沃尔玛45家门店的销售预测与业务分析
文章目录
第一章·业务思路
小伙伴们想象一下这个场景:
假如你是某家连锁超市的运营总负责人。马上到双十一了,你们正在开会,对三个部门负责人问题发愁——
供应链负责人: “领导,牛肉罐头和西瓜的安全库存还够撑几天?供应商那边说临时加单要加价20%,我们订不订?”
市场部负责人: “促销传单明天就要定稿印刷了,这期主打商品我们推什么?推多了怕库存不够,推少了又浪费广告费。”
门店店长: “周末收银员排班表要提交了。上周客流突然暴增,三个收银台只开了两个,顾客排队排到生鲜区了,投诉量翻了倍。”
这三个人提的问题都指i向一个核心问题:你不知道接下来会发生什么。 你不知道顾客会买多少,所以不知道备多少货;不知道备多少货,所以不知道促销推什么;不知道促销会带来多少人流,所以不知道安排几个人。
这就是“没有预测”的日常——永远在被动救火。
一个准确的预测,能让三个部门从容应对活动
如果有一份预测报告:
“双十一当周,某A类门店的食品部门销售额预计在5.2万到5.8万元之间,较上周增长约40%。增长主要由罐装食品和烘焙原料拉动,饮料类变化不大。”
这份预测给到各部门负责人:
1、供应链负责人活动对策:
供应链负责人不再追着供应商打电话临时加单。他提前知道罐装食品要涨20%,于是把订单拆成三批:第一批提前两周到仓,作为基础储备;第二批在节前三天到,应对高峰;第三批作为弹性补货,视实际销售情况触发。物流车辆也提前预定了,不再临时加价找车。结果就是:不缺货,不压货,物流成本还下降了。
2、市场部负责人活动对策:
市场部拿到预测后,传单不再“零食”。预测指出烘焙原料会涨但饮料不涨,于是促销策略瞬间清晰:传单首页打烘焙原料的组合优惠,饮料区不做折扣、反而摆到收银台旁边做冲动消费。促销预算花在了刀刃上,广告转化率翻了一倍。
3、门店店长活动对策:
门店店长提前调整了排班表:周四下午开始加派人手,周五全天满编收银台,周六下午恢复常态。员工不再被临时叫回来加班,顾客排队时间控制在3分钟以内,投诉量归零。
预测的本质,是把“不确定性”变成“可预期的缓冲”
零售行业的利润本来就薄。一次缺货,丢的是一单生意;一次积压,吞掉的是半年利润;一次糟糕的排队体验,可能永远失去一个顾客。
销售预测不是在玩数字游戏。它是在帮企业回答最难的问题:
“明天,到底会发生什么?”
在实际业务中你不可能100%答对这个问题。但哪怕你把准确率从“瞎猜”提升到“有理有据的推断”,你就能让供应链提前一周行动,让促销提前三天定稿,让人力提前一天排班。这多出来的几天缓冲,就是生意场上从“被动挨打”到“主动出击”的差距。
这个项目要做什么?
在这篇文章里,我拿到的是沃尔玛45家门店从2010到2012年的真实销售数据,覆盖了多个商品部门、节假日周期、甚至外部经济环境。
任务很明确:
1、看清过去: 过去两年里,销售额是怎么波动的?节假日到底能拉多高的峰?不同门店、不同部门差异有多大?
2、建模预测: 用Excel内置的预测工具,对未来3个月的销售额做出预估,并给出一个“置信区间”——我不只告诉你预测值,还告诉你这个预测有多可靠。
3、把数字变成决策: 基于预测,给门店经理、供应链和市场部各写一段“你应该怎么做”的建议。
这是一个用数据辅助业务决策的实战模拟测试。全部操作在Excel里完成,不写一行代码。
下一章, 先从数据说起——沃尔玛给了我们什么信息?这些信息长什么样?以及,在开始分析之前,需要做哪些“清扫工作”?
第二章:数据画像与清洗——我们拿到的是什么?
在开始任何分析之前,第一件事不是画图,而是搞清楚:手里的数据从哪来、长什么样、哪里脏了需要清洗干净。
2.1 数据来源与整体结构
