消费级显存也能玩 FLUX.1!ComfyUI 部署 GGUF 量化版完整教程(附模型下载)
导读:本文阅读5分钟,等不及的:
去年 8 月,一个叫 Black Forest Labs 的团队发布了 FLUX.1 这个文生图模型,消息一出来,AI 绘图圈子里的讨论就没停过。很多人第一反应是:Stable Diffusion 的原班人马出来做的东西,肯定有点东西。
事实确实如此。但它的硬件要求也让不少人望而却步——完整版跑起来需要 24GB 显存,对大多数普通用户来说根本不现实。后来社区里的开发者把它做成了 GGUF 量化版本,6GB 显存也能用。这篇文章就说说怎么在 ComfyUI 上把这套东西跑起来。
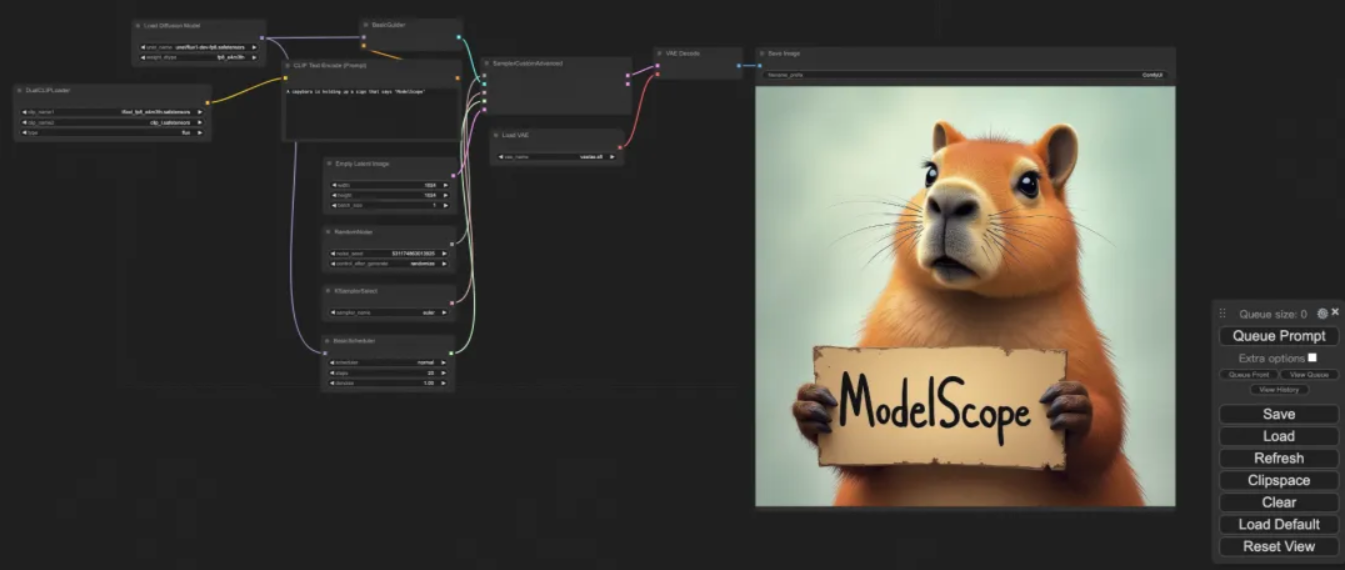
FLUX.1 是什么
FLUX.1 是由 Black Forest Labs 开发的文本生成图像模型。这个团队的核心人物 Robin Rombach,之前在 Stability AI 做首席科学家,Stable Diffusion 系列就是他们那帮人搞出来的。
模型本身有 120 亿参数,用的是混合架构——把多模态 Transformer 块和扩散模型结合在一起。说人话就是:它既能理解你写的文字,又能把这些文字转化成图像,而且两块配合得比以前的方案更好。
官方发布的版本有三个:
- FLUX.1 [pro]:闭源商业版,通过 API 调用,质量最高
- FLUX.1 [dev]:开放权重,非商业用途,效果接近 pro 版
- FLUX.1 [schnell]:开源可商用(Apache 2.0),生成速度比 dev 快约 10 倍,质量稍低一点
普通用户能在本地跑的,主要是 dev 和 schnell 这两个。
它有什么特点
提示词理解准确
这是 FLUX.1 被讨论最多的一点。很多人反映,给它一段比较复杂的描述,它能按要求把各种元素放在正确位置上。比如"左边站一个穿黑色长袍的人,右边站一个穿红色的,中间的桌子是黄色的"——这类多物体、有位置关系的描述,它处理起来比之前的模型稳定很多。
有人专门测试了 FLUX.1 和 SD3 Medium、Auraflow 在复杂提示词下的表现,结论是 FLUX.1 是三者里最符合要求的,把所有元素都摆在了指定位置。
图像里能写字
AI 生成的图像里放文字,一直是个老大难问题,很多模型生成出来的字母要么变形要么乱码。FLUX.1 在这方面改善明显,能处理重复字母、单词拼写这类容易混淆的情况。虽然不是每次都完美,但比以前的方案强不少。
手和身体结构
早期的扩散模型画手的问题是出了名的——六根手指、手指粘连、角度扭曲。FLUX.1 在这方面有改进,各种姿势下的手部渲染相对准确,虽然偶尔还是会出问题,但出问题的概率低了很多。
支持多种比例和分辨率
从 10 万像素到 200 万像素的各种长宽比都支持。不少 AI 工具只能生成正方形图像,FLUX.1 没有这个限制,竖图横图都可以。
开源且本地可跑
dev 和 schnell 版本都能下载到本地跑,不需要联网,也不需要付费订阅。对于不想把图像上传到云端、或者需要批量出图的用户来说,这是一个实际的优点。
跑 FLUX.1 需要什么硬件
这里先说清楚一件事:FLUX.1 的原始模型对硬件要求确实高,但 GGUF 量化版本把门槛降低了不少。
FP8 压缩版
- 显存:12~16GB(RTX 3080/4070 级别)
- 内存:16GB 以上
- 存储:约 17GB
GGUF 量化版(本文重点)
这是对显存要求最低的版本,由社区开发者 city96 制作,从 2 位到 8 位都有:
| 量化精度 | 最低显存要求 | 文件大小(约) | 画质损失 |
|---|---|---|---|
| Q2 | 6GB | 约 3.5GB | 明显 |
| Q4 | 6~8GB | 约 6.5GB | 轻微 |
| Q5 | 8GB | 约 8GB | 很轻微 |
| Q6 | 10GB | 约 10GB | 极轻微 |
| Q8 | 12GB | 约 13GB | 几乎没有 |
有人实测 6GB 显存跑 Q4 版本,出图速度比较慢,一张 512×512 的图大概需要几分钟,但能出图。如果有 8GB 显存,Q5 是比较均衡的选择。
