
| C3 | 纪律高危型 | 异常次数偏高,多维度违纪行为叠加,需要重点关注 |
注意:如果你实际平台中颜色或簇编号解释略有差异,应以你自己 BI 图表中的聚类分布为准。K-Means 的簇编号本身没有固定业务含义,需要结合图表进行解释。
十、将聚类标签回写到学生考勤主题标签表
到这里,我们已经完成了 K-Means 聚类建模和 BI 可视化解释。
但如果只停留在 student_cluster 表中,聚类结果还没有真正融入原有学生考勤主题标签表。
因此下一步需要把聚类结果回写到:
student_attendance_stats这样学生考勤主题标签表就会新增两个扩展标签:
cluster:聚类簇编号attendance_group:考勤群体分类
10.1 为结果表新增扩展字段
首先进入数据集成平台,也就是助睿 ETL。
打开上一实验创建的 ETL 项目,新建转换流:
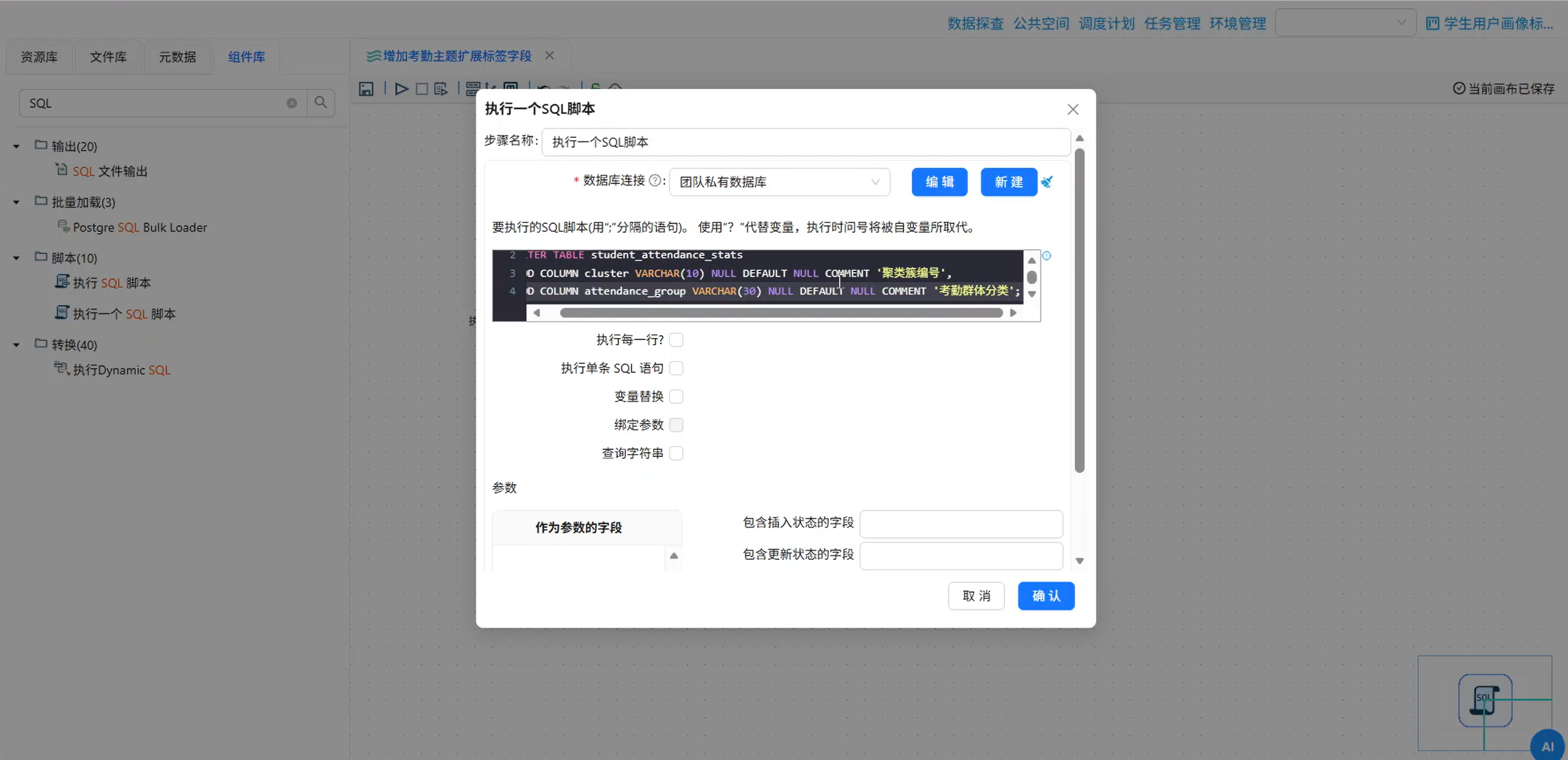
增加考勤主题扩展标签字段在画布中拖入:
执行一个 SQL 脚本数据库连接选择:
团队私有数据库SQL 脚本如下:
ALTER TABLE student_attendance_stats
ADD COLUMN cluster VARCHAR(10) NULL DEFAULT NULL COMMENT '聚类簇编号',
