AIConfigurator: Lightning-Fast Configuration Optimization for Multi-FrameworkLLM Serving
Abstract
优化生产系统中的大语言模型(LLM)推理正变得越来越困难,因为实际负载具有动态变化性,系统又需要满足严格的延迟与吞吐目标,同时可选配置空间也在快速扩大。这种复杂性不仅体现在分布式并行策略上,例如张量并行、流水线并行和专家并行【distributed parallelism strategies (tensor/pipeline/expert)】,也体现在复杂的框架特定运行时参数上。这些运行时参数包括是否启用 CUDA Graph、可用于 KV cache 的显存比例,以及最大 token 容量等,它们都会显著影响推理性能。
现代推理框架种类繁多,例如 TRT-LLM、vLLM 和 SGLang。这些框架各自采用不同的 kernel 和执行策略,使得人工调参不仅高度依赖具体框架,而且在计算成本上也难以承受。我们提出 AIConfigurator,这是一个统一的性能建模系统,能够在不需要 GPU 实测 profiling 的情况下,快速进行与框架无关的推理配置搜索。
AIConfigurator 结合了三部分内容。第一,它提出了一种方法,将推理过程分解为可解析建模的基本原语,包括 GEMM、attention、communication 和 memory operations,同时还能捕捉框架特定的调度动态。第二,它构建了一个经过校准的 kernel 级性能数据库,覆盖多种硬件平台以及流行的开源权重模型,包括 GPT-OSS、Qwen、DeepSeek、LLaMA 和 Mistral。第三,它提供了一个抽象层,能够自动为目标后端解析最优启动参数,并无缝集成到生产级编排系统中。
在生产级 LLM serving 负载上的评估表明,AIConfigurator 能够找到更优的 serving 配置。对于 dense 模型,例如 Qwen3-32B,它最高可以带来 40% 的性能提升。对于 MoE 架构,例如 DeepSeek-V3,它最高可以带来 50% 的性能提升。同时,它平均能在 30 秒内完成搜索。这使得系统能够快速探索巨大的设计空间,从集群拓扑一直到具体推理引擎的特定启动参数。
1 Introduction
大语言模型(LLM)的快速发展,对计算基础设施提出了前所未有的需求。随着最先进模型的参数规模从数亿增长到数千亿,推理部署效率已经成为决定其经济可行性的关键因素。然而,优化这些部署过程充满了复杂性。
服务提供商必须面对配置参数的组合爆炸,这些参数从张量并行、流水线并行和专家并行策略,到 batch size 和量化等细粒度设置不等。传统性能调优通常依赖人工 benchmark 和穷举测试,但这种方式正变得越来越难以为继。随着现代 GPU 成本不断上升,人工穷举测试的成本已经高到难以承受。
这些方法需要大量工程投入才能收敛到某个方案,而这些方案往往仍然不是最优的,导致大量性能潜力没有被充分挖掘。Disaggregated serving(解耦式服务)[19, 28] 的出现进一步加剧了这种复杂性,它将 prefill 阶段和 decode 阶段分配到不同的计算资源上执行。
虽然解耦式服务有望优化 “Goodput”(严格延迟约束下的吞吐量),但它并不是一个普遍更优的方案;其收益高度依赖模型架构、硬件拓扑和网络带宽之间的相互作用。实践者面临一个困难的权衡:对于某个具体 workload 来说,解耦带来的调度灵活性是否能够抵消额外的通信开销?
