(三)深度拆解 OpenDriveVLA 推理数据加载:基于__getitem__()方法获取单帧数据
前言
搭建环境和加载预训练模型,请参考笔者之前的博客:
《OpenDriveVLA 环境部署与推理实践》
《OpenDriveVLA模型加载深度解析(推理阶段)》
在 OpenDriveVLA 项目中,推理阶段的输入数据由 PyTorch Dataset.__getitem__() 接口返回。单帧数据中不仅包括多模态感知数据,还包括经标准化封装、可直接送入大语言模型的文本序列。很多开发者在复现或调试时,常对 question 与 prompt_question 的关系、ChatML 格式的必要性感到困惑。
本文中,笔者结合代码的调试输出,并参考了论文原文,逐层拆解__getitem__() 返回的数据结构,还原从驾驶场景信息到模型输入 input_ids 的完整处理流程,帮助开发者彻底理清 OpenDriveVLA 推理数据加载的底层逻辑。
一、单帧数据结构:__getitem__() 到底返回了什么?
通过调试打印单帧数据,可观测到单帧数据包括如下四个字段:
dict_keys(['uniad_data', 'id', 'question', 'input_ids'])
Tab. 1:单帧数据字段概览
| 字段名 | 数据类型 | 作用 |
|---|---|---|
| uniad_data | dict | 视觉感知数据:封装多视角图像、坐标变换、自车状态及训练真值 |
| id | str | 数据溯源标识:用于样本追踪与调试日志关联 |
| question | str | 原始任务语义:结构化驾驶任务描述文本 |
| input_ids | torch.Tensor | 模型直读输入:经 Tokenizer 编码后的数字序列张量,直接送入 LLM |
从架构上看,单帧数据明确划分为视觉感知数据与语言任务数据,分别驱动模型的视觉特征提取与语言逻辑推理。
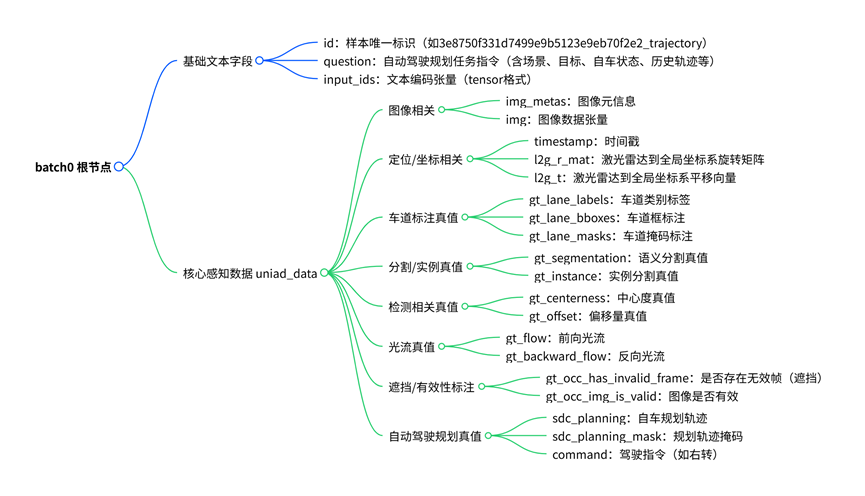
二、 视觉感知数据:uniad_data
OpenDriveVLA 复用了 UniAD 的数据组织范式,所有环境与自车感知数据均封装于 uniad_data 中。其包含以下字段:
dict_keys(['img_metas', 'img', 'timestamp', 'l2g_r_mat', 'l2g_t', 'gt_lane_labels', 'gt_lane_bboxes',
'gt_lane_masks', 'gt_segmentation', 'gt_instance', 'gt_centerness', 'gt_offset', 'gt_flow', 'gt_backward_flow',
'gt_occ_has_invalid_frame', 'gt_occ_img_is_valid', 'sdc_planning', 'sdc_planning_mask', 'command'])
按功能可划分为四类,实现对驾驶场景的完整建模:
- 图像与预处理元数据: img 为多视角周视图像;img_metas 记录缩放、填充、归一化等预处理参数,供视觉编码器对齐特征。
- 坐标系与时序基准: l2g_r_mat(局部→全局旋转矩阵)与 l2g_t(平移向量)构成刚体变换参数;timestamp 提供时间戳。二者共同用于多帧时序特征在全局坐标系下的时序融合。
- 训练真值(GT): 包含车道、语义分割、实例分割、光流等任务的标注数据。仅在训练阶段参与 Loss 计算,推理阶段不参与前向传播。