ADD COLUMN attendance_group VARCHAR(30) NULL DEFAULT NULL COMMENT '考勤群体分类';运行转换流。
执行成功后,student_attendance_stats 表中就新增了两个字段。
新增扩展字段 SQL 执行
10.2 获取聚类结果表 student_cluster
接下来新建转换流:
增加考勤群体分类标签在画布中拖入:
表输入双击表输入组件,从团队私有数据库中选择 AI Studio 输出的聚类结果表:
student_cluster获取该表的 SQL 查询语句。
这里的目标是读取每个学生对应的聚类簇编号。
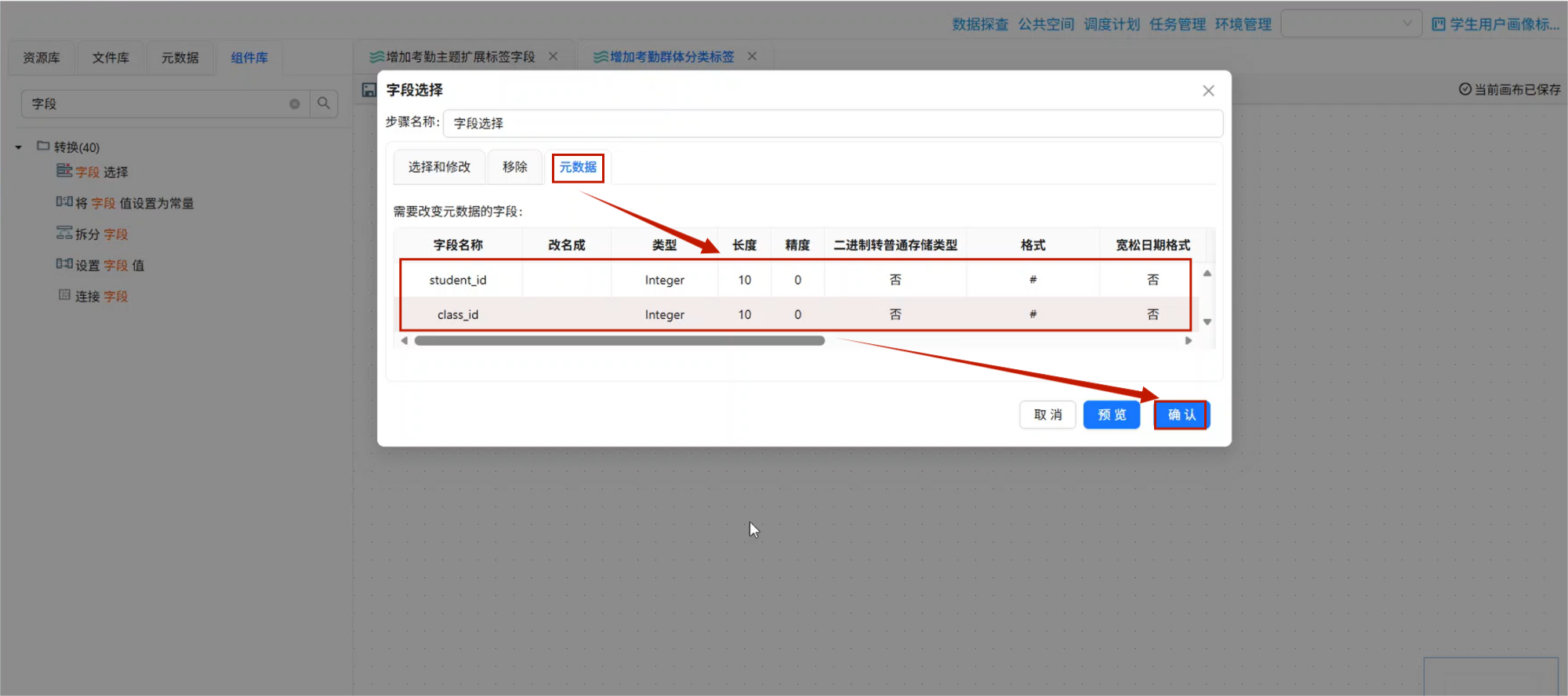
10.3 字段选择:保留 student_id 和 Cluster
student_cluster 表中字段较多,但本次回写只需要两个核心字段:
student_idCluster
因此拖入:
字段选择将表输入组件连接到字段选择组件。
双击字段选择组件,进入移除字段配置,只保留:
student_id
Cluster其余字段删除。
