一万五千字解析编码器预训练模型
编码器预训练学习笔记
一、编码器预训练是什么
编码器预训练是 Transformer 进一步发展的重要方向之一。它的核心思想是:先用大规模无标注文本训练一个通用的文本理解模型,再把这个模型迁移到分类、匹配、问答、命名实体识别、检索等下游任务中。
这里的“编码器”主要指 Transformer Encoder。它不负责逐词生成下一段文本,而是负责把输入序列中的每个 token 编码成上下文相关表示。
重点:编码器预训练的本质
编码器预训练不是让模型直接生成长文本,而是让模型学会“理解输入文本”。训练完成后,每个 token 的表示都融合了上下文信息,句子级表示也可以用于分类、匹配和推理任务。
二、为什么需要编码器预训练
传统词向量模型通常给同一个词固定一个向量。例如 apple 在 “I ate an apple.” 和 “Apple pencil is expensive.” 中含义不同,但静态词向量难以表达这种上下文差异。
编码器预训练要解决的问题是:同一个 token 在不同语境下应该有不同表示。
因此,BERT(Bidirectional Encoder Representations from Transformers)这类模型会通过双向 Transformer Encoder 同时利用左侧和右侧上下文,为每个 token 生成动态表示。
以句子为例:
The bank is situated on the ___ of the river.
如果只看左侧上下文,bank 可能被理解为“银行”。如果同时看到右侧的 river,模型更容易判断 bank 和河岸语境相关。
2.1 单向编码与双向编码
理解 BERT 前,需要先区分单向编码和双向编码。
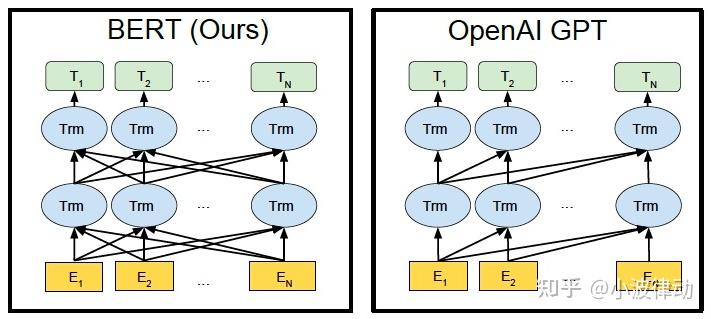
| 对比项 | 单向编码 | 双向编码 |
|---|---|---|
| 可见上下文 | 通常只能看到左侧历史 token | 同时看到左侧和右侧 token |
| 代表模型 | GPT 类自回归模型 | BERT 类 Encoder 模型 |
| 训练目标 | 预测下一个 token | 预测被遮蔽 token 或判断 token 是否被替换 |
| 适合任务 | 文本生成、续写、对话生成 | 文本理解、分类、匹配、抽取 |
| 核心限制 | 无法在当前位置直接使用右侧上下文 | 不天然适合从左到右生成文本 |
例如句子“今天天气很好,我们决定去公园散步。”中,如果编码“决定”这个词,单向模型主要依赖“今天、天气、很好、我们”等前文信息;双向模型还能同时使用“去公园散步”等后文信息,因此更适合理解整句语义。
三、从词向量、ELMo 到 BERT
编码器预训练的出现可以放在上下文表示的发展脉络中理解。
| 模型 | 架构倾向 | 上下文方向 | 使用方式 | 核心特点 |
|---|---|---|---|---|
| Word2Vec、GloVe | 浅层词向量 | 无上下文动态变化 | 作为固定词向量 | 同一个词通常对应同一个向量 |
| ELMo(Embeddings from Language Models) | RNN 或 LSTM | 左右方向拼接 | 特征抽取 | 能产生上下文相关词向量,但常作为额外特征使用 |
| GPT(Generative Pre-trained Transformer) | Transformer Decoder | 单向上下文 | 微调 | 更适合自回归生成 |
| BERT | Transformer Encoder | 深层双向上下文 | 微调 | 更适合理解类任务 |
3.1 Word2Vec:从稀疏编号到静态词向量
Word2Vec 的核心目标是把离散词语映射成低维稠密向量。传统 one-hot 编码只表示“这是词表中的第几个词”,向量维度很高,而且不同词之间默认彼此正交,难以表达“北京”和“中国”、“伦敦”和“英国”这类语义关系。
Word2Vec 使用浅层神经网络学习词向量,常见训练方式有两种:
| 训练方式 | 输入 | 预测目标 | 直观理解 |
|---|---|---|---|
| CBOW(Continuous Bag of Words) | 上下文词 | 中心词 | 根据周围词猜中间词 |
| Skip-Gram | 中心词 | 上下文词 | 根据一个词猜周围可能出现的词 |
例如句子“我 喜欢 自然 语言 处理”中,如果把“自然”作为中心词,CBOW 会根据“我、喜欢、语言、处理”等上下文预测“自然”;Skip-Gram 则会根据“自然”预测它附近可能出现“喜欢、语言”等词。
为了避免在大词表上直接计算完整 softmax 带来的高成本,Word2Vec 常配合负采样或层次 softmax 加速训练。训练完成后,真正被使用的通常不是预测网络本身,而是中间学到的词向量矩阵。
Word2Vec 的重要意义在于:词不再只是离散编号,而是变成可以计算相似度和语义关系的向量。它的局限也很明显:同一个词通常只有一个固定向量,因此无法区分 apple 在“吃苹果”和“Apple 公司”中的不同含义。
3.2 GloVe:用全局共现统计学习静态词向量
GloVe(Global Vectors for Word Representation)同样属于静态词向量方法,但它更强调全局语料统计。Word2Vec 主要从局部上下文窗口中构造预测任务,GloVe 则先统计整个语料中的词与词共现次数,再从共现矩阵中学习词向量。
