Python学习:基本语法(三)
八、类(Class)
1、类(Class)的理解
可理解为一个模板,用于创建具有相同属性和行为的对象,把数据(属性)和操作数据的方法(函数)封装在一起。
所有被同一个类实例化的对象都继承该类下的所有方法
特点:
可重复使用
模块化
可维护性
2、定义类的语法
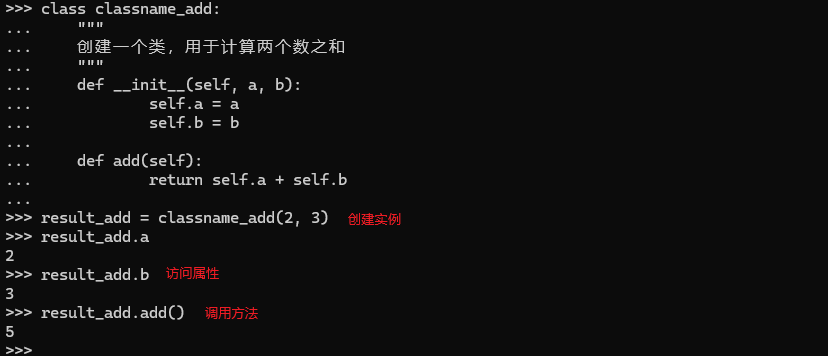
class classname_add:
"""
创建一个类,用于计算两个数之和
"""
def __init__(self, a, b): # 初妈化实例,self为实例本身,必须作为实例的第一个参数
self.a = a # 实例属性 a
self.b = b # 实例属性 b
def add(self): # 实例方法
return self.a + self.b # 返回两个数之和
result_add = classname_add(2, 3)
3、三大核心特性
(1)封装
将数据和操作包装在类内部,对外提供公开的方法
Python没有严格的私有机制,约定以单下划线 _name 表示受保护的,双下划线 __name 实现名称修饰,达到一定隐藏的效果
(2)继承
子类可以继承父类的属性和方法,并可以扩展或重写
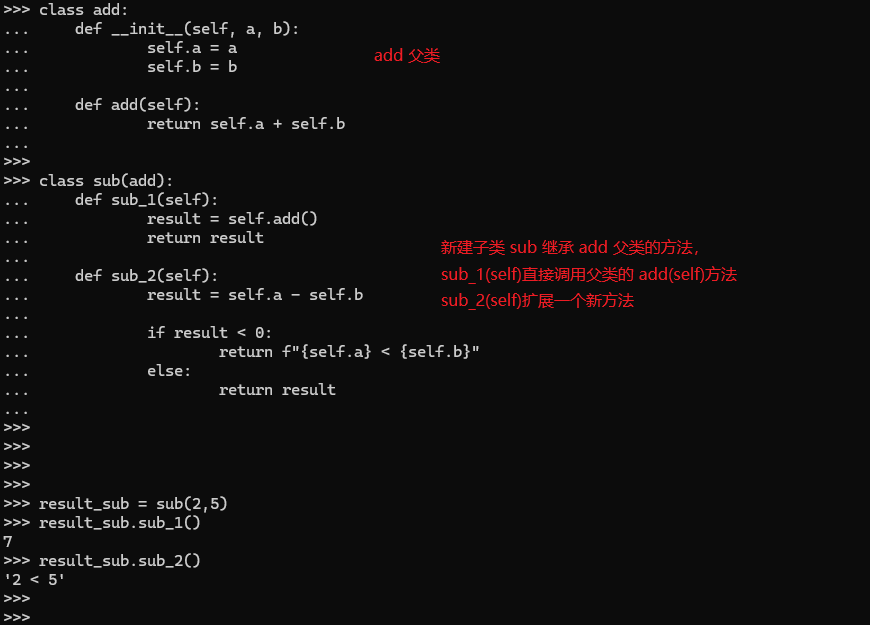
>>> class add:
... def __init__(self, a, b):
... self.a = a
... self.b = b
...