如果后续更新时要求字段类型一致,还需要在元数据中确认 student_id 类型是否与 student_attendance_stats 表一致。
字段选择保留 student_id 与 Cluster
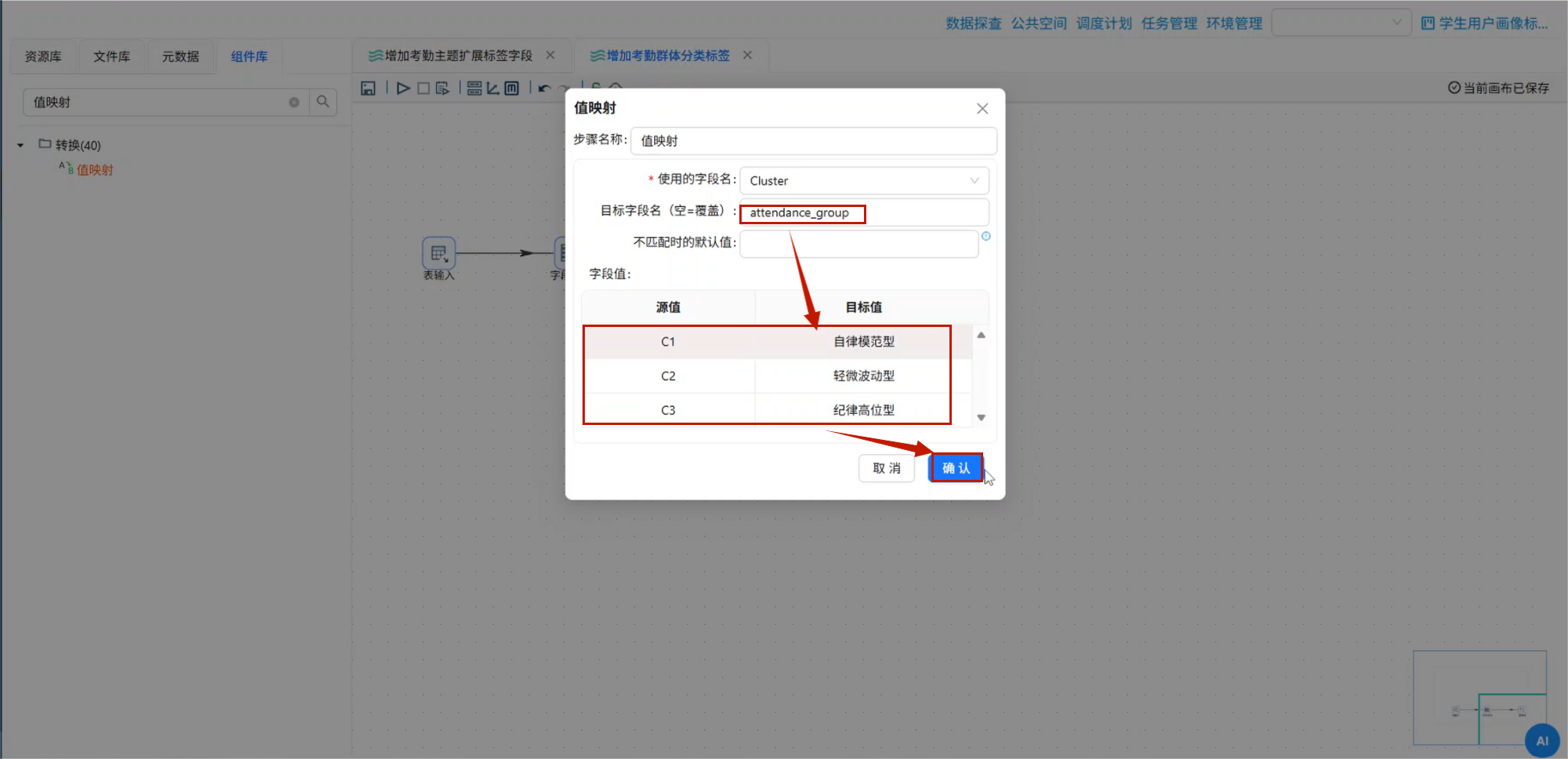
10.4 聚类簇编号映射为中文群体标签
原始聚类结果只有 C1、C2、C3,可读性较差。
所以需要使用 值映射 组件生成中文群体分类字段。
拖入:
值映射连接字段选择组件。
双击值映射组件,使用字段名选择:
Cluster目标字段名设置为:
attendance_group然后配置映射关系。
如果按本文前面的聚类解释,建议使用下面映射:
| 源值 | 目标值 |
|---|---|
| C1 | 自律模范型 |
| C2 | 轻微波动型 |
| C3 | 纪律高危型 |
如果你实际 BI 分析得到的簇含义不同,则按照自己的图表结果调整映射关系。
配置完成后点击确认。
聚类簇编号值映射
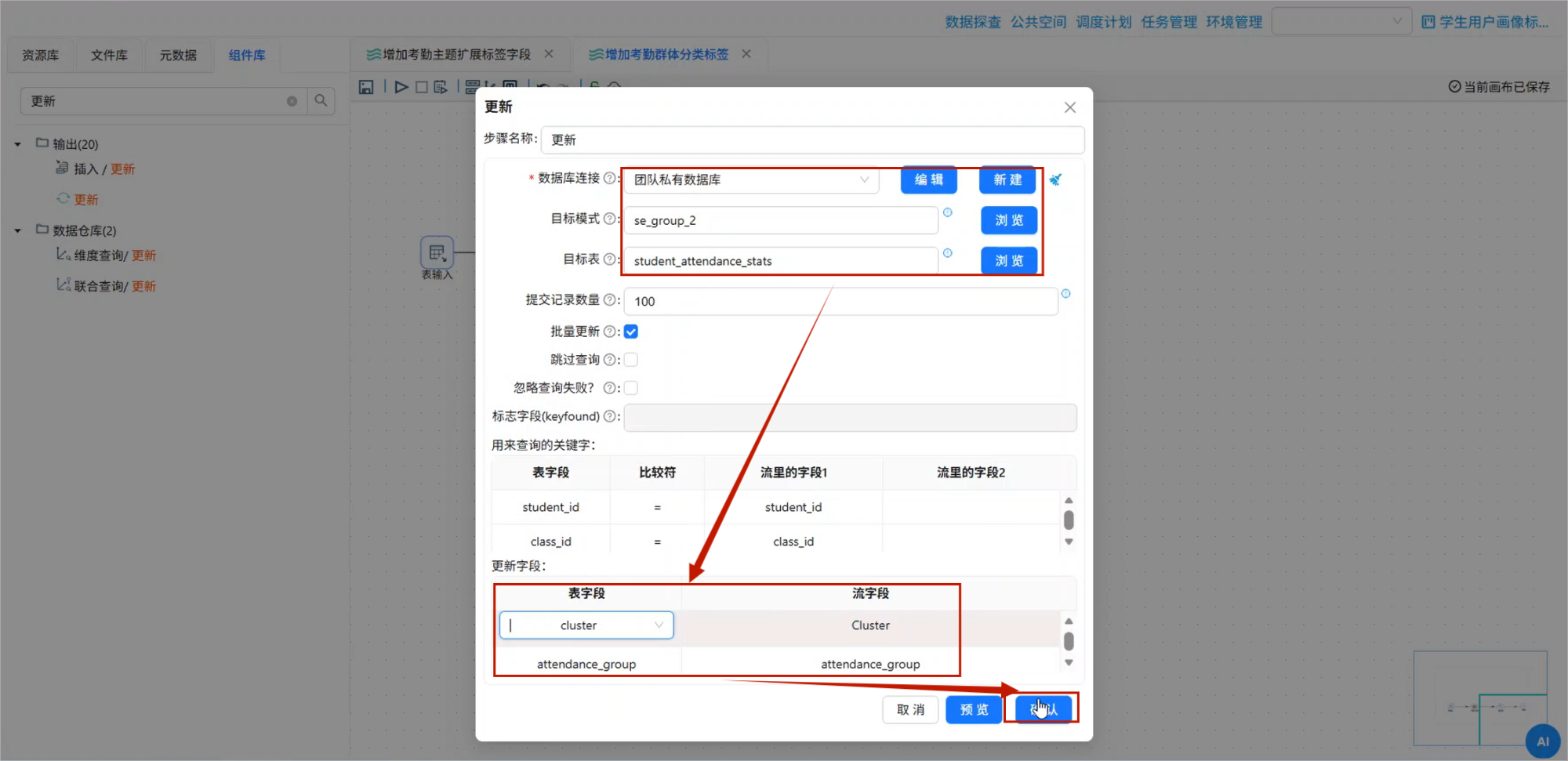
10.5 使用更新组件回写学生考勤主题标签表
最后一步是将聚类结果更新回 student_attendance_stats 表。
拖入:
更新将值映射组件连接到更新组件。
双击更新组件。
数据库连接选择:
团队私有数据库目标模式选择:
labs目标表选择:
student_attendance_stats在查询关键字表格中,保留:
student_id表示更新时根据学生 ID 匹配记录。
在更新字段中,需要将流字段映射到目标表字段:
| 流字段 | 目标表字段 |
|---|---|
| Cluster | cluster |
| attendance_group | attendance_group |
也就是说,当流里的 student_id 与目标表中的 student_id 相同时,就把对应学生的 Cluster 和 attendance_group 更新到原学生考勤主题标签表中。
配置完成后点击确认。
更新组件配置
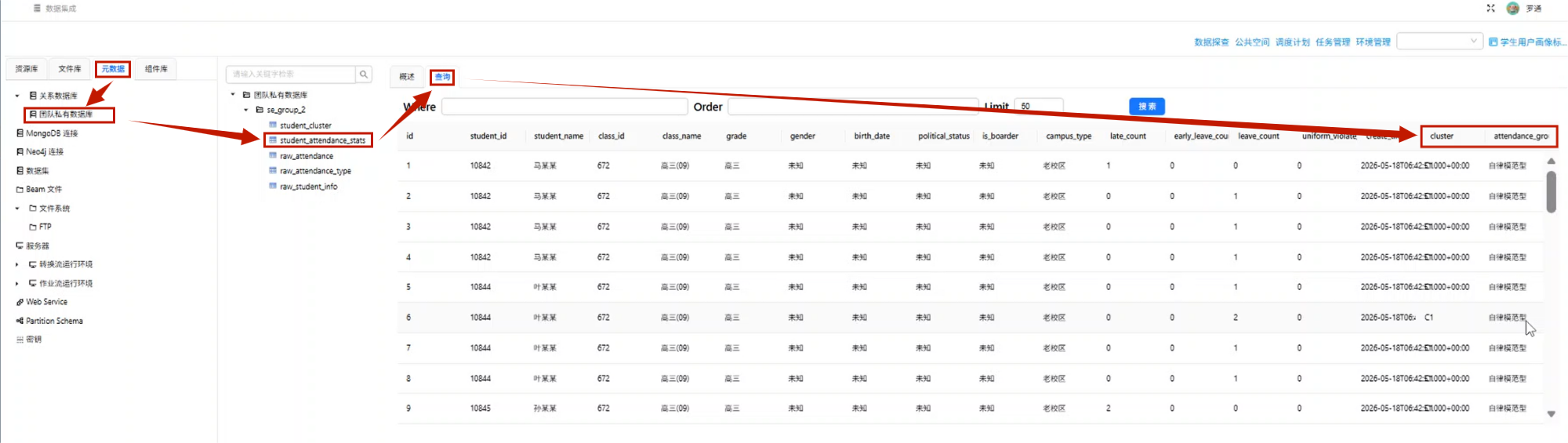
10.6 运行转换流并查看结果
点击运行按钮,执行“增加考勤群体分类标签”转换流。
如果日志中没有报错,说明回写成功。
接下来切换到 元数据 页面。
右键团队私有数据库,选择:
加载元数据然后进入数据探查,打开:
student_attendance_stats点击查询,可以看到表中已经新增了:
clusterattendance_group
并且这两个字段已经成功写入对应数据。
到这里,聚类结果就不再是单独的模型输出,而是正式成为学生考勤主题标签表中的扩展画像标签。