此外,为了让这类系统满足严格的服务等级协议(SLA),尤其是 Time-To-First-Token(TTFT)和 Time-Per-Output-Token(TPOT)约束,所形成的设计空间很容易超过 10,000 种排列组合。除了架构层面的决策之外,推理引擎自身的复杂性也进一步加重了问题。现代框架,例如 TensorRT-LLM [2]、vLLM [13] 和 SGLang [27],暴露了大量可调的运行时参数,例如是否启用 CUDA Graph、可用 KV-cache 显存比例,以及最大 token 容量等,而这些参数都会显著影响性能。某个能够最大化特定 workload 吞吐量的配置,随着 serving 环境变化,往往会变得脆弱或低效。
因此,开发者经常会放弃调优过程,转而使用保守的默认配置,从而使大量性能潜力没有被释放。虽然 Vizier [11] 这类黑盒优化方法,或 Morphling [23] 这类自动化 serving 框架,可以加速寻找最优配置的过程,但它们仍然需要为每个具体场景消耗大量 GPU 时间才能收敛到一个解。
为了解决这些挑战,我们提出了 AIConfigurator,这是一个专门用于在多种推理框架中优化 LLM 推理的工具包。不同于依赖理论抽象的通用模拟器,AIConfigurator 采用一种基于 operation-level 性能建模的数据驱动方法。通过将推理过程分解为基础 kernel,例如 GEMM 计算、attention 机制和通信原语(如 all-reduce、P2P),并利用真实系统数据进行插值,该工具包能够针对 NVIDIA 平台(Ampere、Ada、Hopper 和 Blackwell)给出高保真的性能估计。
我们的贡献包括:
- 设计了一个能够在复杂推理配置空间中进行搜索的系统,并能在数秒内以高精度识别最优配置。
- 通过与主流推理框架的无缝集成展示了系统的有效性,这些框架包括 vLLM、SGLang、TRTLLM 和 NVIDIA 的 Dynamo,并能够给出可执行、可用于生产环境的推荐配置。
- 通过与真实芯片上的 ground-truth 数据进行 benchmark,对系统进行了全面评估。
2 Background
2.1 LLM Inference Optimization
LLM 推理优化包含三个相互依赖的支柱。
高级调度技术,包括 continuous batching [24]、PagedAttention [13]、chunked prefills [5] 和 disaggregated serving [28],通过针对 prefill 阶段(计算受限)和 decode 阶段(内存受限)不同的计算特征进行优化,最大化硬件利用率。模型并行通过 Tensor Parallelism(TP)[21]、Pipeline Parallelism(PP)[12],以及面向 MoE 架构的 Expert Parallelism(EP)[16],将大模型分布到多张 GPU 上。
配置调优需要在由此产生的组合空间中进行搜索;虽然 Vidur [4] 和 APEX [15] 这类模拟器能够支持快速探索,但它们依赖理论 roofline 模型,因此往往会与生产环境中的真实性能产生偏差。
2.2 聚合式服务与解耦式服务
Disaggregated serving(解耦式服务)[19, 28] 将 prefill 和 decode 分离到不同的 GPU 池上,从而支持二者独立扩展,但也引入了 KV-cache 传输开销。Splitwise [18] 表明,对于短上下文场景,这种传输开销可能会抵消解耦带来的收益。
最优架构取决于 workload 组成(prefill-heavy 还是 decode-heavy)、互连带宽以及集群规模;对于较小规模的部署,结合 chunked prefills 的 aggregated serving(聚合式服务)通常会优于 disaggregated serving。这种复杂性正是 AIConfigurator 的动机所在:它同时建模这两种架构,以识别最优配置。
3 Motivation
像“节点内使用 TP,节点间使用 PP”这样的传统经验法则,无法捕捉计算能力与网络带宽之间的非线性相互作用。研究 [17, 26] 表明,自动化搜索在成本效率上可以比人工调优高出 2 倍以上。
框架异构性。Framework Heterogeneity.
生产环境中的推理会涉及多种具有不同性能特征的框架:vLLM [13](PagedAttention、基于 Python 的调度)、SGLang [27](RadixAttention、Triton kernels)、TensorRT-LLM [2](静态图优化、自定义 kernels),以及 NVIDIA Dynamo [1](与后端无关的编排)。每个框架都会表现出独特的性能断崖,这些断崖由大量框架特定的运行时参数控制,而通用模型无法有效捕捉这些现象。
配置调优缺口。Configuration Tuning Gap.