对于大多数使用 RTX 3060(12GB)或 RTX 4060(8GB)的用户,GGUF 版本是跑 FLUX.1 的可行路径。
FLUX.1 与其他模型的横向对比
下面这张表对比了目前几个主流文生图模型/工具的主要属性:
| 对比维度 | FLUX.1 [dev] | Stable Diffusion 3 | Midjourney v6 | DALL·E 3 |
|---|---|---|---|---|
| 开源/闭源 | 开放权重(非商用) | 开放权重(可商用) | 闭源 | 闭源 |
| 本地部署 | 支持 | 支持 | 不支持(仅网页/Discord) | 不支持(仅API/ChatGPT) |
| 参数规模 | 120亿 | 20亿 | 未公开 | 未公开 |
| 最低显存(量化后) | 6GB(GGUF Q4) | 6GB | 不适用 | 不适用 |
| 提示词理解 | 强 | 中等 | 强 | 强 |
| 图像写字能力 | 较好 | 一般 | 中等 | 中等 |
| 手部/解剖结构 | 较好 | 一般 | 较好 | 一般 |
| 生成速度 | 中等(dev版较慢) | 中等 | 较快(云端) | 快(云端) |
| 使用费用 | 免费(本地) | 免费(本地) | 订阅制(约$10/月起) | 按量付费或ChatGPT订阅 |
| 多比例支持 | 支持 | 支持 | 支持 | 支持 |
| LoRA/扩展支持 | 逐渐完善 | 成熟丰富 | 不支持自定义 | 不支持自定义 |
| 商业使用 | dev版不可商用 | 部分版本可商用 | 有订阅计划支持商用 | 有商用协议 |
从社区里的讨论来看,Black Forest Labs 官方发布的基准测试数据显示,FLUX.1 [dev] 在视觉质量、提示跟随度、输出多样性等维度上超过了 Midjourney v6.0、DALL·E 3 (HD) 和 SD3 Ultra。不过基准测试是官方自测,实际用起来的感受因人而异。
有人拿同一批提示词分别跑了 FLUX.1 和 Midjourney,结果是:构图复杂的场景 FLUX.1 更听话,人物皮肤质感 Midjourney 稍好一些,整体差距没有宣传里说的那么大,但 FLUX.1 免费这点确实让人没法忽视。

安装前的准备
系统要求:
- 操作系统:Windows 10/11(64位)
- Python:3.10 或以上
- NVIDIA 显卡:支持 CUDA,显存 6GB 以上
- 内存:16GB 以上(推荐 32GB)
- 硬盘空间:至少 20GB 可用空间
需要下载的文件(提前备好):
- ComfyUI 整合包(包含 Python 环境,省去配置麻烦)
- ComfyUI-GGUF 插件
- FLUX.1 GGUF 主模型文件(根据显存选对应版本)
- T5-XXL 文本编码器(GGUF 版)
- CLIP-L 模型
- VAE 模型(ae.safetensors)
安装包已整理好,下载地址:百度网盘(提取码:lijj)
详细安装步骤
第一步:安装 ComfyUI
下载 ComfyUI Windows 整合包,解压到一个路径里不含中文和空格的文件夹,比如 D:\ComfyUI。
解压完成后,运行根目录下的 run_nvidia_gpu.bat,如果出现一个黑色命令行窗口并最终显示 Prompt Server started,说明 ComfyUI 启动成功。打开浏览器访问 http://127.0.0.1:8188,能看到 ComfyUI 界面就算完成这一步。
第二步:安装 ComfyUI-GGUF 插件
FLUX.1 的 GGUF 版本需要一个专用插件才能在 ComfyUI 里加载。有两种安装方法:
方法 A:通过 ComfyUI Manager 安装(推荐)
打开 ComfyUI 界面,右上角点击 Manager,进入后选择 Custom Nodes Manager,在搜索框输入 GGUF,找到 ComfyUI-GGUF 后点击 Install,等待安装完成后重启 ComfyUI。
如果 Manager 里下载速度很慢或者失败,用方法 B。
方法 B:手动安装
打开 ComfyUI\custom_nodes 文件夹,在地址栏输入 cmd 回车,打开命令行后输入:
git clone https://github.com/city96/ComfyUI-GGUF.git