student_attendance_stats 回写结果
十一、实验完整流程复盘
本次实验从已有考勤统计标签表出发,完成了从建模到结果回写的完整闭环。
整体流程可以总结为:
- 准备学生考勤主题标签表
- 在 AI Studio 中加载数据库数据
- 保留迟到、早退、请假、校服违规等特征字段
- 使用 K-Means 进行学生考勤行为聚类
- 将聚类结果保存到
student_cluster表 - 在助睿 BI 中构建数据集
- 制作多组散点图分析聚类簇分布
- 搭建聚类分析仪表盘
- 将 C1、C2、C3 解释为具体考勤群体
- 在学生考勤主题标签表中新增扩展字段
- 使用 ETL 将聚类编号和群体分类回写结果表
- 查询验证最终结果
K-Means 聚类实验完整闭环图
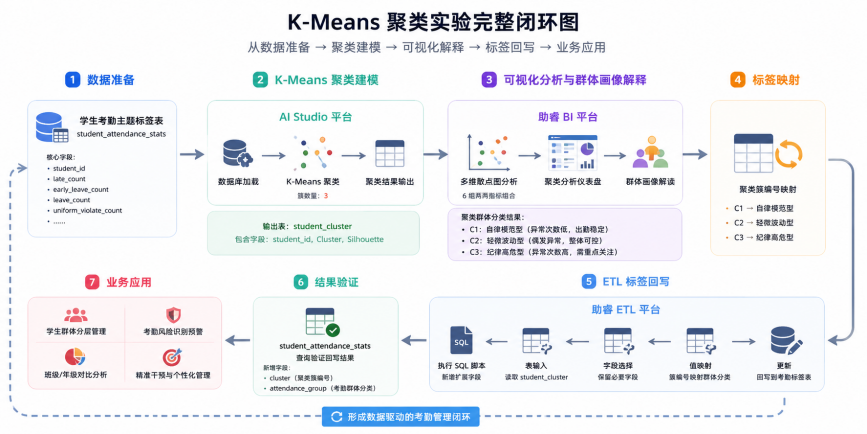
十二、实验结果与业务价值
通过本次实验,学生考勤行为被划分为三类群体:
| 群体分类 | 业务含义 |
|---|---|
| 自律模范型 | 出勤稳定,异常行为极少,可作为正面学生群体 |
| 轻微波动型 | 存在偶发考勤异常,适合日常提醒与持续观察 |
| 纪律高危型 | 存在高频或多维度异常考勤行为,需要重点关注和干预 |
