别再学Java了?大模型时代下,2026技术岗校招的“新旧更替”名单
目录
一、现象:Offer 变少的方向,和突然多出来的岗位
二、本质变化:大模型不是在“帮忙写代码”,而是在“吃掉接口”
三、核心机制拆解:为什么 CRUD 和调参同时失效
四、典型案例对比:两个应届生,同一个夏天
五、工程落地启示:校招简历上该写什么,不该写什么
六、最后一个问题
上个月帮一家二线互联网公司做技术面试官,面了12个校招生。简历翻完,一个感觉非常强烈:大部分人还在用2022年的技能栈,去投2026年的岗位。
问Java八股文,背得滚瓜烂熟。问“你用过大模型API做什么测试或者辅助开发”,全场沉默。有一个同学说“我用GPT写过快排”,然后就没有然后了。
这不是个例。今年春招数据出来,Java后端岗位投递比去年多了18%,但HC只涨了3%。另一边,有个叫“LLM应用测试工程师”的新岗位,投递人数少得可怜,HR挂在网上两周才收到4份简历。
很多人已经开始感觉到不对劲了。但说不清到底是哪里变了。
一、现象:Offer 变少的方向,和突然多出来的岗位
先说几个硬事实。
传统Java后端开发岗,校招薪资涨幅几乎停滞。 头部厂今年给普通硕士的批发价,和2024年基本持平。而一些涉及大模型应用开发的岗位,起跳直接高了30%-50%。
测试岗的变化更剧烈。 过去校招最底层的“手工测试”岗,今年在很多公司直接取消了HC。取而代之的是“AI测试开发”或“大模型质量保障”。面试题从“说说等价类划分”变成了“如何自动化判断大模型回答是否准确”。
一个新职位列表正在成型,我把它整理成了一张表:
|
正在萎缩 / 门槛提高 |
正在新增 / 需求上升 |
|---|---|
|
纯CRUD后端开发 |
LLM应用开发工程师 |
|
手工功能测试 |
大模型评测 / 对齐工程师 |
|
传统数据清洗(写SQL) |
RAG系统开发 / 优化 |
|
简单运维(手动部署) |
AI Agent 开发 |
|
初级数据分析(Excel+SQL) |
提示词工程 / 调优 |
不是Java死了。是 “只会Java” 死了。不是测试没了,是 “只会手工点按钮” 的测试没了。
二、本质变化:大模型不是在“帮忙写代码”,而是在“吃掉接口”
很多人理解错了。他们觉得大模型就是个高级的代码补全工具,所以结论是“以后程序员效率更高,需要的人更少”。
这个说法对,但太浅了。
核心在于:大模型改变了软件系统的“接口形态”。
过去一个软件系统的功能边界,是由程序员写的代码逻辑定义的。你想让系统做什么,就得写一个函数、一个接口、一个页面。每个功能都需要人来实现。
现在,一个LLM API + 提示词,就能替代掉原本需要几十个if-else和大量正则的“规则引擎”。比如客服机器人、内容分类、实体抽取——这些过去需要专门的中小团队维护的业务逻辑,现在一行chat.completions就搞定了。
这意味着什么?意味着企业内部的 “业务胶水代码” 需求在大幅减少。
大量的内部管理系统、数据处理管道、报表生成脚本,正在被一个“会读文档、会写SQL、会发邮件”的Agent替代。而维护这个Agent,不需要一个20人的Java团队。只需要两三个人,加上一个LLM API key。
所以不是Java语言本身被淘汰,而是 围绕Java生态的大量“低复杂度业务开发岗” 正在消失。这些岗过去是校招生的主要入口。 与此同时,新岗位出现了。但它们要求的技能栈,学校基本不教。
三、核心机制拆解:为什么 CRUD 和调参同时失效
我们拿两个典型岗位具体拆。
岗位A:传统后端开发(Java Spring Boot + MySQL + Redis)
这个岗位的主要工作是什么?接收HTTP请求,校验参数,调数据库,算点逻辑,返回JSON。
大模型来了之后,发生了什么变化?
