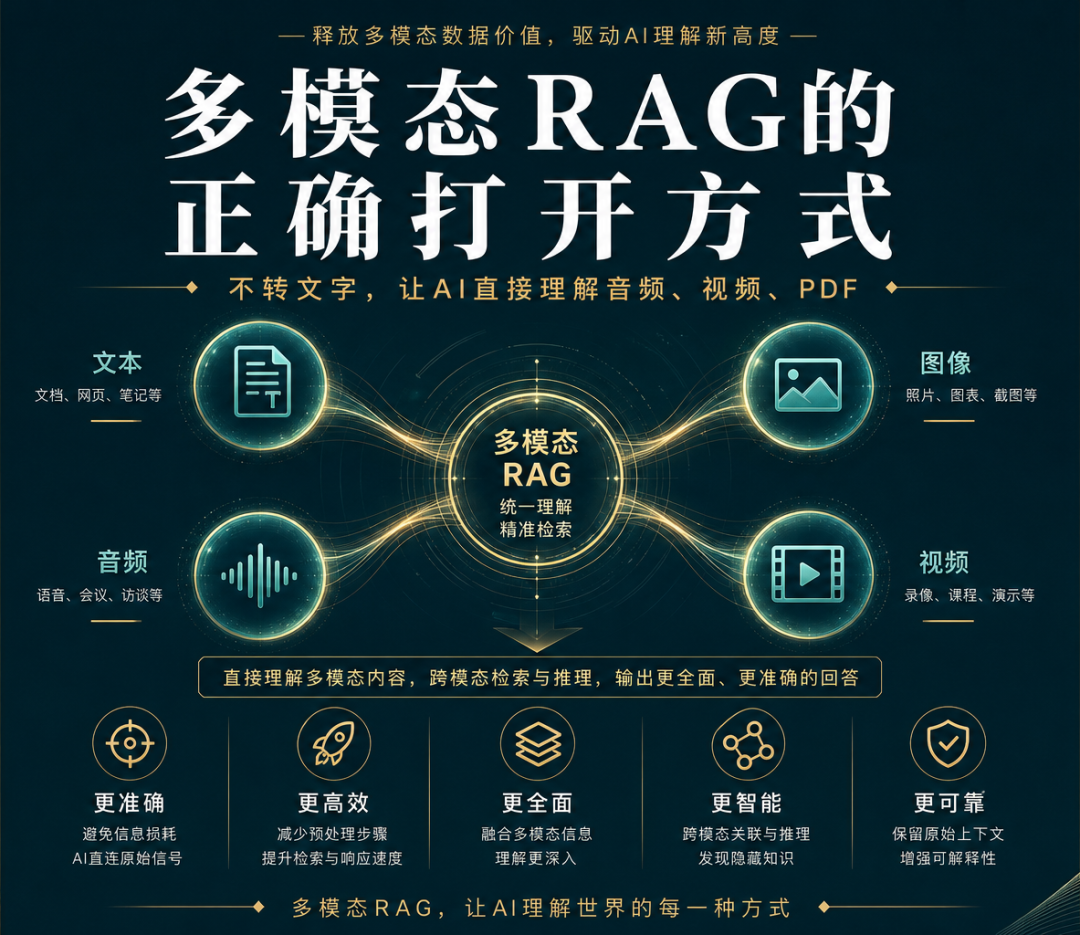
多模态RAG的正确打开方式
本文探讨了多模态RAG(检索增强生成)技术的应用,通过多模态Embedding技术将文本、图像、音频、视频直接映射到同一向量空间,实现跨模态检索。文章详细介绍了Embedding原理、多模态模型对齐技术、实战案例及适用场景,强调保留数据原生形态的重要性,避免信息在转换过程中丢失。
多模态RAG的正确打开方式