GloVe 的基本思路是:如果两个词经常在相似上下文中出现,它们的向量应当接近;如果两个词与其他词的共现比例呈现稳定差异,这种比例关系也应反映在向量空间中。
常见表达形式可以概括为:
w i T w ~ j + b i + b ~ j ≈ log X i j w_i^T \tilde{w}_j + b_i + \tilde{b}_j \approx \log X_{ij} wiTw~j+bi+b~j≈logXij
其中,Xij 表示词 i 和上下文词 j 的共现次数,wi 和 (\tilde{w}_j) 分别表示目标词向量和上下文词向量,bi 与 (\tilde{b}_j) 是偏置项。公式含义是:两个词向量的内积应当能够拟合它们在全局语料中的共现强度。
GloVe 相比 Word2Vec 的重点差异在于:
| 对比项 | Word2Vec | GloVe |
|---|---|---|
| 主要信息来源 | 局部上下文窗口 | 全局词词共现矩阵 |
| 训练目标 | 根据上下文预测词或根据词预测上下文 | 拟合词与词共现次数的对数 |
| 代表特点 | 预测式学习词向量 | 统计式矩阵分解思想更明显 |
| 共同局限 | 同一个词通常只有固定向量 | 同一个词通常只有固定向量 |
GloVe 的重要意义在于:它把全局语料统计直接编码进词向量训练目标中。但它仍然不能根据上下文动态改变词义表示。
3.3 ELMo:从静态词向量走向上下文词向量
ELMo(Embeddings from Language Models)开始解决静态词向量的核心问题:同一个词在不同上下文中应当有不同表示。
ELMo 使用双向语言模型,通常可以理解为两条 LSTM(Long Short-Term Memory)语言模型路径:
- 正向语言模型从左到右读取句子,根据左侧上下文预测后续词。
- 反向语言模型从右到左读取句子,根据右侧上下文预测前面词。
- 最终表示由不同层的隐藏状态加权组合得到。
例如 bank 在 “open a bank account” 中更接近“银行”,在 “on the bank of the river” 中更接近“河岸”。Word2Vec 和 GloVe 会给 bank 一个固定向量,ELMo 则会根据上下文生成不同的 bank 表示。
重点:ELMo 的位置
ELMo 是从静态词向量到预训练语言模型的重要过渡:它已经能产生上下文相关表示,但通常作为下游模型的额外输入特征,而不是像 BERT 那样把整个深层编码器作为统一骨干进行微调。
3.4 token、词向量与上下文表示的关系
理解 BERT 前,需要区分三个容易混淆的概念:token、Token Embedding 和 token 输出表示。
| 概念 | 生成方式 | 是否依赖上下文 | 作用 |
|---|---|---|---|
| token | 原始文本经过分词器切分得到 | 否 | 作为模型处理文本的基本单位 |
| Token Embedding | token id 到词向量表中查表得到 | 否 | 提供每个 token 的初始语义表示 |
| token 输出表示 | Token Embedding 经过多层 Transformer Encoder 后得到 | 是 | 用于分类、标注、问答、匹配等下游任务 |
token 不是天然存在于文本中的单位,而是分词器加工后的结果。例如英文单词、中文字符、中文词、子词片段都可能成为 token。BERT 常用 WordPiece 分词,它会把文本切成词表中存在的片段。
例如:
playing football
可能被切成:
play ##ing football
这里的 play、##ing、football 都是 token。每个 token 会被映射成词表中的整数编号,也就是 token id。模型再用 token id 到 Token Embedding 矩阵中查表,得到初始向量。
Token Embedding 只是进入 Encoder 前的初始向量,真正用于任务的通常是经过上下文交互后的 token 输出表示。
以 bank 为例:
| 句子 | 初始 Token Embedding | 最终 token 输出表示 |
|---|---|---|
| open a bank account | bank 的初始查表向量相同 | 融合 open、account 等上下文,更偏“银行” |
| on the bank of the river | bank 的初始查表向量相同 | 融合 river、of 等上下文,更偏“河岸” |
这也是 Word2Vec 和 BERT 的关键区别:
| 对比项 | Word2Vec | BERT |
|---|---|---|
| 初始向量来源 | 词向量表查表 | Token Embedding 查表 |
| 上下文作用 | 主要在训练阶段更新词向量参数 | 训练和实际编码时都会参与表示计算 |
| 最终使用的表示 | 固定词向量本身 | 多层 Encoder 输出的上下文表示 |
| 同一个词的最终向量 | 通常固定不变 | 会随上下文变化 |
因此,Word2Vec 的“词向量”更像词表中的固定参数;BERT 的“token 输出表示”则是结合当前句子重新计算出来的动态结果。
3.5 这条发展线如何过渡到 BERT
从 Word2Vec、GloVe 到 ELMo,再到 BERT,可以看到表示学习的重点逐步变化:
| 阶段 | 代表方法 | 解决的问题 | 仍然存在的问题 |
|---|---|---|---|
| 静态词向量 | Word2Vec、GloVe | 让词具备稠密语义向量 | 不能根据上下文改变词义 |
| 上下文词向量 | ELMo | 让同一个词在不同语境中有不同表示 | 常作为外部特征接入,模型骨干仍分散 |
| 深层预训练编码器 | BERT | 用 Transformer Encoder 统一学习深层双向表示 | 需要针对预训练任务和微调任务设计输入格式 |
BERT 的关键变化是把 Transformer Encoder 做成可迁移的通用文本理解骨干。它不只是提供词向量,而是把输入表示、上下文建模、预训练任务和下游微调整合成一个统一框架。
四、BERT 的整体结构
BERT 只使用 Transformer Encoder。输入序列经过多层自注意力和前馈网络后,输出每个位置的上下文表示。

4.1 三层结构
从工程结构看,BERT 可以拆成三层:
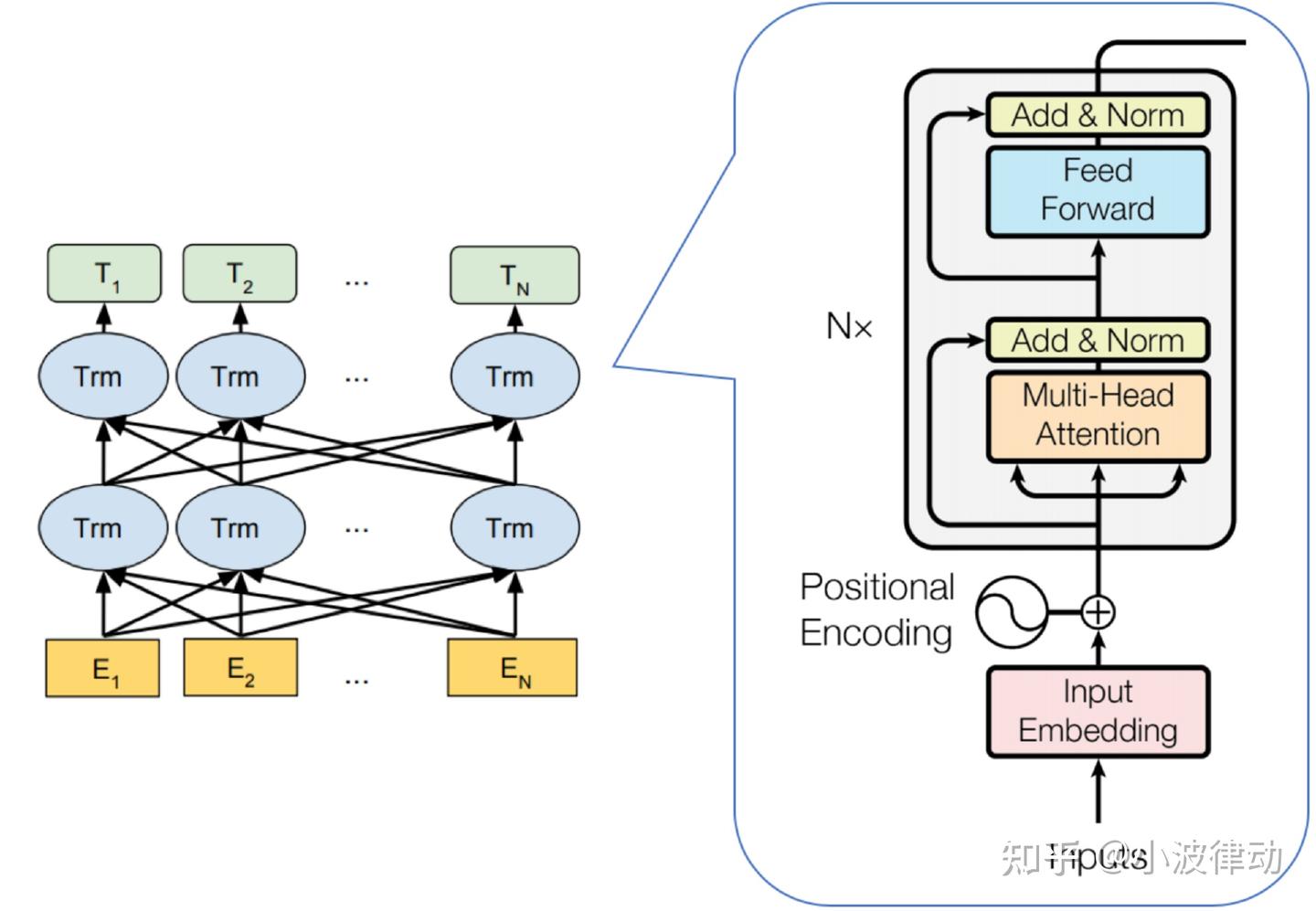
| 层次 | 作用 | 对应含义 |
|---|---|---|
| Embedding 模块 | 把离散 token 转成连续向量 | 负责构造模型输入 |
| Transformer Encoder 模块 | 多层自注意力与前馈网络堆叠 | 负责融合上下文信息 |
| 任务头模块 | 根据任务输出分类、位置或标签 | 负责预训练或微调预测 |
每个 Encoder Block 通常包含多头自注意力、前馈神经网络、残差连接和层归一化。BERT 的“深层双向”主要来自多层 Encoder Block 的堆叠:底层更偏局部词法和短语信息,高层更偏句义、句间关系和任务相关表示。
4.2 输入格式
单句输入:
[CLS] 句子 token [SEP]
句子对输入:
[CLS] 句子 A token [SEP] 句子 B token [SEP]
其中:
[CLS]用于汇聚整个序列的信息,常用于分类任务。[SEP]用于分隔句子或标记句子结束。- token 输出表示可用于序列标注、抽取式问答等任务。

4.3 输入嵌入
BERT 的输入嵌入由三部分相加得到:
h i 0 = E i t o k e n + E i s e g m e n t + E i p o s i t i o n h_i^{0}=E_i^{token}+E_i^{segment}+E_i^{position} hi0=Eitoken+Eisegment+Eiposition
其中,Etoken 表示 token 本身的词向量,Esegment 表示该 token 属于句子 A 还是句子 B,Eposition 表示位置嵌入。
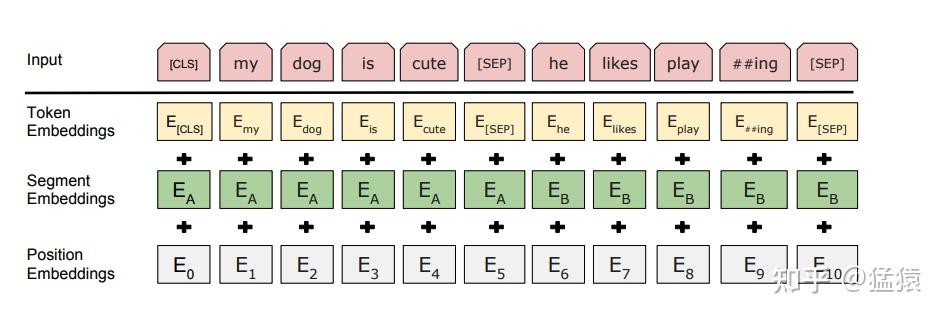
三个输入不是人工手写向量,而是由离散编号查表得到。设 batch size 为 B,序列长度为 S,隐藏维度为 H,词表大小为 V。BERT Base 中 H=768,BERT Large 中 H=1024。
4.3.1 Token Embedding
| 输入部分 | 原始编号 | 查表矩阵 | 输出尺寸 | 作用 |
|---|---|---|---|---|
| Token Embedding | token ids,尺寸 B×S | V×H | B×S×H | 表达每个 token 的词义信息 |
Token Embedding 的生成过程
原始文本先经过分词器,例如 WordPiece。分词后,每个 token 会被映射为词表中的整数编号。模型再用这些编号到 Token Embedding 矩阵中查表。
例如:
[CLS] 今天 天气 很好 [SEP]
会先变成类似:
[101, 791, 1921, 1920, 1962, 102]
这些整数编号的尺寸是 B×S。查表后,每个编号都会变成 H 维向量,因此 Token Embedding 的尺寸变成 B×S×H。
4.3.2 Segment Embedding
| 输入部分 | 原始编号 | 查表矩阵 | 输出尺寸 | 作用 |
|---|---|---|---|---|
| Segment Embedding | token type ids,尺寸 B×S | 2×H | B×S×H | 区分 token 属于句子 A 还是句子 B |
Segment Embedding 的生成过程
Segment Embedding 又叫 token type embedding。它不是由词义决定,而是由句子归属决定。
单句输入时,所有 token type ids 通常都是 0:
[CLS] 这部电影非常精彩 [SEP]
对应:
[0, 0, 0, 0, 0, 0]
句子对输入时,句子 A 和第一个 [SEP] 标记为 0,句子 B 和第二个 [SEP] 标记为 1:
[CLS] 今天的天气真好 [SEP] 适合去户外运动 [SEP]
对应:
[0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1]
这些 0 和 1 会到一个 2×H 的 Segment Embedding 矩阵中查表,得到 B×S×H 的句段向量。
4.3.3 Position Embedding
| 输入部分 | 原始编号 | 查表矩阵 | 输出尺寸 | 作用 |
|---|---|---|---|---|
