基于paddle框架的中文新闻文本标题分类
一、项目介绍
1.1 项目背景
面对海量新闻数据,自动化文本分类可大幅提升内容管理、舆情监控、个性化推荐的效率。本项目基于深度学习实现端到端中文新闻标题分类系统。
1.2 项目亮点
- 基于 PaddlePaddle 实现,模块化架构
- 采用 TextRNN(BiLSTM) 捕捉长距离语义
- 字粒度编码,降低未登录词影响
- 引入 Dropout、早停、权重衰减 防止过拟合
- 支持 10 类新闻分类
- 提供 混淆矩阵、分类指标可视化
- 配套 Tkinter 图形化预测界面
- 测试集准确率:90.59%
1.3模型选择及原理
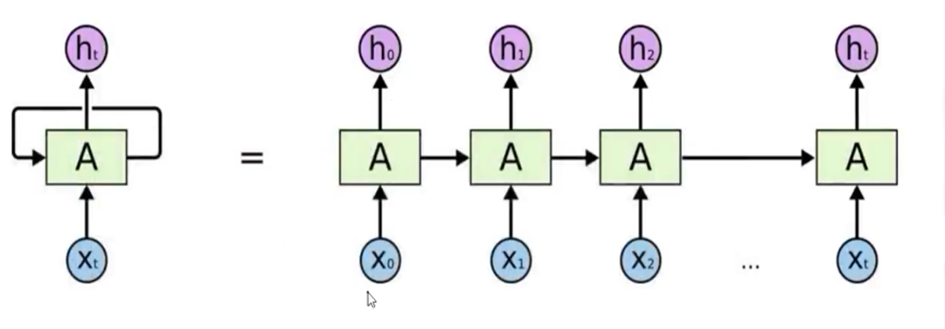
考虑到新闻标题长度短、语义紧凑,RNN 能逐词建模上下文关系,比 CNN 更擅长捕捉整体语义。标题中常出现跨字词的逻辑关联(如 “央行 — 降息 — 股市”),LSTM 可有效建模这类依赖。中文无天然空格分隔,字粒度输入下,RNN 能更好地学习字符级序列规律,降低未登录词影响。训练稳定、泛化性好 在新闻分类这类任务中,BiLSTM 结构简单高效,不易过拟合,最终在测试集上达到 90.59% 的准确率,综合表现优于 TextCNN 等模型。最终选择RNN模型。
循环神经网络(RNN)会按顺序逐字 / 逐词读取文本,每一步都会保留之前的信息,形成记忆状态,从而捕捉文本的时序依赖。 针对传统 RNN 容易出现的梯度消失 / 爆炸问题,本项目使用LSTM(长短期记忆网络)结构,通过门控机制(遗忘门、输入门、输出门)有效控制信息的保留与丢弃,能够稳定学习更长距离的语义关联。 同时我们采用双向 LSTM(BiLSTM),同时从正向和反向读取文本,既能理解前文对后文的影响,也能利用后文反推前文含义,让标题语义表示更完整。
1.4分类类别
plaintext
财经、房产、股票、教育、科技、社会、政治、体育、游戏、娱乐
二、环境配置
plaintext
python >= 3.7
paddlepaddle >= 2.3
numpy
matplotlib
seaborn
scikit-learn
tqdm
tkinter
三、项目结构
plaintext
THUCNews/
├─ data/ 数据集、词汇表、词向量
├─ saved_dict/ 模型权重保存
├─ models/ 模型定义
│ └─ TextRNN.py
├─ utils.py 数据预处理工具
├─ train_eval.py 训练、评估、测试逻辑
├─ run.py 项目主入口
└─ ui.py 图形化预测界面
四、数据预处理(utils.py)
核心功能
- 构建词汇表(字粒度 / 词粒度)
- 文本转索引序列