当前方法,例如 nightly benchmarks [20] 和人工整理的配置方案 [3],本质上是静态查找表,难以满足动态生产环境的需求。AIConfigurator 提供了一种算法化搜索方法,能够在由并行策略、batch size 和 serving 架构组成的多维空间中,识别满足 SLA 要求的配置。
SLA 是 Service Level Agreement,中文一般叫 服务等级协议。
在 LLM serving 里,它指的是系统必须满足的服务质量约束,比如:
TTFT ≤ 1 秒
用户发出请求后,首个 token 必须在 1 秒内出来。TPOT ≤ 50 ms/token
生成每个后续 token 的平均时间不能超过 50 毫秒。吞吐量 ≥ 多少 tokens/s/GPU
每张 GPU 每秒至少要处理多少 token。可用性 ≥ 99.9%
服务不能频繁宕机。放到这篇 AIConfigurator 论文里,SLA 主要指 推理延迟和吞吐约束,尤其是:
TTFT:Time To First Token
从用户提交 prompt 到模型吐出第一个 token 的时间。TPOT:Time Per Output Token
生成阶段每输出一个 token 平均花费的时间。所以一句话就是:
SLA = 你部署 LLM 服务时必须保证的性能底线。
比如论文里可能会设定:
TTFT ≤ 1200 ms,并且 generation speed ≥ 60 tokens/s/user
这就表示:首 token 延迟不能超过 1.2 秒,而且每个用户的生成速度至少要达到每秒 60 个 token。
4 Design and Implementation
AIConfigurator 采用一种有原则的数据驱动方法,来探索庞大的 LLM 推理配置空间。该系统并不依赖理论性的 roofline 模型或穷举式 benchmark,而是将推理过程分解为基础操作,收集这些基本原语在真实硬件上的测量数据,并通过一个定义清晰的性能模型组合得到端到端性能估计。
该工具包通过统一的后端抽象支持多个推理框架。
每个后端(TensorRT-LLM、SGLang、vLLM)都会实现与框架相关的逻辑,包括显存估计、aggregated serving 模拟和基于约束的优化,同时共享通用的 operation modeling 基础设施。本节将介绍 AIConfigurator 的架构、核心机制和实现细节。
4.1 Workflow of AIConfigurator
图 1 展示了在 64 张 H200 GPU 上部署 Qwen-235B 模型时,两种 serving 模式——aggregated 和 disaggregated——之间的 Pareto 曲线对比。这体现了 AIConfigurator 模拟结果中的一个关键洞察。
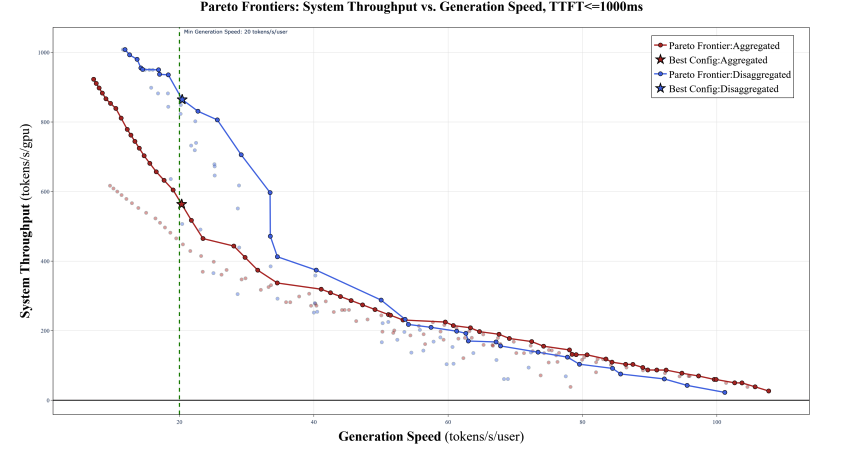
横轴表示 generation speed,也就是每个用户请求每秒生成的 token 数;纵轴表示 system throughput,也就是每张 GPU 每秒生成的 token 数。每个点都表示一种满足 TTFT 约束的 serving 配置。最优配置指的是:在满足目标 generation speed 的同时,实现最高 system throughput 的配置。
例如,当输入序列长度为 4096、输出长度为 1024 时,如果要求每个用户至少达到 20 tokens/s,那么图中带星号的配置就是最优配置,因为它们在超过该速度阈值的同时,最大化了每张 GPU 的吞吐量。值得注意的是,在这个场景下 disaggregated serving 更优:在相同速度约束下,它的最佳配置达到 823 tokens/s/GPU,比最佳 aggregated 配置的 564 tokens/s/GPU 高出约 53%。
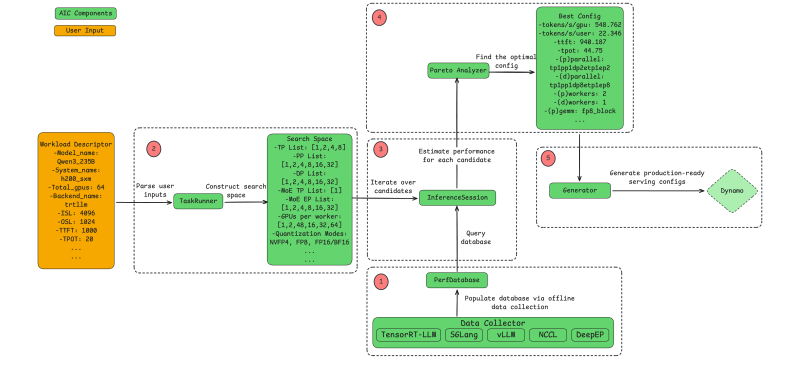
Figure 2: Key components of AIConfigurator and the general workflow of finding the optimal configuration.
总结来说,AIConfigurator 会识别出在满足特定 SLA 目标的同时最大化 system throughput 的最优 serving 配置,例如 TTFT < 1 秒、generation speed > 20 tokens/s/user。图 2 描述了使用 AIConfigurator 的整体工作流,通常包括五个步骤,每个步骤都围绕 AIConfigurator 的一个关键组件展开:
PerfDatabase:首先,系统会执行一个离线数据收集过程,构建一个数据库,其中包含在不同指定硬件平台上,大量常用 LLM operators 的完整性能数据。在这个过程中,每个受支持的推理框架都会被独立处理。
第二步,TaskRunner 会根据用户提供的 workload descriptor 构建搜索空间,该搜索空间由所有合法的候选 serving 配置组成;workload descriptor 中会包含用户期望的环境设置、SLA,以及请求相关的具体特征等信息。
InferenceSession:随后,InferenceSession 会遍历所有候选 serving 配置;对于每一个候选配置,它会结合 iteration-level 建模,以及直接从 PerfDatabase 查询到的 operator-level 性能数据,来估计关键性能指标。
Pareto Analyzer:之后,Pareto analyzer 会根据上一阶段生成的性能预测结果,对所有合法 serving 配置进行筛选和排序,并输出排名靠前的配置以及完整的性能预测信息。
Generator:最后,AIConfigurator 的 generator 模块可以直接将 Pareto analyzer 识别出的 serving 推荐配置,转换为与版本兼容的启动文件,适用于 TensorRT-LLM、vLLM 和 SGLang 中任意一个推理引擎,并自动设置最优 serving 参数,例如 --enable_cuda_graph、--kv_cache_free_gpu_mem_fraction 和 --enable_chunked_context。
像 NVIDIA Dynamo 这样的 serving 框架,也可以直接利用该启动文件来搭建一个经过最优配置的推理服务器。
4.2 Performance Modeling
AIConfigurator 并不是直接估计 system throughput 和 generation speed,而是从一个平均请求的视角出发,在服务器处于稳定并发状态时推导出这两个指标。

TTFT(Time to First Token,首 token 时间)和 TPOT(Time Per Output Token,每个输出 token 的时间)都以毫秒为单位进行度量。OSL(output sequence length,输出序列长度)被视为一个固定值,由用户提供的 workload descriptor 指定。至于 batch size,AIConfigurator 在估计某个 serving 配置的性能时,会遍历一组预先定义好的候选 batch size。为了高效估计 TPOT 和 TTFT,我们首先考虑一个典型请求在推理服务器中被处理的完整生命周期。
在 LLM serving 场景下,任意一个请求都会经历两个不同的处理阶段:prefill/context 阶段会处理完整的用户输入 prompt,在生成第一个输出 token 之前,计算并存储对应的 KV cache。这个阶段通常是计算密集型的,因此一般会使用类似 FlashAttention [8] 的 fused multi-head attention kernel 来加速 attention 计算。此外,也可以使用 context chunking [5],将长输入 prompt 的 prefill 拆分成多个 iteration step。decode/generation 阶段会以逐步自回归的方式,一次生成一个剩余的输出 token。
新生成的 token 会作为下一步的输入,而缓存下来的 key-value pairs 会被用来避免重复计算历史 token 的 key-value pairs。这个阶段通常是内存密集型的,因此会使用类似 XQA [2] 的专用 kernel。虽然 prefill 和 decode 构成了 LLM 推理的基本计算阶段,但真实世界中的性能很大程度上取决于 serving engine 如何调度和编排它们。
一个简单粗糙的抽象不足以捕捉不同调度策略之间的细微差别。因此,AIConfigurator 显式建模了三种不同的 serving 模式:Static、Aggregated 和 Disaggregated;它们分别以不同方式处理资源竞争和阶段交错执行。我们首先定义 static mode 下的基准行为。