本次分析使用的数据,来自Kaggle平台上的“Walmart Recruiting - Store Sales Forecasting”竞赛数据集。它记录了沃尔玛45家门店从2010年2月5日到2012年11月1日期间的周度销售明细,以及对应的外部经济环境指标。
原始数据被拆成了三张表,而不是一张现成的大表。这正是真实工作场景的常态——没有人会把干净的数据放到你面前,需要学会自己去合并。
| 表名 | 角色 | 信息 | 核心字段 |
|---|---|---|---|
| train.csv | 销售记录(主线) | 某门店、某部门、某一周的销售 | Store, Dept, Date, Weekly_Sales, IsHoliday |
| features.csv | 外部环境 | 某门店、某一周的宏观指标 | Store, Date, Temperature, Fuel_Price, CPI, Unemployment |
| stores.csv | 门店档案 | 某门店的静态属性 | Store, Type, Size |
关联逻辑:
- 三张表通过 Store(门店编号)和/或 Date(日期)连接。
- train.csv 和 features.csv 用 Store + Date 组合键关联。
- stores.csv 用 Store 单键接入,补充门店类型和面积。
2.2 数据预览:具体有什么数据
(1)销售记录表 (train.csv)
是我们的主表。打开CSV文件,你会看到这样的结构:
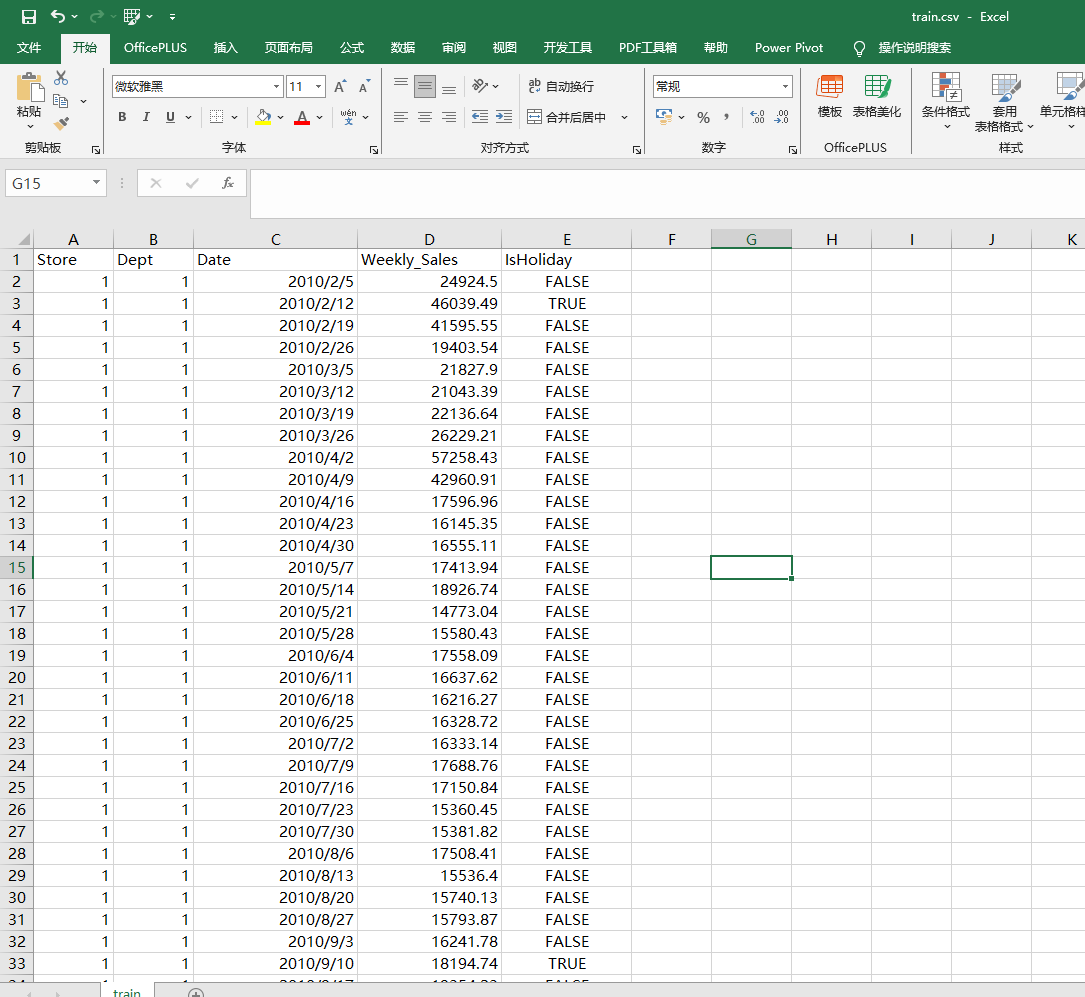
关键字段解读:
- Store (门店): 1到45的编号。每个编号代表一家独立的沃尔玛门店。
- Dept (部门): 1到99的编号。一家门店内部有多个商品部门(如食品、服装、电子),每个部门单独记录销售额。这意味着,同一天同一门店会有多行记录——每行代表一个部门的销售。
- Date (日期): 销售周的周五日期。数据以“周”为颗粒度,每周一个数据点。
- Weekly_Sales (周销售额): 这就是我们要预测的目标变量。 单位是美元。
- IsHoliday (是否节假日): 布尔值(FALSE/TRUE)。标记该周是否包含一个影响销售的节假日(感恩节、圣诞节、劳动节等)。
注意点: 不要直接拿整张表的销售额画图。因为销售额是“门店&部门”粒度的,整表汇总会把不同部门加总,掩盖部门间的差异。后续分析会灵活调整聚合粒度。
(2)外部环境表 (features.csv)
这是帮助我们理解销售波动原因的“外援”数据: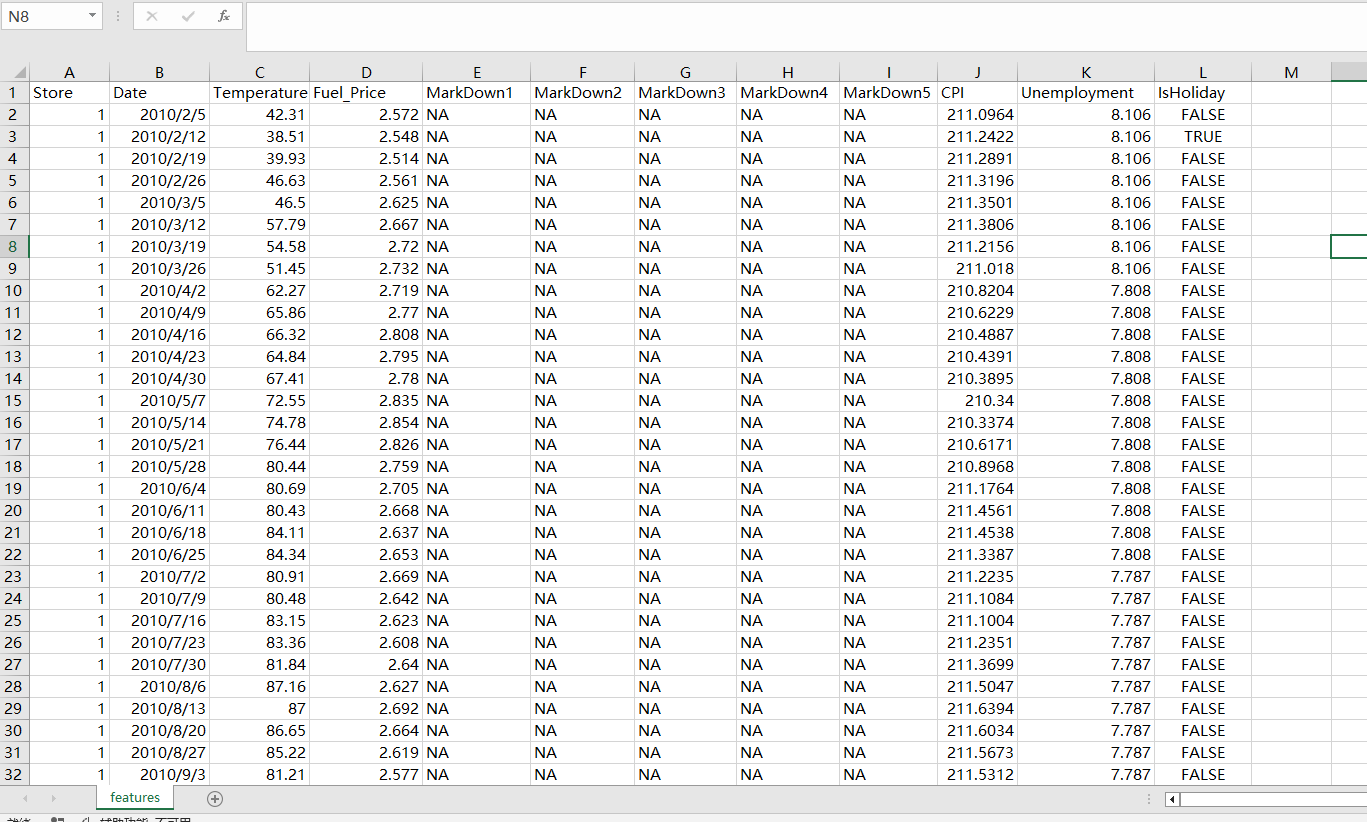
关键字段解读:
- Temperature (温度): 华氏度。极端高温或低温可能影响客流。
- Fuel_Price (燃料价格): 美元/加仑。油价上涨会增加物流成本和消费者出行成本,可能影响消费意愿。
- CPI (消费者价格指数): 衡量通胀水平。注意,不同门店的CPI值不同——因为数据是按区域划分的,沃尔玛门店分布在美国不同经济地区。
- Unemployment (失业率): 百分比。就业形势直接影响居民收入和消费能力。
(3)门店信息表 (stores.csv)
这是数据最少的表,只有45行(每家门店一行):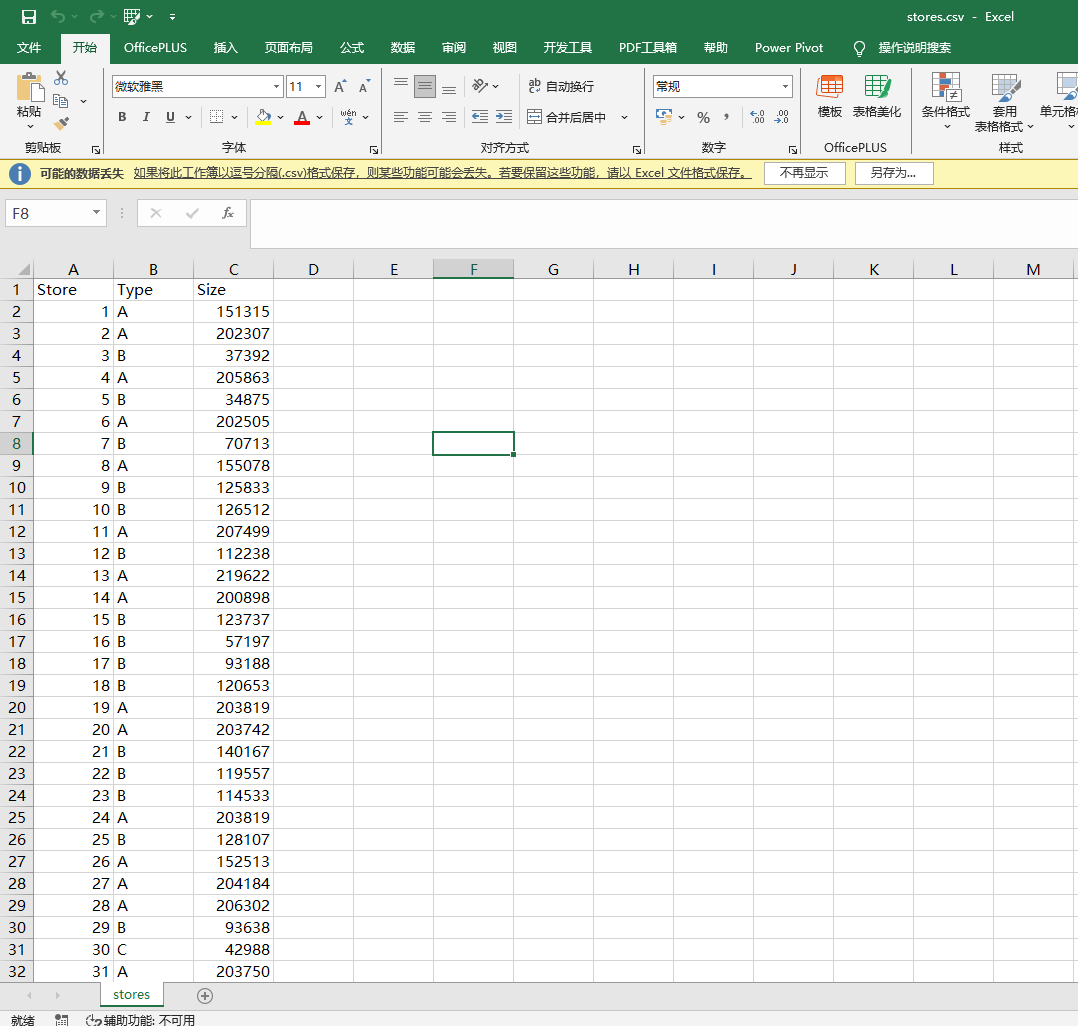
关键字段解读:
- Type (门店类型): A、B、C三种。A类通常是大型超级中心(Supercenter),C类可能是社区店或小型格式店。
- Size (门店面积): 平方英尺。面积越大,通常品类越多、客流量越大。
2.3 数据清洗
步骤1: 批量导入三张CSV表
- 点击“数据” → “获取数据” → “从文件” → “从文件夹”,选择存放三张CSV的文件夹。