等下载完成后重启 ComfyUI。
如果没法用 git,也可以直接下载 zip 压缩包,解压到 ComfyUI\custom_nodes 目录下即可。
第三步:下载并放置模型文件
这是整个安装过程中文件最多的一步,需要下载四个文件,分别放到不同目录。
① FLUX.1 GGUF 主模型
根据自己的显存选版本:
- 6GB 显存 → 选 Q4 版本
- 8GB 显存 → 选 Q5 版本
- 12GB 显存 → 选 Q8 版本
下载好的 .gguf 文件放到:ComfyUI\models\unet\
② T5-XXL 文本编码器(GGUF 版)
这个文件影响模型理解文字描述的能力,建议选 Q5_K_M 或更大的版本以获得较好效果。
下载好的文件放到:ComfyUI\models\clip\
③ CLIP-L 模型
文件名为 clip_l.safetensors,大小约 246MB。
放到:ComfyUI\models\clip\
④ VAE 模型
文件名为 ae.safetensors,大小约 335MB,由 Black Forest Labs 官方提供。
放到:ComfyUI\models\vae\,为了便于识别,可以把文件名改成 flux_ae.safetensors。
以上四个文件全部的整合包可以在上面提供的百度网盘地址里一次性下载。
第四步:搭建工作流
重启 ComfyUI 后,进入界面。默认的简易加载器不支持 GGUF 格式,需要手动添加节点。
添加 UNet 加载器(GGUF)
在空白区域双击,弹出搜索框,输入 unet,选择 Unet Loader (GGUF),把主模型文件选上。
添加 CLIP 加载器(GGUF)
再次双击空白处,输入 clip,选择 CLIP Loader (GGUF),加载 T5-XXL 和 CLIP-L 两个文件,Type 设置为 flux。
添加 VAE 加载器
同样双击空白,添加 VAE 加载器,选择之前下载的 flux_ae.safetensors。
连接节点
把 UNet、CLIP、VAE 加载器的输出分别连接到采样器节点对应的输入端口。注意:FLUX.1 不支持负向提示词,但节点结构上还是要连上两个 CLIP Text Encode(Prompt)节点,否则会报错。
这个工作流的连线方式和标准的 Stable Diffusion 工作流有些不同,如果直接套用旧工作流会出现红色报错。建议从模型网站上找现成的 FLUX.1 GGUF 工作流 JSON 文件导入,省去手动连线的麻烦。
第五步:测试出图
工作流搭好后,在提示词框里输入描述,点击右下角的 Queue Prompt 按钮开始生成。
第一次运行时,模型加载需要一段时间,这是正常现象。生成过程中,每个节点变绿表示该步骤正在执行,全部变绿后图片就生成完成了,保存在 ComfyUI\output\ 目录下。
几个注意事项:
- 写提示词时尽量具体一点,FLUX.1 的提示词跟随度比较高,描述得越详细,结果越接近预期
- 不需要写负向提示词(即便写了也不会生效)
- 如果显存不足导致生成失败,可以把分辨率调低,或者换更低位数的 GGUF 版本
- 出图期间尽量关掉其他占用显存的程序
常见问题
Q:启动后提示找不到模型文件?
检查文件是否放在了正确的目录下,路径里不要有中文字符。
Q:节点显示红色报错?
GGUF 版本的节点和标准节点不通用,确认 UNet 和 CLIP 加载器选的是带"GGUF"字样的节点版本。
Q:生成速度很慢?
FLUX.1 本身就比 SD1.5 慢,低显存设备上更明显。可以把图片尺寸设小一点(512×512)先测试,确认工作流没问题后再提高分辨率。
Q:Q4 和 Q8 版本出来的图差别大吗?
在一般场景下差别不是很明显,但细节丰富的图(比如复杂背景、密集文字)会有一定差距。如果显存允许,优先选更高位数的版本。
整个安装流程下来,对于没接触过 ComfyUI 的人来说,最费时间的部分是下载模型文件,以及第一次搭工作流的时候。跑起来之后,换提示词出图就比较顺畅了。GGUF 版本虽然画质比完整版略有损失,但对于日常使用来说,这个损失在多数场景下感知不明显。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)