企业内部的知识库、文档、FAQ,原本需要专门开发一个搜索系统。现在直接用RAG:把文档切块、向量化,存到向量数据库,用户问问题的时候,检索相关片段,拼成提示词发给大模型,拿到答案。
整个链路里,后端代码的核心工作变成了:调向量库、拼提示词、调LLM API、返回结果。复杂的业务逻辑被“压缩”到了提示词和检索策略里。一个几百行的Python脚本就能跑起来。
不是说不再需要后端了。而是 后端的复杂度从“业务逻辑”转向了“管道工程” 。哪个学校还在教学生手写线程池、手写缓存一致性?有用,但不是校招筛选的重点了。
岗位B:软件测试工程师
传统测试的核心能力:设计测试用例、执行、报bug、回归。
大模型来了,第一个被冲击的就是“用例执行”。因为大模型输出不确定,你不能再用assert equals。你需要学会语义相似度、关键词抽取、正则范围判断、甚至用一个小模型来做答案质量打分。
更重要的是,你原来测的是“功能是否符合需求文档”。现在你测的是“模型是否可靠”——但模型的行为是个黑盒。你不得不去学概率、学采样、学对抗性提示词。
测试工程师的角色,从“质量门禁”变成了“质量观测+反馈闭环”。不会写代码、看不懂概率分布的测试,确实会越来越难。
为什么说“调参”也失效?
因为大模型时代的“调参”,不是调模型自己的参数,而是调提示词、调检索策略、调温度系数、调用例的断言阈值。这是全新的技能组合。学校里教的机器学习调参,跟这个完全是两回事。
四、典型案例对比:两个应届生,同一个夏天
说两个真实的故事。人物信息做了脱敏,但框架是真的。
小张,2025届,985硕,Java方向
刷了半年的LeetCode,背了Spring源码、JVM调优、并发编程。校招投了40家,拿到2个中小厂offer,总包28w。入职后做内部工单系统,每天写CRUD。三个月后带他的老员工离职,他一个人扛着,感觉“学不到新东西”。今年开始看大模型相关的课,但发现很难从零搭起来。
小李,2026届,普本,专业是信息管理
大二开始用Python,大三接触OpenAI API,做了个“论文摘要助手”的小工具放GitHub。不复杂,就几百行代码:读PDF,调API,输出摘要。但这个项目帮他拿到了字节的实习面试。面试官问的是:“你怎么处理API返回的不稳定格式?”他答:“我加了一层正则兜底,如果摘要格式不对就重试三次。”面试官当场说这个思路对了。
实习转正,做LLM应用测试开发。现在做的事情:写自动化测试脚本,用语义模型做断言,搭建持续评测流水线。总包35w+。
两个人的差别在哪儿?不是学校,不是智商。是 小张还在学“被大模型替代的东西”,小李已经开始学“怎么用大模型做东西”。