背景
传统的RAG系统本质上是个文字游戏。不管你的数据是音频、视频还是PDF,统一先转成文字,再丢进向量数据库。
但问题来了:
- 音频里的情感和语气,转成文字还剩多少?
- PDF里的表格布局和图表关系,OCR能完美还原吗?
- 视频里的动作和视觉线索,文字描述能说清楚吗?
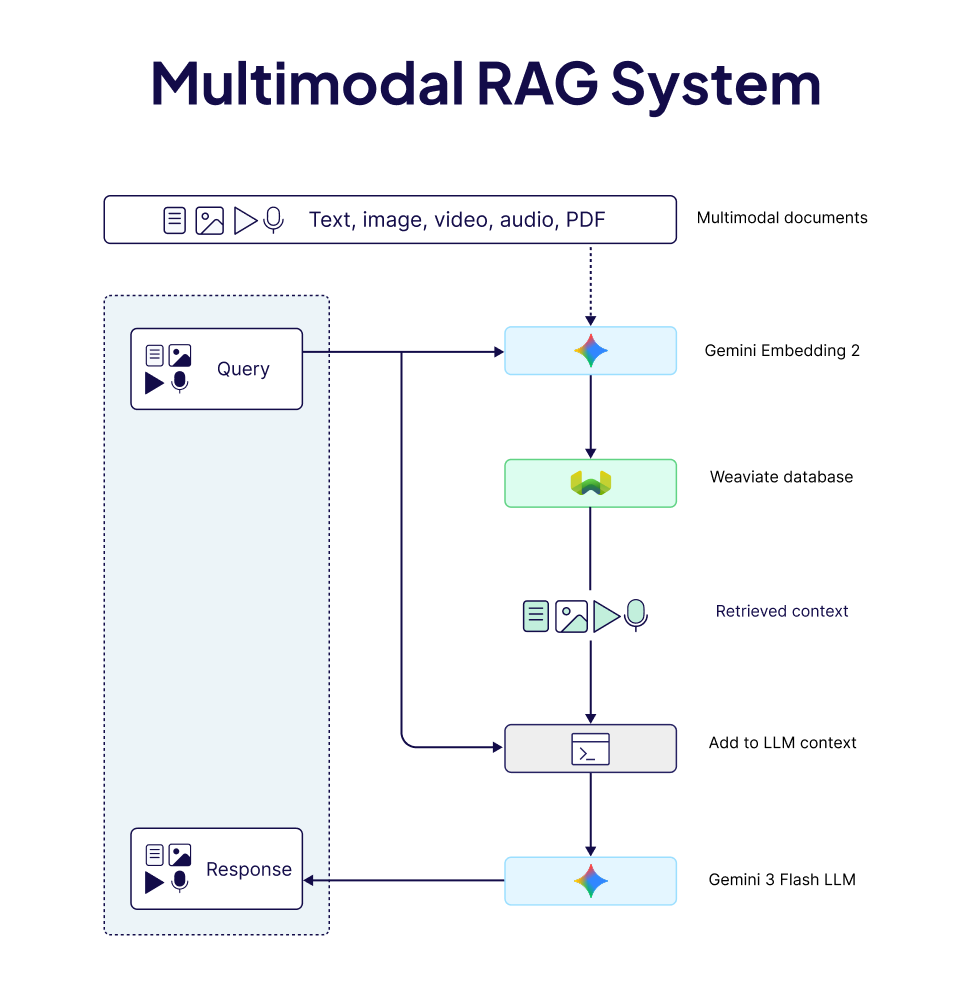
多模态Embedding改变了这个游戏规则:把文本、图像、音频、视频直接映射到同一个向量空间,不用转文字,直接检索。


Part.1
什么是Embedding,为什么要提多模态
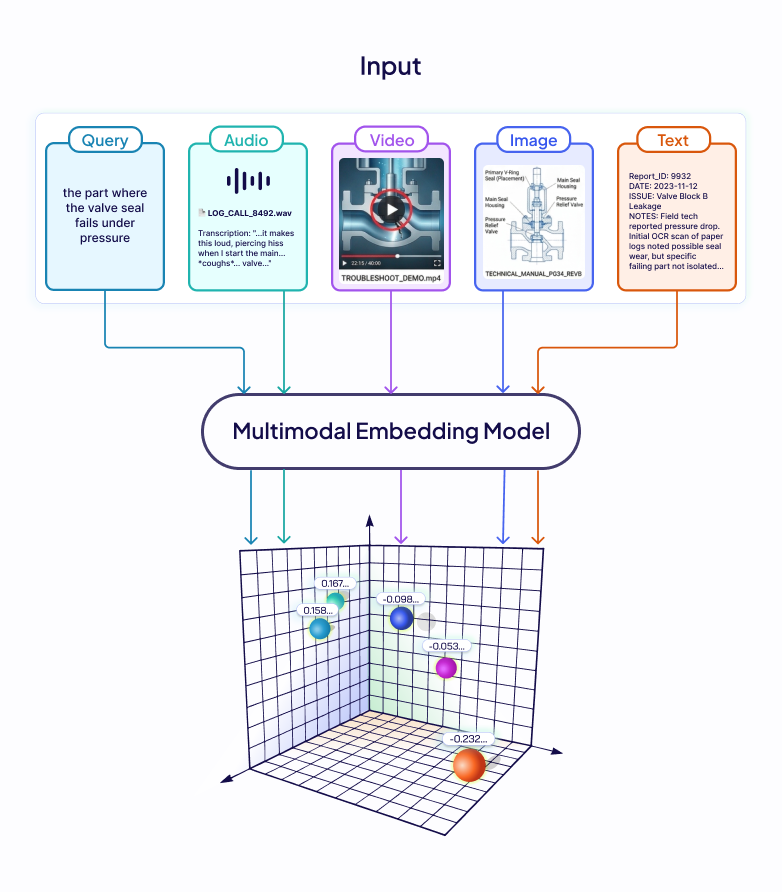
Embedding(向量化)是把数据编码成高维向量的技术。语义相近的内容,在向量空间里距离也相近。