... def add(self):
... return self.a + self.b
...
>>>
>>> class sub(add):
... def sub_1(self):
... result = self.add()
... return result
...
... def sub_2(self):
... result = self.a - self.b
...
... if result < 0:
... return f"{self.a} < {self.b}"
... else:
... return result
...
>>>
>>>结果展示:
(3)多态
多种形态
同一个操作(函数/方法)作用于不同的对象时,能够自动表现出适合该对象的行为。
Python实现多态的两种主要方式
继承 + 方法重写(经典多态)
父类定义方法,子类重写该方法。
调用时无论使用父类还是子类对象,都会自动执行子类的版本
鸭子类型(Duck Typing)
不要求对象必须是某个父类的子类,只要求对象有需要的方法或属性
继承 + 方法重写示例
>>> class add_sub:
... def __init__(self, a, b):
... self.a = a
... self.b = b
...
... def addd(self):
... return
...
>>> class add(add_sub):
... def add(self):
... return self.a - self.b
...
>>> class sub(add_sub):
... def add(self):
... return self.a + self.b
...
>>> def a_s(obj):
... print(obj.add())
...
>>>示例结果

a_s(add(1,5)),直接调用了子类add中的减法
a_s(sub(1,5)),直接调用了子类sub中的加法
鸭子类型示例
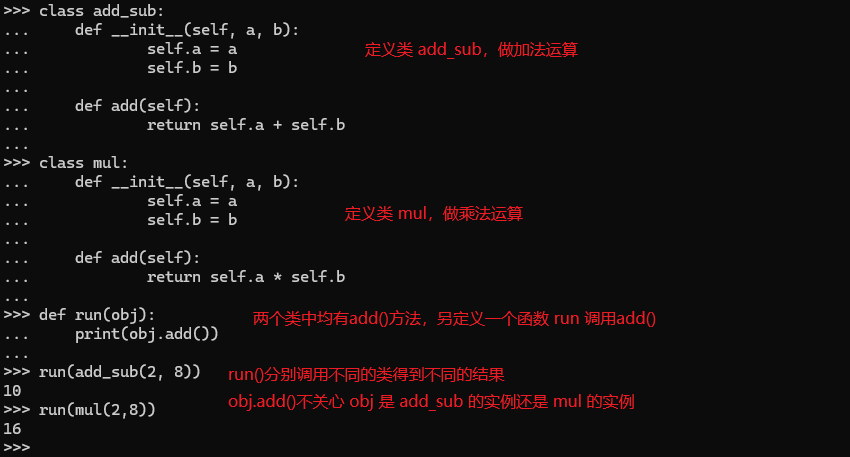
>>> class add_sub:
... def __init__(self, a, b):
... self.a = a
... self.b = b
...
... def add(self):
... return self.a + self.b
...
>>> class mul:
... def __init__(self, a, b):
... self.a = a
... self.b = b
...
... def add(self):
... return self.a * self.b
...
>>> def run(obj):
... print(obj.add())
...
>>> 结果:
4、特殊方法(Magic Methods)
以双下划线开头和结尾的方法,用于定制类的行为
常用示例:
__init__(self, ...): 初始化
__str__(self): str(obj) 或 print(obj) 时调用,面向用户
__repr__(self): repr(obj)时调用,面向开发者,通常力求能还原对象
__len__(self): len(obj)
__add__(self, other): obj + other
示例:
>>> class Point:
... def __init__(self, x, y):
... self.x = x
... self.y = y
...
... def __str__(self):
... return f"({self.x}, {self.y})"
...
... def __add__(self, other):
... return Point(self.x + other.x, self.y + other.y)
...