| Position Embedding | position ids,尺寸 B×S | 可学习位置嵌入矩阵,通常为 512×H | B×S×H | 表达 token 在序列中的绝对位置 |
Position Embedding 的生成过程
BERT 使用可学习的绝对位置嵌入。长度为 S 的输入序列,会先得到从 0 到 S-1 的位置编号。
例如:
[CLS] 今天 天气 很好 [SEP]
对应:
[0, 1, 2, 3, 4, 5]
这些位置编号会到可学习的 Position Embedding 矩阵中查表。BERT 的最大位置长度通常是 512,因此原始 BERT 的位置嵌入矩阵通常为 512×H。
这里的“查表”不表示位置编码是固定规则生成的。BERT 的位置嵌入矩阵是模型参数,会在预训练过程中被更新;它属于可学习的绝对位置编码,而不是 Transformer 原论文中的正弦位置编码。
4.3.4 为什么三种向量要相加
重点:为什么三种向量要相加
Token Embedding 只知道“这个 token 是什么”,Segment Embedding 补充“这个 token 属于哪个句子”,Position Embedding 补充“这个 token 在哪里”。三者尺寸完全相同,逐元素相加后得到最终输入表示,尺寸仍然是 B×S×H。
最终输入流如下:
| 阶段 | 数据 | 尺寸 |
|---|---|---|
| 文本分词 | token 序列 | B×S |
| token 查表 | Token Embedding | B×S×H |
| 句段查表 | Segment Embedding | B×S×H |
| 位置查表 | Position Embedding | B×S×H |
| 三者相加 | 输入向量 H0 | B×S×H |
| LayerNorm 与 Dropout | Encoder 输入 | B×S×H |
4.4 模型规模
| 模型 | Encoder 层数 L | 隐藏维度 H | 注意力头数 A | 参数量 |
|---|---|---|---|---|
| BERT Base | 12 | 768 | 12 | 约 110M |
| BERT Large | 24 | 1024 | 16 | 约 340M |
最大输入长度通常为 512 个 token。
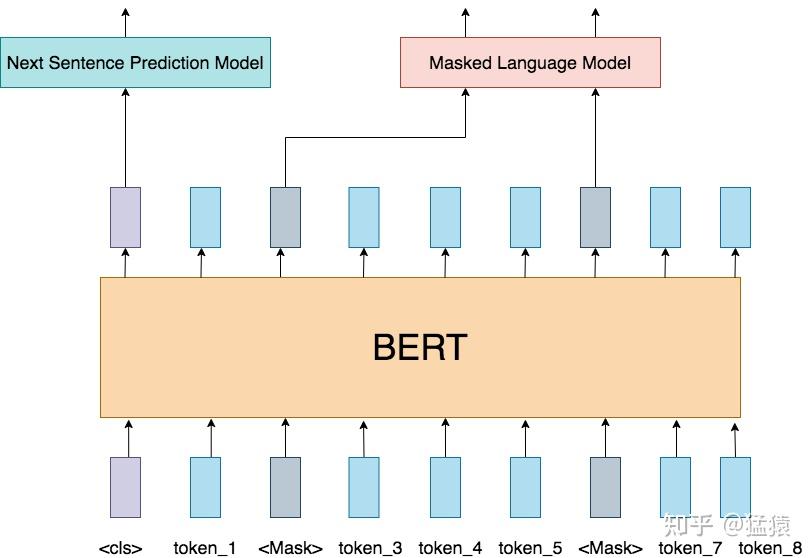
五、BERT 的预训练任务
BERT 的原始预训练包含两个任务:MLM(Masked Language Modeling)和 NSP(Next Sentence Prediction)。
这两个任务都来自无标注文本。原始 BERT 论文使用 BooksCorpus 和英文 Wikipedia 构造预训练语料。训练过程不需要人工标注类别,而是从文本本身自动生成监督信号。
5.1 任务一:MLM
5.1.1 MLM 的定义与设计动机
MLM 可以理解为“上下文填空”。它的设计原因是:BERT 使用双向 Encoder,每个位置都能看到左右上下文。如果直接做“预测下一个词”,模型就会退化成单向语言模型;如果让模型预测当前位置原词,而原词又在输入中可见,就会发生答案泄漏。
因此,BERT 随机遮蔽一部分 token,让模型根据左右上下文恢复原词。这样既保留双向注意力,又能构造自监督训练目标。

训练时随机选择约 15% 的 token 作为预测目标。特殊 token,例如 [CLS] 和 [SEP],通常不参与遮蔽。
被选中的 token 按以下方式处理:
| 比例 | 处理方式 | 目的 |
|---|---|---|
| 80% | 替换为 [MASK] |
明确制造填空位置 |
| 10% | 替换为随机 token | 增加噪声,减少模型只依赖 [MASK] 的问题 |
| 10% | 保持原 token 不变 | 缓解预训练与微调阶段输入分布不一致 |
这种 80、10、10 的设计是为了降低预训练和微调之间的差异。因为下游微调时输入文本中通常没有 [MASK],如果预训练阶段总是把目标词替换成 [MASK],模型会过度依赖这个特殊符号。
5.1.2 MLM 的样本构造
以一句话为例:
my dog is hairy
加上特殊符号后得到:
[CLS] my dog is hairy [SEP]
假设 hairy 被选为预测目标,则输入可能变成:
| 情况 | 输入给 BERT 的序列 | MLM 标签 | 是否计算损失 |
|---|---|---|---|
| 80% | [CLS] my dog is [MASK] [SEP] |
hairy | 只在 hairy 原位置计算 |
| 10% | [CLS] my dog is apple [SEP] |
hairy | 只在 hairy 原位置计算 |
| 10% | [CLS] my dog is hairy [SEP] |
hairy | 只在 hairy 原位置计算 |
注意,三种情况的输入不同,但标签完全相同,始终是原始 token。即使输入中被随机替换成 apple,模型也要在该位置预测 hairy。
更具体地看,假设分词后序列长度 S=6:
| 位置 | 0 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|---|
| 原始 token | [CLS] |