- 序列填充 / 截断
- 数据集迭代器封装
- 预训练词向量处理
代码框架
python
# 构建词汇表
def build_vocab(...):
pass
# 构建训练/验证/测试数据集
def build_dataset(...):
pass
# 数据集迭代器
class DatasetIterater(object):
pass
# 构建迭代器
def build_iterator(...):
pass
# 时间计算工具
def get_time_dif(...):
pass
五、模型配置与结构(models/TextRNN.py)
模型结构
- Embedding 层(支持预训练词向量)
- 双层双向 LSTM
- Dropout 正则化
- 最大池化 + 全连接分类
代码框架
python
class Config(object):
"""模型超参数、路径、训练配置"""
def __init__(self, dataset, embedding):
# 数据集路径
# 类别、词表、模型保存路径
# 训练超参:学习率、batch、epoch、pad_size
# 模型结构:hidden_size、layer数、dropout
class Model(nn.Module):
def __init__(self, config):
# 嵌入层
# 双向LSTM
# Dropout
# 全连接层
def forward(self, x):
# 前向传播
pass
六、模型训练与评估(train_eval.py)
训练策略
- 损失函数:CrossEntropyLoss
- 优化器:Adam
- 学习率衰减
- 早停机制
- 最优模型自动保存
代码框架
python
# 权重初始化
def init_network(model):
pass
# 训练主循环
def train(config, model, train_iter, dev_iter, test_iter, writer):
pass
# 模型评估
def evaluate(config, model, data_iter, test=False):
pass
# 测试集评估
def test(config, model, test_iter):
pass
七、项目主入口(run.py)
功能
- 解析参数
- 加载数据集
- 初始化模型
- 启动训练
- 日志记录
代码框架
python
if __name__ == '__main__':
# 加载数据集
# 构建迭代器
# 初始化模型
# 启动训练
# 保存最优模型八、模型测试结果
plaintext
precision recall f1-score support
finance 0.8918 0.9070 0.8994 1000