4.2.1 Static Mode
在 static serving mode 中,如图 3(A) 所示,workload 会以严格顺序的方式处理,并且 batch size 是固定的。在这种模式下,TTFT 等同于 prefill 阶段的延迟。TPOT 则通过对生成完整输出序列所需的后续 decode steps 的延迟取平均来近似得到。Algorithm 1 概述了计算这些指标的过程。
它采用了一种基于 stride 的优化方法(Step 13),通过在若干区间上插值估计成本,而不是为每一个 token step 都查询数据库,从而降低估计 generation latency 的计算开销。
4.2.2 Aggregated Mode
这种 serving mode 也被称为 inflight batching 或 continuous batching [24];如图 3(B) 所示,它的特点是在单次 inference iteration 中,可以混合处理来自不同请求的 prefill steps 和 decode steps。
相比 static serving,这种灵活性显著提高了 GPU 资源利用率,从而带来更高的 system throughput。我们的性能模型在 Algorithm 2 中有详细描述,它通过将执行过程划分为两个不同阶段来近似这种行为:
Mixed Phase:这一阶段表示 continuous batching 系统的稳定运行状态,其中 prefill 请求和 decode 请求会并发执行。调度器会优先利用可用的 context capacity(Cctx)来处理 prefill 请求。
默认情况下,一个 prefill 请求会包含 ISL 个 token;也可以选择启用 context chunking,将完整的 ISL 个 context tokens 拆分成多个 prefill 请求。剩余的 batch slots 会被分配给 decode 任务(Ngenmix)。关键在于,当 prefill workload 较重时,也就是 context processing time 超过 generation time 时,我们的模型(Algorithm 2,第 6–10 行)会使用一种 rate-matching heuristic 来限制并发 decode streams 的数量。
这可以避免一种 “starvation” 场景,即 decode 请求完成得太快,而新的请求还来不及完成 prefill。这一阶段的 step latency(Lmix)主要由计算密集型的 prefill attention 主导。
Generation-Only Phase:这一阶段建模的是 workload 的尾部阶段,或者请求到达率较低、prefill queue 已经被清空的时期。此时系统会转入纯 decode 状态,将所有 batch slots(B)都用于自回归生成。
这里的 step latency(Lgen)明显更低,通常受限于 memory bandwidth,而不是计算能力。我们基于 Mixed Phase 的延迟来估计 TTFT,并引入一个经验校正因子(Fcorr),该因子被建模为一个分段线性函数。这个因子用于刻画基础调度开销(常数项)、随着 context backlog 增长而成比例增加的排队延迟,以及用于反映系统级准入控制的饱和上限。
对于 TPOT,我们使用两个阶段延迟的加权平均值。值得注意的是,在计算权重时,我们会对 mixed phase duration 应用一个小的 offset(3 steps)(Algorithm 2,Step 5)。这个启发式方法可以过滤掉 batch 初始几个 step 中经常出现的调度抖动,从而提供更稳健的 steady-state decoding performance 估计。这种方法无需完整的离散事件模拟,就能建模 prefill 和 decode 操作之间的非线性干扰。
4.2.3 Disaggregated Mode
与 static mode 和 aggregated mode 不同,Disaggregated Mode 使用两个独立的 worker pool,每个 worker pool 专门负责 LLM 推理中的一个特定阶段。