>>> p1 = Point(1,2)
>>> p2 = Point(3,4)
>>> print(p1 + p2)
(4, 6)
>>>5、类方法、静态方法
实例方法
操作具体实例的数据,行为依赖于实例状态
第一个参数必须是 self
通过实例调用时,self 自动绑定到该实例
可访问和修改实例属性,也可通过 self.__class__ 访问类属性
类方法
使用 @classmethod 装饰
第一个参数 cls(类本身),不是实例
调用时, cls 自动绑定到调用它的类
操作类级别的数据
提供替代构造函数
在继承中,cls 会指向调用它的子类,支持多态
静态方法
使用 @staticmethod 装饰,没有特殊的第一个参数
行为类似普通函数,但被组织在类的命名空间中
不能访问实例属性或类属性
实现与类逻辑相关但不依赖于类或实例状态的功能
通常是工具函数、辅助计算、类型检查等
提高代码的模块化
6、属性(property)
通过 @property 装饰,可将方法伪装成属性,像访问属性一样去访问它
7、类与实例命名空间
每个实例有自己的 __dict__ 存储实例属性
类也有自己的 __dict__ 存储属性和方法
访问属性时,先查实例字典,再查类字典,再查父类字典
MRO顺序
九、模块
1、模块基本概念
也可称为:库
是一个包含 Python 代码的 .py 文件
模块将相关的函数、类、变量组织在一起,提高代码的可维护性和可重用性
模块包括标准库模块、第三方模块
标准模块:
即Python自带的模块
常用的标准模块有:os、sys、math、random、datetime、time、re、json、csv等
第三方模块:
通过包管理器 pip 安装的模块
pip install netmiko
2、模块导入方式
import ------ 导入模块
import ... as ... ------ 导入模块并起别名,起简化模块名称的作用
from ... import ... ------ 从模块中导入特定方法
>>> import math
>>> math.sqrt(16)
4.0
>>> import datetime
>>> datetime.datetime.now()
datetime.datetime(2026, 5, 15, 17, 48, 31, 505709)
>>> import datetime as dt
>>> dt.datetime.now()
datetime.datetime(2026, 5, 15, 17, 48, 44, 512885)
>>> from random import randint
>>> randint(1, 10)
8
>>>3、if __name__ == "__main__" 惯用写法
作用是控制代码的执行时间,用来区分当前文件是 被直接执行 还是 被当作模块导入
每个模块都有一个内置属性 __name__。__name__ 会根据文件的运行方式自动改变:
当模块被直接运行时,__name__ 被设为 "__main__"
当模块被导入到其他模块时,__name__ 被设为模块名(即不带 .py 后缀的文件名)
如果没有判断,当其他脚本导入模块时,脚本会自运运行。只有当程序判断当前文件是被直接执行时,if 条件才会成立,其下方的代码才会被执行。
十、异常处理
异常处理是Python中常用的方法
作用是防止代码因遇到错误而直接崩溃,能够捕获错误、输出原因,并让代码继续往下执行。
语法错误和异常是Python中的两种代码错误。
Python中主要通过 try ... except 来处理异常
常见的异常类型:
SyntaxError:语法错误
IndentationError:缩进错误
NameError:变量名未定义
TypeError:操作或函数应用不适当类型
ZeroDivisionError:除数为 0
IndexError:列表索引超出范围
KeyError:字典中找不到对应的键
FileNotFoundError:找不到指定的文件
ValueError:传入的值无效
>>> try:
... a = 1 / 0
... except ZeroDivisionError:
... print("捕获到:零除错误")
...
捕获到:零除错误
>>>>>> try:
... a = 1 / 0
... except ZeroDivisionError as e:
... print(f"错误内容: {e}")
...
错误内容: division by zero
>>>>>> try:
... a = 1 / 0
... except Exception as e:
... print(f"错误内容: {e}")
...