传统Embedding有个根本局限:
- 文本Embedding只能理解文字
- 音频和视频必须先转成文字才能检索
- 转换过程中,情感、语气、视觉信息大量丢失
多模态Embedding的突破在于:
- 让文本、图像、音频、视频讲同一种语言
- 映射到统一向量空间
- 直接实现跨模态检索


Part.2
模型是如何对齐不同模态的
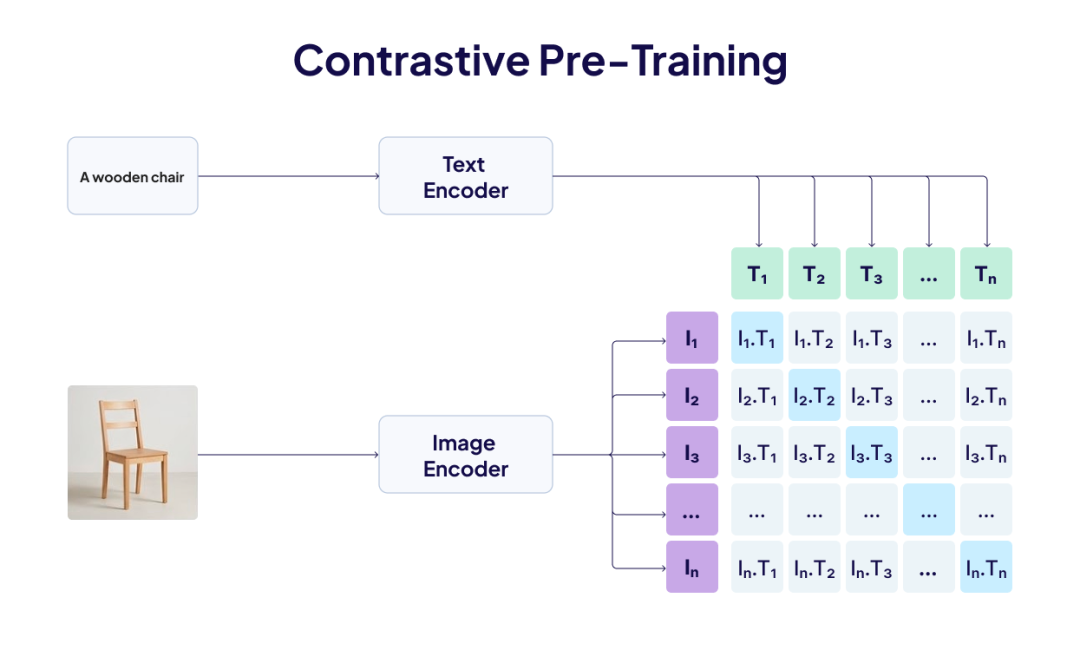
关键技术叫对比学习(Contrastive Learning)。训练时,把匹配的图文对或音视频对的向量拉近,把不匹配的推远。通过海量配对数据训练,模型学会了将不同模态映射到统一空间。
几个里程碑式的模型值得注意。
- CLIP由OpenAI在2021年发布,用400M图文对训练,奠定了图像-文本对齐的基础。
- ImageBind来自Meta在2023年的工作,扩展到6种模态,无需为每种组合单独配对。
这里有个核心挑战来自NeurIPS 2022的一篇论文:不同模态的向量空间无法100%对齐,这就是模态对齐不完美问题。解决方案是从零开始联合训练所有模态,而非逐个对齐。