- Power Query会列出所有文件。我们不要直接点击“合并”,而是点击“转换数据”,分别处理每张表。
- 在左侧“查询”窗格中,依次点击每张表,检查预览数据。
步骤2: 检查与修正数据类型
这是最常见的问题。在Power Query编辑器中,选中每一列,检查“主页”下的数据类型:
| 表名 | 维度(列) | 应设类型 | 常见问题 |
|---|---|---|---|
| train | Store | 整数 | 不应有小数 |
| train | Dept | 整数 | 不应有小数 |
| train | Date | 日期 | 务必设为“日期”,否则时间序列分析会失败 |
| train | Weekly_Sales | 小数/货币 | 确保能求和 |
| train | IsHoliday | 文本或True/False | 检查是否统一为TRUE/FALSE格式 |
| features | Store | 整数 | 与train表保持一致 |
| features | Date | 日期 | 与train表保持一致 |
| features | Temperature | 小数 | 用于相关性分析 |
| features | Fuel_Price | 小数 | 用于相关性分析 |
| features | CPI | 小数 | 不同区域CPI基准不同,不能直接跨门店比较绝对值,但可用于同门店趋势 |
| features | Unemployment | 小数 | 百分比形式,是8.106(%) |
| stores | Store | 整数 | 关联键 |
| stores | Type | 文本 | A/B/C |
| stores | Size | 整数 | 用于门店对比 |
train表:
features表:
stores表:
步骤3:检查缺失值与异常值
对关键列做快速筛选:
- Weekly_Sales: 点击列标题的筛选箭,查看是否有 null 或 0。0值可能是缺货或关店的信号,需要根据业务背景判断是否剔除(查找没发现)。
- Date: 检查是否有空值或异常日期(如1900-01-01)。确保日期范围在2010-02-05到2012-11-01之间(查找没发现)。
- IsHoliday: 确认只有TRUE和FALSE两种值,没有空白(查找没发现)。
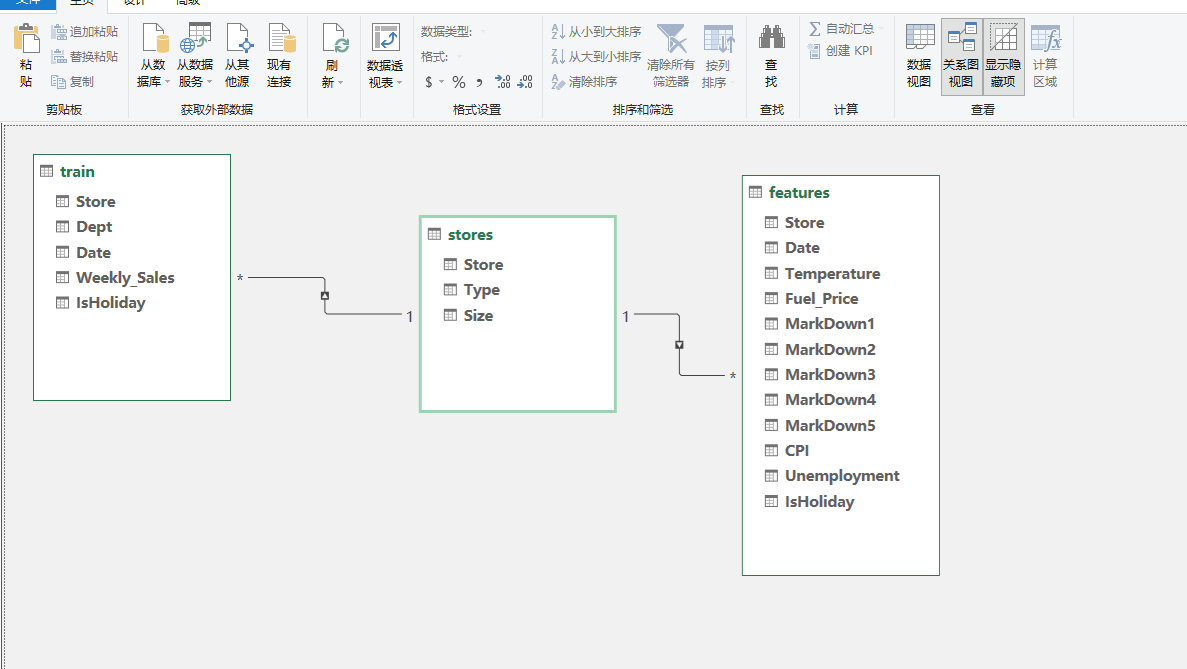
步骤4:处理门店信息表的设计选择
这里有一个表架构问题。stores.csv 只有45行,如果直接合并进主表,每家门店的类型和面积会在几万行数据里重复出现。这没有错,但在数据建模上有更好的处理方式。
这里有两种表架构选择:
| 方案 | 做法 | 优点 | 缺点 |
|---|---|---|---|
| A:物理合并 | 把stores.csv也合并进宽表 | 简单直接,一张表打天下 | 数据冗余,45行变几万行 |
| B:关系建模 | 在Power Pivot中建立Store关联 | 更专业,体现数据建模思维 | 需要额外建立关系 |
这里我用的方案B,把 stores.csv 作为单独的“门店维度表”加载到Power Pivot数据模型,在模型视图中通过 Store 字段与主表建立一对多关系(星型模型)。
步骤5:加载数据到Excel与Power Pivot
- 点击“主页” → “关闭并上载至…” → 选择“仅创建连接”,并勾选“将此数据添加到数据模型”。这张表将成为后续透视表和分析的数据源。
- 对于 stores.csv,同样操作加载到数据模型,但不合并。
第三章:探索性分析——从数据中挖出关键线索
核心:从五个方向对 “什么在影响沃尔玛的周销售额?” 展开分析。
探索分析1:全局趋势——过去两年,销售额是涨是跌?