如图 3(C) 所示,进入系统的请求首先由专门的 prefill workers 处理。prefill 阶段完成后,计算得到的 key-value(KV)cache 和中间状态会被传输给 decode workers,由它们以自回归方式生成后续 tokens。这种解耦带来了显著的架构优势:它消除了 prefill 和 decode 之间的相互干扰,并允许每个 worker pool 根据自身 workload 特征采用不同的模型并行策略,从而分别优化计算受限的 prefill 和内存受限的 decode。
已有研究 [28] 表明,这种分离可以显著提升整体系统的 Goodput。从建模角度看,AIConfigurator 分两个阶段估计 disaggregated system 的性能。首先,它会分别搜索 prefill 配置和 decode 配置的搜索空间,将每个候选配置视为一个独立的 static instance,并使用 Algorithm 1 估计其基础延迟。它会对 prefill latency 应用一个校正因子(βTTFT),用于刻画 disaggregated architecture 中固有的 KV-cache 传输开销。
其次,它会通过 rate-matching 过程构建合法的 composite servers,记作 (x)P(y)D,其中 x 和 y 分别表示 prefill instances 和 decode instances 的数量。该算法通过最大化有效的 per-GPU throughput(ThruGPU)来识别最优配置,而 ThruGPU 是由 system rate Rsys 推导得到的:
![]()
其中,R 表示对应 worker pool 的请求处理速率,也就是每秒处理的请求数,并且会受到干扰因子 α 的折减。一旦识别出最优的 (x)P(y)D 配置,系统的 TTFT 就由所选 prefill worker pool 的延迟决定,其中包括传输开销;而 TPOT 则由 decode worker pool 的延迟决定。
Algorithm 3 详细描述了这一优化过程。
4.3 Iteration-level Modeling
到目前为止介绍的三个算法是否有效,取决于我们能否准确预测某个 inference iteration step 的延迟。例如,在 Algorithm 1 中,我们依赖通过 GETSTEPLATENCY(batch_size, seq_len, phase) 获取的 prefill-only step 和 decode-step 的延迟数据来进行后续估计;而在 Algorithm 2 中,除了 decode-only step(GETGENLAT(Ngen, ISL, OSL))之外,我们还必须获得 mixed step(GETMIXLAT(Nctx, Ngen, ISL, OSL))的准确延迟测量,才能继续建模。
因此,为了建立一种快速且鲁棒的方法来估计给定 iteration step 的延迟,AIConfigurator 充分利用了现代 LLM 推理过程可分解的特性。
4.3.1 Decompose Iteration Into Operators 将一次迭代分解为多个算子
由于现代 LLM 由重复堆叠的 transformer layers 组成,因此任意一次 inference iteration step 都可以被建模为:按照固定顺序多次运行一组 operators,而重复次数通常取决于模型拥有的层数。
引入现代并行策略并不会改变这一基本性质,只是会在 iteration 执行路径的固定位置插入一些定义明确的 communication operators,并通过将输入切分到多个计算设备上来缩小 compute operators 的规模。例如,Figure 4 展示了使用 MoE 模型进行推理时,一次典型 inference step 中 operators 的组成。
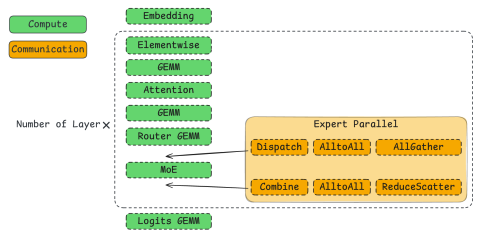
整个 inference step 本质上就是多次运行 4 类 operators,分别是 embedding、GEMM、Attention(根据阶段不同,可以是 prefill attention 或 decode attention)以及 MoE。如果进一步引入 expert parallelism,它会缩小 MoE operator 的规模,同时增加一对 communication operators;具体是哪一对通信算子,则取决于生产环境中使用的 inference engine backend。基于上述观察,在 AIConfigurator 中,我们通过聚合一次 inference iteration step 所包含的各个 operators 的性能 profile,来建模该 iteration step 的延迟。