Part.3
三个实战案例
下面展示三种已经在生产环境验证过的多模态RAG架构。
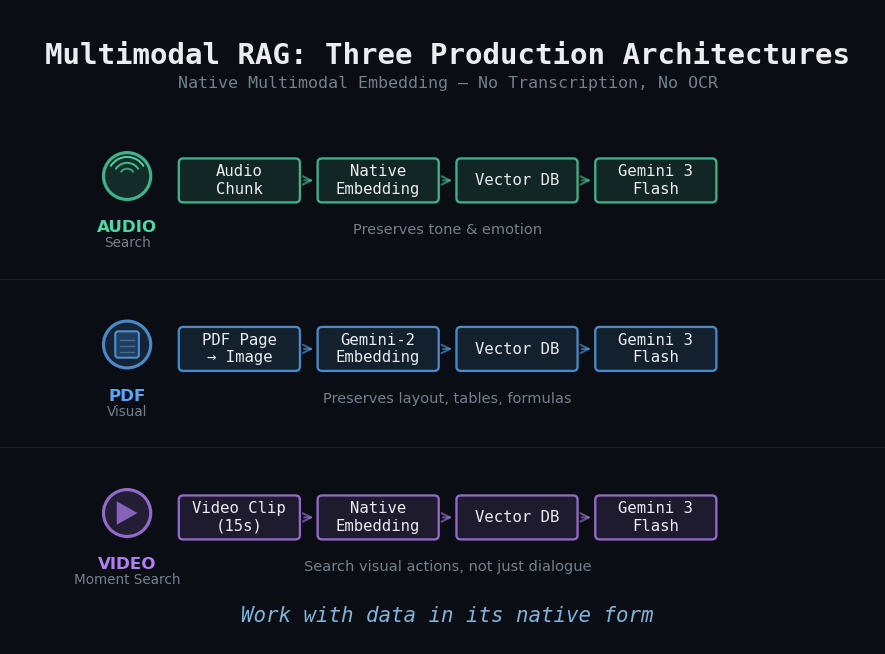
案例1:音频搜索
用户想搜索播客里有在冰雪重压下弯曲这种感觉的音频片段,这本身是一个很难用文字描述的需求,但用音频的原生特征就能直接检索到。
关键设计:
- 音频切成重叠的片段
- 直接用音频本身的Embedding,不转文字
- 召回的音频片段直接传给Gemini Flash生成答案
这种方案的核心优势是保留了音频的音色、语气、情绪这些转录无法捕捉的信息。
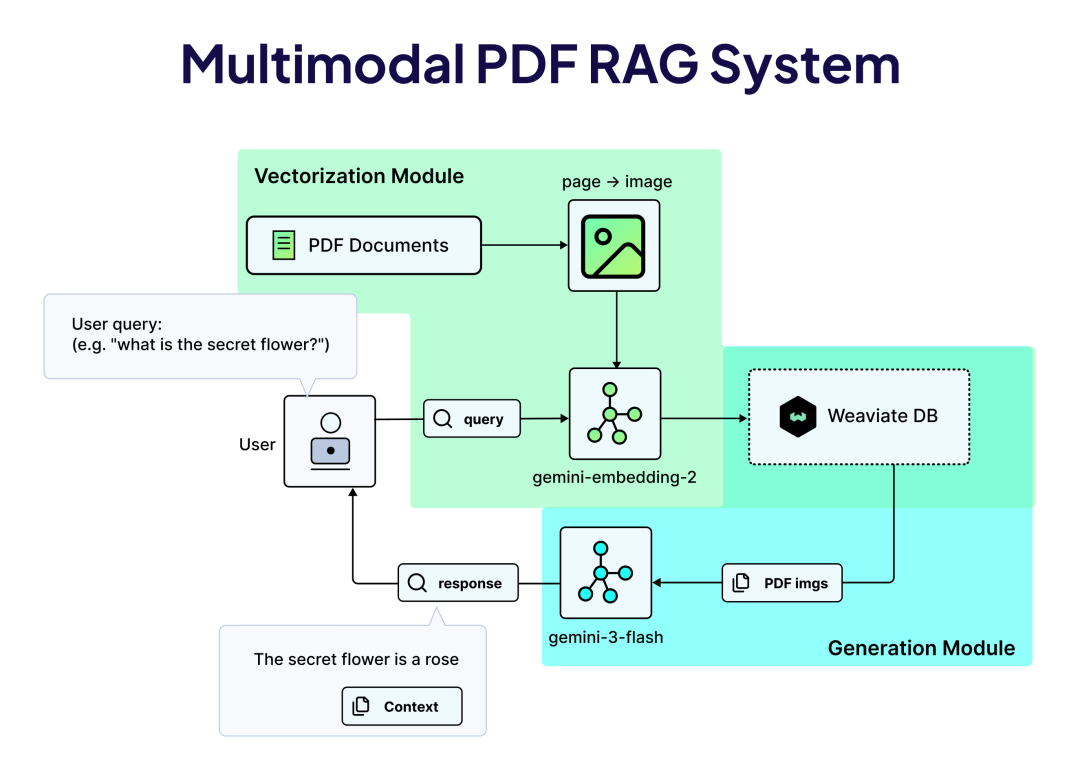
案例2:PDF作为视觉文档
技术文档、论文、表格密集的PDF,直接看比转文字更准确。因为版式本身承载了重要信息:标题和正文的层级关系、表格的行列结构、图表的位置分布。
关键设计:
- PDF页面直接转成图片
- 保留布局、字体、图表、公式
- 使用Gemini Embedding 2的原生多模态能力直接处理图片
案例3:视频时刻搜索
用户想搜索视频里某个动作或某个画面,而不是搜索台词。比如找一下这个角色跳起来的那个镜头,或者那场在海边的日落戏。
关键设计:
- 视频切成15秒重叠片段
- 直接提取视觉特征做Embedding
- 支持以视频搜视频的场景,用户给一段参考视频,系统找到内容、风格或情绪相似的片段