要解决的问题: 整体销售额有没有趋势?是平稳的,还是大起大落?
操作步骤:
1、创建透视表
- 插入数据透视表,数据源选分析宽表。
- 行: Date(日期)。
- 值: Weekly_Sales(求和)。
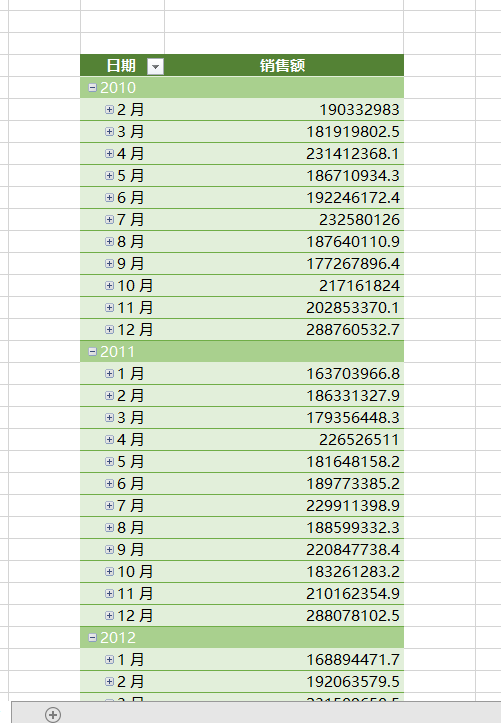
2、按月份聚合
- 右键点击透视表日期列的任意单元格 → 选择“组合”。
- 在弹出的对话框中,同时选中“月”和“年”。点击确定。
- 现在行变成了“年-月”格式,每个点代表一个月的总销售额。
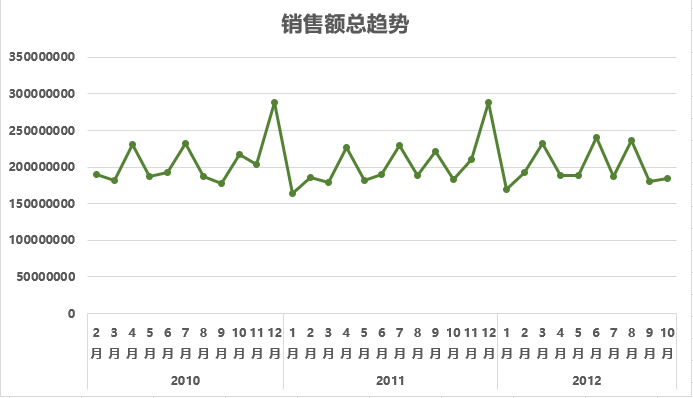
3、插入折线图
- 选中透视表,插入“带数据标记的折线图”。
- X轴为年月,Y轴为月销售总额。
4、添加趋势线
- 右键点击图表上的折线 → “添加趋势线”。
- 选择“线性”,并勾选“显示公式”和“显示R平方值”。
- R平方值越接近1,说明线性趋势越明显;越接近0,说明趋势越不明显、波动越大。
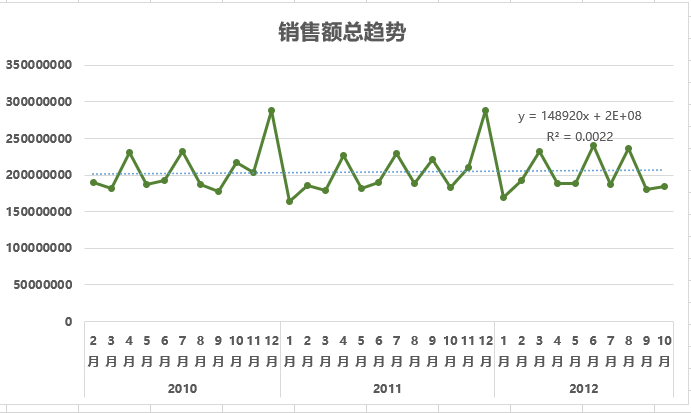
结论分析:
从2010年2月到2012年10月的月度销售趋势来看,销售额呈现“高位震荡、增长停滞”的趋势。趋势线的R平方值为 0.0022,说明线性趋势几乎完全不存在。值得注意的是,每年 [11-12月] 会出现明显的销售高峰,这与感恩节-圣诞节的购物季高度吻合。初步判断,节假日是驱动销售波动的核心因素之一。
趋势线解读:
前面为月度销售额添加了一条线性趋势线,计算出的R平方值为0.0022。这个数字几乎为零,说明时间并不是驱动销售额变化的原因。
它是一个成熟且稳定的门店销售,连续两年维持在高位平台震荡,既没有快速增长,也没有明显下滑。 这意味着预测的重心不在于寻找增长曲线,而是要捕捉那些有巨大影响力的季节性高峰和低谷。
探索分析2:节假日效应——节假日的销售拉升到底有多大?
要解决的问题: 节假日周的销售额,真的比平时高吗?高多少?
操作步骤:
1、创建节假日对比透视表
- 新建数据透视表。
- 行: IsHoliday(是否节假日)。
- 值: Weekly_Sales(求和),并拖入两次。
- 对第二个Weekly_Sales列:右键 → “值字段设置” → “值显示方式” → “总计的百分比”。
- 对两个值字段分别重命名为“总销售额”和“销售额占比”。

2、节假日的周均销售额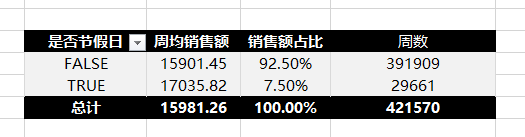
初步汇总显示,节假日周的周均销售额仅为7%。这个数字很明显稀释了节假日那一周的数据贡献,导致看不出效果,它是由所有门店、所有部门混合平均造成的稀释结果。所以需要深挖到具体每一周的销售总额时。
这里需要小伙伴们了解一个节日的相关知识点:感恩节为每年11月的第四个星期四 和 圣诞节为每年12月25日。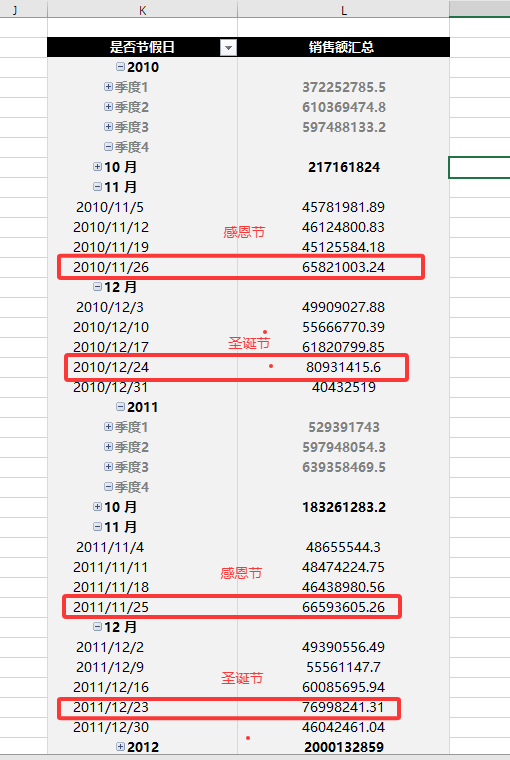
销售额最高的前N周,几乎全部集中在感恩节、圣诞节所在的时段。节假日不是“让每一周都好卖一点”,而是“让某几周的销售瞬间爆表”。这2年中,全年销量最高的那一周,往往是圣诞节前的那一周。如果不能提前备足货、安排好人力,节假日高峰也可能变成销售恶梦。
探索分析3:门店差异——45家门店,谁是大腿,谁在拖后腿?