my | dog | is | hairy | [SEP] |
| 是否选为 MLM 目标 | 否 | 否 | 否 | 否 | 是 | 否 |
| 80% 输入 token | [CLS] |
my | dog | is | [MASK] |
[SEP] |
| 10% 随机输入 token | [CLS] |
my | dog | is | apple | [SEP] |
| 10% 保持输入 token | [CLS] |
my | dog | is | hairy | [SEP] |
| MLM 标签 | 忽略 | 忽略 | 忽略 | 忽略 | hairy | 忽略 |
“忽略”表示该位置不参与 MLM 损失。工程实现中常把忽略位置的 label 设为 -100,交叉熵函数会跳过这些位置。
如果用 token id 表示,假设 hairy 的词表编号是 7344,则三种情况的 label ids 都是:
[-100, -100, -100, -100, 7344, -100]
因此,80%、10% 随机替换、10% 保持原词这三种情况只改变输入,不改变标签。模型必须在位置 4 的输出分布中给原词 hairy 更高概率。
5.1.3 MLM 的数据流与尺寸变化
MLM 的数据流如下:
| 阶段 | 数据含义 | 尺寸 |
|---|---|---|
| 原始 token ids | 分词后的 token 编号 | B×S |
| masked token ids | 替换 15% 目标位置后的输入编号 | B×S |
| attention mask | 标记真实 token 与 padding | B×S |
| token type ids | 标记句子 A 或句子 B | B×S |
| embedding 输出 | 三种嵌入相加后的输入 | B×S×H |
| Encoder 输出 | 每个位置的上下文表示 | B×S×H |
| MLM Head 输出 | 每个位置在词表上的 logits | B×S×V |
| masked positions | 只取被选中的预测位置 | 约 B×0.15S×V |
MLM Head 通常由线性层、激活函数、LayerNorm 和词表投影组成。它把 Encoder 输出的 H 维向量映射到 V 维词表空间。
例如 BERT Base 中,Encoder 输出尺寸是 B×S×768。如果词表大小是 V,那么 MLM Head 输出尺寸是 B×S×V。训练损失只在被选中的 15% 位置上计算,未被选中的位置不计入 MLM 损失。
5.1.4 MLM 的标签与损失计算
MLM 损失使用词表级交叉熵。对某个被选中的位置 i,MLM Head 会输出一个 V 维 logits 向量。经过 Softmax 后,得到词表中每个 token 的概率。
如果原始 token 是 hairy,损失只取 hairy 对应词表编号的负对数概率:
L i = − log P ( x i = hairy ∣ x ∖ M ) L_i=-\log P(x_i=\text{hairy}\mid x_{\setminus M}) Li=−logP(xi=hairy∣x∖M)
如果一个序列中有多个被选中的位置,则把这些位置的损失求和或取平均:
L M L M = − ∑ i ∈ M log P ( x i ∣ x ∖ M ) L_{MLM}=-\sum_{i\in M}\log P(x_i \mid x_{\setminus M}) LMLM=−i∈M∑logP(xi∣x∖M)
其中,M 表示被选中的预测位置集合,xi 表示原始 token,x\setminus M 表示被遮蔽后的输入上下文。
完整计算流程如下:
| 步骤 | 位置 4 的数据 | 说明 |
|---|---|---|
| 1 | Encoder 输出 h4,尺寸 H | 位置 4 的上下文表示 |
| 2 | MLM Head 输出 logits4,尺寸 V | 每个词表 token 一个分数 |
| 3 | Softmax 得到 P4,尺寸 V | 转成词表概率分布 |
| 4 | 读取 hairy 的概率 P4,hairy | 只看原始标签对应概率 |
| 5 | 计算 -log P4,hairy | 得到该位置交叉熵损失 |
如果模型给 hairy 的概率越高,损失越小;如果模型把概率分给 apple、dog 等其他 token,损失就会变大。
重点:MLM 训练到的能力
MLM 迫使模型利用双向上下文恢复缺失 token,因此模型会学习词义、短语搭配、句法结构和局部语义关系。但是 MLM 主要关注 token 级预测,对句子间关系的约束不够直接。
5.2 任务二:NSP
5.2.1 NSP 的定义与设计动机
NSP(Next Sentence Prediction)用于判断两个句子是否真实相邻。训练样本中,50% 的句子 B 是原文中句子 A 的下一句,50% 的句子 B 是随机采样句子。
NSP 的设计动机是补充句子间关系建模。很多下游任务不是只理解单句,而是要理解两个文本之间的关系,例如问答、自然语言推理和句子匹配。
原始 BERT 通过 NSP 给 [CLS] 位置增加句子对级别的监督信号,使它更适合承载整段输入的分类信息。


5.2.2 NSP 的样本来源与构造方式
NSP 样本来自连续文档。构造时先从同一篇文档中取句子 A,再构造句子 B。
| 样本类型 | 构造方式 | 标签 |
|---|---|---|