Part.4
什么时候该用多模态Embedding
适合的场景:
- 音频的情感/语气是核心信息,如播客、语音邮件
- PDF的版式依赖信息很重要,如表格、图表、公式、标注
- 视频需要搜索视觉动作/场景,而不只是对话
- 用户想给我找个感觉像这个的,以例搜例
不适合的场景:
- 纯文本数据,文本Embedding已经够用
- 百万级纯文章库,没有音频、视频、图像


Part.5
设计要点
几个关键决策需要考虑:
- 原生Embedding vs 桥接方案:原生Embedding能保留更多信号,推荐Gemini Embedding 2
- 分块策略:音频和视频用固定时间窗口加重叠,确保检索时能命中关键片段
- 维度与存储:MRL技术可压缩维度而不明显破坏效果,适合存储成本敏感的场景
- 检索后生成:把原始媒体直接给生成模型,不要先转文字
核心原则:用数据最原生、最原始的形态处理它
- 不转录失去语气
- 不OCR破坏版式
- 不描述丢失视觉



原文信息
标题:Multimodal Embeddings and RAG: A Practical Guide
链接:https://weaviate.io/blog/multimodal-guide
作者:Prajjwal Yadav
来源:Weaviate Blog


术语解释
- Embedding(向量化):把文字、图像、音频等数据转换成高维向量,让语义相似的内容在向量空间里距离也相近
- 向量空间:高维向量所在的空间,相似内容在该空间中距离更近,是语义检索的基础
- 向量数据库:专门存储高维向量并支持相似度检索的数据库,如Weaviate、Milvus等
- 多模态Embedding:支持多种数据模态同时映射到同一个向量空间,实现跨模态检索
- 原生Embedding:从一开始就用多模态数据联合训练的模型,信号保留完整,如Gemini Embedding 2
- 桥接方案:用多个单模态模型分别处理不同模态,再通过某种方式对齐,过程中会有信息损失
- RAG(检索增强生成):先从向量数据库检索相关内容,再交给大语言模型生成答案
- 对比学习(Contrastive Learning):匹配的图文对或音视频对被拉近,不匹配的被推远,从而学会跨模态对应关系
- CLIP:OpenAI 2021年发布的图文对齐模型,400M图文对训练,多模态Embedding领域的基础模型
- ImageBind:Meta 2023年发布的模型,将6种模态映射到统一向量空间,无需为每种组合单独训练
- 模态锥不完美重叠:NeurIPS 2022论文指出的问题,不同模态的向量空间无法100%完美对齐,也被称为模态对齐不完美
- MRL (Matryoshka Representation Learning):降维技术,类似俄罗斯套娃,可选择不同维度节省存储
- Chunking(分块):将长文本、音频或视频切分成固定大小的片段,音频和视频使用带重叠的时间窗口
01
什么是AI大模型应用开发工程师?
如果说AI大模型是蕴藏着巨大能量的“后台超级能力”,那么AI大模型应用开发工程师就是将这种能量转化为实用工具的执行者。
AI大模型应用开发工程师是基于AI大模型,设计开发落地业务的应用工程师。
这个职业的核心价值,在于打破技术与用户之间的壁垒,把普通人难以理解的算法逻辑、模型参数,转化为人人都能轻松操作的产品形态。
无论是日常写作时用到的AI文案生成器、修图软件里的智能美化功能,还是办公场景中的自动记账工具、会议记录用的语音转文字APP,这些看似简单的应用背后,都是应用开发工程师在默默搭建技术与需求之间的桥梁。
他们不追求创造全新的大模型,而是专注于让已有的大模型“听懂”业务需求,“学会”解决具体问题,最终形成可落地、可使用的产品。
CSDN粉丝独家福利
给大家整理了一份AI大模型全套学习资料,这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】