要解决的问题: 不同门店的销售贡献差异有多大?大店一定卖得多吗?
操作步骤:
1、按门店汇总透视表
- 新建数据透视表。
- 行: Type(门店类型)。
- 值: Weekly_Sales(求和),重命名为“总销售额”。
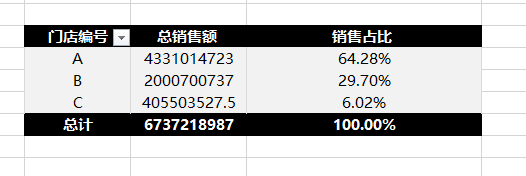
从45家门店的销售贡献来看,[A类/B类] 门店是销售主力,贡献了 94% 的总销售额。
2、计算平均门店面积销售额
计算这个指标有个意义:门店租金成本与投入产出比。
公式:总销售额/门店面积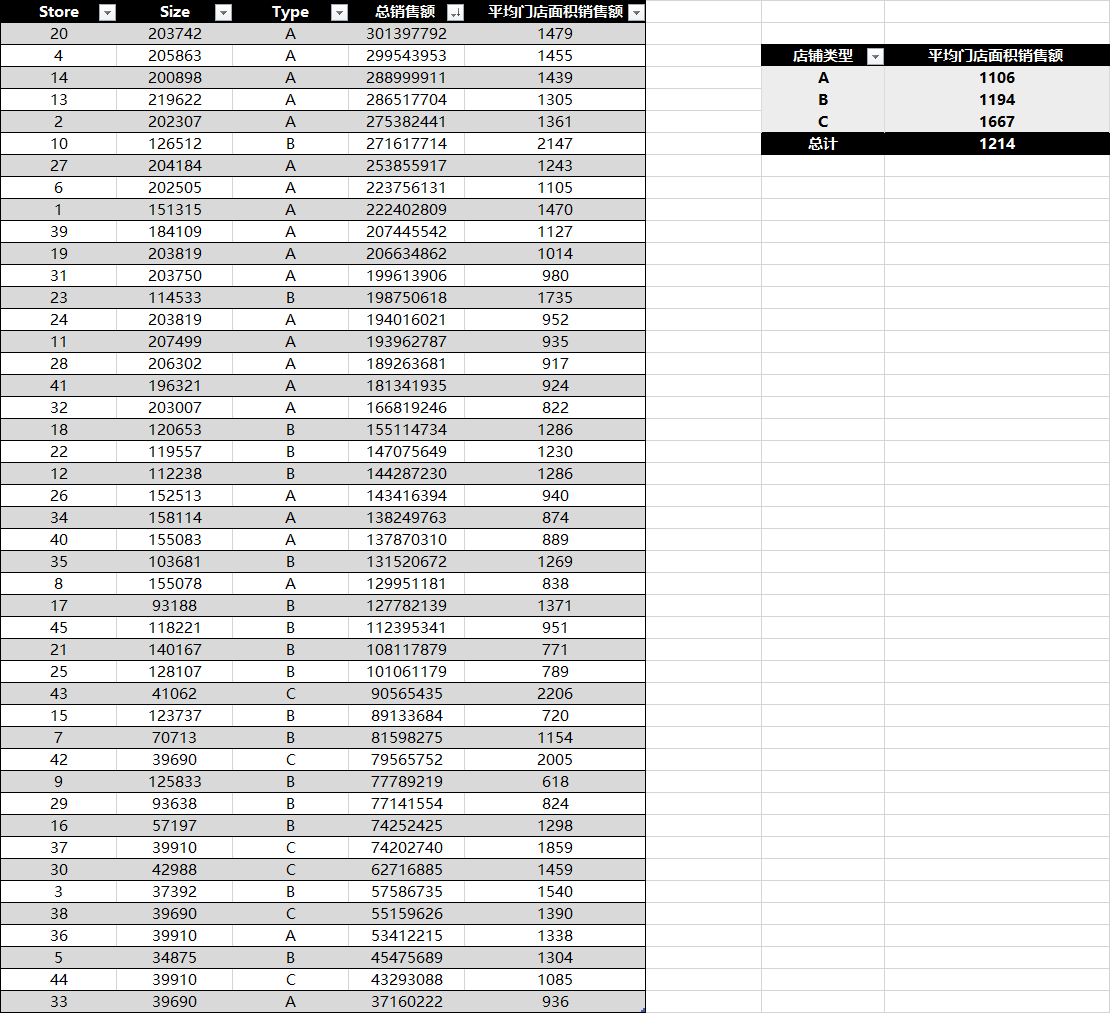
3、结论分析:
3.1、A类店是绝对主力,但内部极度分化
从门店类型看,A类店贡献了大部分销售额,是生意的基本盘。但同样是A类店,差距惊人。比如20号店坪效高达1479,而11号店只有935。面积几乎相同,但单位面积产出差了50%以上。说明A类店的运营水平参差不齐,存在改善空间。
3.2、C类店是隐藏的效率黑马
43号店(C类)面积仅41062平,在45家店里倒数,总销售额排在中下游。但它的坪效高达2206,是全门店第一。42号店(C类)坪效2005,排第二。这两家小店用不到大店四分之一的面积,创造了比任何A类店都高的单位产出。
3.3、规模陷阱——大,不等于强
5号店(B类)面积11.8万,坪效仅951。44号店(C类)面积相近(3.99万),坪效1085。门店不是越大越好。 C类店已证明,精准选品和高周转可以在较小面积里做出极高效率。部分大面积门店可能存在空间利用率低、品类臃肿的问题。
探索分析4:部门差异——哪些部门是赚钱的?哪些是拖后腿?
要解决的问题: 99个部门里,谁的销售贡献最大?集中度如何?
操作步骤:
1、按部门汇总透视表
- 新建数据透视表。
- 行: Dept(部门编号)。
- 值: Weekly_Sales(求和),降序排列。
2、计算占比
占比 = 该部门销售额 / 总销售额
3、结论分析:
3.1、头部集中度较低
92号部门以7.18%的占比拿下第一,95号(6.67%)、38号(5.84%)紧随其后。前三名合计占比不到20%,没有一个部门占比超过10%。
3.2、沃尔玛的销售分布非常均匀
大约87个部门的累计销售额才达到70%,说明每个部门都是小而稳的销售额基点,没有绝对的命门部门,也没有可以随意砍掉的长尾。
3.3、数据中有四个“幽灵部门”
部门编号:47,销售额-4962.93、部门编号:43,销售额14.32、部门编号:39,销售额177.98、部门编号:78,销售额1714.71。在后续的分析,可以直接剔除掉。
探索分析5:外部因素——温度、油价、失业率,真的在影响销售吗?
要解决的问题: 那些宏观经济指标,和我们门店的销售额有没有相关性?是正相关还是负相关?