五、工程落地启示:校招简历上该写什么,不该写什么
如果说2026年的技术岗校招有一个“新旧更替”名单,它长这样:
旧名单(写了不加分,甚至可能扣分)
-
“熟悉Java集合类、多线程、JVM”
-
“熟练使用MySQL,能写复杂SQL”
-
“有手工测试经验,会使用Jira”
-
“熟悉Linux基本命令”
不是这些东西没用。是 所有科班生都会,拉不开差距。而且面试官心里清楚,这些技能大模型也能干个七七八八。
新名单(写上去,面试官会多看两眼)
-
“使用过至少一种大模型API(OpenAI/Claude/国产模型),完成过一个端到端的小应用”
-
“了解RAG基本流程:文档切块、向量化、检索、上下文组装”
-
“能用Python实现基于语义相似度的自动化断言”
-
“做过大模型输出的质量评测,哪怕只是用BLEU或GPT-4打分”
-
“阅读过某个大模型相关论文(如RAG、Self-consistency)并能复现核心思路”
注意,我不是说你必须放弃Java。我是说 你的简历上必须有大模型的痕迹。哪怕只是一个课设,哪怕只是调了两周的API。
下面是这张变化的底层逻辑图,你可以看清楚岗位能力的转移方向。
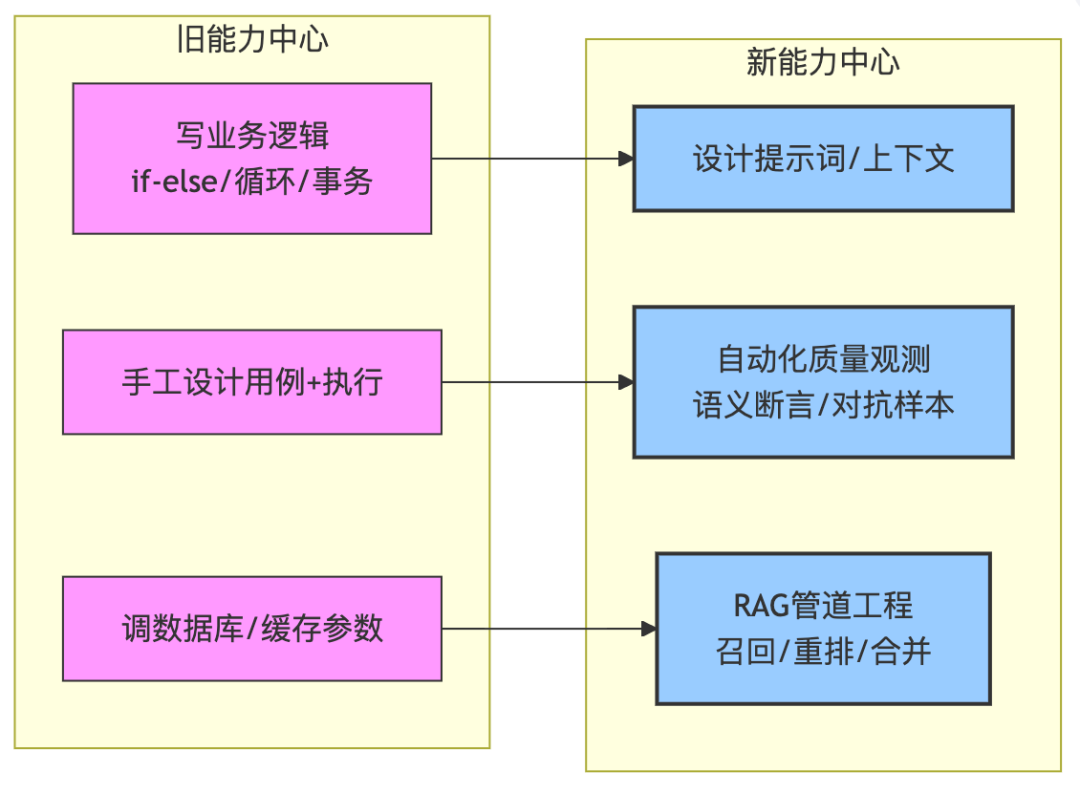
图里最核心的信息:不是能力被抛弃,是能力在迁移。写if-else的能力迁移到写提示词。手工点点的能力迁移到写自动化断言。调MySQL参数的能力迁移到调RAG检索参数。
能完成这种迁移的人,拿到新名单的入场券。不能的,会觉得“Java没落了”、“测试没前途了”。
六、最后一个问题
写这篇文章不是劝所有人立刻扔掉Java书去学提示词。而是想让你认真想一个问题:
你现在的技能栈里,有没有一个环节是“一旦大模型能力再往前走半步,就不再需要你”的?
如果有,而且你没有plan B,那2026年的这个校招季,你可能会比想象中更难。
反过来,哪怕你只是用大模型API写过一个自动整理会议纪要的小脚本,投简历的时候都会多一个故事可以讲。面试官不指望你懂模型原理,只想知道你有没有在“新范式”下动手解决问题的能力。
你上一个亲手跑通的、调过大模型API的项目,是什么时候的事?
本文部分内容参考了霍格沃兹测试开发学社整理的相关技术资料,主要涉及软件测试、自动化测试、测试开发及 AI 测试等内容,侧重测试实践、工具应用与工程经验整理。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 4
4 0
0- 0



 已为社区贡献69条内容
已为社区贡献69条内容

所有评论(0)