4.4 Operator Database
AIConfigurator 通过在真实 GPU 硬件上进行离线 profiling 来构建性能数据库,目前支持 TensorRT-LLM、vLLM 和 SGLang。
Database Coverage.数据覆盖
该数据库包括:(1)GEMM 操作,其参数包括维度(M、N、K)以及量化格式(FP16、FP8、INT8、INT4);(2)Attention 操作,覆盖计算受限的 context attention 和内存受限的 generation attention,并支持 MHA [22]、GQA [7] 和 MLA [9];(3)Communication primitives,包括在不同 message size 和 GPU 数量下的 AllReduce、AllGather、AllToAll 以及点对点传输;(4)带有 dispatch/combine [25] 模式的 MoE 操作;以及(5)硬件规格,包括内存带宽、计算吞吐和互连带宽。
Data Collection.数据收集。
我们结合了三种策略:第一,使用框架原生工具对参数进行穷举 profiling,包括 batch size、sequence length 和 hidden dimension;每一组平台-框架组合大约需要 30 GPU-hours;第二,使用已有 profiling 数据点,通过插值估计中间配置的延迟;第三,对于尚未 profiling 的算子,使用 Speed-of-Light estimation,通过 roofline 模型提供解析性的性能边界。
4.4.1 Power Law Correction for MoE
MoE 算子的性能高度依赖 token 分布。已有工作 [10, 14] 表明,在推理过程中,某些 experts 会接收到不成比例地更多 tokens;来自 Qwen3-235B 的观察显示,大约 70% 的计算只由 20% 的活跃 experts 承担。为了刻画这种负载不均衡,AIConfigurator 实现了一种受控 token 分配过程,用来模拟生产环境中观察到的幂律分布(Figure 5)。
步骤 1:采样 expert 负载权重。
我们通过从幂律分布中采样 E 个权重来生成一个负载 profile,其中每个 expert 对应一个权重。使用逆变换采样方法,并令 U ~ Uniform(0,1),每个原始权重计算如下:
![]()
其中,xmin 和 xmax 定义分布的上下界,α 控制负载不均衡的程度。随后,这些权重会被归一化,用来得到每个 expert 分配到的 token 数量:
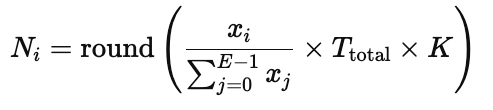
其中,Ttotal 是 batch size,K 是 top-k routing factor,也就是每个 token 会被路由到 K 个 experts,而 Ni 是分配给第 i 个 expert 的 token 数量。由于取整产生的剩余 tokens 会被重新分配,以保证总数平衡。
参数 α 控制分布的偏斜程度:当 α ≈ 0 时,会得到近似均匀的负载,这是理论理想情况;而当 α ≈ 1.2 时,会产生重尾分布,即少数 “hot” experts 接收大部分 tokens,这与 Qwen3-235B 等模型中的观察结果相匹配。
Step 2: Construct Synthetic Router Assignments.
步骤 2:构造合成 router 分配。
在正常推理过程中,一个训练得到的 gating network 会将每个 token 路由到其对应的 expert 或 experts。为了进行受控 benchmark,我们绕过这个 router,直接注入一个合成分配矩阵 L∈RTtotal×EL \in R^{T_{\text{total}} \times E}L∈RTtotal×E,其中恰好有 Ni 个 tokens 被确定性地路由到第 i 个 expert。这消除了 router 带来的随机波动,并确保硬件执行的正是步骤 1 中构造出的精确 workload 形状;这样就可以捕捉由负载最重 expert 导致的 “tail latency”,而在实践中,这种尾部延迟往往决定了整体吞吐。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)