操作步骤:
1、创建“每周总销售额”透视表
- 新建数据透视表。
- 行:Date。
- 值:Weekly_Sales(求和),重命名为“周总销售额”。
- 复制这个透视表,粘贴为数值到新单元格。
- 会得到两列:Date 和 周总销售额,共约143行(143周)。
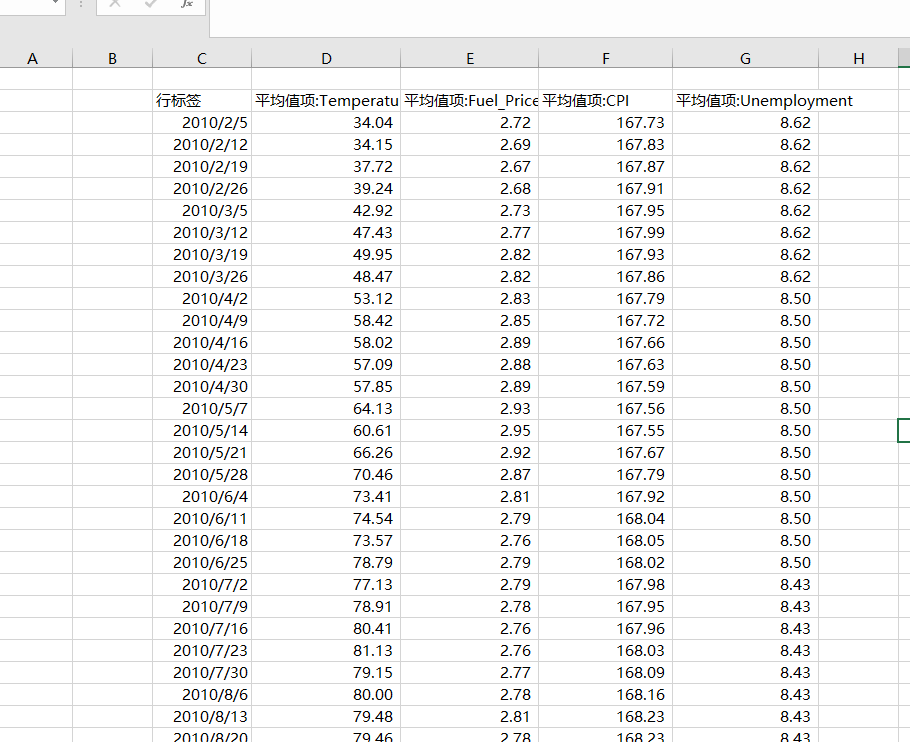
2、聚合外部特征表——按周取平均值
- 对 features.csv 表,插入另一个数据透视表。
- 行:Date.
- 值:依次拖入 Temperature、Fuel_Price、CPI、Unemployment,全部设为“平均值”。
- 复制这个透视表,粘贴为数值。
3、把外部变量匹配到分析底表
使用vlookup函数匹配对应的信息到最开始的步骤1里的字段后面。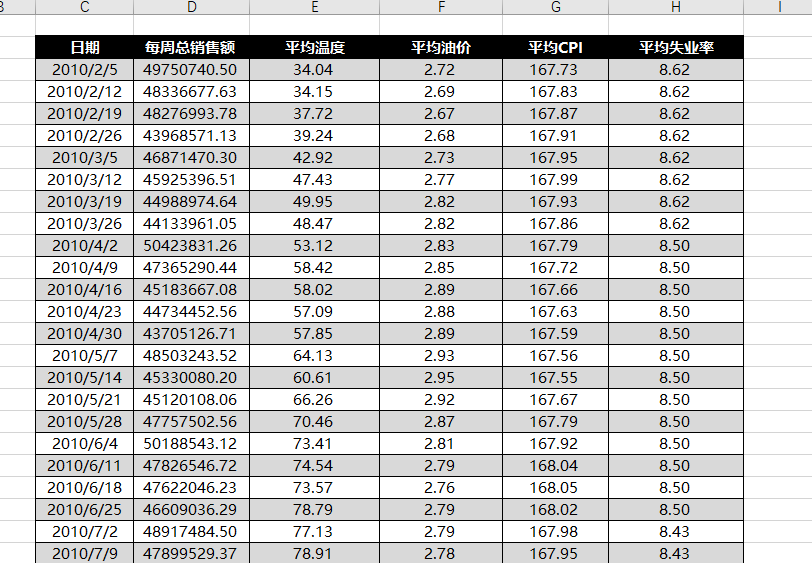
4、计算相关系数
使用 CORREL 函数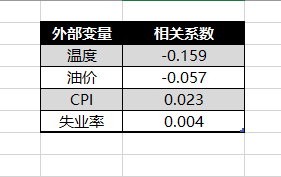
| 外部变量 | 相关系数 | 解读 |
|---|---|---|
| 温度 | -0.159 | 极弱负相关。温度升高,销售额微微下降,但几乎可以忽略 |
| 油价 | -0.057 | 几乎为零。油价涨跌,销售额岿然不动 |
| CPI | 0.023 | 几乎为零。通胀水平和销售额无关 |
| 失业率 | 0.004 | 零相关。就业形势完全不解释销售额变化 |
说明:外部环境指标,几乎不影响销售额。
5、结论分析:
5.1、沃尔玛卖的是刚需,不是可选消费
油价涨了,消费者可能少开车,但不能少买卫生纸。失业率高了,家庭预算紧了,但米面粮油还是得买。CPI在涨,通胀在走,但沃尔玛的收银机照样响。这恰好证明了:这45家门店卖的不是可买可不买的东西,而是老百姓过日子的必需品。这是沃尔玛商业模式的核心壁垒。
5.2、更好进行预测建模
外部变量解释力几乎为零,在后续预测建模时,我们没必要把它们塞进模型里。强行加入只会增加复杂度、引入噪音,反而降低预测精度。最好的预测,只需要:历史销售数据 + 节假日标记。
第四章:预测建模——用历史数据,推测未来12周
目标: 基于2010年2月至2012年10月的每周销售数据,预测2012年11月至2013年1月(约12周)的销售额,并给出置信区间。
工具: Excel
核心原理: 预测工作表背后使用的是指数平滑算法(ETS)。它会自动分解你的时间序列,识别出趋势、季节性、周期性,然后外推。我们不需要手动调参,Excel会自动完成拟合。
第一步:数据准备——构建“单列时间序列”底表
预测工作表只能处理“单列时间序列”——即一列日期、一列数值。不能直接用它来预测“45家门店×99个部门”的明细。需要先按周汇总全部销售额。
操作:
- 新建数据透视表,数据源选你的分析宽表(train.csv清洗后的那张)。
- 行:Date
- 值:Weekly_Sales(求和),重命名为“周总销售额”。
- 将透视表复制为值(这里将这个数据命名为预测数据表,方便记忆)。
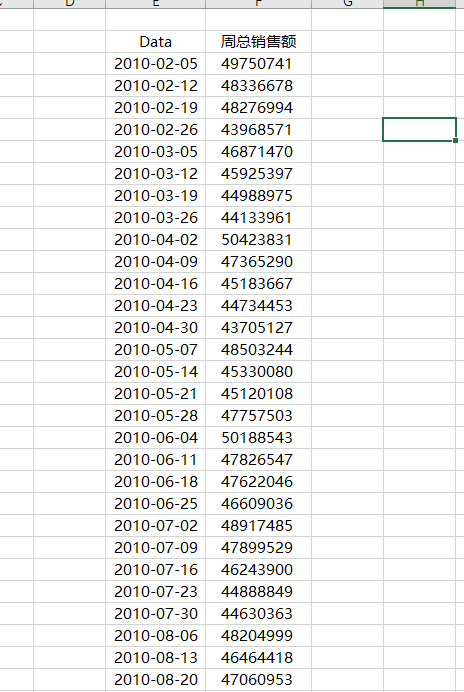
第二步:运行预测工作表
操作:
1、选中数据区域
在“预测输入”工作表中,选中两列的全部数据(包括标题行)。
2、调出预测工作表
点击Excel顶部“数据”选项卡 → 在“预测”组中,点击 “预测工作表” 按钮。
3、配置预测参数
A、弹出的对话框会显示一张预览图,里面有历史数据的折线和预测的延伸线。
B、在对话框底部,点击 “选项” 展开详细设置:
| 参数 | 设置值 | 说明 |
|---|---|---|
| 预测结束 | 手动输入日期 2013-01-31 | 你最终想要预测到哪一周。数据集截止2012年10月底,往后推12周大约是2013年1月底。 |