错误内容: division by zero
>>>完整结构示例:
try:
num = int(input("请输入一个数字:"))
result = 10 / num
except ValueError:
print("输入的不是有效数字!")
except ZeroDivisionError:
print("除数不能为零!")
else:
print(f"计算成功,结果是:{result}")
finally:
print("程序结束,执行收尾工作。")如果有多个except,Python 会从上到下匹配
尽量避免写空的 excetp 或宽泛的 except Exception
十一、正则表达式
Regular Expression
一种用于字符串匹配、查找、替换和分割的强大模式描述语言
Python通过内置模块 re 提供对正则表达式的支持
1、核心概念
模式:Pattern,由普通字符和元字符组成的字符串,定义匹配规则
普通字符:a、b、c、1、2、3等
元字符:*、+、. 等
匹配:Match,检查字符串是否符合模式
搜索:Search,在字符串中查找第一个符合模式的子串
查找全部:Findall,返回所有符合模式的子串
替换:Sub,将匹配到的子串替换为指定内容
分割:Split,按匹配到的模式分割字符串
2、常用元字符与语法检查
| 元字符/语法 | 说明 | 示例 |
| . | 匹配除换行符之外的任意单个字符 | a.c 匹配abc、a&b |
| ^ | 匹配以 ^ 后面字符或字符串开头的字符串 | ^Hello 匹配 Hello world |
| $ | 匹配以 $ 前面字符或字符串结尾的字符串 | world$ 匹配 Hello world |
| * | 匹配 * 前一个字符0次或多次 | ab* 匹配 a、ab、abbb |
| + | 匹配 + 前一个字符1次或多次 | ab+ 匹配 ab、abb |
| ? | 匹匹配 ? 前一个字符0次或1次 | ab? 匹配 a、ab |
| {n} | 匹配 {n} 前一个字符 n次 | a{4} 匹配 aaaa |
| {n,} | 匹配 {n,} 前一个字符至少 n 次 | a{2,} 匹配 aa、aaa |
| {n, m} | 匹配 {n, m} 前一个字符至少n次,最多 m 次 | a{2, 4} 匹配 aa、aaa、aaaa |
| [abc] | 匹配 [ ] 内任意一个字符 | [abc] 匹配 a、b、c |
| [^abc] | 匹配除 [ ]内字符外的任意一个字符 | [^0-9] 匹配非数字 |
| [a-z] | 范围匹配 | 匹配任意一个小写英文字母 |
| | | 或,匹配 | 左边或右边任意一个 | cat|dog 匹配 cat 或 dog |
| (...) | 分组,捕获匹配的文本 | (ab)+ 匹配 abab |
| (?:...) | 非捕获分组 | 只分组不捕获 |
| \d | 匹配任意一个阿拉伯数字,同 [0-9] | |
| \D | 匹配非阿拉伯数字,同 [^0-9] | |
| \w | 小写,匹配任意单词字符(字母、数字、下划线) | |
| \W | 大写,匹配非单词字符 | |
| \s | 小写,匹配一个空白字符(空格、制表符、换行) | |
| \S | 大写,匹配任意一个非空白字符 | |
| \b | 单词边界 | r"\bcat\b" 匹配单词 cat |
| \B | 非单词边界 | |
| \ | 转义字符,如当字符串中出现了 ?,匹配这个问号 \? |
3、re模块主要函数
re.match(pattern, string,flags=0)
用于从字符串的开头开始匹配正则表达式模式。
如果开头匹配成功,返回一个匹配对象(Match)
如果开头不匹配,则返回(None)
参数:
pattern:正则表达式模式字符串,建议使用 r'...',表示原始字符串
string:要匹配的目标字符串
flags:可选
返回值:
匹配成功:返回 re.Match 对象,可调用 group() 等方法获取匹配内容
匹配失败:返回 None
>>> import re
>>> a = 'Hello world'
>>> b = re.match('Hello', a)
>>> b
<re.Match object; span=(0, 5), match='Hello'>
>>> print(b)
<re.Match object; span=(0, 5), match='Hello'>
>>> print(b.group())
Hello
>>> a1 = 'world Hello'
>>> b1 = re.match('Hello', a1)
>>> b1
>>> print(b1)
None
>>>re.search(pattern,string)
搜索整个字符串,返回第一个匹配的
>>> import re
>>> a1 = 'world Hello'
>>> b1 = re.search('Hello', a1)
>>> print(b1)
<re.Match object; span=(6, 11), match='Hello'>
>>> print(b1.group())
Hello
>>>re.findall(pattern, string)
返回所有非重叠匹配的列表
>>> a = 'Hello world!world Hello'
>>> b = re.findall('Hello', a)
>>> b
['Hello', 'Hello']
>>>re.finditer(pattern, string)
返回一个迭代器,迭代器中每个元素是匹配对象(re.Match),包含字符串中所有非重叠匹配的详细位置。适合需要逐个处理匹配圣果或获取匹配位置的场景。
不会一次性将所有匹配结果保存在内存中,而是逐个生成,适合处理大量匹配或大文本。
>>> import re
>>> text = "apple 10, banana 20, cherry 30"
>>> text_re = re.finditer(r'(\w+)\s+(\d+)', text)
>>> for match in text_re:
... print(f"完整匹配:{match.group(0)}")
... print(f"产品名称:{match.group(1)}, 数量:{match.group(2)}")
... print(f"起止位置:{match.span()}\n")
...