realty 0.9112 0.9240 0.9176 1000
stocks 0.8737 0.8098 0.8401 1000
education 0.9453 0.9500 0.9476 1000
science 0.8284 0.8590 0.8434 1000
society 0.8976 0.9200 0.9086 1000
politics 0.8967 0.8680 0.8821 1000
sports 0.9710 0.9898 0.9715 1000
game 0.9074 0.9720 0.9228 1000
entertainment 0.9371 0.9410 0.9239 1000
accuracy 0.9059 10000
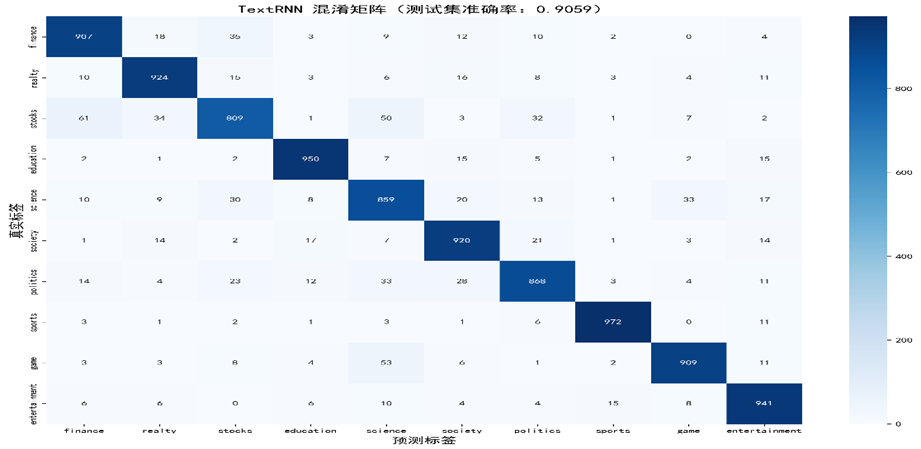
九、混淆矩阵可视化
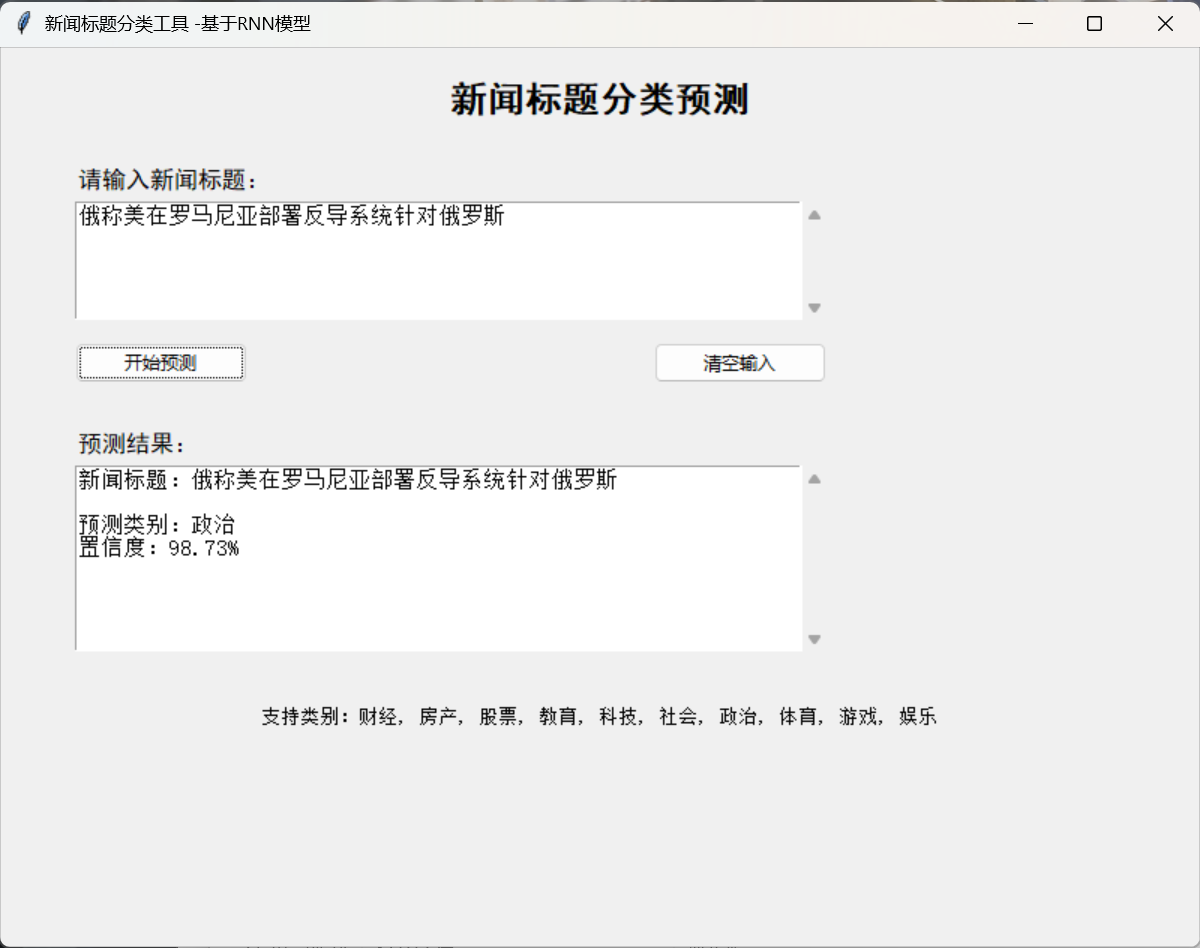
十、图形化预测界面(ui.py)
功能
- 新闻标题输入
- 一键预测
- 中文类别显示
- 置信度输出
- 清空 / 重置
代码框架
python
class NewsClassifierUI:
def __init__(self, root):
# 加载模型与词汇表
# 英文→中文类别映射
# 构建UI布局
def load_model_and_vocab(self):
# 加载模型权重
pass
def text_to_idx(self, text):
# 文本转索引
pass
def predict_news(self, text):
# 预测类别
pass
def build_ui(self):
# 界面布局:输入框、按钮、结果框
pass
if __name__ == "__main__":
root = tk.Tk()
app = NewsClassifierUI(root)
root.mainloop()
十一、UI 界面展示
十二、运行步骤
- 准备 THUCNews 数据集并放入指定目录
- 生成词汇表
- 运行
run.py训练模型 - 运行
ui.py启动图形化预测工具 - 输入新闻标题,一键查看分类结果
十三、总结
本项目基于 PaddlePaddle 实现了一套完整、可直接运行的中文新闻标题分类系统,采用 TextRNN 模型,测试准确率达 90.59%,并配套可视化与交互界面,非常适合深度学习课程设计与 NLP 入门学习。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 23
23 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)