| 正样本 | 句子 B 是原文中紧跟句子 A 的下一句 | IsNext |
| 负样本 | 句子 B 是从语料库中随机采样的句子 | NotNext |
正负样本比例通常各占 50%。
例如:
句子 A:
今天的天气真好。
真实下一句:
适合去户外运动。
NSP 正样本输入为:
[CLS] 今天的天气真好。 [SEP] 适合去户外运动。 [SEP]
标签为:
IsNext
如果句子 B 随机换成“这家餐厅的价格很高。”,则标签为 NotNext。
5.2.3 NSP 的数据流与尺寸变化
NSP 和 MLM 共用同一个 BERT Encoder。区别在于,NSP 只使用 [CLS] 位置的最终输出。
| 阶段 | 数据含义 | 尺寸 |
|---|---|---|
| 句子对 token ids | [CLS] A [SEP] B [SEP] |
B×S |
| token type ids | A 部分为 0,B 部分为 1 | B×S |
| embedding 输出 | 三种嵌入相加后的输入 | B×S×H |
| Encoder 输出 | 每个 token 的上下文表示 | B×S×H |
[CLS] 输出 |
取第 0 个位置的向量 | B×H |
| NSP 分类层输出 | 二分类 logits | B×2 |
NSP 分类层是一个简单线性层,把 [CLS] 的 H 维向量映射成 2 维 logits,分别表示 IsNext 和 NotNext。
5.2.4 NSP 的标签与损失计算
L N S P = − y log P ( I s N e x t ) − ( 1 − y ) log P ( N o t N e x t ) L_{NSP}=-y\log P(IsNext)-(1-y)\log P(NotNext) LNSP=−ylogP(IsNext)−(1−y)logP(NotNext)
其中,y=1 表示 IsNext,y=0 表示 NotNext。
5.3 MLM 与 NSP 的联合训练
MLM 和 NSP 在同一批输入上联合训练。一个样本既会有 MLM 标签,也会有 NSP 标签。
整体数据流可以概括为:
| 步骤 | 处理内容 | 输出 |
|---|---|---|
| 1 | 从无标注文档中抽取句子 A 和句子 B | 正样本或负样本句子对 |
| 2 | 拼接 [CLS] A [SEP] B [SEP] |
token 序列 |
| 3 | 生成 token ids、token type ids、position ids | 三类输入编号 |
| 4 | 随机选择 15% token 做 MLM 改写 | masked token ids 与 MLM 标签 |
| 5 | 输入 BERT Encoder | B×S×H 的上下文表示 |
| 6 | MLM Head 预测被遮蔽 token | B×S×V logits |
| 7 | NSP Head 预测句子是否相邻 | B×2 logits |
| 8 | 合并两个损失 | L=LMLM+LNSP |
联合训练后的效果是:MLM 主要训练 token 级语义理解,NSP 主要训练句子对级关系判断。后续研究发现 NSP 并不是所有场景都必要,因此 RoBERTa 移除了 NSP,并通过更多数据、更长训练和动态 masking 获得更强效果。
六、BERT 如何适配下游任务
BERT 的优势在于下游任务改动较小。通常只需要在预训练模型顶部增加一个轻量任务头。
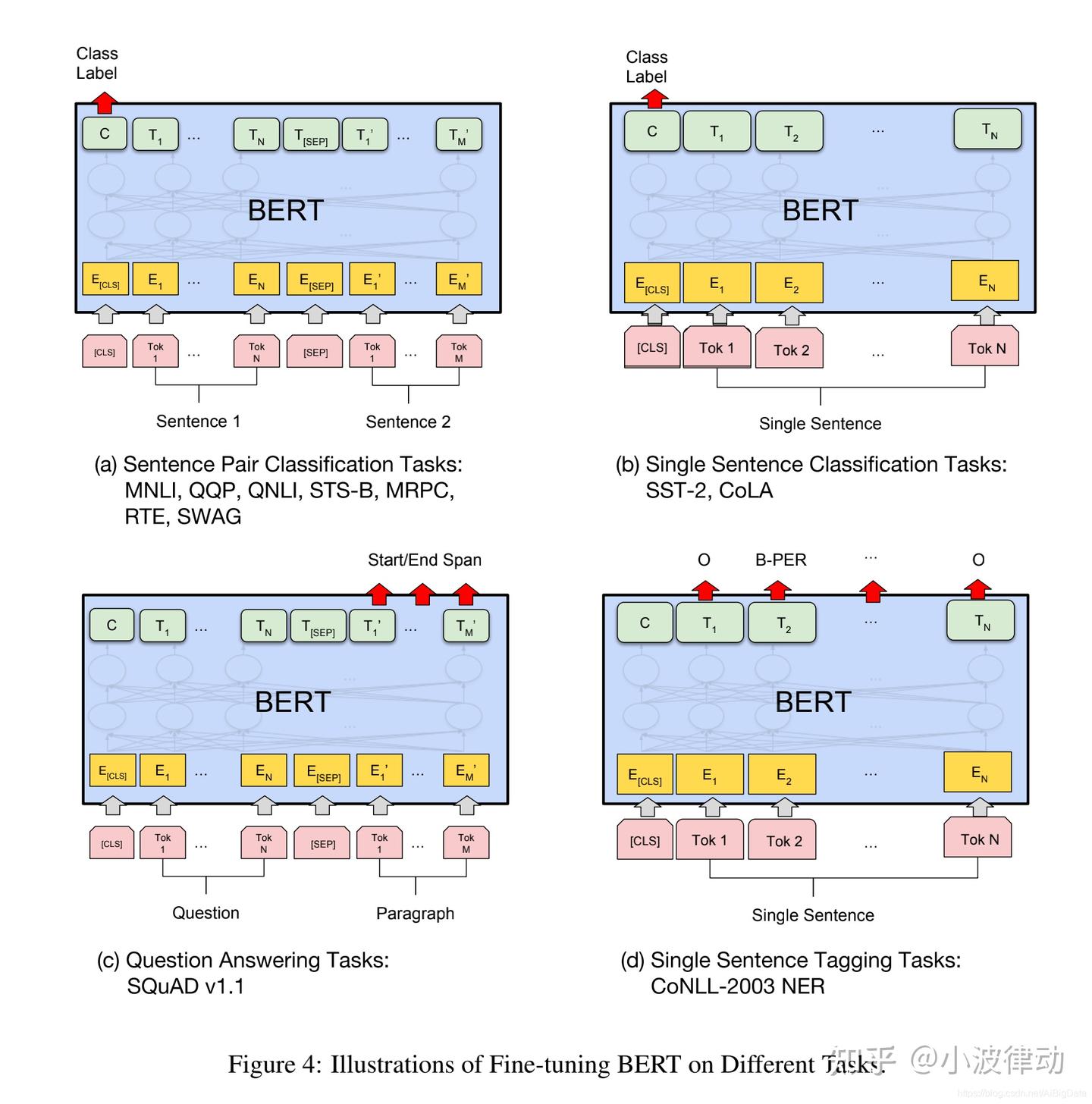
| 下游任务类型 | 典型任务 | 使用的输出 | 任务头 |
|---|---|---|---|
| 单句分类 | 情感分析、垃圾邮件检测、主题分类 | [CLS] 输出 |
全连接分类层 |
| 句对分类 | 自然语言推理、语义相似度、文本匹配 | [CLS] 输出 |
二分类或多分类层 |
| 文本问答 | 阅读理解、抽取式问答 | 每个 token 输出 | 起始位置和结束位置预测层 |
| 单句标注 | 命名实体识别、词性标注、槽位抽取 | 每个 token 输出 | token 级分类层或 CRF 层 |
| 语义检索 | 查询与文档匹配、相似句召回 | 句向量或 token 向量 | 相似度计算或对比学习头 |
6.1 句对分类
句对分类输入两个句子,并判断两者之间的关系。例如自然语言推理任务需要判断第二个句子是否能由第一个句子推出,常见标签包括蕴含、中立和矛盾。

输入形式通常为:
[CLS] 今天的天气真好。 [SEP] 适合去户外运动。 [SEP]
模型取 [CLS] 位置的输出向量,通过分类层得到句间关系标签。
6.2 单句分类
单句分类只输入一个句子,并输出类别。例如情感分析可以判断“这部电影非常精彩!”属于正面情感还是负面情感。

输入形式通常为:
[CLS] 这部电影非常精彩! [SEP]
分类层读取 [CLS] 输出,得到类别概率分布。
6.3 文本问答
抽取式问答输入问题和文档,模型需要在文档中定位答案片段。常见做法是对每个 token 分别预测“答案起始位置”和“答案结束位置”。
输入形式通常为:
[CLS] 北京是中国的哪个省份? [SEP] 北京是中国的首都,位于华北地区,不是省份。 [SEP]
如果答案是“不是省份”,任务头会输出该片段在文档中的起始索引和结束索引。
6.4 单句标注