02
AI大模型应用开发工程师的核心职责
需求分析与拆解是工作的起点,也是确保开发不偏离方向的关键。
应用开发工程师需要直接对接业务方,深入理解其核心诉求——不仅要明确“要做什么”,更要厘清“为什么要做”以及“做到什么程度算合格”。
在此基础上,他们会将模糊的业务需求拆解为具体的技术任务,明确每个环节的执行标准,并评估技术实现的可行性,同时定义清晰的核心指标,为后续开发、测试提供依据。
这一步就像建筑前的图纸设计,若出现偏差,后续所有工作都可能白费。
技术选型与适配是衔接需求与开发的核心环节。
工程师需要根据业务场景的特点,选择合适的基础大模型、开发框架和工具——不同的业务对模型的响应速度、精度、成本要求不同,选型的合理性直接影响最终产品的表现。
同时,他们还要对行业相关数据进行预处理,通过提示词工程优化模型输出,或在必要时进行轻量化微调,让基础模型更好地适配具体业务。
此外,设计合理的上下文管理规则确保模型理解连贯需求,建立敏感信息过滤机制保障数据安全,也是这一环节的重要内容。
应用开发与对接则是将方案转化为产品的实操阶段。
工程师会利用选定的开发框架构建应用的核心功能,同时联动各类外部系统——比如将AI模型与企业现有的客户管理系统、数据存储系统打通,确保数据流转顺畅。
在这一过程中,他们还需要配合设计团队打磨前端交互界面,让技术功能以简洁易懂的方式呈现给用户,实现从技术方案到产品形态的转化。
测试与优化是保障产品质量的关键步骤。
工程师会开展全面的功能测试,找出并修复开发过程中出现的漏洞,同时针对模型的响应速度、稳定性等性能指标进行优化。
安全合规性也是测试的重点,需要确保应用符合数据保护、隐私安全等相关规定。
此外,他们还会收集用户反馈,通过调整模型参数、优化提示词等方式持续提升产品体验,让应用更贴合用户实际使用需求。
部署运维与迭代则贯穿产品的整个生命周期。
工程师会通过云服务器或私有服务器将应用部署上线,并实时监控运行状态,及时处理突发故障,确保应用稳定运行。
随着业务需求的变化,他们还需要对应用功能进行迭代更新,同时编写完善的开发文档和使用手册,为后续的维护和交接提供支持。
03
薪资情况与职业价值
市场对这一职业的高度认可,直接体现在薪资待遇上。
据猎聘最新在招岗位数据显示,AI大模型应用开发工程师的月薪最高可达60k。
在AI技术加速落地的当下,这种“技术+业务”的复合型能力尤为稀缺,让该职业成为当下极具吸引力的就业选择。
AI大模型应用开发工程师是AI技术落地的关键桥梁。
他们用专业能力将抽象的技术转化为具体的产品,让大模型的价值真正渗透到各行各业。
随着AI场景化应用的不断深化,这一职业的重要性将更加凸显,也必将吸引更多人才投身其中,推动AI技术更好地服务于社会发展。
CSDN粉丝独家福利
给大家整理了一份AI大模型全套学习资料,这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献145条内容
已为社区贡献145条内容

所有评论(0)