| 季节性 | 设为 52 | 一年有52周。销售数据有明显年度周期(每年12月高峰),设为52让模型自动检测以年为周期的波动模式。Excel会自动检测周期性,也可以手动指定。如果数据有明显年度周期(每年12月高峰),指定52周效果更好。 |
| 置信区间 | 保持默认 95% | 真实值落在“上限”和“下限”之间的概率是95%。 |
| 缺失点 | 保持默认 内插 | 如果历史数据中有缺失周,Excel自动填补。 |
| 重复 | 保持默认 自动检测 | Excel自动识别是否有重复时间点并聚合。 |
勾选 “包括预测统计信息”,Excel会在预测图表下方生成一张评估表,包含模型拟合的误差指标(MAE、RMSE等)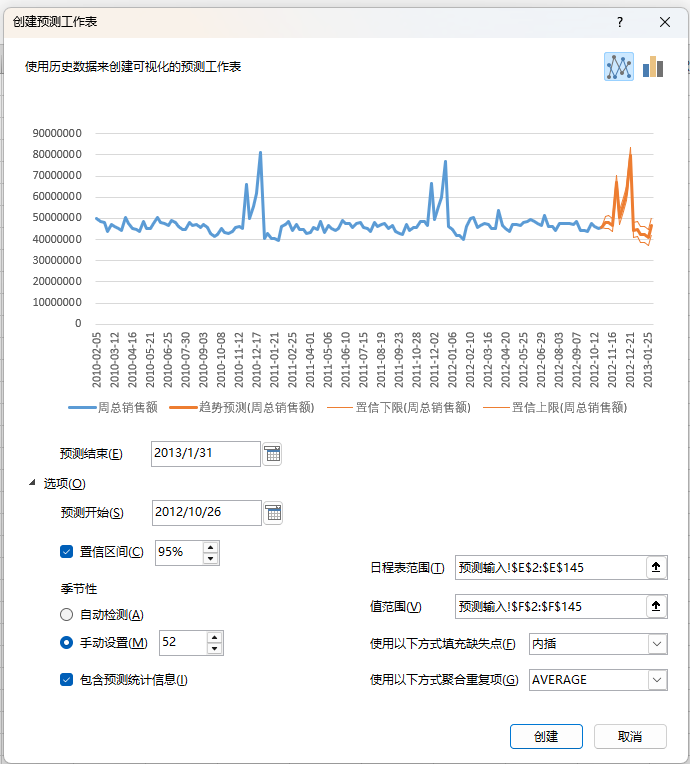
4、创建图表
- 点击“创建”。
- Excel会自动生成一个新工作表,包含:
- 一张完整的折线图(历史数据 + 预测值 + 置信区间上下限)
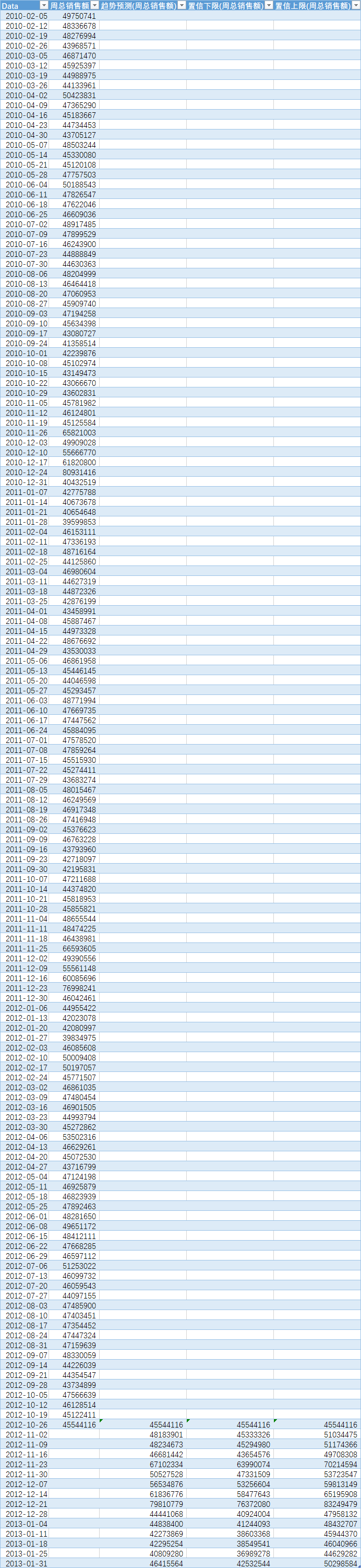
- 一个表格,包含三列:日期、预测值、置信下限、置信上限
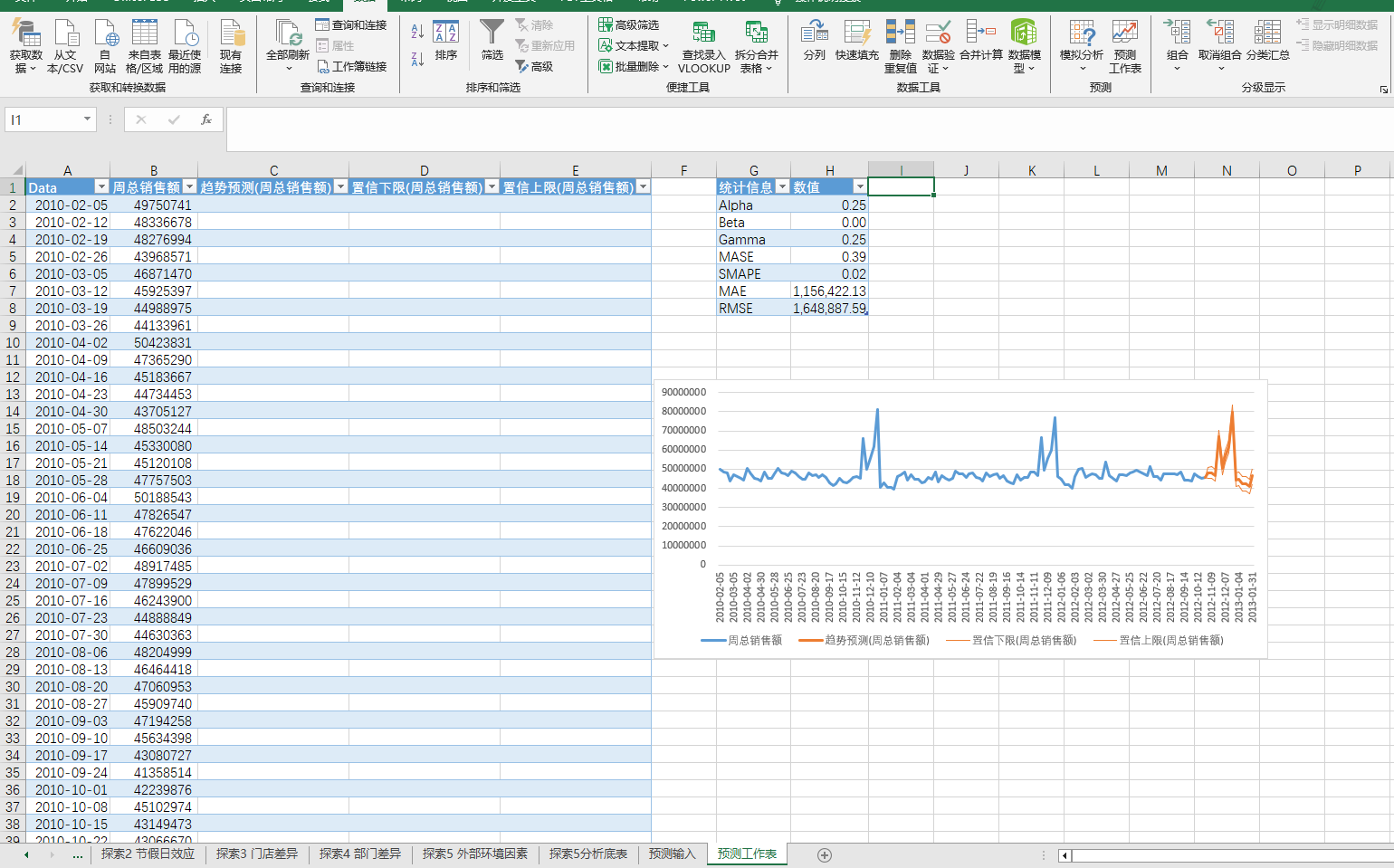
第三步:解读预测结果
预测结果解读:
1.12月峰值精准命中,但天花板依然在8000万
圣诞前周(12月第3周)的预测峰值为7981万,恰好落在2010年(8093万)和2011年(7700万)之间。说明模型没有被2012年的异常高值带偏,而是基于三年规律给出了一个“中间但是可靠”的判断。验证了在探索分析1的判断:旺季天花板已到,不会突然爆发。
2. 1月低谷准时到来,降幅达44%
预测显示,从12月21日的7981万峰值,到1月4日的4484万,销售额在两周内下降近3500万,降幅达44%。这每年都会上演的“节后悬崖”。 这个规律性暴跌对库存和人力影响很大,但也因为规律性比较强,提前准备的空间很多。
3. 置信区间在高峰周显著变宽
12月21日这周(圣诞节前一周)的置信区间宽度约688万(7637万-8325万),而平时只有约600万。说明模型对“峰值有多高”没那么确定——因为高峰期的销售受天气、促销力度等随机因素影响更大。供应链在备货时,应按上限(8325万)预留弹性,而不是按点预测(7981万)。
模型局限性:
1. 基于历史规律,不等于未来必然发生: 模型假设未来的销售模式与过去三年一致。若出现极端天气、供应链中断、突发经济冲击等情况,实际值可能大幅偏离预测。
2. 未引入外部变量: 在探索分析5中已证明温度、油价、CPI、失业率对销售额的解释力极弱,因此预测完全基于历史销售数据自身的时间序列规律。
3. 实际业务用法: 将本预测作为“基线预案”,实际运营中每周对比实际值是否超出置信区间。若连续两周超过上限或下限,说明环境发生了结构性变化,需重新调整预测模型。
注意:预测不是一次性的工作,而是需要持续校准的过程,需要根据实际情况反馈调整(计划也是一样的思路)。重要、很重要、非常重要。
第五章:结论与行动——从预测到决策
解决问题:“所以呢?现在该干什么?”
5.1 全局回顾:我们知道了什么?
在2010到2012的两年多里,这45家沃尔玛门店,呈现出三个的特征:
| 特征 | 发现 | 来源 |
|---|---|---|
| 无增长 | 月度销售额高位震荡,趋势线R²=0.0022,几乎没有趋势 | 探索分析1 |
| 周期性强 | 每年12月雷打不动冲上8000万美元,1月跌回4500万 | 探索分析1和4 |
| 稳定性高 | 外部经济环境(油价、失业率、CPI)几乎不影响销售额 | 探索分析5 |
核心:精准匹配供需、避免资源浪费
5.2 部门行动指南:基于预测,各司其职
1、供应链部门:分批式备货
第一批(11月上旬-感恩节前):