- 自车规划与指令: sdc_planning 是未来 3 秒规划轨迹真值(6 个 Waypoint,每 0.5s 一个);command 为高层导航指令(如 turn right),作为轨迹规划的核心约束条件。
三、 语言任务核心:从原始 question 到 ChatML 封装
3.1 原始 question 的语义结构设计
原始 question 封装了当前驾驶任务的全量语义:
'Scene information: <scene_start><SCENE><scene_end>\n'
'Object-wise tracking information: <track_start><TRACK><track_end>\n'
'Map information: <map_start><MAP><map_end>\n'
'Ego states: - Velocity (vx,vy): (-0.02,4.26) ... \n'
'Historical trajectory (last 2 seconds): [(-0.30,-17.01),...] \n'
'Mission goal: turn right\n'
'Planning trajectory: <trajectory>'
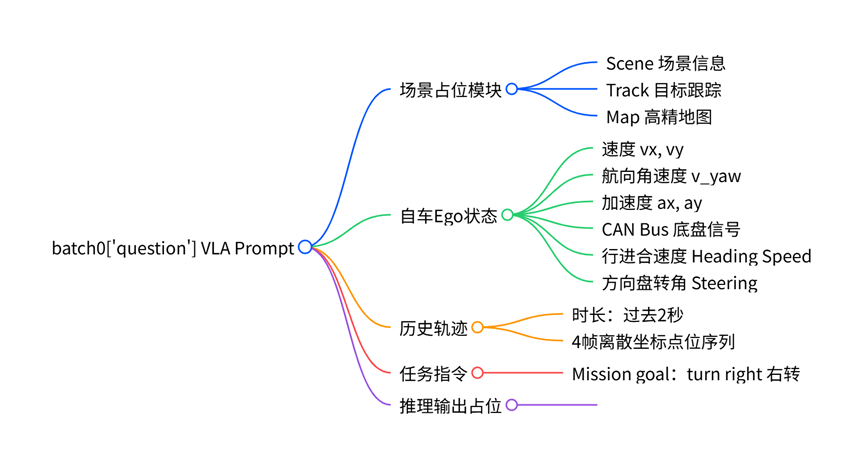
具体来说,原始 question是当前驾驶任务的任务描述,是一种结构化的语义载体,通过纯文本序列统一表征多源驾驶上下文,主要包含三类信息:
- 驾驶场景描述:采用 <scene_start>…<scene_end>、<track_start>…<track_end>、<map_start>…<map_end> 等显式占位符,分别锚定场景全局特征、动态物体跟踪序列与高精地图拓扑。在 Token 化阶段,这些边界标记作为多模态特征与语言指令的对齐锚点,确保视觉场景、动态轨迹与地图信息在 LLM 输入序列中的精准定位与解析。
- 自车运动学状态:包含速度、航向角速度、加速度等动力学参数及当前转向指令。作为轨迹生成的物理先验约束,结合系统提示词规范,可有效引导模型生成符合运动学规律的序列。
- 历史轨迹与导航指令:串联过去 2 秒(共 4 帧)的自车位姿序列以建模短期运动趋势,同时注入高阶导航指令(如直行、右转等),为轨迹规划提供方向性约束。
3.2 ChatML 封装逻辑
为适配 Qwen-VL 架构的对话式推理范式,原始任务描述需封装为标准 ChatML 格式,以显式划分角色边界与上下文范围。封装后的完整结构如下:
<|im_start|>system
You are Open-DriveVLA... [系统设定、坐标系规则、任务约束、输出格式要求]
<|im_end|>
<|im_start|>user
[此处完整嵌入原始 question]
<|im_end|>
<|im_start|>assistant
System 段: 定义模型角色、坐标系约定、输出格式模板与安全约束,全程约束生成行为。
User 段: 承载当前驾驶任务的具体语义,即前述结构化任务描述。
Assistant 前缀: 标记模型输出起点,引导 LLM 沿既定格式续写轨迹序列。实际推理时,该前缀将直接触发自回归生成,直至输出完整轨迹或遇到结束标记。