单句标注需要为每个 token 分配标签。例如命名实体识别可以从“苹果公司是一家总部位于美国加利福尼亚州库比蒂诺的科技公司。”中识别组织名和地点。

常见标注方案是 BIO:B 表示实体开始,I 表示实体内部,O 表示非实体。模型对每个 token 输出一个标签分布,必要时再接 CRF(Conditional Random Field)层约束标签转移。
重点:预训练与微调的关系
预训练阶段学习通用语言表示,微调阶段把通用表示适配到具体任务。编码器预训练模型的价值在于减少下游任务对大量标注数据的依赖。
七、BERT 之后的主要发展路线
BERT 之后的编码器预训练并不是单纯“换一个名字”,而是围绕几个问题继续改进。
7.1 RoBERTa:把 BERT 训练得更充分
RoBERTa(A Robustly Optimized BERT Pretraining Approach)的核心观点是:原始 BERT 在训练规模、训练步数、batch size 和数据规模上并没有被充分训练。
RoBERTa 的主要改动:
- 移除 NSP。
- 使用更大 batch size。
- 使用更多训练数据。
- 使用动态 masking,而不是固定 masking。
- 训练更久。
RoBERTa 的意义在于说明:很多性能提升并不一定来自新结构,也可能来自更充分、更合理的预训练设置。
7.2 ALBERT:降低参数量并提升扩展性
ALBERT(A Lite BERT for Self-supervised Learning of Language Representations)关注 BERT 参数量和训练成本问题。
ALBERT 的主要改动:
- Factorized Embedding Parameterization:将词嵌入维度和隐藏层维度解耦,减少词表嵌入参数。
- Cross-layer Parameter Sharing:不同 Transformer 层共享参数,减少整体参数量。
- SOP(Sentence Order Prediction):用句子顺序预测替代 NSP,更关注句间连贯性。
7.2.1 SOP 的原理
SOP(Sentence Order Prediction)是 ALBERT 用来替代 NSP(Next Sentence Prediction)的句间预训练任务。它关注的问题不是“两个句子是否来自同一篇文档”,而是“两个连续片段的顺序是否正确”。
SOP 的样本通常来自同一篇文档中的两个连续片段:
| 样本类型 | 构造方式 | 标签 |
|---|---|---|
| 正样本 | 按原文顺序输入片段 A,再输入片段 B | 正确顺序 |
| 负样本 | 把同一组连续片段交换顺序,输入片段 B,再输入片段 A | 错误顺序 |
例如原文顺序是:
句子 A:今天的天气真好。
句子 B:适合去户外运动。
SOP 正样本为:
[CLS] 今天的天气真好。 [SEP] 适合去户外运动。 [SEP]
SOP 负样本为:
[CLS] 适合去户外运动。 [SEP] 今天的天气真好。 [SEP]
模型读取 [CLS] 位置的最终表示,通过二分类层判断顺序是否正确。SOP 迫使模型学习句子之间的语义承接、因果顺序和篇章连贯性。
7.2.2 SOP 与 NSP 的区别
NSP 的负样本通常从其他文档中随机采样句子,这可能让任务变得偏简单:模型只需要判断两个句子是否主题不一致,而不一定真正理解句子顺序。
SOP 的负样本来自同一篇文档的连续片段,只是交换顺序,因此主题仍然接近。模型必须判断“先说 A 再说 B”是否比“先说 B 再说 A”更自然。
| 对比项 | NSP | SOP |
|---|---|---|
| 判断目标 | 句子 B 是否是句子 A 的下一句 | 两个连续片段的顺序是否正确 |
| 负样本来源 | 常从其他文档随机采样 | 同一文档连续片段交换顺序 |
| 主要风险 | 可能学到主题差异,而不是句间连贯性 | 更聚焦篇章顺序和语义承接 |
| 代表模型 | BERT | ALBERT |
SOP 的核心改进是:把“是否相邻”改成“顺序是否合理”,从而减少模型靠主题差异取巧的可能。
ALBERT 的重点不是简单变小,而是在减少参数的同时保持甚至提升可扩展性。
7.3 SpanBERT:从预测 token 变成预测片段
SpanBERT(Span-based BERT)认为很多理解任务关注的是连续文本片段,例如问答中的答案 span、指代消解中的实体 mention。
SpanBERT 的主要改动:
- 遮蔽连续 span,而不是随机遮蔽独立 token。
- 使用 span boundary representations,通过片段两端表示预测整个被遮蔽片段。
- 更适合问答、关系抽取、指代消解等 span selection 任务。
直观理解:普通 MLM 像挖掉零散单词,SpanBERT 像挖掉一整段短语,让模型学习如何根据边界上下文恢复缺失片段。
7.4 ELECTRA:从生成式填空变成判别式验假
ELECTRA(Efficiently Learning an Encoder that Classifies Token Replacements Accurately)提出 RTD(Replaced Token Detection)任务。
ELECTRA 不再只预测被 mask 的少量位置,而是先用一个小生成器替换部分 token,再让判别器判断每个 token 是否被替换。