相比单纯查看迟到次数、请假次数,聚类分析能够从多维度综合判断学生考勤行为模式。
对校园管理来说,这类结果可以用于:
- 班主任快速识别重点关注学生
- 辅导员进行考勤风险分层管理
- 学校按年级、班级、住校状态开展行为分析
- 后续结合成绩、消费、课程数据进一步构建综合学生画像
十三、实验总结
本次实验基于上一实验输出的学生考勤主题标签表,使用 K-Means 聚类算法对学生考勤行为进行自动分群,并借助助睿 BI 平台完成聚类簇的可视化解释,最终将聚类结果回写至原学生考勤主题标签表,形成了完整的考勤画像扩展标签。
从技术流程上看,本实验串联了 AI Studio 建模、BI 可视化分析、ETL 标签回写 三个环节,覆盖了数据分析项目中非常典型的“建模—解释—落地”流程。
从业务价值上看,本实验将原本单一的考勤次数统计进一步转化为可解释的学生群体画像,使学校能够更直观地识别自律稳定学生、轻微波动学生和纪律高危学生,为后续精细化管理、行为干预和个性化教育提供数据支撑。
对初学者来说,这个实验最大的价值在于:
它不只是演示了一个 K-Means 算法,而是完整展示了一个数据分析结果如何从模型输出变成可落地使用的业务标签。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)