封装后的完整Prompt文本中,question 仅指 User 段的任务内容,而 Prompt 涵盖 System、User 及 Assistant 前缀的整体上下文。这种封装方式既保留了多模态对齐的结构化语义,又严格遵循了大模型的对话协议,确保轨迹生成过程可控、可解析。
四、 模型直读输入:Tokenization 与 input_ids 生成机制
ChatML 封装后的 完整 Prompt 文本 仍为人类可读的自然语言序列,而大语言模型(含 Qwen-VL 架构)的底层计算单元仅能处理离散的数字表示。因此,该文本需经过 Tokenization(分词) 流程,转换为模型可执行的数值张量。
4.1 转换代码实现
# Convert text to IDs
input_ids = tokenizer_uniad_token(
prompt_question, self.tokenizer, return_tensors='pt'
).unsqueeze(0).to(self.device)
4.2 input_ids 张量结构与 Tokenizer 映射机制
input_ids是 ChatML 文本序列经分词后映射至模型词表的整数张量,其形状为 torch.Size([1, 472]),维度含义如下:
| 维度 | 尺寸 | 含义 |
|---|---|---|
| Dim 0 | 1 | Batch Size,推理阶段采用单样本逐帧处理 |
| Dim 1 | 472 | Sequence Length,即 prompt_question 经 Byte-level BPE 分词后的子词单元(Subword)数量 |
🔧 Tokenizer 配置与特殊扩展
OpenDriveVLA 通过 Hugging Face transformers.AutoTokenizer 加载分词器,需严格保证 分词器与模型权重版本一致,避免输入分布偏移。分词过程会注入 Qwen 原生的Token(如 <|im_start|>, <|im_end|> 等),以及OpenDriveVLA 专属扩展的特殊Token。Tokenizer 的具体词表配置、特殊 Token 映射逻辑,可参考笔者博文《OpenDriveVLA模型加载深度解析(推理阶段)》2.1.1小节的描述。
五、 推理数据加载的完整流程
OpenDriveVLA推理数据加载过程中,三个关键的变量如下:
| 变量名 | 本质 | 开发用途 |
|---|---|---|
| question | 原始任务文本(干净、无格式) | 日志打印、语义核对、Prompt 模板调试 |
| prompt_question | ChatML 封装后的完整对话文本 | 实际送入 Tokenizer 的文本输入 |
| input_ids | Token 化后的数字张量 | 大模型真正的直接输入 |
推理数据加载流程:
多模态原始数据 + 任务文本 → 提取 question → 拼接 System Prompt 转 ChatML → Tokenizer 编码 → input_ids → 送入 LLM,请参照下图: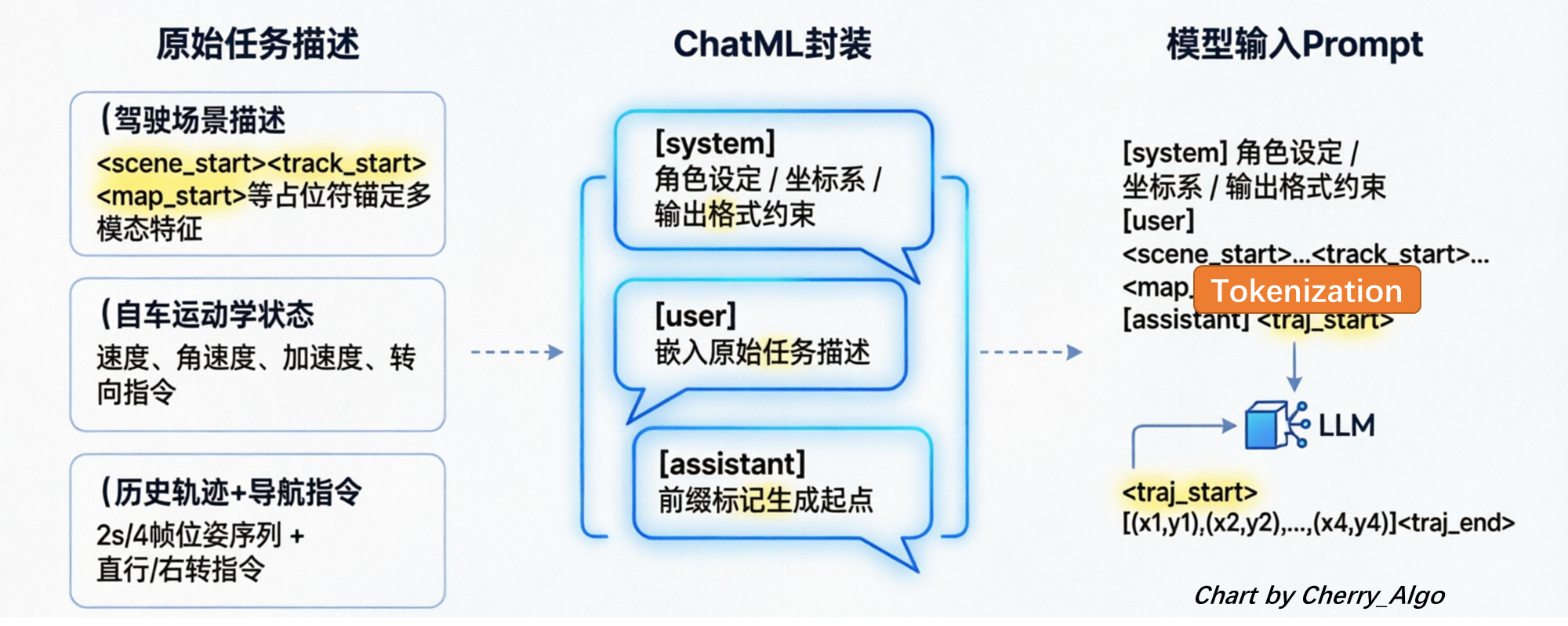
理清这一数据pipeline后,开发者可快速定位数据对齐错误、格式拼接遗漏或 Token 长度异常等问题。希望本文能为你复现 OpenDriveVLA 或自定义 Driving VLA 任务提供清晰的数据视角。如有疑问,欢迎在评论区交流。
(本文为CSDN原创,转载请注明出处。)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)