L R T D = − ∑ i z i log D ( x i ) + ( 1 − z i ) log ( 1 − D ( x i ) ) L_{RTD}=-\sum_i z_i\log D(x_i)+(1-z_i)\log(1-D(x_i)) LRTD=−i∑zilogD(xi)+(1−zi)log(1−D(xi))
其中,zi 表示第 i 个 token 是否为原始 token,D(xi) 表示判别器认为该 token 为真实 token 的概率。
ELECTRA 的关键优势是训练信号更密集。MLM 通常只对 15% 的位置计算损失,而 RTD 可以对全部位置提供监督信号。
7.5 DeBERTa:解耦内容与位置
DeBERTa(Decoding-enhanced BERT with Disentangled Attention)主要改进注意力中的内容信息和位置信息处理方式。
DeBERTa 的主要改动:
- Disentangled Attention:每个词用内容向量和位置向量分别表示。
- 注意力分数同时考虑内容到内容、内容到位置、位置到内容等关系。
- Enhanced Mask Decoder:在预测被遮蔽 token 时引入更充分的绝对位置信息。
DeBERTa 的核心思想是:词义和位置不是同一类信息,应当在注意力计算中分开建模,再组合使用。
7.6 主要模型对比
| 模型 | 主要目标 | 预训练任务 | 关键改进 | 适合理解的重点 |
|---|---|---|---|---|
| BERT | 建立双向编码器预训练范式 | MLM + NSP | 深层双向 Transformer Encoder | 编码器预训练的基础框架 |
| RoBERTa | 充分优化 BERT 训练流程 | MLM | 移除 NSP、更多数据、更大 batch、动态 masking | 训练策略本身很关键 |
| ALBERT | 降低参数量并提升扩展性 | MLM + SOP | 嵌入分解、跨层参数共享、句序预测 | 参数效率和句间建模 |
| SpanBERT | 强化片段表示 | Span masking + Span Boundary Objective | 预测连续片段而不是零散 token | 问答和指代消解中的 span |
| ELECTRA | 提升样本效率 | RTD | 判别 token 是否被替换 | 更密集的预训练监督 |
| DeBERTa | 改进位置与内容建模 | MLM 变体 | 解耦注意力、增强 mask 解码器 | 内容信息和位置信息分开建模 |
八、参考资料
- Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- Google Research Blog. Open Sourcing BERT: State-of-the-Art Pre-training for Natural Language Processing
- Yinhan Liu 等. RoBERTa: A Robustly Optimized BERT Pretraining Approach
- Zhenzhong Lan 等. ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
- Mandar Joshi 等. SpanBERT: Improving Pre-training by Representing and Predicting Spans
- Kevin Clark 等. ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
- Pengcheng He 等. DeBERTa: Decoding-enhanced BERT with Disentangled Attention
- Hugging Face Transformers. BERT model documentation
- Tomas Mikolov 等. Efficient Estimation of Word Representations in Vector Space
- Jeffrey Pennington, Richard Socher, Christopher Manning. GloVe: Global Vectors for Word Representation
- Matthew Peters 等. Deep contextualized word representations
- CSDN 参考文章:ELMo 详解
- CSDN 参考文章:Word2Vec 详解
- CSDN 参考文章:GloVe 详解
- CSDN 参考文章:图解 BERT 模型
- 本地参考笔记:
/Users/mac/Downloads/万字长文,带你搞懂什么是BERT模型(非常详细)看这一篇就够了!-CSDN博客.html - 本地参考笔记:
/Users/mac/Downloads/BERT学习笔记一:基于论文精读的模型详解 - 知乎.html - 本地参考笔记:
/Users/mac/Downloads/(7 封私信) AI大模型介绍-BERT - 知乎.html

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 3
3 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)