- 预测显示,感恩节周销售额将达6710万美元(95%置信上限7021万)。
- 行动:按7021万的对应库存量备货,而不是6710万。因为感恩节高峰的置信区间较宽,高估比低估的代价小得多(缺货丢的是销售和口碑,积压还有节后时间消化)。
第二段(感恩节后-圣诞节前):
- 预测峰值7981万美元(12月21日),与往年持平。
- 策略: 感恩节后不要降低补货频率。从11月底到12月中旬,保持每周两次补货节奏。圣诞节前一周达到库存顶峰,圣诞后立即将订货量削减40%,为1月淡季预留库存弹性。
2、市场部门:多层次促销
2.1 感恩节采取攻势,圣诞节采取防守策略
- 感恩节是唯一一个预测略微高于往年的窗口(6710万 vs 6659万/6582万)。可能意味着消费者信心微幅回升。市场部应把最大的折扣力度放在感恩节周,抢占市场,回流第一波资金。
- 圣诞节销售是“惯性高峰”——不需要额外促销刺激,顾客自己会来。此时打折等于白送利润。圣诞节周的促销策略应为“满额赠”而非“直接折扣”,保护利润率。
2.2 焦A类核心部门
- 在探索分析4中发现,前87个部门才累计贡献70%的销售额,没有绝对头部。但前20个部门仍然贡献了约35%的销售额。
- 策略: 促销传单的首页,必须放这些A类核心部门的商品。不要为了“品类丰富”而把C类长尾部门放上首页——它们带不来流量和销售额。
2.3 1月不打折,采取“清仓模式”
- 1月销售额预测仅4484万,且置信区间下限低至4124万。消费会进入一个“疲软期”。
- 策略: 用圣诞节后的第一周做“静默清仓”,不投广告费,不印新传单。把营销预算留到2月超级碗或情人节。
3、人力部门:排班的时间表
3.1 12月前三周(备战高峰):
- 12月21日当周预测7981万,意味着单周客流量将是一年最高。
- 策略: 12月第一周起,收银台全部放开,取消所有员工休假(调休或不补加班工资)。按7981万对应的客流量反推所需收银员数,并加10%弹性应对置信上限(8325万)。
3.2 12月最后一周(过渡期):
- 12月28日预测骤降至4444万,比前一周低44%。
- 策略: 12月26日起,逐步恢复正常排班。收银台开放数量可减少至高峰期的60%。
3.3 1月全月(淡季期):
- 1月销售额稳定在4000-4600万,为全年最低水平。
- 策略:安排员工轮休年假,利用淡季完成内部培训和设备检修。确保核心员工在2月前回归——因为2月起销售开始回升。
5.3 分析总结
1、不要想爆发式增长,做好日常成本控制和店铺运营。
2、不要浪费淡季:每一年的1月低谷都会准时到来,它不是意外,是你可以提前规划的确定性。利用它来做培训、做检修、做结构优化。
3、不要高估外部环境,因为油价、失业率、CPI,这些宏观新闻标题里的变量,对这45家门店的销售几乎没有影响。能驱动销售额增长的,只有两件事:节假日,和自身的运营效率。
个人心得:
这篇文章的核心,是如何利用历史数据构建一个可以解释、可以执行的预测模型,并最终转化为各部门的行动指南。
总结而言,预测的本质,是将未来的“不确定性”转化为可量化的“风险区间”,并为这个区间准备好多种应对方案。 它不能保证100%准确,但能将决策从“凭感觉”提升到“有依据”。这正是数据分析和业务赋能的核心价值所在。
分析主线:
第一个项目,Olist电商,做的是 “诊断”——从10万条订单里,找到物流延迟正在影响复购的证据。
第二个项目,绿色物流,做的是 “优化”——模拟三种减碳方案,算出了那条既能降排放又能省钱的路。
第三个项目,沃尔玛销售预测,做的是 “预判”——用两年多的历史数据,给未来12周的销售额绘制地图。
完整的业务分析链路:Olist(诊断问题)→ 绿色物流(优化方案)→ 沃尔玛(预测未来)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)