完整匹配:apple 10
产品名称:apple, 数量:10
起止位置:(0, 8)
完整匹配:banana 20
产品名称:banana, 数量:20
起止位置:(10, 19)
完整匹配:cherry 30
产品名称:cherry, 数量:30
起止位置:(21, 30)
>>>re.sub(pattern, repl, string, count=0)
替换匹配的子串
参数:
pattern:正则表达式模式或已编译的正则对象
repl:需要替换成的内容
string:需要执行替换的原始字符串
count:最多替换的次数,默认为0,表示替换所有
>>> text = 'Hello world'
>>> a = re.sub('Hello', 'Lilei', text)
>>> print(a)
Lilei world
>>> text_1 = 'Hello Lilei! Lilei is a student'
>>> text_1re = re.sub(
... 'Lilei',
... 'Liumei',
... text_1)
>>>
>>> print(text_1re)
Hello Liumei! Liumei is a student
>>>re.subn()
同sub,但返回的是一个元组,包括替换后的字符串和替换的次数
>>> a = 'aaaaaa'
>>> b = re.subn('a','c',a)
>>> print(b)
('cccccc', 6)
>>>re.split(pattern, string, maxsplit=0)
按模式分割字符串,返回一个列表。
参数:
pattern:正则表达式
string:要分割的原始字符串
maxsplit:最大分割次数,默认为 0,无限分割)
>>> a = 'a a a a a'
>>> b = re.split(' ',a) # 直接匹配空格进行分割
>>> b
['a', 'a', 'a', 'a', 'a']
>>> b = re.split('\s',a) # 通过匹配 \s(一个空字符)进行分割
>>> b
['a', 'a', 'a', 'a', 'a']
>>>
>>> b1 = re.split('\s', a,maxsplit=3) # 指定分割次数
>>> b1
['a', 'a', 'a', 'a a']
>>>
re.compile(pattern)
编译正则表达式
将正则表达式的模式字符串编译成一个正则表达式对象(re.Pattern),可被多次复用。
>>> pattern = re.compile(r'\d+')
>>> text = 'a1b2c3'
>>> pattern.findall(text)
['1', '2', '3']
>>> pattern.sub('X',text)
'aXbXcX'
>>>4、匹配对象的方法(match、search、finditer返回)
group():返回匹配的字符串
group(n):返回第 n 个分组(n = 0 表示整个匹配)
groups():返回所有分组构成的元组
start():匹配开始索引
end():匹配结束索引
span():返回(start,end)元组
5、贪婪匹配与非贪婪匹配
贪婪匹配:默认匹配模式,尽可能匹配更长字符串。* 、+ 、{n,} 都是贪婪匹配
非贪婪匹配:在量词后加 ?,匹配尽可能短的字符串
>>> text = "<div>hello</div><div>world</div>"
>>> re.findall(r'<div>.*</div>', text)
['<div>hello</div><div>world</div>']
>>> re.findall(r'<div>.*?</div>', text)
['<div>hello</div>', '<div>world</div>']
>>>
AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 14
14 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)